
FLOAT — Flow Matching for Audio-driven Talking Portraits
发布时间:
[Paper Reading] FLOAT: Flow Matching 驱动的语音口型合成方法
本文记录 KAIST 论文 FLOAT: Generative Motion Latent Flow Matching for Audio-driven Talking Portrait 的阅读内容,包含动机、结构设计、Motion Latent Auto-Encoder、Flow Matching 训练方式以及推理流程等。
代码已开源: float
1. 动机(Motivation)
当前 audio-driven talking head 方法多依赖 Stable Diffusion latent 空间进行视频生成,这带来几个典型问题:
1. 推理慢
扩散模型需要几十到上百步去噪迭代,导致生成速度慢,不便于实际应用。
2. 像素 latent 空间不适合建模运动
Stable Diffusion 的 latent 是图像压缩空间,其跨帧一致性差,不适合表达“运动轨迹”,容易出现闪烁与不稳定。
3. 依赖强几何先验(landmarks / 3DMM)
基于关键点或 3DMM 的方法限制了头动和表情的自由度,使模型难以捕获自然的非语言动作(眼神变化、细微表情等)。
2. LIA 背景与 Motion Latent Space 的设计动机
FLOAT 使用的 motion 表示方式来自 LIA(Latent Image Animator)。LIA 的思想是:
2.1 Motion Latent Space 是独立于图像 latent 的空间
图像 latent 适合压缩像素,但并不适合描述:
- 表情演变
- 头部姿态变化
- 局部区域(眼、嘴)的动态细节
因此需要一个专门用于运动的 latent space。
2.2 将 identity 与 motion 分解
LIA 认为一帧图像应编码为:
\[w = w_{\text{id}} + w_{\text{motion}}\]- \(w_{\text{id}}\):恒定不变,表征外观
- \(w_{\text{motion}}\):跨帧变化,描述姿态与表情
2.3 Motion latent 是可线性组合的正交空间
LIA 假设运动在一个正交基空间中表示:
\[w_{\text{motion}} = \sum_{m=1}^{M} \lambda_m \, v_m\]且基底满足正交性:
\[\langle v_m, v_k \rangle = \delta_{mk}\]这种正交分解带来的优势:
- 可解释性强(某个基可能对应“点头/转头/张嘴”)
- 可编辑(通过修改某个 \(\lambda_m\) 控制运动)
- 低维结构适合生成模型学习
FLOAT 继承了这一 motion latent 设计,并将其作为 Flow Matching 模型的目标空间。
3. FLOAT 整体框架
FLOAT 包含两个核心组件:
- Motion Auto-Encoder
- 学习 identity latent 与 motion latent(LIA-style)
- Decoder 负责根据 latent 重建高分辨率帧图像
- 使用多种局部损失强化嘴/眼区域细节
- Flow Matching 模型(Transformer Vector Field)
- 从噪声 ODE-integrate 到目标 motion latent 序列
- 以音频和情绪为条件驱动运动生成
- 仅需少量采样步数(≈10)
推理流程为:
源图 → Encoder → identity latent
音频 → Flow Matching → motion latent 序列
identity + motion → Decoder → 视频帧
整体结构如下: 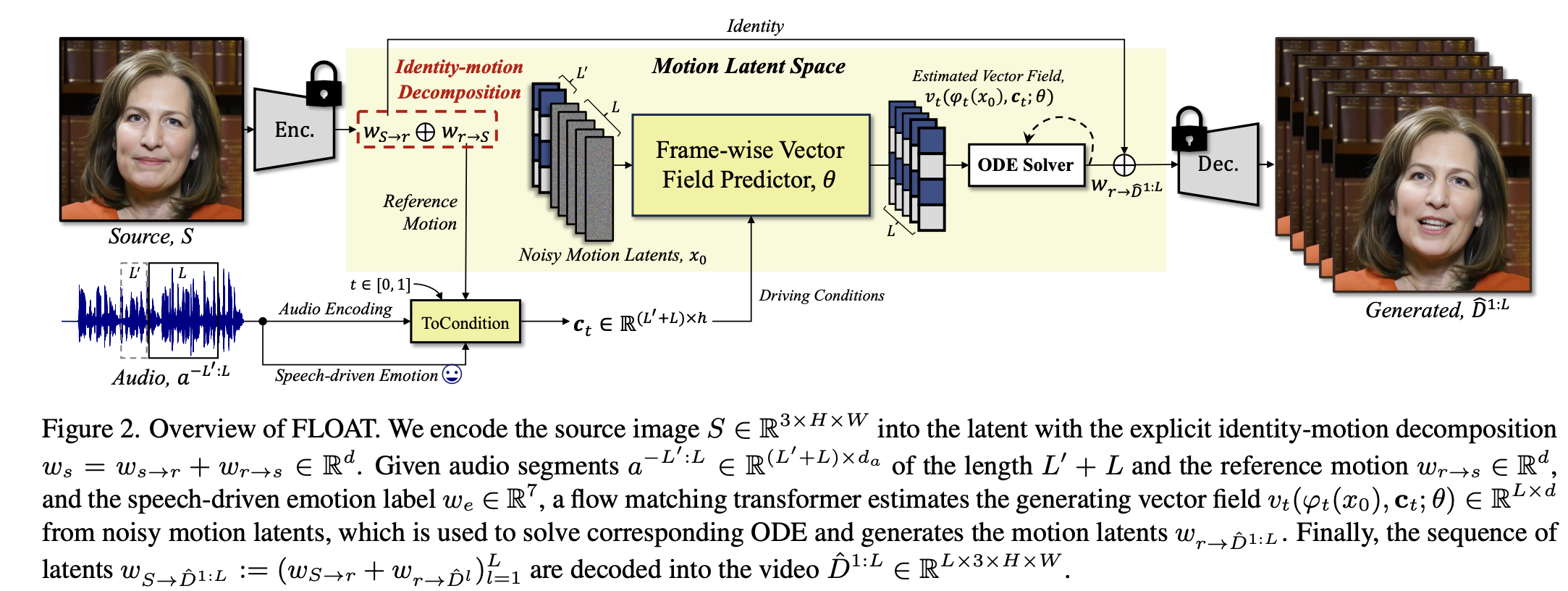
4. Motion Auto-Encoder 结构与训练
4.1 latent 分解
给定源图 \(S\) 和目标帧 \(D\),Encoder 输出:
\[w_S = w_{S\to r} + w_{r\to S}\] \[w_D = w_{D\to r} + w_{r\to D}\]其中:
- \(w_{S\to r}, w_{D\to r}\):identity latent
- \(w_{r\to S}, w_{r\to D}\):motion latent
训练目标:
\[\hat D = \text{Dec}(w_{S\to r} + w_{r\to D})\]即:用源图的 identity + 驱动帧的 motion 重建驱动帧。
4.2 Motion latent 的正交分解
motion latent 被约束为正交基扩展:
\[w_{r\to D} = \sum_{m=1}^M \lambda_m(D)\, v_m\]其中:
- \(v_m\) 是训练出来的 motion basis
- \(\lambda_m\) 是其系数
- basis 满足正交:
4.3 Encoder / Decoder 结构(概述)
Encoder:
- 多层卷积 + 下采样
- residual blocks
- 输出 identity latent 与 motion 系数 \(\lambda_m\)
Decoder:
- Dense → reshape
- 多级上采样 + residual blocks
- 输出高分辨率(512×512)RGB 图像
- 通过多级局部损失约束嘴/眼细节
整体结构如下如: 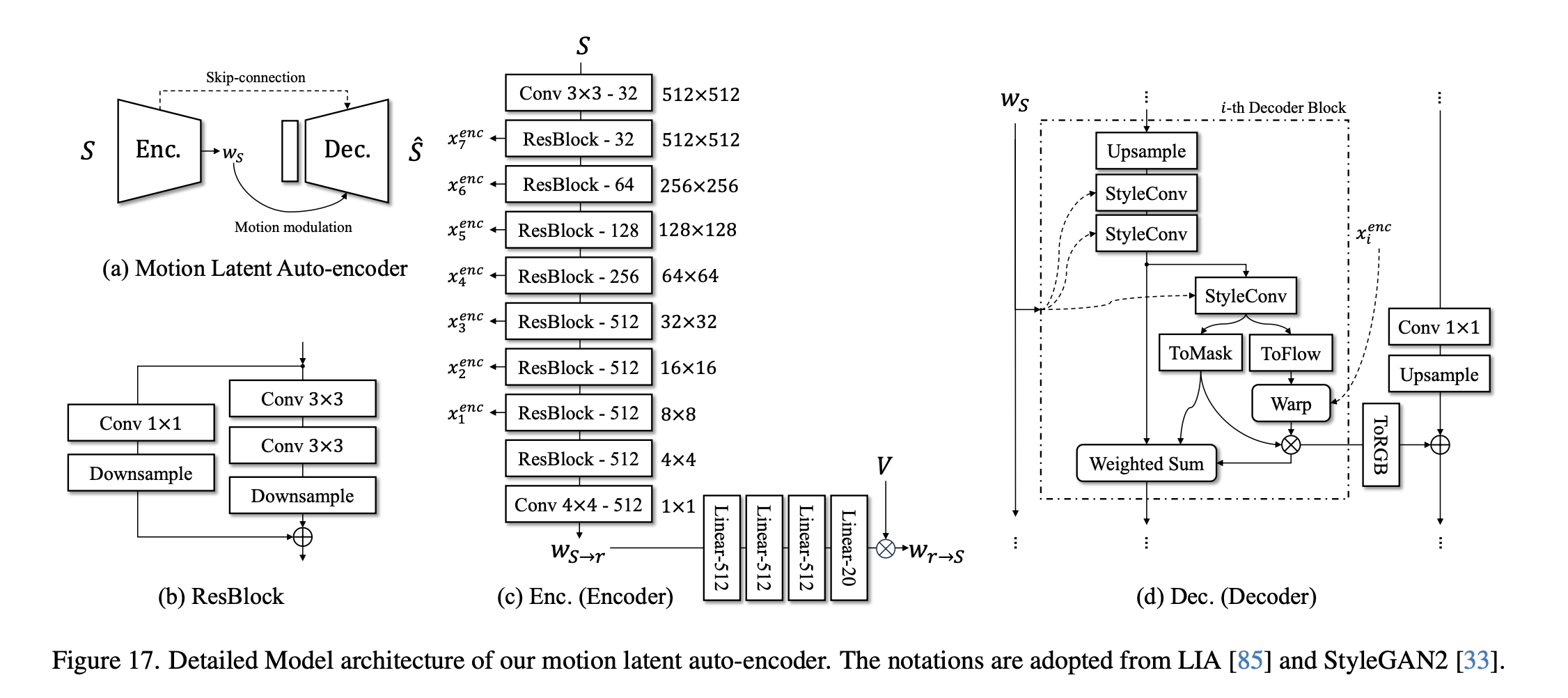
4.4 Loss 设计
Auto-Encoder 的总损失为:
\[\begin{aligned} \mathcal{L}_\text{AE} = {} & \mathcal{L}_\text{L1} \\ & + \lambda_\text{lp} \, \mathcal{L}_\text{perceptual} \\ & + \lambda_\text{comp-lp} \, \mathcal{L}_\text{component} \\ & + \lambda_\text{full-adv} \, \mathcal{L}_\text{globalGAN} \\ & + \sum_{x \in \{\text{eye}, \text{lip}\}} \Big( \lambda_{x\text{-adv}} \, \mathcal{L}_{x\text{-GAN}} + \lambda_{x\text{-FSM}} \, \mathcal{L}_{x\text{-FSM}} \Big) \end{aligned}\]其中:
- \(\mathcal{L}_\text{L1}\):像素级 L1
- \(\mathcal{L}_\text{perceptual}\):VGG 感知损失
- \(\mathcal{L}_\text{component}\):嘴/眼区域的 LPIPS
- \(\mathcal{L}_\text{globalGAN}\):整体外观自然度
- \(\mathcal{L}_{x\text{-GAN}}\):局部判别器(关键区域)
- \(\mathcal{L}_{x\text{-FSM}}\):局部纹理风格匹配(牙齿、眼睛非常关键)
5. Flow Matching:训练流程
Flow Matching 直接学习一个向量场,使得从噪声积分得到目标 motion latent。
5.1 Flow Matching 样本构造
给定目标 motion latent \(x_1\),从高斯采样 \(x_0\):
\[x_t = (1 - t)x_0 + t x_1\]真实向量场:
\[u_t = x_1 - x_0\]训练目标:
\[\mathcal{L}_\text{OT} = \| v_\theta(x_t, c_t) - u_t \|\]5.2 velocity consistency loss
为了减少抖动:
\[\mathcal{L}_\text{vel} = \| \Delta v_t - \Delta u_t \|\]总损失:
\[\mathcal{L} = \mathcal{L}_\text{OT} + \mathcal{L}_\text{vel}\]5.3 条件(Condition)构造
Flow Matching 的条件 \(c_t\) 包括:
- 逐帧音频 embedding(Wav2Vec2)
- 语音情绪 embedding(7 类 soft label)
- 源图 motion latent \(w_{r\to S}\)
- 时间 embedding \(\text{Emb}(t)\)
训练阶段加入 dropout 用于后续 classifier-free guidance。
各个条件的使用具体如下如所示: 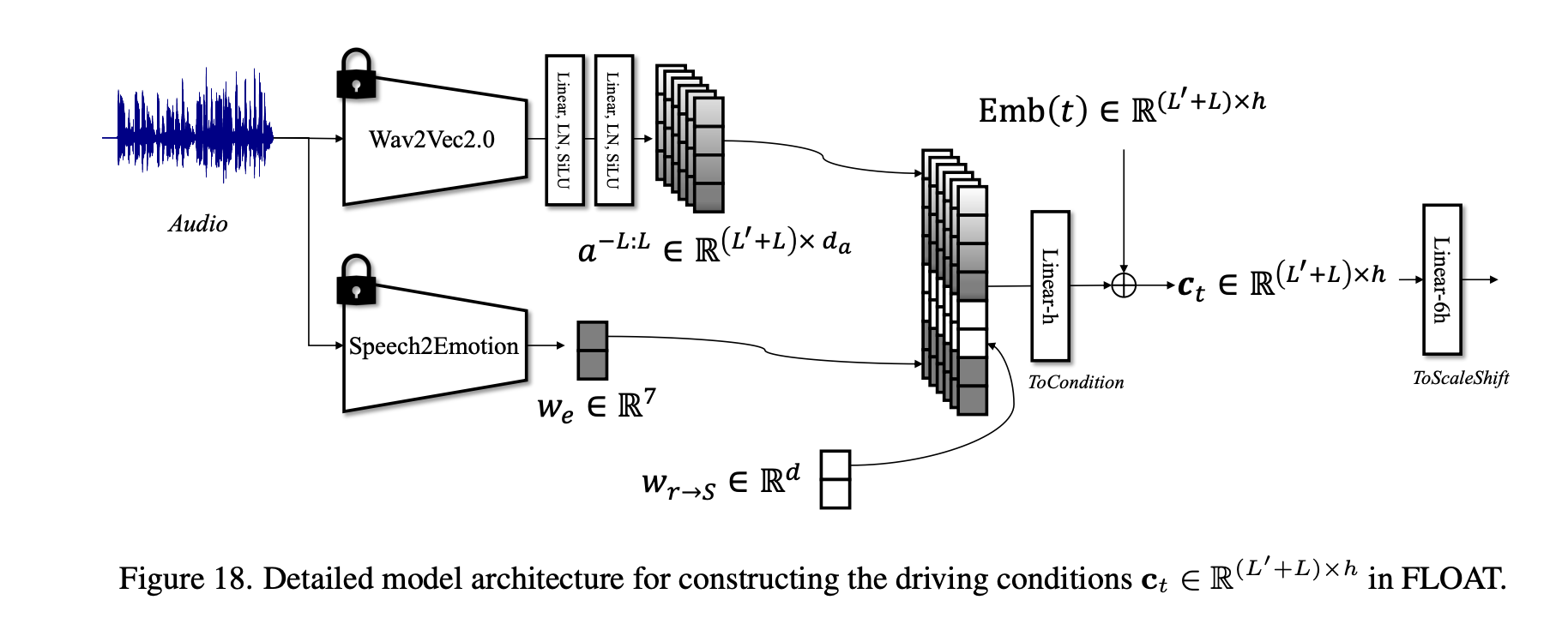
6. Transformer Vector Field(DiT 风格)结构
Flow Matching 的向量场使用 Transformer 实现,其设计类似 DiT,但更适合视频运动建模。
6.1 输入 token
每一帧的 motion latent 是一个 token:
- 输入形状:\(L \times d\)
- 帧级别输入有利于局部时序信息建模
6.2 Frame-wise AdaLN
不同于 DiT 的全局 AdaLN,FLOAT 使用逐帧 AdaLN:
\[\text{AdaLN}(x^l) = \gamma^l(c^l)\cdot \text{LN}(x^l) + \beta^l(c^l)\]其中:
- (\(x^l\)):第 (\(l\)) 帧的 motion latent token
- (\(c^l\)):对应帧的条件(音频 embedding + 情绪 embedding)
- (\(\gamma^l, \beta^l\)):由 (\(c^l\)) 经过 MLP 生成
为什么要逐帧处理,因为音频是逐帧的 ,运动 latent 是逐帧序列,每帧的语音特征、情绪都不同,逐帧 AdaLN 带来的效果:
- 更精准的 lip-sync
- 不同帧之间的动作自然过渡
- 更强的条件控制能力
6.3 Frame-wise gating
额外有逐帧 gating 参数:
\[\alpha^l \cdot x^l\]控制音频/情绪对每一帧运动的影响强度。
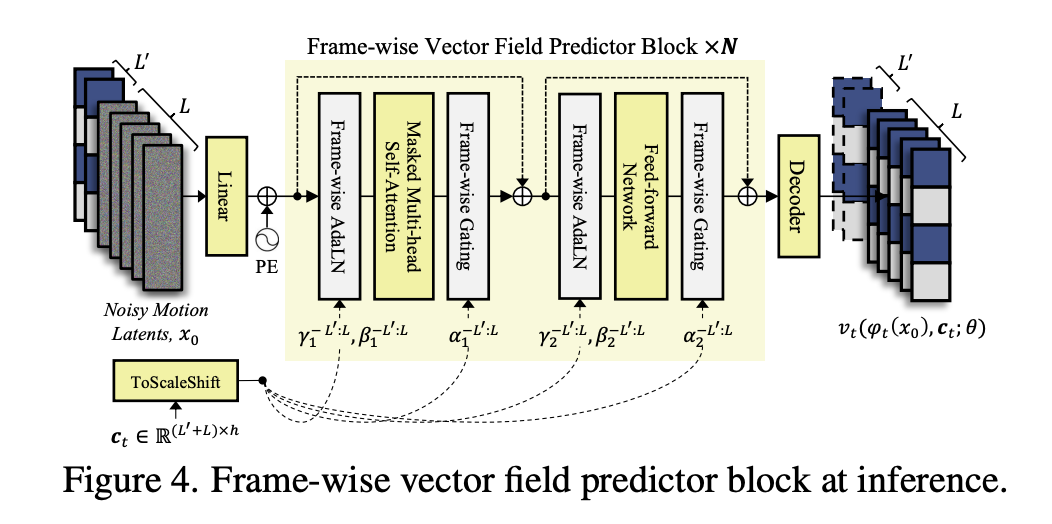
6.4 Temporal Masked Attention
只在局部时间窗口内做 attention(例如前后 2 帧),确保时序信息平滑。
- 避免 Transformer 跨长距离传播误差
- 保证短时运动一致性
- 减少闪烁与跳帧
Transformer 最原始的自注意力结构:
\[\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d}}\right)V\]FLOAT 在此加入 时间掩码矩阵 (M):
- 允许注意力只在邻近帧之间传播
- 例如只关注前后 2 帧
这样:
\[A_{ij} = \text{softmax}\left( \frac{Q_i K_j^T}{\sqrt{d}} + M_{ij} \right)\]若帧间距离超过阈值:
- (\(M_{ij} = -\infty\))
- softmax 后 attention 权重 = 0
简单理解:
通常 talking head 视频中,嘴部动作、眼部动作都具有局部时间连续性,因此 attention 不该跨太远。
6.5. L′ 与 L:核心序列窗口机制
这是 FLOAT 关键的部分。
定义
- L:当前窗口需要生成的帧数(“main window”)
- L′:来自上一窗口的历史帧数,用于保持跨窗口连续性(“overlap window”)
整个窗口长度为:
\[L′ + L\]窗口结构:
| 区域 | 长度 | 描述 | 是否要生成 |
|---|---|---|---|
| (-L′:0) | L′ | 上一窗口的 motion latent & audio | ❌ 不生成,只作为输入 |
| (1:L) | L | 当前窗口输出 | ✔ 需要 Flow Matching 生成 |
如果不使用 L′:
- 每个窗口之间会发生跳变(jump-cut)
- 嘴部、头部动作不连续
- 无法生成长序列视频
论文原文给出:
\[\mathcal{L}_{OT}(\theta) = \| v_t^{1:L}(x_t, c_t) - u_t(x|w_{r\to D^{1:L}}) \| + \| v_t^{-L′:0}(x_t, c_t) - w_{r\to D^{-L′:0}} \|\]解释:
(A) 主窗口 L 的 Flow Matching Loss
\[v_t^{1:L} \to \text{预测要生成的帧}\]这部分是标准 Flow Matching:从 noise 生成 motion latent。
(B) 历史窗口 L′ 的 Reconstruction Loss
\[v_t^{-L′:0} \to \text{保持上一窗口的 motion latent 不变}\]作用:
- 让 Transformer 学会“接上”前一个片段
- 保持跨窗口时序一致性
- 保证生成长视频时不会跳变
xt 的构造(拼接序列)
\[x_t = [ w_{r\to D^{-L′:0}} \;|\; \phi_t(x_0) ]\]- 前 L′:上一窗口的真实 motion latent
- 后 L:从 noise φ_t(x0) 演化到目标
长度 = L′ + L。
公式 (12):Velocity Consistency Loss
\[\mathcal{L}_{vel} = \|\Delta v_t - \Delta u_t\|\]- Δ 意味着“相邻帧差分”
- 约束向量场的时间梯度对齐真实运动轨迹
- 使嘴部与头部动作在时间上更平滑
总损失 (13)
\[\mathcal{L}_{total} = \lambda_{OT}\mathcal{L}_{OT} + \lambda_{vel}\mathcal{L}_{vel}\]Inference(推理阶段)
推理阶段仍然使用 L′ + L 的窗口。
窗口算法:
- 第一个窗口:
- 历史 L′ 音频 + motion latent 全部置零
- 然后生成 L 帧
- 后续窗口:
- 使用上一窗口生成的最后 L′ 帧
- 加上当前窗口的音频
- 再生成新的 L 帧
这样整个输出视频保持连续性。
7. 推理流程(Inference Pipeline)
FLOAT 的推理步骤如下:
Step 1. 编码源图 identity/motion
\[w_{S\to r}, w_{r\to S} = \text{Encoder}(S)\]Step 2. 提取音频特征与情绪标签
- Wav2Vec2 → 逐帧音频 embedding
- 语音情绪分类器 → 7 维 soft label
Step 3. Flow Matching 生成 motion latent 序列
从高斯采样 \(x_0\):
\[x_{t+\Delta t} = x_t + \Delta t \cdot v_\theta(x_t, c_t)\]通常需要 ≈10 步。
Step 4. 解码视频帧
每一帧 latent:
\[w^{(l)} = w_{S\to r} + w_{r\to \hat D^{(l)}}\]通过 decoder 得到最终帧图像。
8. 主要实验观察
- FLOAT 生成质量优于或接近 diffusion 基线
- Lip-sync(LSE-D)显著更好
- 推理速度远快于 diffusion(仅 10 步)
- 时序更稳定(依赖 velocity loss + motion latent 结构)
这一部分是新增集成内容,对 FLOAT 的设计决策进行逐项分析。
8.1 Frame-wise AdaLN vs Cross-Attention
论文实验对比了两种方式:
逐帧 AdaLN 更好地生成表情、嘴部同步,并产生更丰富的头部动作。
原因:
- AdaLN 逐帧调制 γ、β → 精确控制每帧
- Cross-attention 会让条件与序列互相干扰
- 在局部 Mask Attention 中,AdaLN 控制力更强
8.2 Flow Matching vs Diffusion(ϵ / x₀ prediction)
对比项:
- Diffusion (ϵ prediction)
- Diffusion (x₀ prediction)
- Flow Matching(本方法)
结果:
- FID、FVD 持平甚至更好
- lip-sync(LSE-D)明显优于 Diffusion
- 推理速度是 Diffusion 的 5×
表格摘要:
| 方法 | LSE-D ↓ | FVD ↓ | NFE |
|---|---|---|---|
| Diffusion | 较差 | 中等 | 50 |
| Flow Matching | 最好 | 最好 | 10 |
说明 Flow Matching 更适合捕捉嘴部微运动的连续性。
8.3 Guidance 系数 γₐ(音频)与 γₑ(情绪)
论文发现:
- γₐ ↑ → lip-sync & FVD 提升
- γₑ ↑ → 情绪表达更强(E-FID 提升)
表格(Tab. 6)显示,最佳组合通常为:γₐ = 2, γₑ = 1
代表音频引导比情绪引导更重要。
小结
消融实验证明:
- AdaLN 优于 Cross-Attn:逐帧控制能力更强
- Flow Matching 优于 Diffusion:更快、lip-sync 更准确
- Guidance 可调节表现风格
- 窗口 L′+L 对长序列至关重要
这些模块共同构成 FLOAT 的性能优势。
9. 小结
FLOAT 的关键点可以总结为:
- 使用 Motion Latent Space 代替像素 latent
- 结构化运动表达
- 正交分解可解释、可编辑
- 有利于减少跨帧抖动
- 用 Flow Matching 代替 Diffusion
- 推理步数减少 5–10 倍
- 时序一致性更高
- transformer-based vector field 结构干净、易扩展
- Decoder 用大量局部损失增强嘴/眼细节
- 实际工程中十分必要
- 与 motion latent 低维的缺陷互补
FLOAT 为构建音频驱动数字人的高效生成系统提供了一个结构合理、工程友好的方案,也为 audio→expression 或音频驱动的其他运动生成提供了借鉴意义。