
Self-Forcing 到 Self-Forcing++:让自回归视频扩散按推理方式训练
Self-Forcing 到 Self-Forcing++:让自回归视频扩散按推理方式训练
论文 1:Self Forcing: Bridging the Train-Test Gap in Autoregressive Video Diffusion
论文 2:Self-Forcing++: Towards Minute-Scale High-Quality Video Generation
检索日期:2026-05-24
主线:把 bidirectional video diffusion 蒸馏成可流式自回归模型,并把训练分布尽量推到真实推理分布上。
开篇点评:它真正解决的不是“更快采样”,而是训练分布错位
Self-Forcing 系列的切入点很直接:视频扩散模型要做实时、长视频、交互式生成,就不能每次等完整视频一次性 denoise 完。它需要像语言模型一样一段一段往后吐视频,而且最好能用 KV cache 复用历史上下文。
问题也随之出现。传统的 Teacher Forcing 或 Diffusion Forcing 训练时,模型看到的上下文不是它自己推理时会制造出来的上下文;推理阶段一旦前面生成得有一点偏,后面就会在偏掉的历史上继续生成,误差会积累成过曝、变暗、冻结、闪烁、语义漂移。
Self Forcing 的核心贡献不是又提出一个快采样 trick,而是把训练方式改成“训练时就 self-rollout”:让模型在训练阶段按推理流程自回归生成历史帧,再在这条模型自己生成的轨迹上做视频级分布匹配。Self-Forcing++ 接着解决原版只在短 horizon 内有效的问题:让 student 先滚出很长的序列,再从长序列里抽短窗口交给短视频 teacher 纠错,用 rolling KV cache 贯穿训练和推理。
我的判断是,这条路线的价值在于它把 video diffusion 的问题从“单次采样速度”推进到了“sequence model 的训练-推理一致性”。这比单纯把 diffusion steps 降到 4 步更关键,因为实时视频生成的长期质量最终卡在 exposure bias 和 cache state mismatch 上。
Paper Card
| 项目 | Self Forcing | Self-Forcing++ |
|---|---|---|
| Paper | arXiv:2506.08009, NeurIPS 2025 | arXiv:2510.02283, ICLR 2026 OpenReview |
| Authors | Xun Huang, Zhengqi Li, Guande He, Mingyuan Zhou, Eli Shechtman | Justin Cui, Jie Wu, Ming Li, Tao Yang, Xiaojie Li, Rui Wang, Andrew Bai, Yuanhao Ban, Cho-Jui Hsieh |
| Project | self-forcing.github.io | self-forcing-plus-plus.github.io |
| Code | guandeh17/Self-Forcing | justincui03/Self-Forcing-Plus-Plus |
| Base model | Wan2.1-T2V-1.3B, CausVid-style causal initialization | Wan2.1-T2V-1.3B student, short-horizon bidirectional teacher |
| 核心问题 | AR video diffusion 的 train-test gap / exposure bias | 原版 Self Forcing 超过 5 秒训练 horizon 后质量衰退 |
| 核心机制 | self-rollout during training, holistic distribution matching, rolling KV cache | long self-rollout, backward noise initialization, extended DMD, rolling KV training, optional GRPO |
| 主要证据 | VBench、user study、FPS/latency、ablation | 5s/50s/75s/100s long-video benchmark、Visual Stability、training budget scaling |
| 复现风险 | 64 张 80GB GPU 训练、score/critic 网络配置复杂、VBench 与 prompt rewriting 细节影响数值 | 长 rollout 训练成本高、Visual Stability 使用 Gemini-2.5-Pro、代码/模型公开程度仍需按 repo 当前状态核对 |
Abstract:论文摘要解读
Self Forcing 的摘要可以拆成三句话。第一,AR video diffusion 的核心痛点是 exposure bias:训练时模型被喂 ground-truth context,推理时却只能吃自己生成的历史帧。第二,Self Forcing 不再让训练只看真实历史,而是在训练中用 KV cache 自回归 rollout,让每一帧都依赖模型自己生成的前序帧。第三,训练信号从逐帧 denoising loss 扩展到整段视频的 distribution matching loss,因此优化目标直接作用在模型真正会生成的视频分布上。
Self-Forcing++ 的摘要是在这个基础上补长视频短板。短视频 teacher 本身只有约 5 秒能力,student 如果只在这个窗口里被约束,推理到 50 秒、100 秒以后仍会出现误差累积。Self-Forcing++ 的做法是让 student 先用 rolling KV cache 自己生成长序列,再从长序列里抽短窗口,让 teacher 对这些“已经带着累计误差的局部片段”提供 DMD 纠错信号。它声称可以在不需要长视频 teacher、不重新训练长视频数据集的情况下,把生成长度推到 100 秒,并在更高训练预算下展示 4 分 15 秒样例。
Motivation
现代 text-to-video diffusion 通常是 bidirectional DiT:所有帧一起 denoise,未来帧可以影响过去帧。这对离线短视频生成很强,但它天然不适合 streaming。真实交互式视频系统需要满足三个条件:
- 当前帧生成时不能依赖未来帧;
- 生成完一小段就能播放,不能等完整视频;
- 历史上下文不能每次重算,否则 latency 和显存都会爆。
自回归分解正好满足这个方向:
\[p_\theta(x^{1:N}) = \prod_{i=1}^{N} p_\theta(x^i \mid x^{<i})\]但把 diffusion 放进这个 chain rule 后,每个 conditional 仍然是一个 denoising process。若训练仍然使用 ground-truth context,模型学到的是 data-context conditional:
\[p(x^i \mid x^{\lt i}_{\mathrm{data}})\]推理真正需要的却是 model-context conditional:
\[p(x^i \mid \hat{x}^{\lt i}_{\theta})\]这个差异就是 Self Forcing 要正面处理的 train-test gap。
直观效果:先看训练范式差异
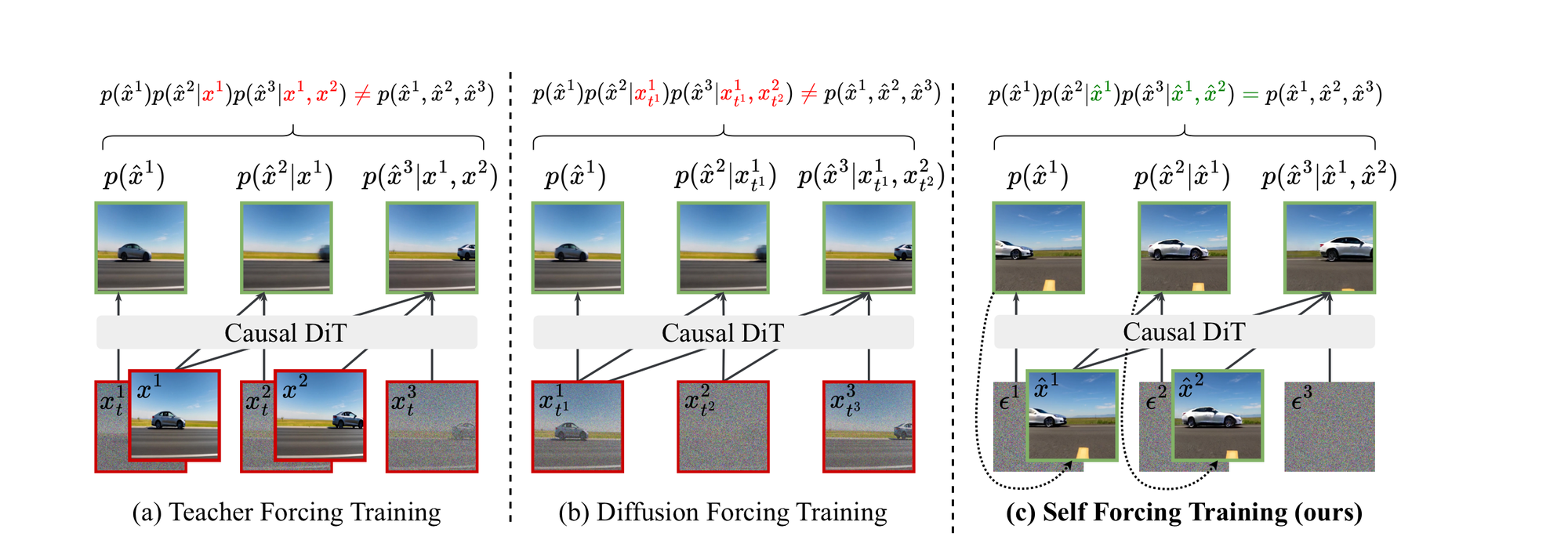
图 1:Self Forcing 原论文的 training paradigm 图。Teacher Forcing 和 Diffusion Forcing 虽然都能并行训练,但生成出来的中间分布不是模型推理时真正会遇到的分布;Self Forcing 训练时直接使用模型自己的历史输出。
这张图最值得看的是右侧。Self Forcing 并不是在 denoising loss 上加一个补丁,而是把条件上下文替换成模型自己生成的历史 $\hat{x}^{\lt i}$。这一步让训练流程接近推理流程,也让后面的 distribution matching loss 能真正作用在模型生成分布上。
Self Forcing:方法总览
Self Forcing 的训练可以理解成四层嵌套:
- 先把 Wan2.1 这样的 bidirectional diffusion model 转成 causal / autoregressive student;
- 用 few-step diffusion 让每个 chunk 只走很少 denoising steps;
- 训练时 self-rollout,历史上下文来自 student 自己;
- 在整段生成视频上用 DMD、SiD 或 GAN 做 holistic distribution matching。
自回归 diffusion 的 conditional
论文把每个帧或 chunk 简写为 $x^i$。每个 conditional 不是一次 softmax,而是一个 diffusion sampler:
\[p_\theta(x^i \mid x^{<i})\]在 few-step 设定下,给定 denoise timesteps ${t_1,\dots,t_T}$,当前帧从高噪声 latent 开始,逐步调用 $G_{\theta}$:
\[x^i_{t_T} \sim \mathcal{N}(0,I), \quad \hat{x}^i_0 = G_\theta(x^i_{t_j}, t_j, \mathrm{KV}(x^{<i}))\]论文实现里采用 Wan2.1 系列的 flow matching 参数化,并使用 uniform 4-step schedule $[1000,750,500,250]$。这意味着它的“实时性”不是只靠 KV cache,也靠把每个 conditional 的 denoising 链压得很短。
为什么要 holistic distribution matching
普通 denoising loss 近似学习的是数据条件分布。如果上下文来自真实视频,loss 优化得再好,也不能保证模型在自己生成的上下文上稳定。Self Forcing 把训练样本改成:
\[\hat{x}^{1:N} \sim p_\theta(x^{1:N})\]然后在生成视频分布和数据视频分布之间做匹配。以 DMD 为例,它优化 reverse KL 的梯度方向:
\[\mathbb{E}_{t}\left[D_\mathrm{KL}(p_{\theta,t} \Vert p_{\mathrm{data},t})\right]\]这里的 $p_{\theta,t}$ 是“模型自己 rollout 出的视频再加噪”的分布,$p_{\mathrm{data},t}$ 是真实视频加噪后的分布。这个细节很关键:loss 的输入不再是 teacher-forced 中间产物,而是 inference-time model distribution。
为什么训练没有贵到不可接受
看起来 self-rollout 会非常慢,因为自回归 rollout 不能像标准 transformer 那样完全并行。论文的工程解法有三点:
- 使用 few-step diffusion,避免每个 chunk 走几十步;
- 随机采样一个 denoise step $s$,只在该步保留梯度,其他步
no_grad; - 历史帧的 KV cache 做 stop-gradient,避免跨整条时间链反传。
对应训练可以概括为:
\[s \sim \mathrm{Uniform}\{1,\dots,T\}\]模型每次 rollout 时仍经过多个 denoising steps,但只让其中一个 step 获得梯度。论文报告 DMD 训练约 1.5 小时收敛,典型配置是 64 张 80GB GPU,每张 GPU batch size 为 1。这个成本并不小,但它说明 Self Forcing 是一个 post-training recipe,而不是从零预训练范式。
Rolling KV Cache:从能流式生成到能继续往后生成
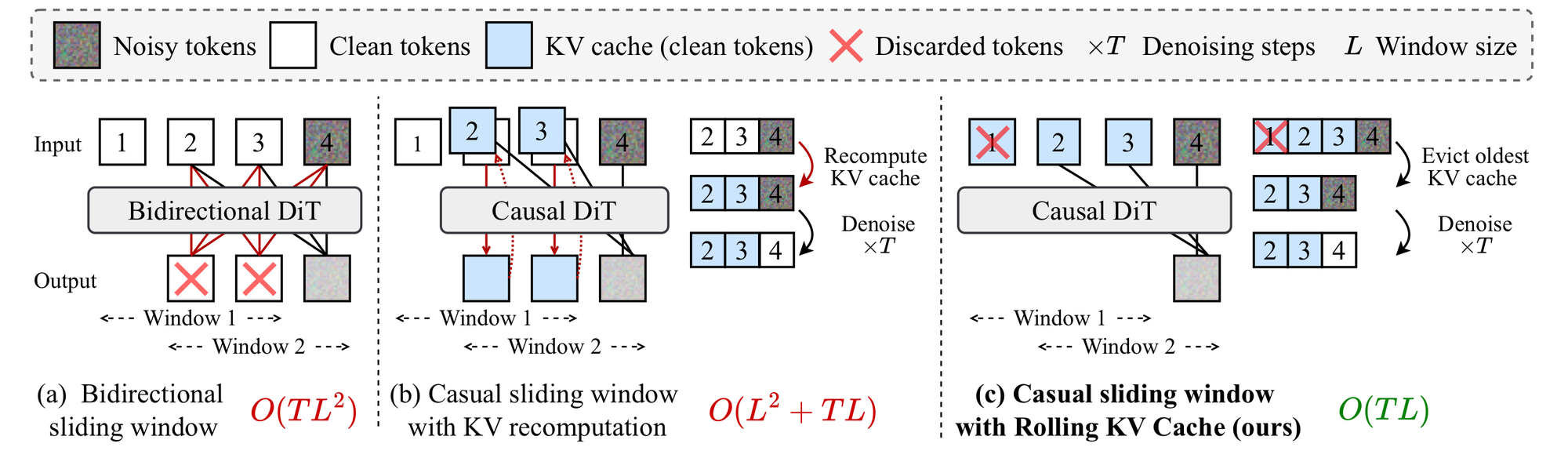
图 2:Self Forcing 原论文的 rolling KV cache 图。bidirectional sliding window 不支持 KV cache,causal sliding window 若每次重算 overlap 会浪费计算;rolling KV cache 只保留最近 $L$ 帧 token 的 K/V。
普通 bidirectional diffusion 在长视频 sliding window 中很痛苦,因为每个窗口的 attention 都要重算。因果模型可以缓存历史 K/V,但早期 causal sliding window 仍然需要对 overlap 部分重新计算 cache。Self Forcing 的 rolling KV cache 做法更接近 streaming LLM:cache 满了就弹出最旧的 K/V,再追加新输出的 K/V。
复杂度直觉是:
\[O(TL^2) \rightarrow O(L^2 + TL) \rightarrow O(TL)\]其中 $T$ 是 denoising steps,$L$ 是窗口大小。论文报告,在 10 秒视频 extrapolation 上,重算 KV 只有 4.6 FPS;rolling KV 加上对应训练策略后可以保持 16.1 FPS,同时缓解 naive rolling KV 的严重 artifact。
这里有一个容易忽略的细节:第一帧 latent 和后续 latent 的统计属性不同。第一帧只编码第一张图,不含同样的 temporal compression;如果训练时模型总能看到这个特殊 first image latent,推理时 rolling cache 把它滚出去后就会出现分布错位。原版 Self Forcing 用 local attention window training 让模型在训练中不要总依赖第一 chunk,以模拟长视频中的 cache 状态。
Evaluation:Self Forcing 的证据强在哪里
Self Forcing 的主表比较了 Wan2.1、LTX-Video、SkyReels-V2、MAGI-1、CausVid、NOVA、Pyramid Flow 等模型。关键数字是:
| 方法 | 参数量 | 吞吐 | 首帧延迟 | VBench Total | 备注 |
|---|---|---|---|---|---|
| Wan2.1 | 1.3B | 0.78 FPS | 103s | 84.26 | bidirectional diffusion,质量强但不流式 |
| CausVid | 1.3B | 17.0 FPS | 0.69s | 81.20 | 同样来自 Wan-1.3B,速度快但有误差累积 |
| Self Forcing chunk-wise | 1.3B | 17.0 FPS | 0.69s | 84.31 | 速度接近 CausVid,VBench 更高 |
| Self Forcing frame-wise | 1.3B | 8.9 FPS | 0.45s | 84.26 | 延迟更低,吞吐略低 |
这些数字支持两个 claim:第一,Self Forcing 的速度确实来自 few-step AR diffusion 和 KV cache;第二,它不是用质量换速度,VBench 与 user preference 都显示它至少在短视频范围内能接近甚至超过 Wan2.1 这样的慢速模型。
但也要注意,VBench 是短视频评测。原版 Self Forcing 自己的 limitation 也承认:当生成长度显著超过训练 context length,质量退化仍然存在,梯度截断也可能限制长程依赖学习。这正是 Self-Forcing++ 要接上的地方。
Self-Forcing++:长视频不是把 rolling KV 开大就行
Self-Forcing++ 的出发点是:原版 Self Forcing 能缓解短视频 exposure bias,但它的 teacher 和训练目标仍然集中在约 5 秒窗口内。推理时如果让 student 生成 50 秒、100 秒,前 5 秒后的状态并没有被充分训练。论文观察到这些长 rollout 通常不是马上完全崩,而是先保留结构、随后出现 motion stagnation、过曝或变暗、局部语义漂移。
这说明问题不只是模型不会自回归,而是 long-horizon rollout 中的误差状态没有被 teacher 纠正过。
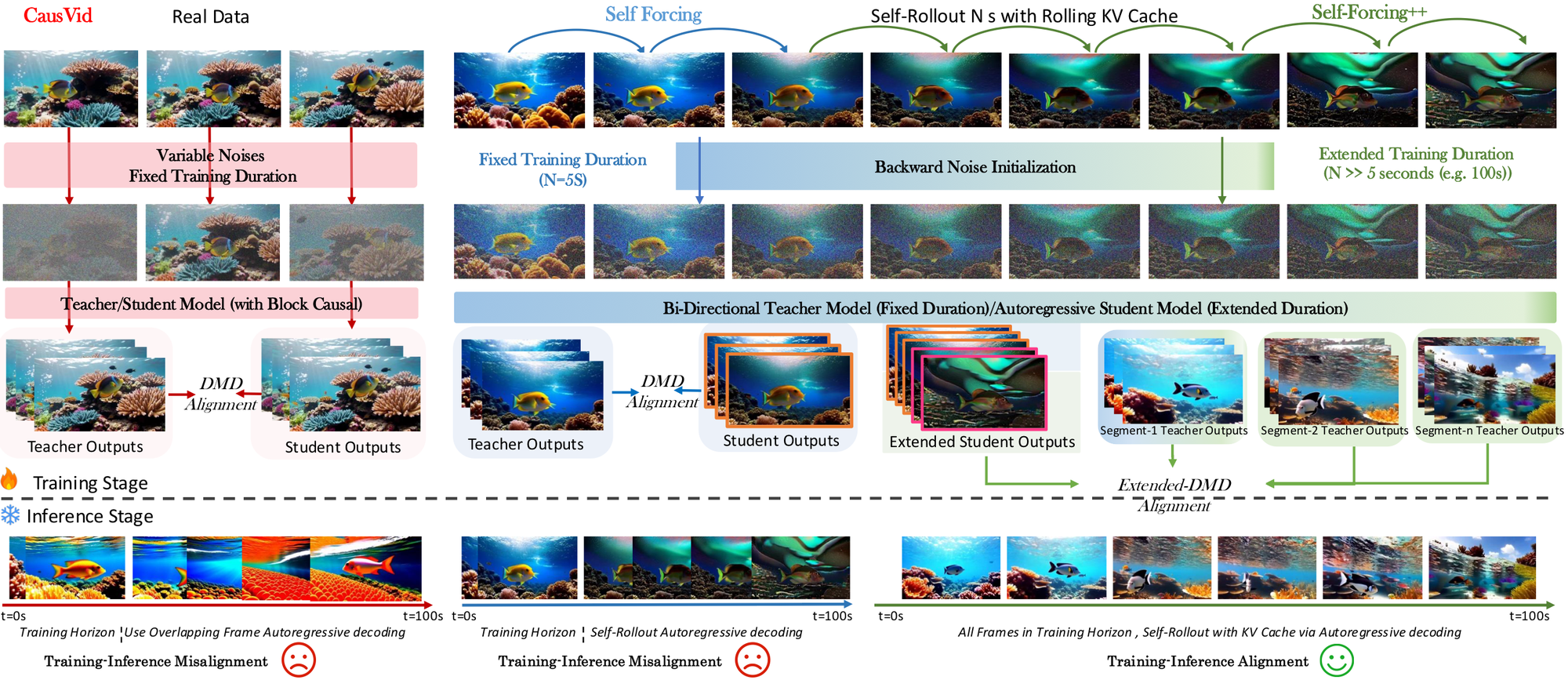
图 3:Self-Forcing++ 的 workflow。它让 student 使用 rolling KV cache 自己生成长序列,再对其中局部窗口做 backward noise initialization 和 extended DMD,使短视频 teacher 能纠正长 rollout 里的退化片段。
Extended DMD:用短 teacher 监督长 rollout 的局部窗口
Self-Forcing++ 不要求 teacher 直接生成 100 秒视频。它的假设是:虽然 teacher 只有短 horizon 生成能力,但任意一段合理长视频中的短窗口都应该服从短视频的局部数据分布。于是训练流程变成:
- student 用 rolling KV cache rollout 出长序列 $V$,长度 $N \gg K$;
- 从 $V$ 中均匀抽一个连续窗口 $W = V[i:i+K-1]$;
- 对窗口做 backward noise initialization,把干净 student rollout 重新加噪;
- 用 teacher 和 student 在该窗口上的 score 差做 DMD;
- 可选地用 optical-flow reward 做 GRPO,压制突变和不平滑运动。
窗口采样可以写成:
\[i \sim \mathrm{Uniform}\{1,\dots,N-K+1\}, \quad W = V[i:i+K-1]\]Extended DMD 的直观目标是:
\[\nabla_{\theta}\mathcal{L}_{\mathrm{DMD,extended}} \approx -\mathbb{E}_{t,i}\left[ \left(s^T(\Phi(G_\theta(W_i),t),t)-s^S_\theta(\Phi(G_\theta(W_i),t),t)\right) \frac{dG_\theta(W_i)}{d\theta} \right]\]不必纠结这个式子的每个符号,关键是 $i$ 不是固定在前 5 秒,而是从 long rollout 里抽窗。teacher 纠正的是 student 已经进入长视频误差状态后的局部片段。
Backward Noise Initialization:为什么不能从纯随机噪声开始
如果从纯随机噪声开始做窗口蒸馏,窗口会和前后上下文断开,teacher/student 对齐只是在短片段里成立,不能反映 long rollout 的历史依赖。Self-Forcing++ 先让 student 生成 clean rollout,再把噪声加回这些 latent 上,把它们变成扩散时间步 $t$ 的输入。论文给出的形式是:
\[x_t = (1-\sigma_t)x_0 + \sigma_t \epsilon, \quad \epsilon \sim \mathcal{N}(0,I)\]这样做的意义不是普通 data augmentation,而是保留 long rollout 的语义和时序结构,同时让 teacher 能在 noisy state 上提供 DMD correction。
Training with rolling KV cache:把 cache 状态也对齐
原版 Self Forcing 已经使用 rolling KV 做推理,但训练中仍可能存在固定 cache 与 rolling cache 的状态差异。Self-Forcing++ 把 rolling KV cache 直接放进训练 long rollout,训练和推理都在同一类 cache dynamics 下运行。这样它不再需要 CausVid 那种 recomputing overlapping frames,也不依赖额外的 latent frame masking 来近似推理状态。
这是 Self-Forcing++ 比“简单延长生成”更有意义的地方:它训练的是模型在真实长视频推理状态下的恢复能力。
直观效果:分钟级 horizon scaling
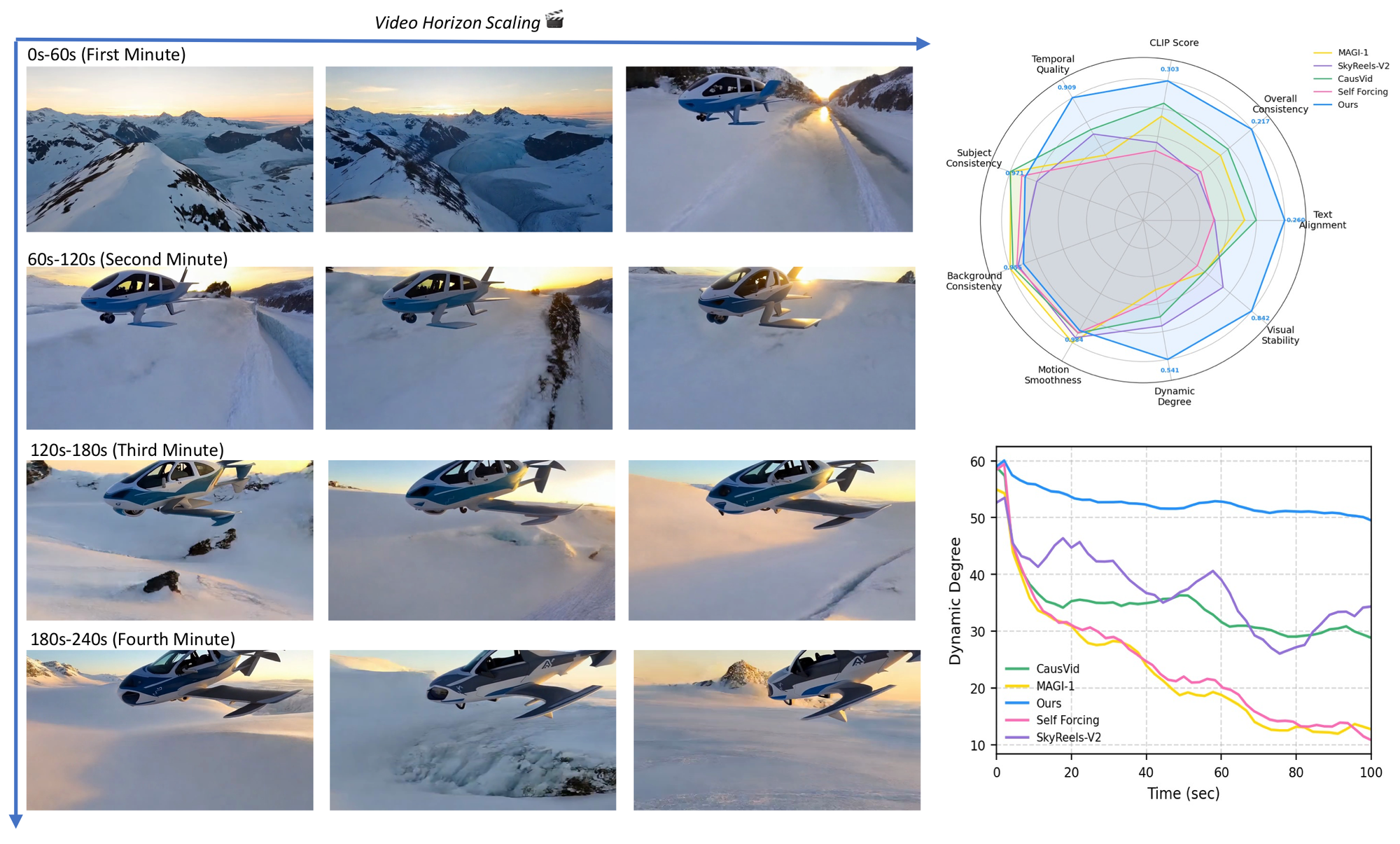
图 4:Self-Forcing++ teaser。左侧展示分钟级生成中的帧,右侧展示长视频评价维度和 dynamic degree 随时间变化。论文声称在更高训练预算下可生成 4 分 15 秒视频。
Self-Forcing++ 的实验把短视频和长视频分开看。短视频 5 秒上,它没有显著牺牲原版质量;真正差异在 50 秒、75 秒、100 秒。
| Horizon | 指标 | CausVid | Self Forcing | Self-Forcing++ |
|---|---|---|---|---|
| 50s | Text Alignment | 25.25 | 24.77 | 26.37 |
| 50s | Dynamic Degree | 37.35 | 34.35 | 55.36 |
| 50s | Visual Stability | 40.47 | 40.12 | 90.94 |
| 100s | Text Alignment | 24.41 | 22.00 | 26.04 |
| 100s | Dynamic Degree | 34.60 | 26.41 | 54.12 |
| 100s | Visual Stability | 39.21 | 32.03 | 84.22 |
这组数字的含义是:baseline 在 long horizon 上并非完全不会生成,而是经常通过“动得少”维持部分 temporal quality 分数;Self-Forcing++ 的 dynamic degree 和 visual stability 同时更高,说明它的长视频不只是更稳定,也更不容易冻结。

图 5:Self-Forcing++ 的 training budget scaling。论文报告从 1x 到 25x budget,长时生成能力逐步提升;25x 设置展示了 255 秒生成样例。
数据全流程:输入、表示、训练和评测
| 阶段 | 数据 / 表示 | Self Forcing | Self-Forcing++ |
|---|---|---|---|
| Prompt | text prompt | VidProM 的 VidProS 子集,过滤短 prompt、命令参数和 NSFW,再用 Qwen/Qwen2.5-7B-Instruct 扩写 | 论文未完整公开同等细粒度 prompt 过滤流程,评测使用 VBench 与 MovieGen prompt set |
| Video latent | VAE latent | Wan2.1 causal 3D VAE latent,论文没有在正文固定 $C_{\ell}, H_{\ell}, W_{\ell}$ | 同基座 Wan2.1-T2V-1.3B |
| Base initialization | teacher/student | Wan2.1-T2V-1.3B 经过 CausVid-style ODE solution pair 初始化成 causal student | bidirectional teacher + autoregressive student,沿用 CausVid/Self Forcing 转换思路 |
| Training rollout | model-generated history | 训练时 self-rollout,KV cache 来自模型自己生成的历史 | 长 rollout,$N$ 远大于 5 秒,训练和推理都使用 rolling KV cache |
| Loss | distribution matching | DMD / SiD / GAN;DMD 和 SiD 可不需要真实训练视频,GAN 使用 14B base 生成 70k videos | Extended DMD;从 long rollout 里抽 5 秒窗口;可选 GRPO + optical-flow reward |
| Evaluation | benchmark | VBench、user preference、FPS、latency、rolling KV ablation | 5s VBench、50/75/100s VBench Long、Gemini-2.5-Pro Visual Stability |
这里最容易被忽略的是 prompt rewriting。Self Forcing appendix 明确说 VBench prompt 也用 Qwen/Qwen2.5-7B-Instruct 重写,并且在 baseline 支持的情况下也报告 prompt rewriting 后结果。因此复现数值时不能只跑原始 VBench prompt,否则比较未必公平。
Training:两个版本的训练机制对照
Self Forcing 的训练目标是短 horizon 内的 train-test alignment:
- sample prompt;
- 初始化空 KV cache;
- 对每个 frame/chunk 从 noise 开始 few-step denoise;
- 当前输出写入 $\hat{x}^{1:N}$,同时计算 K/V 放入 cache;
- 对完整生成视频加噪,并用 DMD/SiD/GAN 匹配数据或 teacher distribution。
Self-Forcing++ 的训练目标是长 horizon 的 error recovery:
- 用 student 和 rolling KV cache rollout 出长视频 $V$;
- 从 $V$ 随机抽局部窗口 $W$;
- 对 $W$ 做 backward noise initialization;
- 用短 horizon teacher 计算局部分布纠错信号;
- 继续把这个纠错反馈给 student,让它学会在长 rollout 的退化状态中恢复。
我的理解是,Self Forcing 更像“让模型习惯自己犯的小错”,Self-Forcing++ 更像“故意把模型带到长视频累计误差状态,再训练它从这些状态里回来”。
Inference:测试时到底怎么生成
两篇论文的推理流程都围绕 causal DiT + few-step diffusion + KV cache:
- 输入 text prompt,经过文本编码器得到 conditioning;
- 初始化空 KV cache;
- 对当前 frame/chunk 初始化 Gaussian noise latent;
- 用当前 noise、timestep、text condition、history KV 做 few-step denoise;
- 得到 clean latent 后,计算并追加该 chunk 的 K/V;
- rolling cache 满时丢弃最旧 entries;
- VAE decode 输出视频帧或 chunk。
区别在于,Self-Forcing++ 的训练已经让模型见过这个 rolling cache 长时状态,因此推理到 50 秒、100 秒时,不再只是依赖原版短 horizon 的泛化。
Evaluation:VBench 的局限与 Visual Stability
Self-Forcing++ 对 VBench 提了一个重要质疑:VBench 的 image / aesthetic 子指标可能会高估过曝或已经退化的长视频帧。长视频里,模型冻结、变亮、变暗、纹理崩掉,有时反而不会在 framewise aesthetic 上被足够惩罚。
论文因此引入 Gemini-2.5-Pro 作为 video MLLM evaluator,定义过曝、误差累积等长视频问题,让模型按 0 到 100 聚合成 Visual Stability。这个设计有现实意义,但也带来复现风险:它依赖闭源评测模型、prompt 设计和视频采样方式。对学术 benchmark 来说,这比纯开放指标更难完全复刻。
所以我的判断是:Self-Forcing++ 的趋势性结论可信,尤其是 long horizon 下 dynamic degree 和 visual stability 的大幅差距;但如果要把它作为严格 SOTA 证据,仍需要看公开视频、评测 prompt、Gemini evaluator prompt 和采样脚本是否完整公开。
实验与证据:哪些 claim 被支持,哪些还不够
Claim 1:Self Forcing 缓解短视频 AR diffusion 的 exposure bias。
证据较强。它和 CausVid 使用相近 1.3B base 与吞吐条件,VBench total 从 81.20 提到 84.31,并在 user preference 中胜过多个 baseline。ablation 也显示 DMD、SiD、GAN 三种 distribution matching objective 都能让 Self Forcing 优于 TF/DF baseline。
Claim 2:Self Forcing 可以做到 real-time streaming。
证据较强但边界明确。17 FPS 和 0.69s latency 是单 H100、chunk-wise、832 x 480、1.3B 模型、4-step diffusion 条件下的结果。它说明方法有实时潜力,但不是任意分辨率、任意设备都能实时。
Claim 3:Self-Forcing++ 能显著改善 50s 到 100s 长视频质量。
证据较强。100s 下 visual stability 从 Self Forcing 的 32.03 提到 84.22,dynamic degree 从 26.41 提到 54.12,这说明它不是只靠冻结画面维持一致性。
Claim 4:可扩展到 4 分 15 秒。
证据是 demo 和 scaling figure,属于强展示但弱可复现实验。它非常有启发性,但要转成可复现结论,需要完整训练预算、checkpoint、采样配置和评测脚本。
复现与工程风险
第一,训练成本不低。Self Forcing appendix 里 DMD 训练约 1.5 小时收敛,但配置是 64 张 80GB GPU;SiD/GAN 为 2 到 3 小时。即便只是 post-training,也不是普通单卡能复现的实验。
第二,loss 依赖 teacher / score / critic 网络。DMD 需要 real score network 和 fake score network,论文里 DMD 使用 Wan2.1-T2V-14B 作为 real score network,critic 初始化来自 Wan2.1-T2V-1.3B。复现时这些模型版本、CFG weight、timestep schedule、prompt rewriting 都会影响结果。
第三,长视频评测仍然是开放问题。Self-Forcing++ 指出 VBench 会误判长视频质量,这是合理批评;但 Gemini-2.5-Pro Visual Stability 本身又引入闭源 evaluator。工程上更稳的做法是同时保留公开视频、人工评测、motion/consistency 指标、MLLM judge prompt 和失败案例,而不是只看一个总分。
第四,长程记忆没有彻底解决。Self-Forcing++ limitation 里也承认,模型仍然继承 Wan2.1-T2V-1.3B 的能力边界,长期遮挡区域可能发生 content divergence。rolling KV 是短中期上下文机制,不等于真正的可检索长程记忆。
这条路线对后续工作的启发
我觉得 Self-Forcing 系列最值得带走的不是某个具体公式,而是一个训练原则:
sequential generative model 应该尽量在训练时暴露给它推理时会遇到的状态分布。
这在 LLM 里对应 RL / self-play / on-policy correction,在视频扩散里对应 self-rollout + distribution matching。对后续 long video generation、interactive world model、game simulation、robotics imagination,都有直接启发。
可能的继续方向有三类:
- 更便宜的 self-rollout training:减少 64 H100 级别训练成本,让 post-training 可被更多团队复现;
- 更开放的 long-video benchmark:解决 VBench 长视频误判,同时避免完全依赖闭源 VLM judge;
- 真正的 long-term memory:rolling KV 只能保留窗口内 token,几分钟生成需要更稳定的 identity、object permanence 和 scene memory。
总结
Self Forcing 把 AR video diffusion 的核心矛盾讲清楚了:速度问题可以靠 few-step 和 KV cache 缓解,但质量问题必须处理 train-test gap。它通过训练时 self-rollout 和视频级 distribution matching,让模型在自己的生成分布上被监督,因此短视频实时生成的质量和 latency 都有明显改善。
Self-Forcing++ 则把问题往前推进了一层:短 horizon 训练仍然不足以支撑分钟级生成。它让 student 自己滚出长序列,再用短 teacher 对长序列里的局部退化窗口做 extended DMD,实质上是在训练“长视频误差状态的恢复能力”。从实验看,这个方向确实比简单 rolling KV 或 overlap recomputation 更接近长时稳定生成。
但这条路线也还没有完全闭环。训练成本、闭源评测、长期记忆、代码和模型公开程度,都会影响它从漂亮论文走向可复现工程系统。作为研究方向,它最重要的贡献是把视频扩散从“短片离线生成”推向“按推理方式训练的流式序列生成”。
参考链接
- Self Forcing: arXiv, PDF, NeurIPS 2025 proceedings, Project, Code
- Self-Forcing++: arXiv, PDF, ICLR 2026 OpenReview, Project, Code