
DiT4SR: Taming Diffusion Transformer for Real-World Image Super-Resolution
发布时间:
[Paper Reading] 基于 Diffusion Transformer 的真实世界超分辨率方法 DiT4SR
1. 研究问题与 Motivation
Real-World Image Super-Resolution (Real-ISR) 与传统 SR 最大的区别是:真实世界 LR 图像的退化过程复杂、多样且难以建模(模糊、压缩、噪声、非线性退化等),需要模型不仅能恢复结构,还要生成自然、高保真的细节。
近年来,Stable Diffusion(SD1/2/XL)凭借海量预训练数据的强先验,被大量用于 Real-ISR。但这些方法均依赖 UNet 架构 + ControlNet 注入 LR 条件。
与此同时,基于 DiT(Diffusion Transformer)的新一代模型(如 SD3、Flux)开始在生成图像任务显著超越 UNet。DiT 的核心优势包括:
- transformer 更强的全局建模能力
- 多模态交互模块(MM-DiT)允许文本与图像 latent 双向交互
- 更容易规模化(scaling laws 更好)
于是一个自然的问题出现:
能否利用 SD3 中的 DiT 架构来做 Real-ISR?并且效果能否超过 UNet-based SD?
然而直接把 ControlNet 套到 DiT 上会遇到明显问题:
- ControlNet originally designed for UNet
- 只能实现 单向信息流(LR → Noise latent)
- 无法让 LR latent 与生成 latent 在 DiT 内部充分耦合交互
- DiT 全局 attention 缺乏局部感受野,不利于恢复精细结构
ControlNet 注入和本文方法的示例: 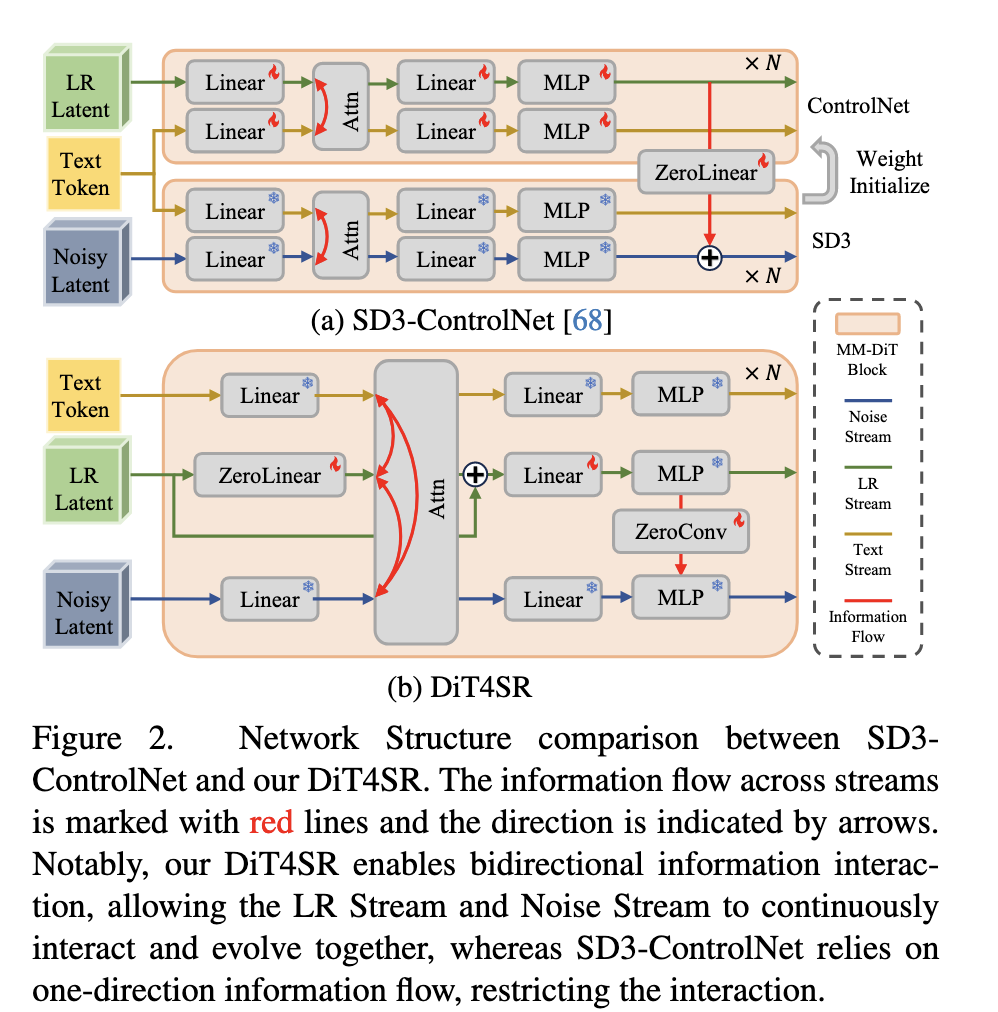
因此论文提出:
如何 “驯服” DiT,使其能够有效用于真实世界超分辨?
2. 核心贡献(Contributions)
论文的核心贡献可以总结为三点:
2.1 在 DiT 内部增加一个 LR Stream
不同于 ControlNet 复制模块、独立注入的方式,作者将 LR latent 直接集成到每个MM-DiT block 内部,创建三路流:
- Noise Stream(原 diffusion latent)
- Text Stream
- LR Stream(新加入)
并且在 Attention 中融合三路 token,使其能够:
实现 LR latent 与生成 latent 的 双向交互(bidirectional interaction)。
2.2 LR 信息通过 Attention + Residual 共同稳定注入
为避免 LR 信息在深层 attention 中逐渐衰减,论文提出:
- LR Residual path:确保 LR latent 在深层 DiT block 中仍保持稳定、连续的指导能力。
2.3 LR Injection via Convolution(局部信息注入)
DiT 只靠 global attention 缺乏局部建模,因此作者在 MLP 中引入:
- 3×3 depth-wise convolution
- 并且将 MLP 的中间特征 \(\eta(L)\) 注入到 \(\phi(X)\)(Noise Stream)内
从而增强局部细节恢复,尤其对文字,建筑结构,边缘细节显著有提升。
论文证明:
线性层注入不如卷积注入效果好。 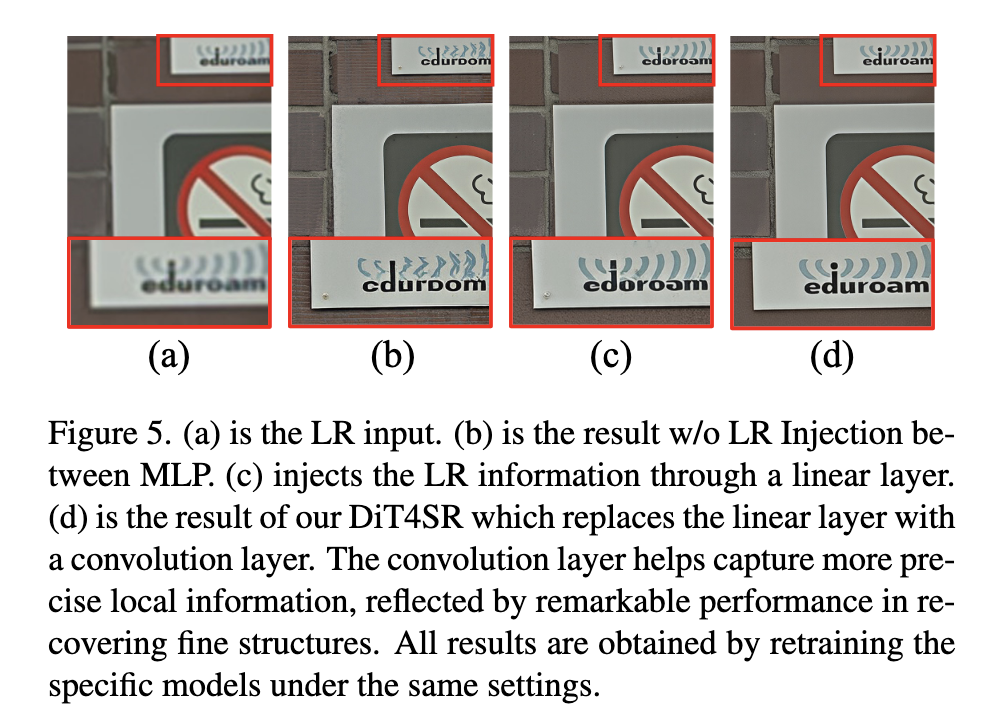
3. 方法整体结构(Architecture)
整体结构如下: 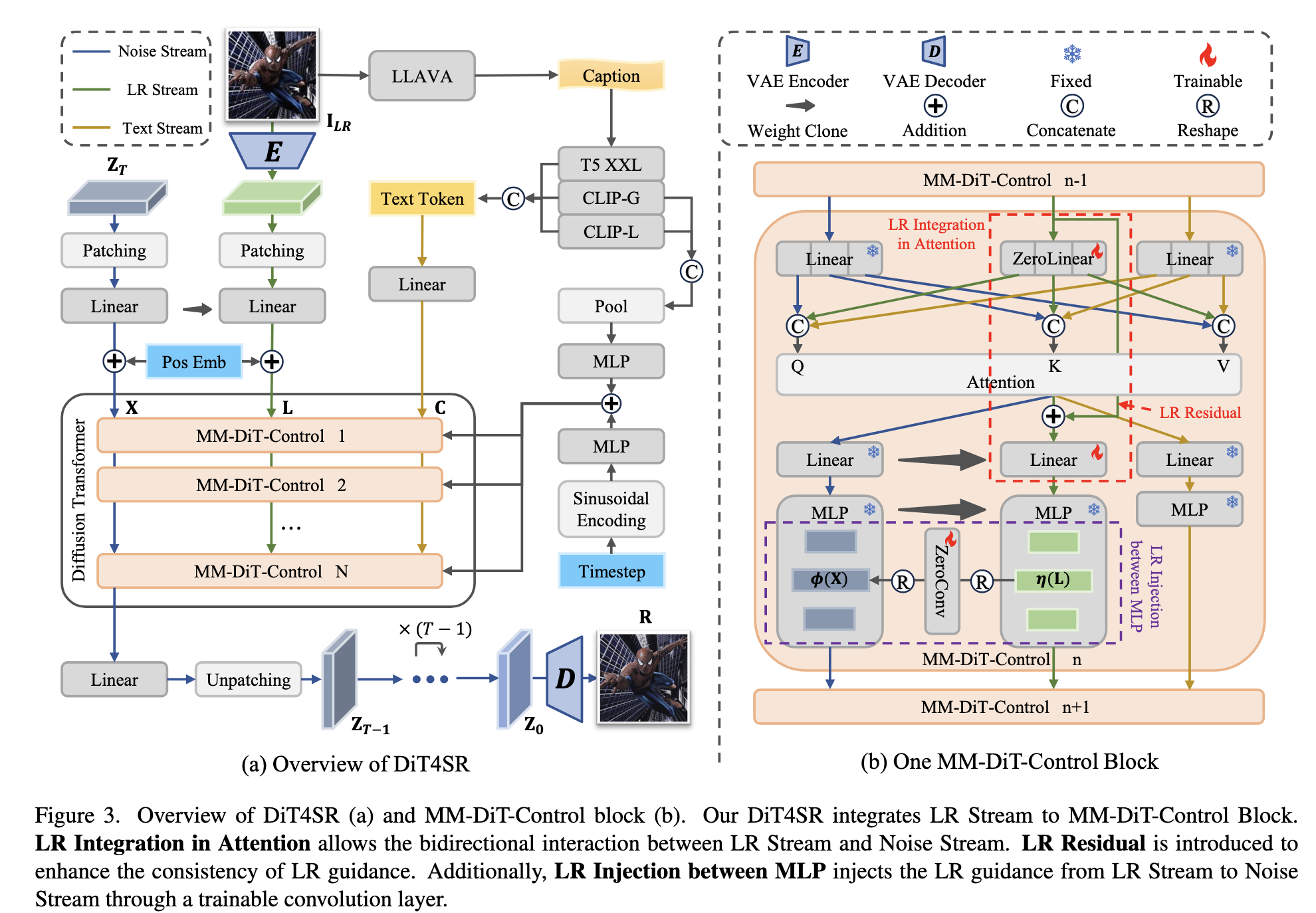
整体流程如下:
- LR 图像 \(I_{LR}\) → VAE Encoder → LR latent
- LR latent flatten + patch embedding → LR tokens
- Diffusion latent \(Z_t\) patch embedding → Noise tokens
- 文本 caption 编码 → Text tokens(CLIP-L, CLIP-G, T5-XXL)
- 三路 token 进入 N 个 MM-DiT-Control blocks
其中特别设计的模块包括:
- LR Integration in Attention
- LR Residual
- LR Injection between MLP
最终得到 \(Z_0\),通过 VAE decoder 输出 HR 图像。
4. 模型结构设计细节
4.1 三路 Token 在 Attention 中的融合
三种 token 分别通过三套 Q/K/V 投影:
\[Q = P^X_Q(X) \mathbin{\|} P^L_Q(L) \mathbin{\|} P^C_Q(C)\]K/V 同理。
关键点:
- LR 的线性投影初始权重为零(Zero-Init),保证模型初期不会破坏预训练权重。
- Attention map 可视化显示:
LR ↔ Noise 的 cross attention 非常明显,方向是双向的。
4.2 LR Residual
为解决 “deep blocks 中 LR 信息逐渐衰减”,作者为 LR Stream 添加 residual:
\[L_{\text{out}} = \text{Attention}(...) + L_{\text{in}}\]该路径显著增强了深层 block 的稳定性。
4.3 LR Injection between MLP(卷积注入)
MLP 前向:
Noise Stream: \(\phi(X) \in \mathbb{R}^{K \times 4D}\)
LR Stream: \(\eta(L) \in \mathbb{R}^{K \times 4D}\)
将 LR 特征 reshape 成 feature map,然后:
- 做 depth-wise 3×3 conv
- 再 reshape 回 token
- 注入到 Noise MLP
卷积提供了:
- 局部感受野
- 更强的细节恢复能力
- 避免纯 attention 带来的文字结构模糊
实验(Figure 5)清楚体现:
- 线性层无法恢复文字
- 卷积能够恢复字母形状
5. 训练数据与预处理
训练集来自合成退化:
- DIV2K
- DIV8K
- Flickr2K
- FFHQ(前10K face images)
- +1K作者自采高分辨率照片
退化模型采用 Real-ESRGAN 的 pipeline,与 SeeSR 保持一致。
训练分辨率:
- LR: 128×128
- HR: 512×512(倍率 ×4)
6. 训练流程(Diffusion Training)
扩散在 latent 空间进行,与 SD3 过程一致:
- forward: 加噪 \(Z_0 → Z_t\)
- reverse: 预测 \(Z_0\) 或 \(v\)(论文沿用 SD3 原本的目标)
条件包括:
- Timestep embedding
- Text embedding(CLIP + T5)
- LR token(本工作引入)
Loss 沿用 SD3 的 diffusion loss,论文未特别修改:
\[\mathcal{L} = \mathbb{E}_{Z_0, t, \epsilon} \left[ \| \epsilon_\theta(Z_t, t, L, C) - \epsilon \|^2 \right]\]7. 推理流程(Inference)
推理完全遵循 SD3 采样流程(多步扩散),只需要:
- 输入 LR
- 编码成 latent
- 通过 DiT4SR 多步采样
- 解码得到 HR
8. 实验设置与结果
8.1 Benchmark
四大 Real-ISR 数据集:
- DrealSR
- RealSR
- RealLR200
- RealLQ250
指标:
- LPIPS(图像保真度)
- MUSIQ、MANIQA、ClipIQA、LIQE(无参考指标)
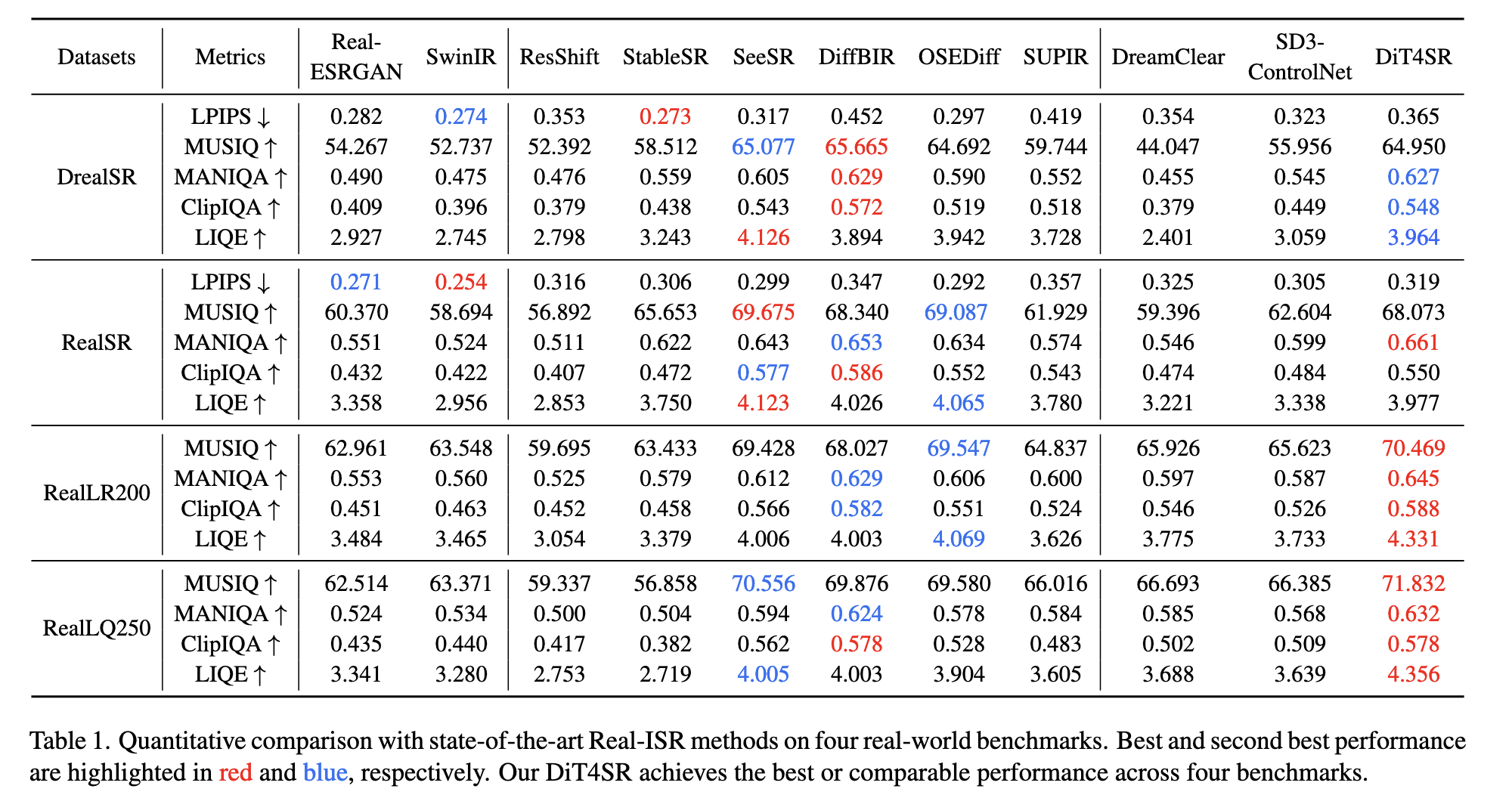
8.2 与 SOTA 对比
对比方法包括:
- Real-ESRGAN, SwinIR(传统)
- StableSR, SeeSR, DiffBIR, SUPIR(UNet-based diffusion)
- DreamClear(DiT + ControlNet)
- SD3-ControlNet(作者复现的 baseline)
结果:
- DiT4SR 在 RealLR200、RealLQ250 数据集 全面第一
- 在 DrealSR 与 RealSR 也达到 SOTA 或非常接近
- 视觉质量明显优于 UNet-based 系列(特别是细节与文字)
尤其重要的是:
在相同 SD3 backbone 下,DiT4SR 明显优于 SD3-ControlNet,证明结构设计的必要性。

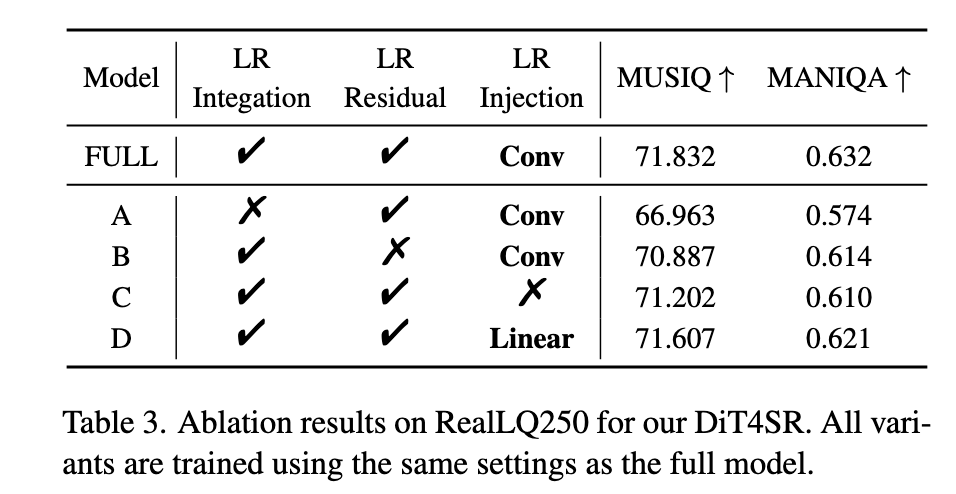
9. 消融实验(Ablation Study)
对主要模块分别移除或替换:
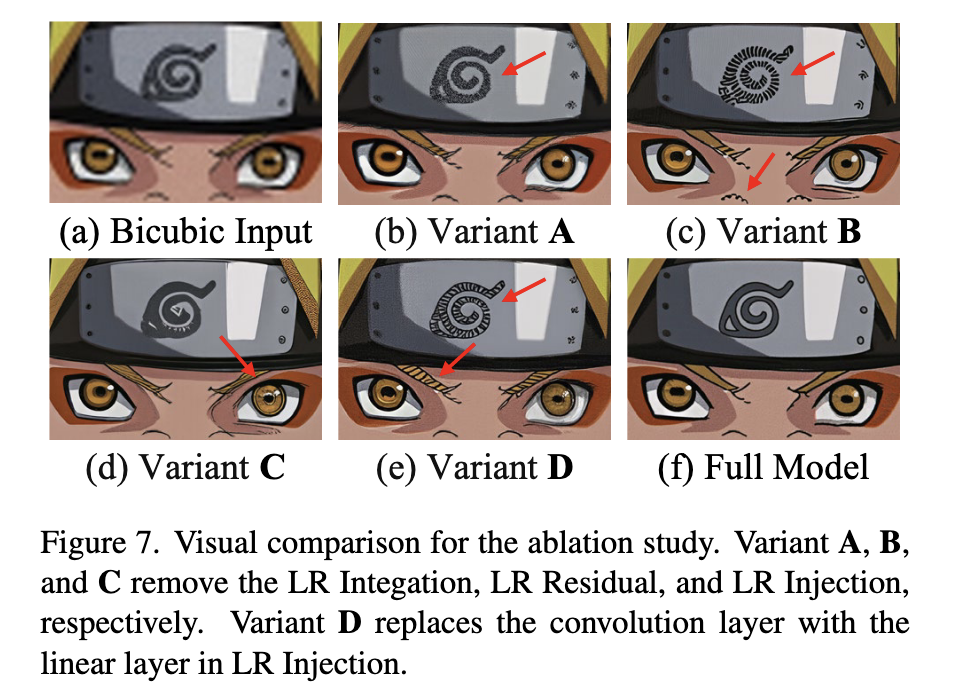
9.1 移除 LR Integration(Variant A)
性能明显下降 → 证明 attention 内双向交互是关键组成。
9.2 移除 LR Residual(Variant B)
深层出现 artifact → 证明 residual 对稳定 LR Stream 至关重要。
9.3 移除 LR Injection(Variant C)
细节不足(尤其文字)→ 单靠 attention 不够恢复局部结构。
9.4 将卷积替换为线性层(Variant D)
文字结构仍然模糊 → 卷积更适合 local detail 恢复。
10. 全文总结与未来方向
10.1 总结
DiT4SR 是第一批成功将 大规模 Diffusion Transformer (SD3/DiT) 应用于 Real-ISR 的方法。论文的关键发现是:
- LR Stream 应直接嵌入 DiT block,而非 ControlNet 式的外接网络
- 双向 attention 是高质量恢复的关键
- 卷积注入能弥补 DiT 的弱局部感知能力
最终使 DiT4SR 在多个真实数据集上达到 SOTA 级别。