
Efficient Rectified Flow for Image Fusion
发布时间:
[Paper Reading] Efficient Rectified Flow for Image Fusion(RFfusion)论文解读
文章整体框架图如下: 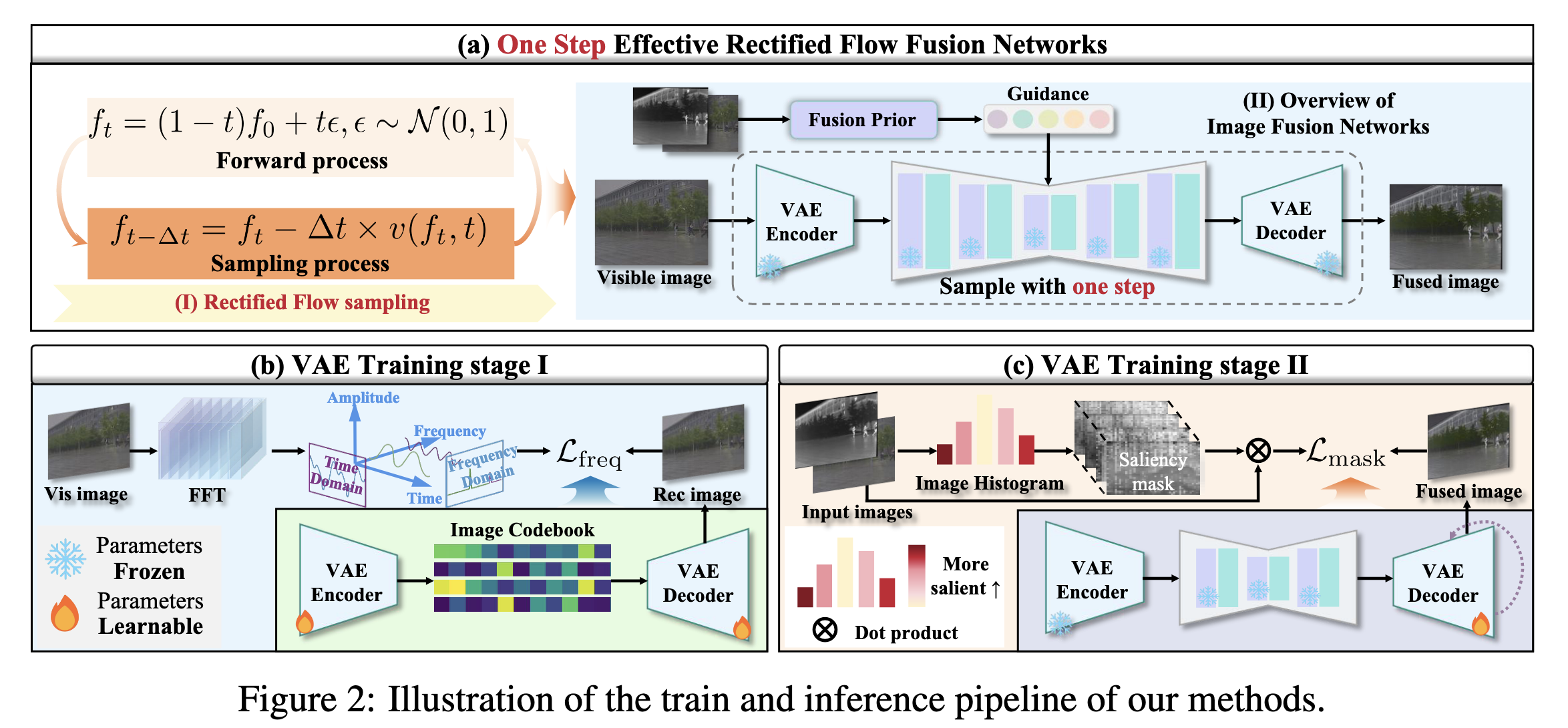
1. 论文要解决什么问题(Problem)与出发点(Motivation)
图像融合(Image Fusion)典型场景包括红外-可见光(IR-VIS)融合、多曝光融合(MEF)、多焦点融合(MFF)。该任务的核心矛盾在于:融合结果并不存在唯一“正确答案”,因此数据集通常只提供输入对(例如 \(I_{ir}\) 与 \(I_{vis}\)),而不提供严格意义上的融合 GT \(I_{f}^{gt}\)。传统方法多依赖手工先验(如 TV、梯度/显著性约束)或轻量网络监督,而近年扩散模型能提供更强的生成先验,但推理成本高、采样步数多,难以部署。
本文的出发点是:能否利用一个强大的“通用生成先验”,在推理阶段通过一个明确的融合先验(fusion prior)进行校正,从而做到极少步(甚至一步)采样的高质量融合?
作者给出的答案是:用 Rectified Flow(RF)作为通用生成先验框架,并引入可插拔融合先验,使融合在推理阶段发生。
2. 核心贡献点(Contributions)
从论文表述与代码实现综合来看,本文的贡献可以分成“论文层面”和“实现层面”两条主线:
1) 论文层面:将 Rectified Flow 引入融合任务,并主张“无需额外训练即可一步采样融合”。
直觉是:RF 的路径更“直”(线性插值式),使得少步 Euler 近似更有效。
2) 系统层面:将融合任务拆成三部分协作:
- 预训练 RF 生成模型:提供自然图像分布先验(不在融合数据上训练)。
- 可插拔融合先验:在推理中强制输出满足 IR-VIS 一致性。
- VAE(尤其 decoder):负责把被校正后的表示解码成视觉可用的融合结果。
3) 代码层面(非常关键):融合先验并非以 \(\nabla \log p(I_{ir}, I_{vis} \mid x)\) 的显式梯度形式注入速度场,而是以“对 \(x_0\) 的一次显式优化修正(EM/TV 先验)”注入采样链路。这使其更接近“\(x_0\) 级 Plug-and-Play prior + posterior 更新”的实现范式。
3. 相关工作与局限性:本文优化点在哪里
1) 扩散融合方法(如 DDFM/CCF 系列)的局限:
- 强质量但采样步数多,推理耗时大;
- 少步采样会显著劣化融合质量;
- 部署成本高。
2) 蒸馏/一致性类 one-step 的局限:
- 往往需要额外训练或蒸馏;
- 训练代价大且不够通用;
- 对任务迁移不稳定。
3) 传统手工先验融合(TV、梯度、显著性)局限:
- 结果可能不够“自然”、存在伪影;
- 对复杂场景鲁棒性不足;
- 难以获得高层语义一致性。
本文的优化点在于:
- 使用 RF 作为通用生成先验,保证输出接近自然图像流形;
- 用可解释的融合先验对结果进行约束,保证融合一致性;
- 通过 VAE 将推理成本压到 latent / 图像空间可控范围,并稳定融合输出。
4. 方法整体结构(Overall Framework):论文图与代码的统一解释
整体 pipeline 可以理解为:
- RF 模型(预训练、冻结)提供一个“接近自然图像”的预测结果;
- 融合先验模块对预测结果进行一次校正,使其同时符合 \(I_{ir}\) 与 \(I_{vis}\);
- VAE decoder 输出最终融合图。
其中最关键的是:融合先验并不需要融合 GT,而是通过与输入对的一致性(以及结构先验)来约束。
5. Rectified Flow:论文中的核心原理
Rectified Flow 将从 \(x_0\) 到噪声 \(\epsilon\) 的路径“直线化”,常见形式是:
- 前向:\(x_t=(1-t)x_0 + t\epsilon\)
- 网络学习一个速度场 \(v_\theta(x_t,t)\),用于从噪声端向数据端回推(ODE 视角)。
论文叙述的关键点是:路径更直意味着数值积分可用更少步逼近,从而支撑“极少步(甚至一步)”采样。
但在具体仓库实现中,采样并非纯粹的“只用 ODE 速度场一步走完”,而是叠加了融合先验对 \(x_0\) 预测的显式修正(见第 7 节)。
6. “没有训练”的 RF 模型从哪来:配置文件反推
仓库配置清楚表明 RF 模型并非在融合数据上训练:
- model.name = ncsnpp:这是经典 score-based 生成模型 backbone;
- training.sde = rectified_flow:表示其训练目标为 RF;
- sigma_max、sigma_min、num_scales 等参数更符合通用自然图像生成设定;
- model.path 指向 checkpoint_12.pth:推理阶段直接加载预训练权重并冻结。
因此,RF 在本文系统中扮演的是“通用生成先验”,而不是“融合网络”。
7. 代码级关键:fusion prior / guidance 是如何加进来的
这是本文最容易被误解、但也最关键的工程事实:融合先验在仓库中通过一个显式优化算子注入采样链路,核心特征如下。
7.1 先验注入的位置:加在 \(x_0\) 预测上,而非速度场上
采样代码中,模型输出被直接当作 \(x_0\) 的预测值(或等价的“干净图像估计”),随后对其进行融合先验修正。也就是说,先验修改的是 \(\hat{x}_0\),而不是显式修改 \(v_\theta\) 或 score。
这种接口与 Plug-and-Play diffusion / posterior sampling 的经典套路一致:
- 先验先修正 \(\hat{x}_0\);
- 再由扩散解析关系反推 \(\epsilon\);
- 再执行一次 posterior 更新得到新的 sample。
7.2 只在亮度通道做融合:\(Y\) 通道 prior
代码中将预测图转换到 YCbCr,仅对 \(Y\) 通道(亮度)施加融合先验:
- IR-VIS 融合中,IR 主要提供强度/结构;
- VIS 提供颜色信息(CbCr);
- 因此在 \(Y\) 上做融合是合理且常见的工程选择。
7.3 EM_onestep:融合先验的本体(非学习、显式优化)
EM_onestep 的核心做法是把融合写成一个显式优化问题,包含:
- 鲁棒数据项:通过像素级权重自适应地决定哪里更需要注入 IR 信息;
- TV 结构先验:通过近端算子(prox)抑制噪声、保边缘;
- FFT 求解:将差分/卷积转到频域实现快速闭式更新。
其中的关键重参数化是以可见光为基准做残差建模:
- 当前预测残差:\(X=\hat{f}-V\)
- IR 相对 VIS 的残差:\(Y=I-V\) 目标是更新 \(X\) 使其逼近 \(Y\),最终回到新的融合亮度图 \(F\)。
从直觉上,这一步做的是:
- 让融合结果同时符合 IR 与 VIS 的一致性;
- 用 TV 保持结构与边缘;
- 用鲁棒权重抑制异常像素导致的过度注入。
因此这里的 “guidance” 更像是一个“可插拔的 MAP / EM 先验修正器”,而不是神经网络式的 learned guidance。
8. VAE:为什么需要、训练什么、训练过程如何(不写公式版本)
虽然论文在叙述上强调 RF 的一步采样,但从系统角度看,VAE 的角色非常关键:它让表示空间稳定、降低成本,并在输出层面决定“融合图长什么样”。
8.1 为什么需要 VAE
- 降低高分辨率图像直接在生成模型上推理的成本;
- 使采样/校正过程在更稳定的表示空间进行;
- decoder 决定了最终输出的可视质量与一致性。
8.2 两阶段训练:Stage I 与 Stage II 的逻辑
Stage I:结构/频域感知预训练
- 输入是单幅图像(IR 或 VIS 都可视为普通训练样本),目标是让 VAE 的编码-解码过程对结构与频率分布更敏感;
- 强调“结构保真”的表示能力,而非融合。
Stage II:融合导向的 decoder 微调(proxy supervision)
- 训练信号不来自融合 GT(数据集本身通常没有),而来自由 IR/VIS 构造的规则性约束(强度、梯度、结构相似、颜色保持、显著性权重等);
- 训练目标是:当表示中包含来自不同模态的信息时,decoder 能以合理方式解码出融合结果;
- 通常 encoder 冻结、decoder 可学习,以保持表示空间稳定、把融合“呈现能力”集中到解码端。
8.3 “有无 fusion GT”的严谨结论
- 严格意义的融合 GT \(I_f^{gt}\):通常不存在;
- Stage II 使用的是 proxy target / rule-based supervision,即从 \(I_{ir}\)、\(I_{vis}\) 自动构造监督信号;
- 因此方法在监督范式上更接近“弱监督/自监督/规则监督”,而不是全监督。
9. 推理(Inference):一步采样为何能跑起来
推理阶段的关键点是“把通用生成先验与融合先验在一步内协同”:
1) RF backbone 给出一个接近自然图像流形的预测; 2) fusion prior 在 \(\hat{x}_0\) 层面对亮度进行一次 EM/TV 修正,使其解释 IR 与 VIS; 3) 通过 posterior update 得到最终 sample; 4) decoder 解码输出融合图。
当配置中 sample_N=1 时,意味着外层采样循环只跑一次(one-step)。此时系统性能高度依赖:
- RF 预测的初值是否足够接近目标解;
- EM_onestep 的修正是否足够强且不引入过度平滑;
- VAE decoder 是否能稳定输出自然且满足融合规律的结果。
10. 实验与消融:如何理解其有效性(以机制解释为主)
从机制上,本文的优势通常来源于三类因素叠加:
1) 生成先验优势:RF backbone 降低了“融合结果不自然/伪影”的概率; 2) 先验约束优势:EM/TV 将融合任务中最关键的结构一致性硬编码到推理中; 3) 表示与解码优势:VAE 的训练(尤其 Stage II)让最终输出更符合融合评价准则(结构、梯度、显著性、颜色)。
消融实验若要“真正说服人”,核心应验证:
- 去掉 EM prior 是否会显著退化融合一致性;
- 仅用 EM prior 不用 RF 是否会显著损伤自然性;
- 不做 Stage II 是否导致解码输出在融合准则上不稳定;
- one-step 是否依赖 RF 初值质量而导致对不同数据域敏感。
11. 局限性(Limitations):论文与代码共同暴露的点
1) RF 不是融合专用
RF backbone 是通用生成模型,未针对融合任务训练,其融合能力并非 learned,而依赖后处理先验与解码器。
2) 融合先验是手工优化器
EM_onestep/TV 是可解释先验,但也意味着:
- 超参数(如 \(\lambda\)、\(\rho\))敏感;
- 可能产生过平滑;
- 对不同场景(低照度、强噪声、运动模糊、跨域成像)需要重新调参。
3) “Rectified Flow guidance”与实现存在表述差距
论文更容易让读者以为先验以 \(\nabla \log p(\cdot)\) 形式加到速度场,而代码中是 \(\hat{x}_0\) 级 PnP 修正。两者思想相通,但实现范式不同,写作上容易引起理解偏差。
12. 对相关领域的建议与未来方向(Future Work)
1) 将融合先验 learnable 化
用可学习模块替代或增强 EM/TV 先验,使其从数据中学习“何处该信 IR / 何处该信 VIS”,并保持可控性与稳定性。
2) 更严格的 RF 条件化/任务适配
当前 RF 仅作为通用先验。一个自然方向是让 RF 具备对融合输入的条件能力,例如显式条件 \(I_{ir}\)、\(I_{vis}\),或在 latent 层做轻量适配(LoRA/adapter)以提升一步质量。
3) 从 \(x_0\) 级 PnP 到速度场级 guidance 的统一
当前实现走的是 \(\hat{x}_0\) 修正路径。未来可以探索将可微 prior 显式注入 \(v_\theta\)(或等价的 score/velocity),获得更一致的理论表达与可控的优化行为。
4) 面向真实工程的鲁棒性与可解释评估
融合缺乏唯一 GT,因此需要更可靠的无参考评价体系、与下游任务一致性(检测/分割/跟踪)指标结合,避免单纯追逐传统融合指标。
13. 全文总结(Takeaways)
Efficient Rectified Flow for Image Fusion 的核心价值并不只是“用 RF 一步采样”,更在于提出并实现了一种系统化融合范式:
- 预训练通用生成模型作为自然性先验;
- 可插拔融合先验在推理阶段施加一致性约束;
- VAE(尤其 decoder)承接并稳定输出融合结果;
- 在 one-step 配置下仍可获得可用融合质量。
从代码还原角度,本文更准确的技术定位是:
- \(\hat{x}_0\) 级 Plug-and-Play prior(EM/TV) + posterior 更新,
- RF backbone 提供强初始化/流形约束,
- 共同实现高效融合推理。
这套范式对多模态复原/融合、PnP 生成式逆问题、以及“生成模型用于真实任务落地”都具有直接参考意义。