
Stable Video-Driven Portraits
发布时间:
[Paper Reading]:Stable Video-Driven Portraits — 基于 DiT 的高保真视频驱动人像生成
来源:Stable Video-Driven Portraits 核心亮点:Stability AI最近放出了一篇视频驱动单图的文章,但是还没有开源,基于 Stable Diffusion 3.5 Medium (DiT) 架构,通过最小化参数引入和巧妙的数据构造,实现了 SOTA 级别的单图驱动视频生成。
1. 摘要与背景分析
视频驱动人像生成(Video-Driven Portrait Animation)的核心目标是利用一段驱动视频(Driving Video)控制单张源图像(Source Image)的表情和姿态生成视频。
现有痛点:
- 非扩散模型(如 LivePortrait):虽然推理效率高,但往往难以生成高频纹理细节,且在风格化图像(如动漫、素描)上泛化能力较弱。
- 现有扩散模型(如 AniPortrait, X-Portrait):大多基于 U-Net 架构。AniPortrait 依赖稀疏的关键点(Landmarks),导致表情僵硬;X-Portrait 在大姿态变化下容易产生时空伪影(Artifacts)。
本文突破: 本文提出了一种基于 DiT (Diffusion Transformer) 的新框架。核心思想是复用预训练模型的强大先验,通过将源图像和驱动信号直接拼接(Concat)到输入流中,配合全时空注意力机制,实现了高保真、时序连贯且支持跨风格的生成。
2. 核心原理与架构设计
模型基于 Stable Diffusion 3.5 Medium (SD3.5M)。作者没有引入复杂的 ControlNet 式的额外编码器,而是采用了更为直接的 Token Concatenation 策略,整体结构如下:
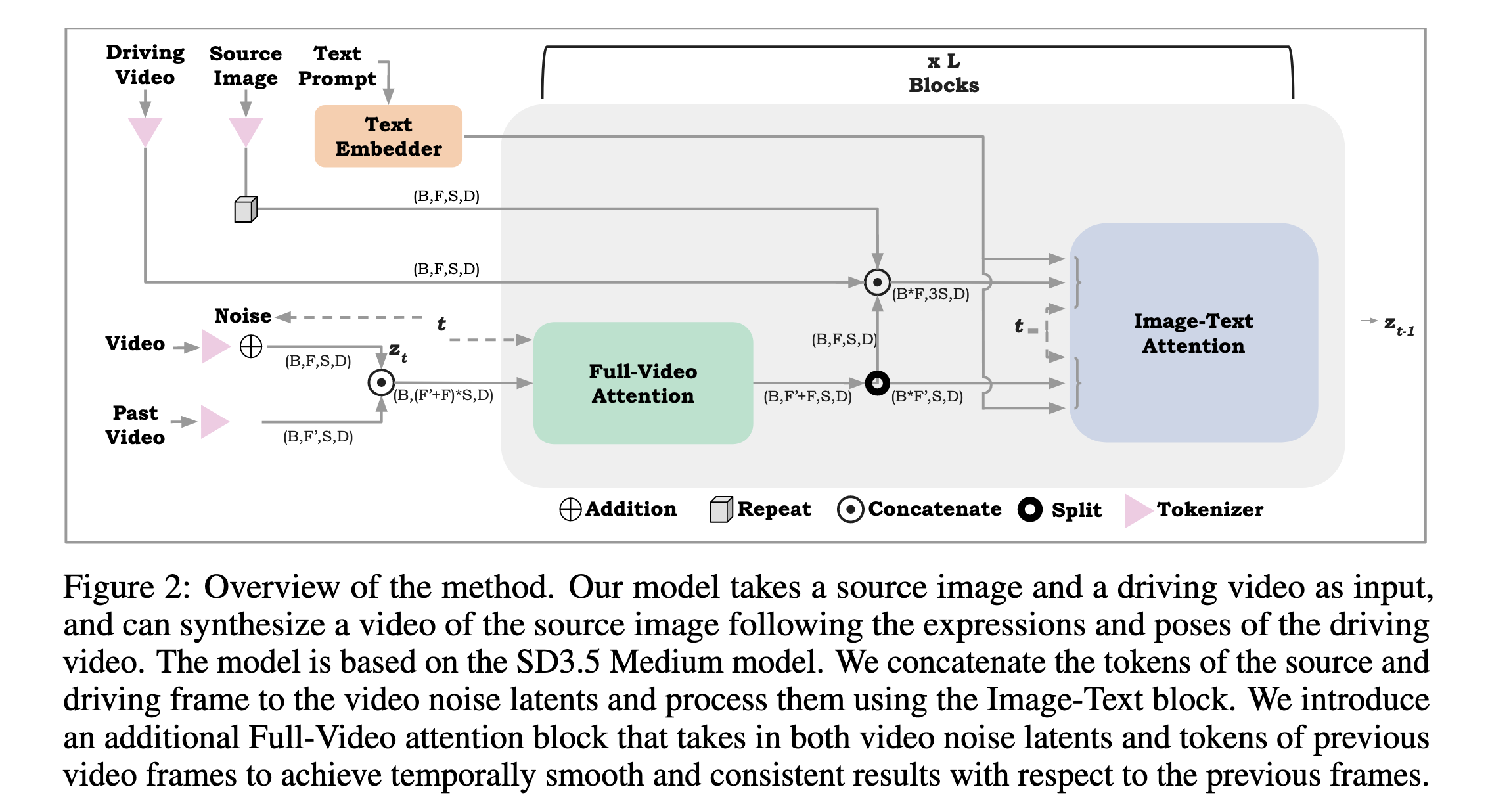
2.1 输入层的 “3S” 拼接策略
为了将控制信号注入 Transformer,模型将以下三部分 Token 在序列维度进行拼接,对于每一帧,输入 Token 总长度为 \(3S\):
- 噪声潜变量 (\(z\)):当前生成的视频帧噪声。
- 源图像 (\(S\)):提供身份特征。源图像被重复 \(F\) 次以对应视频帧。
- 驱动视频 (\(D\)):提供运动特征。作者采用了一种“保留核心,遮挡其余”的策略。具体而言,通过 Mask 操作仅保留(Retain)眼、鼻、嘴等高动态区域的像素,将其余面部区域(如脸型、发型、背景)完全遮挡(Mask out)。
- 设计深意:这种做法是一种巧妙的平衡。相比于 Landmark,保留五官像素提供了眼神流转、嘴唇纹理等丰富的细粒度运动细节;相比于全脸输入,遮挡其余部分则有效阻断了驱动者的外观(Identity)信息泄漏。
关键技术:空间编码偏移 (Spatial Encoding Shift) 为了让 Transformer 区分这三组 Token,作者采用了不同的空间位置编码。源图像 \(S\)和驱动视频\(D\)的 Token 坐标被加上了固定的偏移量(Shift),使其在空间上与噪声 Token\(z\) 互不重叠。这相当于在 Transformer 的视野中构建了一张互不干扰的“虚拟大图”。
2.2 全时空注意力机制 (Full-Video Attention)
SD3.5M 原生仅支持空间注意力。为了引入时序连贯性,作者引入了 Full-Video Attention 模块。
- 输入:当前帧噪声 \(z\)和历史帧\(\mathcal{T}'\)的拼接。注意,源图像\(S\)和驱动视频\(D\) 为了效率不参与此时序计算。
- 机制:每个 Token 不仅关注同一帧内的 Token,还关注所有其他帧(包括历史帧)的所有 Token。
- 作用:这种全交互机制能捕捉细微的唇部运动和眼部注视,有效消除了帧间闪烁。
3. 训练与推理流程
3.1 解决 Cross-ID 训练难题
在视频驱动任务中,如果在训练时源图和驱动图来自同一个人(Self-driven),模型极易发生“外观泄漏”(即直接复制像素而非学习运动)。
- 解决方案:利用 LivePortrait 模型生成配对数据。
- 具体操作:让身份 B 做身份 A 的动作。训练时,输入源图为 A,驱动视频为 B(做 A 的动作)。这强制模型必须从驱动信号中提取运动信息,而不是外观信息。
3.2 “Careful Curriculum” 两阶段训练
为了处理长视频生成的误差累积问题,作者采用了两阶段训练策略:
- Stage 1 (Zero-Out):将历史帧输入 \(\mathcal{T}'\) 强制置零。迫使模型仅依赖驱动信号生成内容,防止模型在初期就“偷看”历史帧而产生依赖。
- Stage 2 (Fine-tuning):在最后 10k 步训练中加入真实的历史帧。让模型学习如何利用历史信息进行平滑过渡。
3.3 推理策略:多信号融合
推理时采用类似 Classifier-Free Guidance (CFG) 的策略,计算四个分支的线性组合:
\[z = u + \lambda_{s} \times (s - u) + \lambda_{d} \times (d - s) + \lambda_{p} \times (p - d)\]其中:
- \(u\): 无条件生成(Unconditional)。
- \(s\): 仅源图像控制(Source-only)。
- \(d\): 源图像 + 驱动视频控制(Source + Driving)。
- \(p\): 全条件控制(含历史帧)(Fully conditioned)。
通过调节 \(\lambda\)参数(如\(\lambda_{s}=2, \lambda_{d}=2.5, \lambda_{p}=1\)),可以精确控制身份保持、运动跟随和时序平滑的权重。
4. 实验对比与消融分析
4.1 对比实验
作者在 HDTF 和 TalkingHead-1KH 数据集上与 LivePortrait, AniPortrait, X-Portrait 进行了对比。
- Self-Reenactment (自驱动):
- 指标:在 L1, LPIPS, FVD (视频质量), Sync (口型同步) 等所有指标上均优于基线。
- FVD:得益于 Full-Video Attention,生成视频的时序伪影最少,FVD 分数显著更低。
- Cross-Reenactment (跨驱动):
- 口型与眼动:Sync-C/D 和 MAE 指标显著优于依赖 Landmark 的 AniPortrait。AniPortrait 由于仅使用 Landmark,无法捕捉细微表情和眼球注视方向。
- 风格泛化:定性结果显示,该模型能完美驱动素描、油画、动漫等非真实人脸,而 LivePortrait 在这些场景下往往丢失高频细节。
4.2 消融实验
- Attention 机制:对比 Factorized Attention(仅关注对应位置),Full-Video Attention 在唇形同步 (\(Sync\)) 和眼球运动 (\(MAE\)) 上表现更好,证明了全局时空交互捕捉细微运动的必要性。
- Curriculum 策略:如果不采用“先置零后微调”的策略,模型生成的长视频在额头等区域会出现明显的暗色伪影 (Dark Artifacts),证明了该策略对消除误差累积的关键作用。
5. 总结与思考
Stable Video-Driven Portraits 展示了 DiT 架构在细粒度视频控制任务上的潜力。
- 架构做减法,数据做加法:作者没有设计复杂的适配器网络,而是直接利用 Transformer 的序列处理能力(\(3S\) Concatenation)。
- 时序建模的新范式:Full-Video Attention 虽然计算量大,但对于捕捉微表情(如抿嘴、眼神流转)至关重要,这是以往 Factorized Attention 难以做到的。
- 泛化性的来源:通过保留预训练 DiT 的大部分参数,模型继承了 SD3.5 对各种艺术风格的理解能力,解决了传统 GAN 方法“只能生成真人”的局限。
局限性:当源图像的人脸比例极端异常(如某些卡通形象眼鼻距离过近)时,模型可能会出现结构误判。