
FLOAT:在 motion latent 里用 Flow Matching 生成可控 talking portrait
FLOAT:在 motion latent 里用 Flow Matching 生成可控 talking portrait
论文:FLOAT: Generative Motion Latent Flow Matching for Audio-driven Talking Portrait
作者:Taekyung Ki, Dongchan Min, Gyeongsu Chae
会议:ICCV 2025
检索日期:2026-05-24
主线:不要在 Stable Diffusion 的 pixel latent 里硬做 talking head,而是在显式 motion latent 里用 flow matching 采样头动、表情和口型。
开篇点评:FLOAT 的重点不是“又一个 talking head”,而是换了生成空间
很多 audio-driven talking portrait 方法的困难并不只在“嘴型对不齐”。嘴型只是最容易量化的部分;一个自然的虚拟人还要有头动、眼神、眉毛、情绪强度、说话节奏,以及跨帧稳定的身份和面部细节。
近年来的 diffusion-based 方法,比如借 Stable Diffusion latent 做视频生成,通常画质强,但会遇到两个工程问题:采样慢,以及 pixel latent 不天然等价于 motion latent。图像 VAE latent 适合保存外观和语义,但把它沿时间维扩展成视频后,运动轨迹、局部表情和口腔细节会被空间重建目标混在一起,容易闪烁或依赖额外 2D landmark、3DMM、skeleton、bbox 这类强先验。
FLOAT 的做法更像 VASA-1 这一类 motion latent thinking:先训练一个能把 identity 和 motion 分开的 motion auto-encoder,再用 Flow Matching 在 motion latent sequence 上采样。这样生成模型不直接生成像素,也不在 SD latent 里处理所有外观细节;它只负责生成一段“应该怎么动”的 latent,再由 decoder 把 identity 和 motion 合成成视频帧。
我的判断是,FLOAT 对工程更有价值的点在于这个任务分解:外观重建交给 auto-encoder,运动生成交给 compact latent flow。它并没有把 talking portrait 的所有问题都解决,但把“口型、表情、头动、速度”这几个目标放到了一个更合适的表示空间里。
Paper Card
| 项目 | 信息 |
|---|---|
| Paper | CVF Open Access, PDF, arXiv:2412.01064 |
| Project / Code | Project, GitHub |
| Task | Single image + driving audio to talking portrait video |
| Core idea | learned orthogonal motion latent + OT-based flow matching + frame-wise vector field predictor |
| Conditions | Wav2Vec2 audio feature, speech-to-emotion label, source reference motion, flow time embedding |
| Resolution / FPS | 512 x 512 preprocessing, 25 FPS |
| Default sampling | Euler ODE solver, NFE 10 |
| Training data | HDTF, RAVDESS, VFHQ for auto-encoder; HDTF and RAVDESS for audio-synchronized FLOAT training |
| Release boundary | GitHub releases inference code and checkpoints; training code is explicitly not released; license is CC BY-NC-ND 4.0 |
Abstract:论文摘要解读
FLOAT 的摘要主要表达三层意思。第一,现有 diffusion portrait animation 虽然画质好,但 iterative sampling 让推理慢,视频一致性也不稳定。第二,FLOAT 不在 pixel-based latent space 里直接做运动生成,而是利用一个 learned orthogonal motion latent space,试图把运动和外观解耦。第三,模型用 transformer-based vector field predictor 学习 flow matching 的生成向量场,条件来自音频和 speech-driven emotion,因此可以在较少采样步下生成口型同步且带情绪增强的 motion latent sequence。
这篇论文真正的技术核心是两阶段:Phase 1 训练 motion latent auto-encoder,让图像可以被拆成 identity latent 和 motion latent;Phase 2 用条件 Flow Matching 从噪声采样 motion latent sequence,再把 identity + generated motion 解码成 talking video。
Motivation:为什么不用 Stable Diffusion latent 直接做
论文对 prior methods 的判断比较清楚:
- SD latent 是 pixel/semantic compression space,不是专门的 motion space;
- 直接把 image diffusion lift 到 video,时间一致性和采样速度都容易成为瓶颈;
- landmarks、3DMM、skeleton 等强几何先验虽然稳定,但会限制头动和表情自由度;
- 纯音频到 motion 是 one-to-many:同一句话可以有多种头动和情绪,因此模型需要概率生成能力和可控性。
FLOAT 的回答是:先学一个低维、线性、正交的 motion basis,再让 generative model 在这个空间里采样。这个空间比像素空间小得多,也比简单 landmarks 更自由。
直观效果:音频情绪影响非语言动作
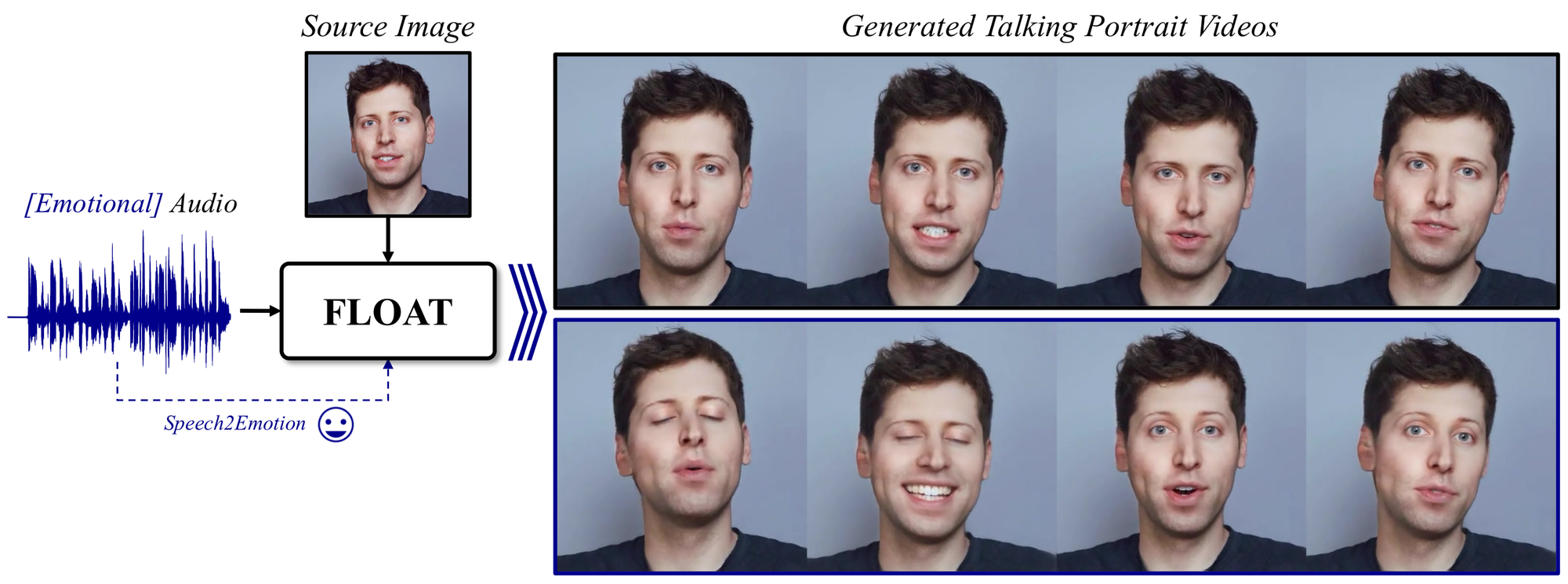
图 1:论文 teaser。FLOAT 输入单张 source image 和 audio,Speech2Emotion 分支给出情绪条件,使生成结果不仅有口型,也包含更明显的情绪相关表情和头动。
这张图能说明 FLOAT 和只追求 lip-sync 的方法不一样。它试图把 speech emotion 作为 motion condition,而不是让用户手动指定每一帧表情。论文支持七种基本情绪:angry、disgust、fear、happy、neutral、sad、surprise。GitHub 推理脚本也保留了 --emo 参数:如果不指定,就从音频预测情绪;如果指定,就可以做 emotion redirection。
方法总览:source image 到 generated video 的数据流
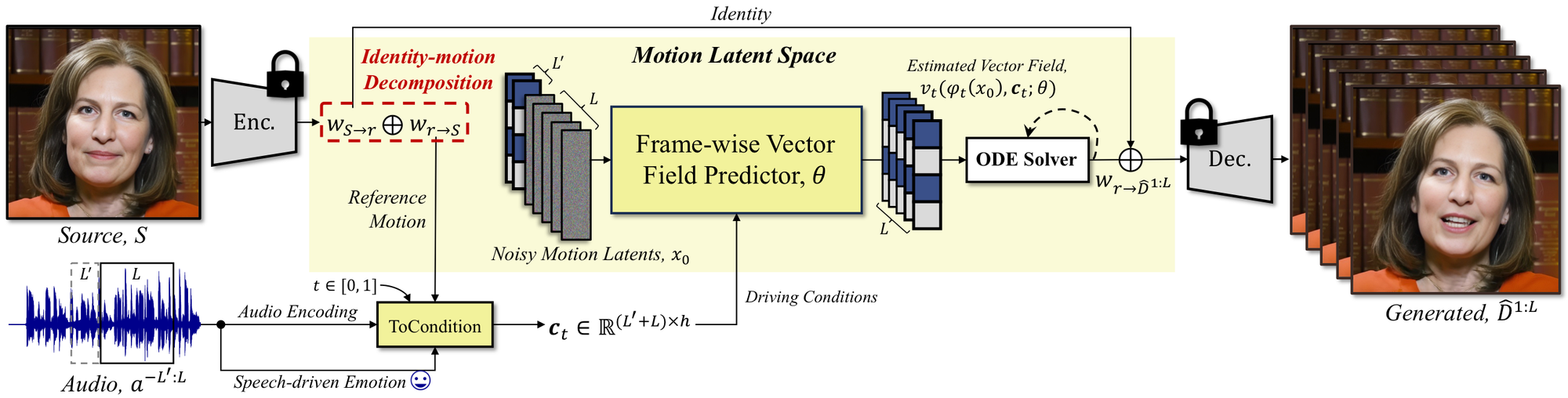
图 2:FLOAT 总览。source image 先编码成 identity-motion decomposition;audio、emotion、reference motion 和 flow time 共同构造条件;Flow Matching Transformer 从 noisy motion latents 预测 vector field,经 ODE solver 得到 motion latents,最后 decoder 生成视频。
论文中的核心符号可以压成下面这条链:
\[S \rightarrow (w_{S\to r}, w_{r\to S})\] \[(a^{-L':L}, w_e, w_{r\to S}, t) \rightarrow \mathbf{c}_t\] \[x_0 \xrightarrow{\text{Flow Matching Transformer + ODE}} w_{r\to \hat{D}^{1:L}}\] \[w_{S\to \hat{D}^{1:L}} = (w_{S\to r} + w_{r\to \hat{D}^{l}})_{l=1}^{L} \rightarrow \hat{D}^{1:L}\]直观地说,source image 提供“这个人长什么样”,audio 和 emotion 提供“这段话怎么驱动”,Flow Matching 只负责生成“这一段应该怎样动”。
Phase 1:Motion Latent Auto-Encoder
FLOAT 继承 LIA 的 latent image animation 思路,用一个 auto-encoder 学显式的 identity-motion decomposition。给定 source image $S$,encoder 得到 latent:
\[w_S := w_{S\to r} + w_{r\to S}\]其中 $w_{S\to r}$ 表示 identity latent,$w_{r\to S}$ 表示 motion latent。motion latent 又被写成正交基的线性组合:
\[w_{r\to S} = \sum_{m=1}^{M}\lambda_m(S)\mathbf{v}_m\]论文实现里 motion latent dimension 是 $d=512$,正交 motion directions 数量是 $M=20$。这意味着每个 motion latent 可以被投影回 20 个 motion basis coefficients;因此后面可以做 lambda-control,也就是直接改某个系数来编辑头部姿态。
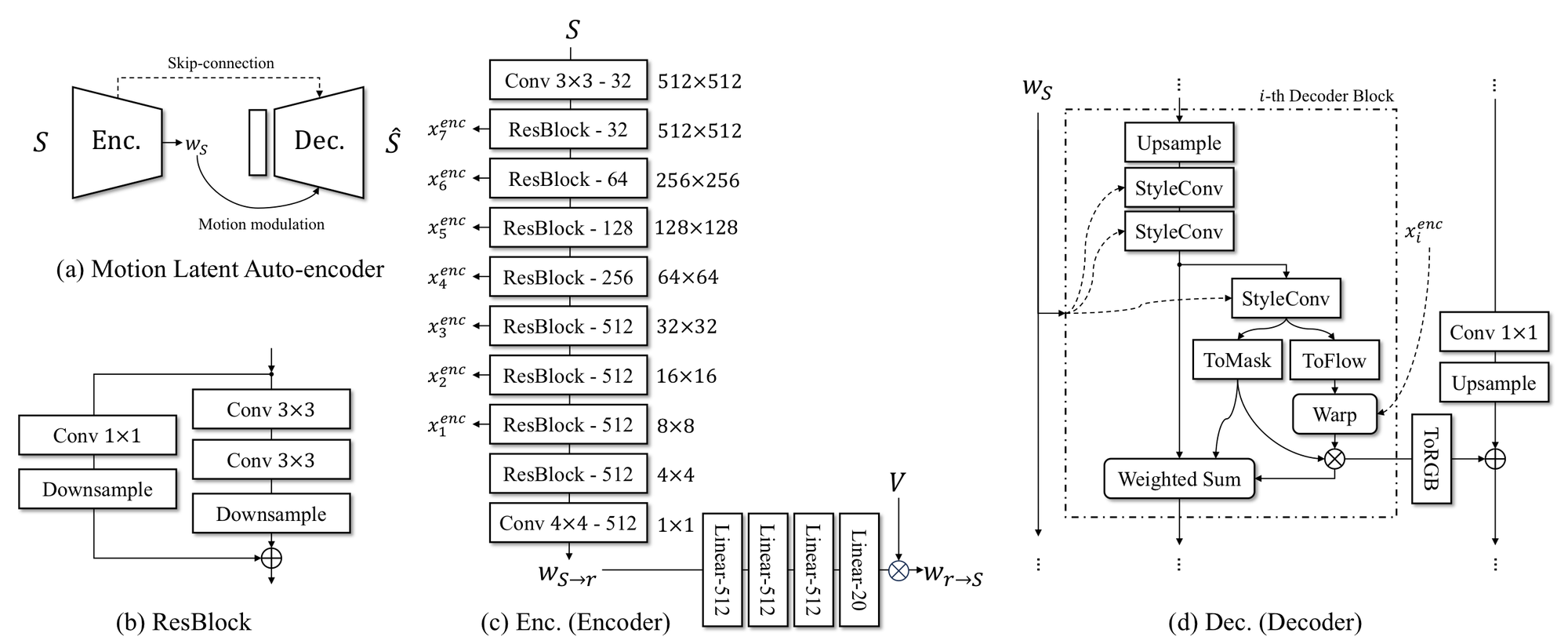
图 3:motion latent auto-encoder 结构。encoder 输出 identity latent 和 motion coefficients,decoder 用 StyleGAN2/LIA 风格模块、skip connection、motion modulation 重建目标帧。
训练时,不是拿同一帧做自重建,而是从同一视频 clip 里采 source image 和 driving image。模型要用 source 的 identity 加 driving 的 motion 去重建 driving frame:
\[\hat{D} = \mathrm{Dec}(w_{S\to r} + w_{r\to D})\]这个训练方式迫使 encoder 学到“人是谁”和“当下怎么动”的分离。
Facial component perceptual loss
高分辨率 talking face 的一个常见问题是:嘴、牙齿、眼球这些局部区域太小,普通全图 reconstruction loss 容易被大面积皮肤和头部姿态淹没。FLOAT 为此加入 facial component perceptual loss,把嘴和眼区域的多尺度 VGG feature 单独做 perceptual supervision:
\[\sum_{i=1}^{N} \frac{1}{|M_i|} \left\| M_i \otimes \phi_i(\hat{D}) - M_i \otimes \phi_i(D) \right\|_1\]它还配合 lip/eye component discriminator 和 feature style matching。论文的解释很重要:在 motion auto-encoder 里,局部组件质量不只是高频 texture 问题,因为 source 和 target 存在空间错位;它更像低频结构对齐问题,所以简单照搬 face restoration 的 texture discriminator 不够。
Phase 2:在 motion latent space 里做 Flow Matching
Flow Matching 的目标不是一步预测最终 motion,而是学习一个时间依赖的 vector field。给定目标 motion latent sequence $x_1$ 和高斯噪声 $x_0$,OT path 写成直线:
\[x_t = (1-t)x_0 + t x_1\]对应的目标速度场是:
\[u_t = x_1 - x_0\]训练 loss 是让网络预测的 vector field 靠近这个目标:
\[\mathcal{L}_{\mathrm{OT}}(\theta) = \left\| v_t((1-t)x_0 + tx_1; \theta) - (x_1-x_0) \right\|_2^2\]在 FLOAT 里,$x_1$ 不是像素视频,而是一段 motion latent sequence。这样 vector field 的输出维度是 $L \times d$,比直接生成 512 x 512 视频小很多。
条件构造:audio、emotion、reference motion、time
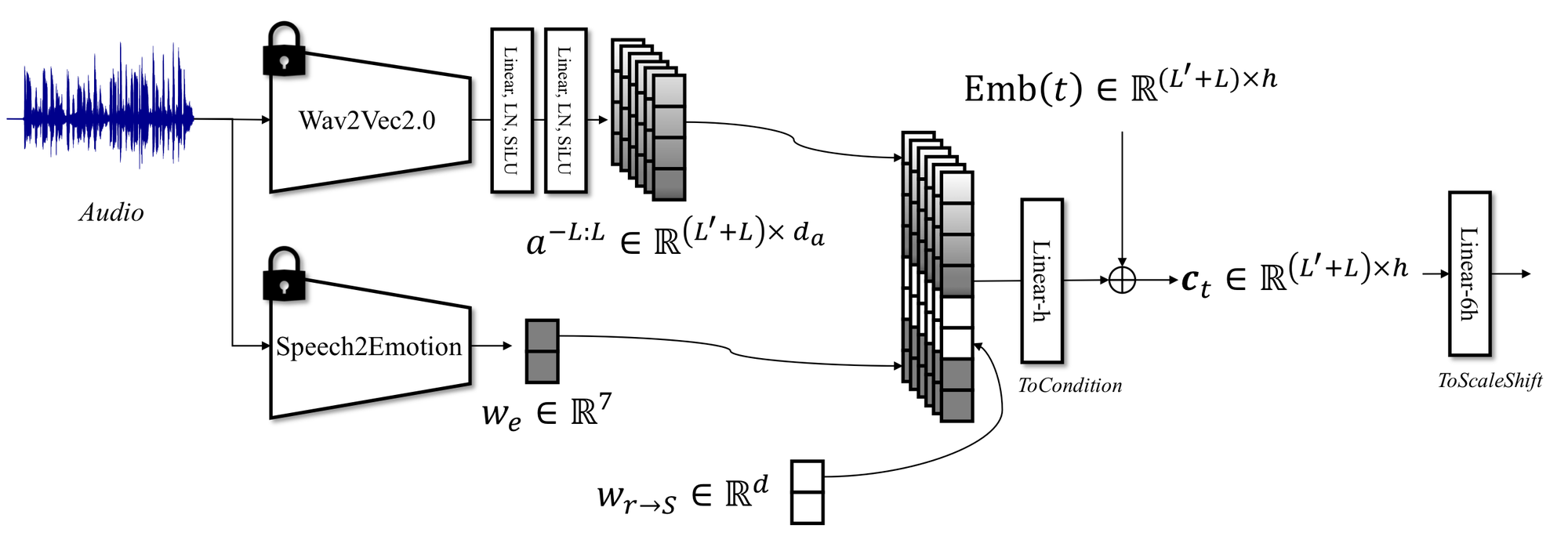
图 4:FLOAT 的 condition builder。Wav2Vec2.0 提供 frame-wise audio feature,Speech2Emotion 提供 7 类 emotion soft label,reference motion 和 flow time embedding 一起映射成每帧条件。
论文和代码里能对上的默认配置是:
| 条件 | 来源 | 语义 |
|---|---|---|
| Audio feature | Wav2Vec2.0 | 逐帧语音内容、节奏和音素线索 |
| Emotion label | Wav2Vec2 speech emotion classifier | 7 类 emotion probability 或用户指定 one-hot |
| Reference motion | source image motion latent | 保留 source 的初始 pose / expression reference |
| Flow time | sinusoidal embedding | 当前 ODE / flow time |
| Preceding window | 前 10 帧 audio feature 和 generated motion latent | 跨 chunk 平滑过渡 |
代码里的 BaseOptions 默认是 fps=25、wav2vec_sec=2,因此一个 generation chunk 是 50 frames;num_prev_frames=10,因此每个 chunk 还看前 10 帧上下文。
Frame-wise Vector Field Predictor
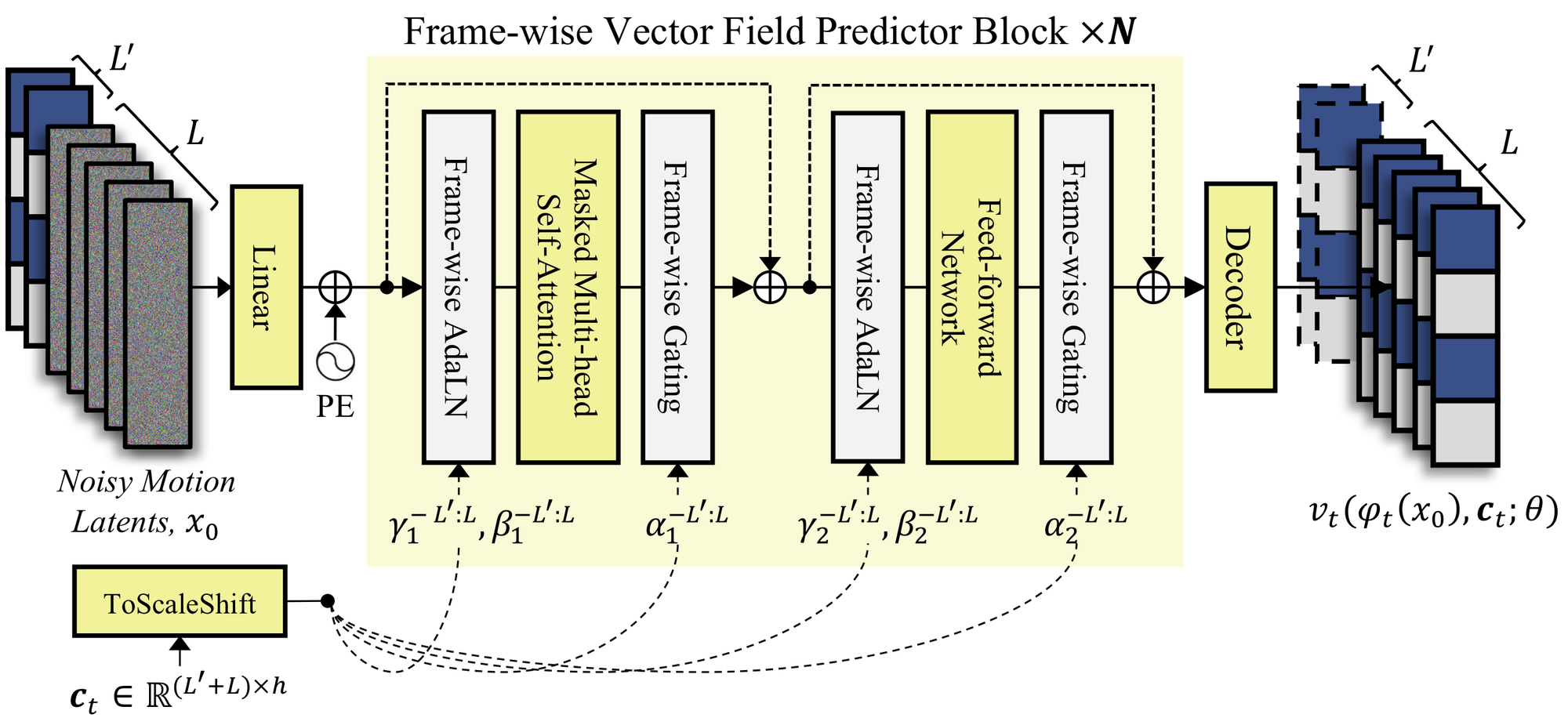
图 5:frame-wise vector field predictor block。它不是简单 cross-attention,而是每帧先用对应条件做 AdaLN 和 gating,再用 masked multi-head self-attention 建模时间关系。
FLOAT 借鉴 DiT,但没有把一个全局 condition 粗暴灌进所有 token。每一帧都有对应的 condition embedding,并通过 frame-wise AdaLN / gating 调制该帧 latent,再用 masked self-attention 建模相邻时间关系。论文实现里 vector predictor 使用 8 attention heads、hidden dimension 1024、attention window length 2。
这种设计的动机很明确:audio condition 是 frame-wise 的。第 $l$ 帧的嘴型和表情应该主要受附近音频影响,而不是由一个全局 clip embedding 决定。
Training:两阶段训练数据和目标
Motion Auto-Encoder
Auto-encoder 训练使用 HDTF、RAVDESS 和 VFHQ。VFHQ 没有同步音频,但它有大量高分辨率人脸视频,可以补 identity 多样性。supplement 写到 auto-encoder 训练约 460k steps、9 天、单张 NVIDIA A100,batch size 8,learning rate 为 2e-4。
训练目标包含 L1、perceptual、facial component perceptual、full-image adversarial、eye/lip local adversarial 和 feature style matching。这个阶段的目标是把 identity 和 motion 拆干净,并保证 512 x 512 重建质量。
FLOAT Flow Matching
训练 FLOAT 时排除 VFHQ,因为它不提供 synchronized audio。HDTF 被转成 25 FPS、音频重采样到 16 kHz,并裁剪到 512 x 512。论文报告 HDTF 训练集是 11.3 小时、240 个 videos、230 个 identities;测试集是 78 个 disjoint identities,每个 15 秒。RAVDESS 使用 22 个 identities 训练,剩余 2 个 identities 测试。
Phase 2 默认配置:
| 参数 | 数值 |
|---|---|
| motion latent dim | 512 |
| orthogonal basis count | 20 |
| hidden dim | 1024 |
| attention heads | 8 |
| attention window length | 2 |
| generated window | 50 frames |
| preceding frames | 10 frames |
| optimizer | Adam |
| batch size | 8 |
| learning rate | 1e-5 |
| training time | about 2 days for 2,000k steps on one A100 |
| ODE solver | Euler |
训练目标是 OT flow matching loss 加 velocity consistency loss:
\[\mathcal{L}_{\mathrm{total}}(\theta) = \lambda_{\mathrm{OT}}\mathcal{L}_{\mathrm{OT}}(\theta) + \lambda_{\mathrm{vel}}\mathcal{L}_{\mathrm{vel}}(\theta)\]论文设置两个权重都为 1。velocity loss 约束时间轴上的一阶差分,目的是减少相邻帧 motion latent 的不连续。
Inference:测试时到底怎么生成
官方代码的推理过程和论文基本一致:
- 输入 reference image 和 audio;
- 如果不加
--no_crop,先做人脸检测、padding、crop 到 512 x 512; - 音频用 16 kHz 加载,Wav2Vec2 提取 frame-wise feature;
- Speech2Emotion 输出七类情绪分布;若用户给
--emo,改用指定 emotion one-hot; - source image 经过 motion auto-encoder 得到 identity latent 和 reference motion latent;
- 每 50 frames 采样一个 motion latent chunk;
- 每个 chunk 用前 10 帧 generated motion / audio feature 做平滑上下文;
- ODE solver 从 Gaussian noise 积分到 generated motion latent;
- decoder 把 identity latent 加 generated motion latent,逐帧生成 video;
- 用 ffmpeg 把原始音频 mux 回输出视频。
默认 guidance scale 在代码和 README 中也能对上:a_cfg_scale=2,e_cfg_scale=1,nfe=10。README 还建议如果音频有重背景音乐,可以先用 ClearVoice 提取 vocals,这说明实际工程效果对音频预处理比较敏感。
Evaluation:实验支持了什么
FLOAT 的主实验在 HDTF / RAVDESS 上比较 SadTalker、EDTalk、AniTalker、Hallo、EchoMimic。指标包括 FID、FVD、CSIM、E-FID、P-FID、LSE-D、LSE-C。它的结果大致是:
| 方法 | FID | FVD | CSIM | E-FID | P-FID | LSE-D | LSE-C |
|---|---|---|---|---|---|---|---|
| Hallo | 25.363 / 57.648 | 197.196 / 375.557 | 0.869 / 0.860 | 1.039 / 2.492 | 0.037 / 0.050 | 7.792 / 7.613 | 7.582 / 4.795 |
| EchoMimic | 33.552 / 81.839 | 296.757 / 320.220 | 0.823 / 0.805 | 1.234 / 3.201 | 0.023 / 0.047 | 8.903 / 8.161 | 6.242 / 4.144 |
| FLOAT | 21.100 / 31.681 | 162.052 / 166.359 | 0.843 / 0.810 | 1.229 / 1.367 | 0.032 / 0.031 | 7.290 / 6.994 | 8.222 / 5.730 |
这个表的正确读法是:FLOAT 在 FID、FVD、E-FID、P-FID、LSE-D、LSE-C 上整体很强,但 CSIM 不是第一,Hallo 的 identity similarity 更高。也就是说 FLOAT 的优势主要是视频质量、运动/姿态分布和 lip-sync,而不是绝对 identity preservation。
Speed:为什么它比 diffusion-based talking head 快
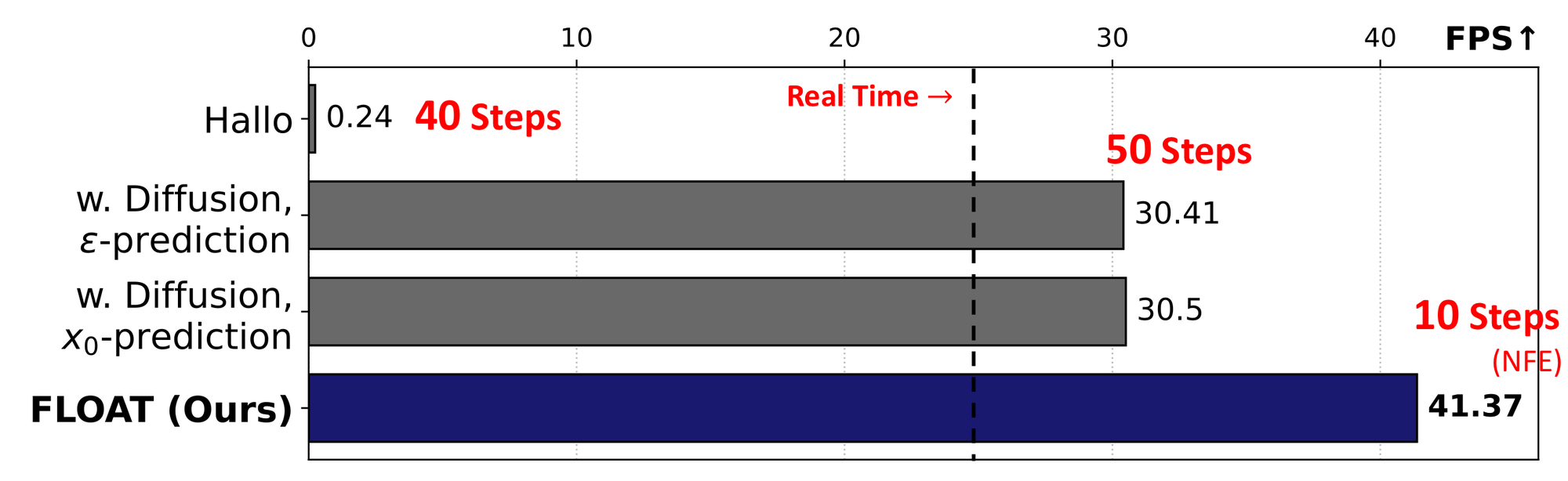
图 6:速度对比。论文在单张 V100 上测 forward pass efficiency,FLOAT 默认 NFE 10 达到 41.37 FPS;diffusion ablation 使用 50 steps,约 30 FPS;Hallo 的 diffusion pipeline 远慢于实时。
速度来自两个层面:
- 生成目标是 motion latent sequence,不是 pixel latent video;
- Flow Matching 使用 ODE solver,默认 NFE 10,比 diffusion baseline 的 50 DDIM steps 少。
supplement 的 NFE ablation 也很有用:NFE 2 仍有不错 FID 和 LSE-D,但 FVD 和 E-FID 变差,表现为头动抖、表情静态或过强。也就是说,低 NFE 可以保图像和口型,但会牺牲 motion quality;默认 NFE 10 是画质、口型和运动稳定性的折中点。
应用:lambda-control 和 emotion redirection
因为 motion latent 是正交基组合,生成出的 motion latent 可以投影回 basis coefficient:
\[\left\langle w_{r\to\hat{D}}, \mathbf{v}_k \right\rangle = \left\langle \sum_{m=1}^{M}\lambda_m(\hat{D})\mathbf{v}_m,\mathbf{v}_k \right\rangle = \lambda_k(\hat{D})\]这带来 test-time pose editing:改某个 lambda coefficient,再把 motion latent 组合回去。论文展示了用 lambda-control 改头部方向,而不明显干扰其他动作。这个性质来自 orthonormal basis,本质上是把 talking head 的一部分可编辑性放在 motion representation 里。
Emotion redirection 则更偏应用层。若音频预测出的情绪不符合用户意图,可以手动指定 one-hot emotion,再通过 emotion guidance scale 增强或减弱。README 中也明确建议更强情绪可把 e_cfg_scale 调到 5 到 10,但这属于工程调参,不保证所有输入都自然。
复现与工程风险
第一,官方 repo 是 inference code + checkpoints,不是完整训练代码。README 明确写了 training code will not be released,因此论文主训练流程不能完全端到端复现。checkpoint 可下载,适合做推理验证和集成评估,但不适合复现实验曲线。
第二,license 是 CC BY-NC-ND 4.0。它可以用于研究演示,但不适合直接商用或二次发布修改版。工程落地前必须重新确认授权。
第三,数据分布偏 frontal face。supplement 和 README 都提到非正脸会退化,尤其是 yaw angle 较大、戴眼镜、有明显配饰的 source image。下面这个 failure case 就是眼镜区域和非正脸细节处理不稳定。

图 7:论文 supplement 的 failure case。FLOAT 在非正脸和眼镜等 accessories 上容易出错,这与训练数据的 frontal pose 分布偏置一致。
第四,emotion space 只有七类基本情绪。论文自己也承认,它不能表达更细腻的情绪状态,比如 shyness 这类语义化表情。作者建议未来引入 text cues,这其实也说明“speech-to-emotion soft label”只是一个轻量控制信号,不是完整的 affect modeling。
第五,音频质量会影响结果。代码使用 Wav2Vec2 audio feature 和 speech emotion classifier,README 建议背景音乐重时先做 vocal extraction。对实际部署来说,噪声、混响、多说话人、语言分布都会影响 motion 和 emotion。
总结
FLOAT 的贡献可以概括为一句话:把 audio-driven talking portrait 的生成目标从 pixel video 换成 motion latent trajectory,再用 Flow Matching 快速采样这条轨迹。它把 identity reconstruction、motion generation、emotion control 分到不同模块里,因此在速度、口型同步和 motion expressiveness 上有比较清楚的优势。
这篇论文最值得借鉴的是表示空间选择。很多 talking head 方法在更大的 diffusion backbone 上堆条件,FLOAT 反过来问:这个任务真正需要生成的是什么?答案是“运动”,不是每一帧的完整外观。只要 motion latent 足够表达头动、嘴、眼和表情,生成器就可以更轻、更快、更可控。
不足也很明确:完整训练不可复现、license 限制强、非正脸和 accessories 仍然脆弱、情绪建模较粗。把它放在研究脉络里看,FLOAT 是一个很好的 motion-latent + flow-matching baseline;把它放在产品系统里看,还需要更强的数据覆盖、更鲁棒的裁剪/对齐、更细粒度情绪控制和明确商用授权。
参考链接
- FLOAT paper: CVF Open Access, PDF, arXiv
- FLOAT project/code: Project Page, GitHub
- Key dependencies in the released inference code: Wav2Vec2 base, speech emotion recognizer