
Dual Prompting Image Restoration with Diffusion Transformers
发布时间:
[Paper Reading] 基于扩散 Transformer 的双重提示图像复原 (DPIR)
在图像复原(Image Restoration, IR)领域,虽然基于 U-Net 架构的潜在扩散模型(Latent Diffusion Models)已被广泛采用,但其在实现高质量复原方面仍面临挑战。与此同时,扩散 Transformer(Diffusion Transformers, DiTs)(如 Stable Diffusion 3, SD3)凭借其能够捕捉长距离依赖关系以及优越的可扩展性,正成为一种有前途的替代方案。
本文将深入解析 CVPR 论文提出的 DPIR (Dual Prompting Image Restoration)。该方法利用 DiT 的特性,通过引入低质量图像调节分支和双重提示控制分支,有效地从全局和局部视角提取低质量图像的条件信息,从而显著提升复原质量。
1. 背景与核心动机
现有的基于 U-Net 的复原方法(如 ControlNet, StableSR)通常依赖于复杂的 ControlNet 副本或适配器(Adapter)进行条件控制。然而,直接将这些方法迁移到由 ViT Block 组成的 DiT 上面临主要挑战,因为 DiT 缺乏 U-Net 那样的跳跃连接机制,难以在深层网络中保持低质量(LQ)图像的信息。
此外,在图像复原中,仅靠文本描述无法完全捕捉图像丰富的视觉特征(如纹理细节)。DPIR 旨在通过设计针对 DiT 的条件机制来解决这些问题。
2. 预备知识:整流流 (Rectified Flow)
不同于传统的扩散公式,DPIR 采用了与 SD3 一致的整流流 (Rectified Flow) 公式。它定义了从噪声分布 \(\pi_1\)到数据分布\(\pi_0\) 的直线路径。
前向过程定义为:
\[z_{t} = (1-t)x_{0} + t\epsilon\]其中 \(x_0\) 为数据样本,\(\epsilon \sim \mathcal{N}(0, I)\) 为噪声。
训练目标是最小化条件流匹配(Conditional Flow Matching)损失:
\[\mathcal{L}_{CFM} = \mathbb{E}_{t, p_t(z_t), p(\epsilon)} [ ||v_{\theta}(z_t, t) - (x_1 - x_0)||^2 ]\]其中 \(v_{\theta}\) 是预测速度场的网络,它可以接收额外的控制信号(如文本或图像条件)。
3. DPIR 核心架构详解
DPIR 的整体管线如下图所示,主要包含三个核心模块:抗退化 VAE 编码器、低质量图像调节分支以及双重提示控制分支。
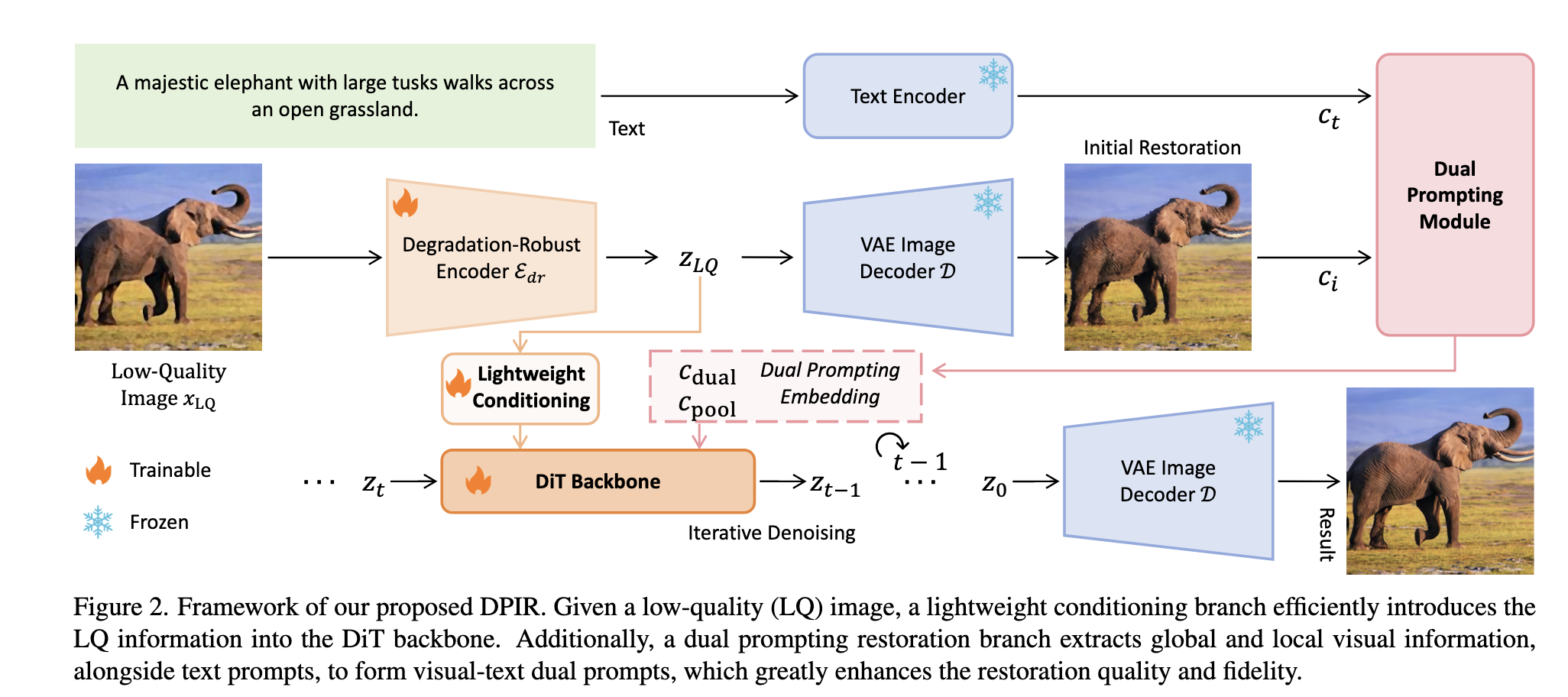
3.1 抗退化 VAE 编码器 (Degradation-Robust VAE Encoder)
为了获得高质量的潜在空间条件,作者对 SD3 的 VAE 编码器 \(\mathcal{E}_{dr}\) 进行了微调,使其对退化更加鲁棒。
- 优势:SD3 的 VAE 具有 16 个通道,相比 SDXL 的 4 通道能为 DiT 提供更好的初始条件。
- 微调策略:为了防止 VAE 对模糊输入产生过于平滑的潜在表示,引入了感知损失(LPIPS)和对抗损失(GAN)。
微调的损失函数为:
\[||\mathcal{D}(\mathcal{E}_{dr}(x_{LQ})) - x_{HQ}||_1 + \lambda_{lpips}\mathcal{L}_{lpips} + \lambda_{gan}\mathcal{L}_{GAN}\]其中 \(x_{LQ}\) 为低质量输入,\(x_{HQ}\) 为高质量真值,\(\mathcal{D}\) 为冻结的解码器。
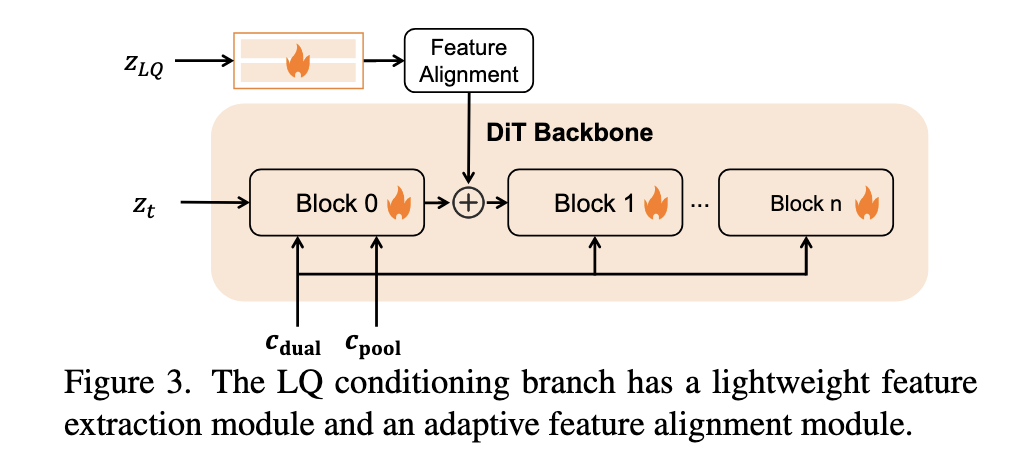
3.2 低质量图像调节分支 (Low-Quality Image Conditioning Branch)
这是一个轻量级模块,受 ControlNeXt 启发,旨在高效地将图像先验注入 DiT 骨干。
- 结构:不使用庞大的骨干网络副本,而是仅通过少量卷积层 \(\mathcal{F}_{c}\) 提取特征。
- 注入方式:提取的特征通过自适应特征对齐 (Adaptive Feature Alignment) 模块,注入到 DiT 的第一个 Block 中。
注入公式如下:
\[y_{c} = \mathcal{F}_{d_{0}}(z_{t};\theta_{d_{0}}) + \eta(\mathcal{F}_{c}(z_{LQ};\phi_{c}); \mu, \sigma)\]其中:
- \(z_t\)是时刻\(t\) 的噪声潜变量。
- \(\mathcal{F}_{d_{0}}\) 是 DiT 的第一个 Block。
- \(\eta\)是自适应对齐函数,利用主分支特征的均值\(\mu\)和方差\(\sigma\) 对条件特征进行归一化,确保训练稳定性。
3.3 双重提示控制分支 (Dual Prompting Control Branch)
这是本文的核心创新点。SD3 原本使用混合文本嵌入(两个 CLIP 和一个 T5)。DPIR 认为文本不足以描述复原细节,因此设计了双重提示模块。
A. 双重提示机制
作者保留了 T5 的文本嵌入,但用图像视觉特征替换了 CLIP 的文本嵌入。 具体做法是:
- 将 \(x_{LQ}\) 输入 CLIP 图像编码器。
- 提取 Pooled Embedding (\(c_{pool}\)) 和 Visual Tokens (\(c^{vis}\))。
- 这些视觉特征通过 Cross-Attention 作用于 DiT 的每一层,直接指导纹理恢复。
B. 全局-局部视觉训练 (Global-Local Visual Training)
在复原任务中,局部 Patch(例如“一只狗的眼睛”)往往缺乏整体语境。为此,作者提出了 Global-Local 策略:
- Local:裁剪待复原的局部 Patch \(x^{local}\)。
- Global:裁剪包含该局部区域的更大范围的 Context Patch \(x^{global}\)。
- 融合:分别提取两者的视觉特征并拼接,形成最终的视觉提示 \(c_{G-L}^{vis}\)。
这种策略让模型既能看清局部细节,又能理解全局语义。

4. 实验结果与分析
4.1 定量评估
在 DIV2K, RealSR, DRealSR 等数据集上的测试表明,DPIR 取得了 SOTA 的性能。
- 感知指标:在 LPIPS 和 DISTS 等反映人眼视觉质量的指标上,DPIR 始终取得最好或第二好的成绩。
- 无参考指标:在真实世界数据集 DRealSR 上,DPIR 在 CLIP-IQA, MUSIQ 等指标上均取得领先。
4.2 消融实验
- 提示策略的影响:实验对比了“仅文本提示”、“仅视觉提示”和“双重提示”。结果显示,双重提示(Dual Prompting)显著增强了图像复原质量,特别是在图像美学方面。
- 全局-局部训练的影响:相比仅使用 Local Patch 训练,引入 Global Context 后,模型能够大幅提升各项指标分数,避免了错误的纹理生成,更加忠实地还原细节。
5. 总结
DPIR 成功地将 Diffusion Transformer (SD3) 引入图像复原领域。其核心贡献在于:
- 设计了轻量级调节分支,高效利用 LQ 图像先验。
- 提出了双重提示策略,用视觉特征替代部分文本特征,并结合全局-局部训练,显著增强了复原结果。
这一工作证明了 DiT 架构在底层视觉任务中的潜力。