
GaussianEmoTalker 深读:用 3D Gaussian 做实时情绪说话头像
GaussianEmoTalker 深读:用 3D Gaussian 做实时情绪说话头像
GaussianEmoTalker 讨论的是一个很具体的头像生成问题:给定目标身份、语音、情绪类别和情绪强度,实时生成嘴型同步、表情带情绪、身份细节稳定的 3D talking head。
开篇导读
这篇论文最值得读的地方,不是简单地把 3D Gaussian Splatting 用到 talking head 上,而是把“说话”和“情绪”拆成两个更容易控制的阶段。普通 audio-driven talking head 主要学 audio 到嘴型和脸部运动的映射;emotional talking head 还要让眉眼、脸颊、嘴角、张嘴幅度和情绪强度一起变化。如果直接从 audio + emotion 预测最终头像,模型需要同时解决身份、嘴型、表情和渲染细节,搜索空间很大。
GaussianEmoTalker 的主线是先构建目标身份的中性说话空间,再学习从中性状态到情绪状态的 Gaussian 属性残差。中性空间负责身份细节和基础 articulation,情绪分支只负责“中性脸应该怎样被情绪改动”。这个 decomposition 让模型更容易保持身份,也让后续 residual deformation 更可解释。

我的判断是,它适合放进 3D emotional avatar / Gaussian talking head 的 related work 里重点读。方法链条比较清楚,消融也能对应到核心模块;但当前没有公开实现代码、checkpoint、split list 和评测脚本,所以它更像一条机制明确的研究路线,而不是可直接复现实验包。
Abstract
摘要先把问题限定在一个现实矛盾里:audio-driven talking head 已经能在 lip synchronization 和 visual quality 上取得进展,但 expressive emotional avatars 仍难,尤其还要求 controllable intensity 和 real-time generation。这里的重点不是“会说话”,而是“说话时情绪要能被类别和强度控制,同时还要实时”。只追求嘴型同步,很多旧方法已经能做;只追求情绪丰富,diffusion 或 2D generative 方法也有优势。GaussianEmoTalker 要同时兼顾这些目标。
摘要接着说,方法不是从 speech 直接预测最终 emotional avatar,而是把 emotional animation 写成 neutral-to-emotional residual deformation。中性空间相当于先给目标身份建一个稳定基底,身份长相、局部细节和基础嘴型运动先固定;情绪分支再加残差,比如眉毛更皱、嘴角更上扬、脸颊更鼓、眼睑更紧。这样可以减小第二阶段的学习负担,也让 Gaussian offsets 更像有语义的局部修改。
GaussianBlendshapes 是 Stage 1 的基础。它把 head avatar 表示成 neutral base 加 expression blendshapes,每个 blendshape 包含 3D Gaussian 的位置、旋转、尺度、颜色、透明度等属性变化。GaussianEmoTalker 继承这个表示来构建 identity-specific neutral talking space。identity-specific 很关键:模型不是跨身份泛化,而是为一个人训练一个头像。
Stage 2 的条件包括 mesh displacement cues、audio features、emotion categories 和 intensity encodings。mesh displacement 给空间结构,audio 给语音节奏和音素相关运动,emotion category 决定表情类型,intensity encoding 决定强弱等级。spatial-audio-emotion attention 的作用,是把这些异构条件对齐到每个 Gaussian primitive 上,再预测 Gaussian 属性 offsets。
摘要最后声称方法能同时获得视频质量、嘴型同步、情绪可控和实时渲染。后文实验确实围绕这些 claim 展开:self-driven 有 FID / FVD / PSNR / SSIM / LPIPS / Sync conf / FPS,cross-driven 有 Sync / LMD / AUE,另有 user study 和 ablation。边界也要保留:当前公开材料还不能完整复核这些指标。
Introduction
引言从 VR、human-computer interaction、digital humans、film production 和 virtual conferencing 切入。这个应用铺垫不是装饰,因为这些场景都要求低延迟和连续交互;数字人如果需要等很久才生成,或者说几分钟后身份和表情开始漂,就很难进入真实使用。
论文把早期 GAN / landmark 路线归纳为两类:要么直接学 audio 到 video frames,要么用 landmarks 之类中间表示连接音频和视频。这些方法主要解决 lip-syncing 和 video quality,较少真正处理 emotionally expressive videos。换句话说,它们能让嘴跟着声音动,却不一定让整张脸“带着情绪说话”。
情绪控制被引入后,很多方法使用 one-hot emotion labels。one-hot 能告诉模型“这是 happy / sad / angry”,但不能自然表达“有多 happy / 多 angry”。EDTalk 通过 decoupling lip movements、head poses 和 emotions 来适配新情绪,但也缺少 intensity editing。MEAD 出现后,多强度情绪数据让 intensity control 变成可训练问题。
EAT 和 EMOdiffhead 被放在更接近本文的位置。EAT 用 emotional deformation network 和 emotion-adaptive module 预测 3D landmark shifts,但依赖外部检测器,强情绪和检测误差会影响后续生成。EMOdiffhead 用 DECA 抽 expression vectors,再用 diffusion 生成丰富表情和精确唇形;它的问题不是表达力,而是多步采样带来的效率压力。
因此论文提出核心问题:能否开发一个既保留丰富情绪表达、又能实时运行的 audio-driven emotional avatar editing pipeline?3D Gaussian Splatting 被选中,是因为它已经证明可以高质量实时渲染。作者把 emotional talking head 看成普通 talking head animation 的特殊形式:先建 neutral facial state,再学习从 neutral 到 emotional 的 Gaussian attribute deformation。
方法概述紧接着回答两个关键问题。怎样用 3D Gaussians 建出保留身份细节的 neutral state space?Stage 1 用 GaussianBlendshapes。怎样让 emotion category、intensity 和 audio content 共同控制 Gaussian 属性变化?Stage 2 用 mesh displacement、audio、emotion 和 intensity 输入 spatial-audio-emotion attention,预测 residual offsets。三条 contribution 也正好对应这条路线:实时 3DGS 情绪语音合成框架,neutral / emotional state spaces 的构造,以及融合 spatial variation、audio 和 emotion 的 attention 机制。
Preliminary
3D Gaussian Splatting 把场景表示成一组 3D Gaussians。每个 Gaussian 有中心位置、协方差控制的椭球形状、颜色和透明度;渲染时把 3D Gaussian 投影到 2D 平面,通过 alpha blending 得到像素颜色。它适合这篇论文,是因为每个 primitive 都是显式的:模型可以直接预测 rotation、scale、color、opacity 的变化,而不是像 NeRF 一样只在隐式场里条件化 density / color。
投影到相机坐标时,协方差经过 view transformation 和 projective Jacobian 变换:
这些公式对本文的作用,是说明 Gaussian 的空间形状和屏幕投影可以被显式优化。因此当情绪导致局部面部形变时,模型可以修改 Gaussian 的空间和外观属性。
GaussianBlendshapes 把传统 blendshape 思想移到 3D Gaussian head avatar 上。它用 neutral base model $B_0$ 和一组 expression blendshapes $\{B_1,\dots,B_K\}$ 表示不同表情,每个 expression basis 相对 neutral base 的差异是 $\Delta B_k = B_k - B_0$。给定 expression coefficients $\psi_k$,新表情写成:
这就是 Stage 1 能工作的原因:先把身份和基础表情空间拟合好,再让后续模块只在这个空间上做 residual。论文也指出 GaussianBlendshapes 本身更适合常见情绪视频,强情绪拟合困难;这正好给 Stage 2 的 Emotional Gaussian Deformation 留出必要性。
Method
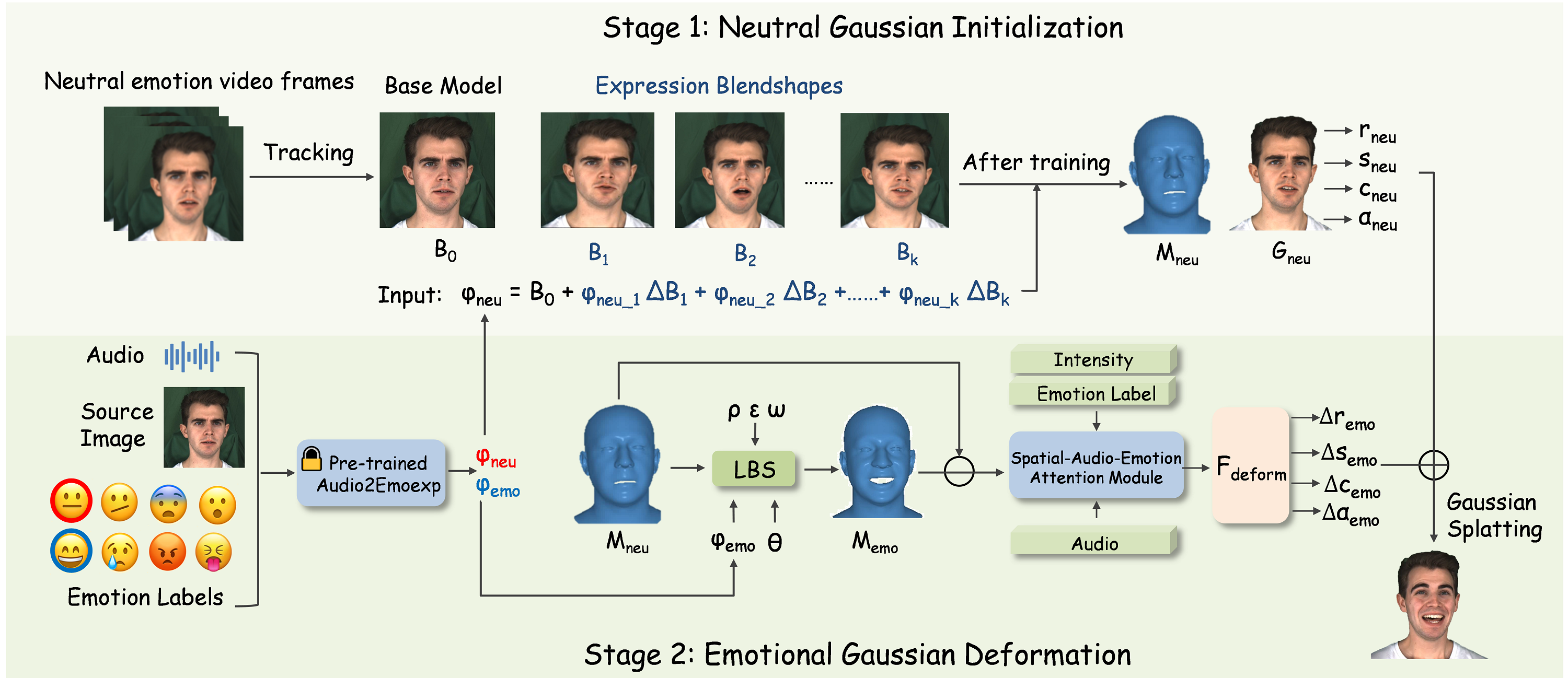
方法总览把系统说成两阶段。给定目标人物的 neutral speaking video,Stage 1 用 GaussianBlendshapes 构建 character-specific neutral state space。随后,一个预训练 audio-to-expression model 从输入 audio 预测 facial expression;这个 expression 进入 neutral state space,产生 neutral mesh 和 neutral Gaussian properties。Stage 2 再用 3D Gaussians 构建 emotional deformation space,通过 cross-attention 融合 spatial、audio、emotion 信息,得到相对 neutral space 的 Gaussian property offsets。
Neutral Gaussian Initialization 的数据准备依赖 face tracker。论文按 GaussianBlendshapes 的流程,从 neutral video clips 中计算 neutral FLAME mesh 和 50 个 basis expression meshes。这里的 “50 basis” 是表达空间的维度来源,不能误读成 50 个身份或 50 种情绪。
Gaussian 初始化分三块。$B_0$ 从 neutral FLAME mesh $M_0$ 上通过 Poisson disk sampling 放置点,作为 Gaussian 初始位置;每个 Gaussian 找到 $M_0$ 上最近的 triangle,并通过 triangle vertices 插值得到 LBS blend weights;mouth interior Gaussians $B_m$ 用两个预设 billboards 表示上下牙,再采样成 Gaussians。mouth interior 很实用,因为嘴部张合时牙齿区域会暴露,如果只建脸皮,很容易出现口腔空洞或贴图不稳定。
A2ET 是方法里最容易误解的部分。论文不是直接沿用 EAT 的 landmark decoder,而是复用 EAT 的 audio encoder 和 emotion-conditioning backbone,把 decoder 换成轻量 FLAME coefficient regression heads。它预测 FLAME expression vector $\psi$ 和 local pose vector $\theta=(\theta^{jaw},\theta^{neck})$,只包含 jaw 和 neck rotations。source image $I_s$ 是目标身份的固定 canonical neutral frame,用于保持 mouth geometry 和身份相关结构。
论文特别说明 MEAD 近似固定视角,因此不预测 global head pose 或 eye pose,而是把这些组件固定到 tracker 估计的 canonical values。这个约束很重要:GaussianEmoTalker 并不是自由摄像机轨迹下的通用头部运动生成器,它是在 aligned MEAD crop / fixed-view 设定下做高保真局部动态。
neutral expression $\psi_{neu}$ 进入预拟合的 GaussianBlendshapes,得到 neutral mesh 和 Gaussian attributes:
Emotional Gaussian Deformation 负责把 neutral space 推到 emotional space。论文参考 IMavatar,用 emotional expression 和 pose parameters 通过 LBS 得到 emotional mesh:
真正被 Stage 2 使用的空间 cue 是 $\Delta M=M_{emo}-M_{neu}$。它表达的不是绝对头部形状,而是“情绪让中性 mesh 怎样移动”。这一步把情绪的几何变化变成了 cross-attention 可以使用的 query 条件。
论文还加入 AU45、camera code 和 null token 来拆分 speech-related motion 与非语音因素。AU45 来自 FACS,用来表示 eye blink;tracked camera parameters $c_n$ 吸收 aligned crop 中剩余的轻微视角变化;null token $z_\emptyset$ 是和其它条件通道同维度的全零向量。对第 $n$ 帧,attention 初始 query 是:
null token 的解释很值得注意。它不是为了增加信息,而是提供一个 global anchor,让 attention 不必把所有通道都强行绑定到高频 audio fluctuation 上。论文在消融里说去掉它会带来 inter-frame instability,这个机制解释是合理的:静态皮肤颜色、头发、长期动态惯性不应该每一帧都被语音强行驱动。
emotion 和 intensity 使用 CLIP TextEncoder 编码。emotion text 包括 happy、sad、fear、disgusted、contempt、angry、surprised;intensity text 是 level1、level2、level3。它们分别得到 $f_e$ 和 $f_s$:
这里有一个明显边界:论文使用文本 embedding 表示离散强度级别,但没有证明 level1 到 level3 之间可以可靠插值。因此 limitation 说不能生成 1.5 或 2.5 这样的连续强度,并不是偶然限制,而是当前条件设计没有训练连续强度监督。
spatial-audio-emotion cross-attention 的作用,是避免用固定 3D point 的 element-wise multiplication 来绑定 audio / emotion 权重。动态 talking head 中,同一个 3D coordinate 未必一直对应同一脸部语义区域;如果权重固定,训练会难收敛。cross-attention 让 spatial query $q_n$、audio feature $a_n$、emotion feature $f_e$ 和 intensity feature $f_s$ 交互。
最后,deformation network 用 MLP regressors 预测 Gaussian 属性残差:
final emotional Gaussian attributes 是 neutral attributes 加 residual。论文文字里 opacity 记号有 $\alpha$ 和 $o$ 的混用,这不影响理解,但说明当前 v1 文稿还存在编辑层面的不严谨。

Training Objectives 覆盖两阶段。RGB loss 直接约束像素,VGG feature loss 约束 perceptual quality,FLAME loss 用最近 FLAME vertex 的 pseudo ground truth 监督 deformation network 的 expression、pose 和 skinning weight 相关预测,最后加 D-SSIM:
实现细节明确给了 Stage 2 训练 5000 iterations、RTX 3090、Adam、initial LR 0.0001 衰减到 0.00001,loss 权重为 $\lambda_{\mathrm{RGB}}=1$、$\lambda_{\mathrm{D-SSIM}}=0.25$、$\lambda_{\mathrm{flame}}=1$、$\lambda_{\mathrm{vgg}}=0.1$,FLAME loss 内部 $\lambda_e=1000$、$\lambda_p=1000$、$\lambda_w=1$。缺失的是 Gaussian count、attention layer number $L$、hidden dim、batch sampling、tracker / CLIP / SyncNet 具体版本和 A2ET 训练细节。
Experiments
实验使用 MEAD。论文说每个 actor video crop 到 $512\times512$,覆盖 8 种 emotion 和 3 个 intensity levels;每个 identity 的 independent video clips 按 9:1 划分 train/test,所以测试集是 unseen sequences。每次训练基于 monocular data。这意味着评测是在 person-specific fixed-view setting 下进行的,不应扩大解释成跨身份、自由视角、开放场景生成。
指标分两类。self-driven 有 ground truth frame,所以可以评估视频质量、运动和嘴型同步:FID、FVD、PSNR、SSIM、LPIPS、CPBD、mouth / face LD、LVD、Sync conf 和 FPS。cross-driven 没有 ground truth image,论文改用 Sync、LMD 和 AUE。self-driven 更像 reconstruction / reenactment 质量评估,cross-driven 更像换音频后的嘴型同步和动作合理性评估。
baseline 包括 SadTalker、EAT、EDTalk、GSBS 和 EmoTaG。GSBS 是被改进的直接基础,EmoTaG 是较近的 emotion-aware Gaussian baseline,SadTalker / EAT / EDTalk 更像不同范式的 talking head 代表。公平性需要谨慎:person-specific 3DGS、one-shot、few-shot personalization 和 diffusion/2D 方法放在同一表里,训练数据和推理条件可能并不完全对齐。


self-driven 定量表里,Ours 在多数指标上最好:FID 26.36、FVD 132.34、PSNR 32.40、SSIM 0.84、LPIPS 0.18、CPBD 0.46、Sync conf 5.23、FPS 40.0。最接近的强 baseline 是 EmoTaG,PSNR 32.22、SSIM 0.82、LPIPS 0.19、Sync conf 5.08、FPS 33.0。GSBS 的 FPS 更高,为 51.0,但质量和 Sync conf 低于 Ours。这支持论文的主要权衡:Stage 2 residual deformation 牺牲部分速度,换来更强的情绪表达和同步质量。
| Method | FID↓ | FVD↓ | PSNR↑ | SSIM↑ | LPIPS↓ | Sync conf↑ | FPS↑ |
|---|---|---|---|---|---|---|---|
| GSBS | 32.33 | 169.32 | 30.78 | 0.75 | 0.27 | 4.34 | 51.0 |
| EmoTaG | 27.95 | 136.82 | 32.22 | 0.82 | 0.19 | 5.08 | 33.0 |
| Ours-Combine | 27.77 | 134.46 | 32.35 | 0.82 | 0.17 | 5.19 | -- |
| Ours | 26.36 | 132.34 | 32.40 | 0.84 | 0.18 | 5.23 | 40.0 |
cross-driven 用四段与目标身份无关、且不在 test set 中的 audio。论文说测试所有 emotion labels 和 intensities 后取平均。Ours 在 Audio I 到 IV 的 Sync 分别为 5.235、5.164、5.431、5.453,整体优于或接近最好;LMD 和 AUE 也通常最低。因为没有 ground truth image,cross-driven 的视觉质量不能用 PSNR / SSIM 证明,只能依赖同步指标、动作误差和 qualitative examples。
user study 有 20 名参与者,都是计算机视觉背景的硕士或博士学生。论文把 intensity level 3 下 8 个 emotion、3 个代表 actor 合成 24 个关键测试序列,并让参与者按 emotional accuracy、audio-visual synchronization、identity consistency、video quality 评价。Ours 得到 40%、60%、35%、75%,EmoTaG 分别为 35%、10%、20%、20%。这支持主观感知质量,但样本规模和参与者分布都较窄,不能替代大规模用户偏好研究。
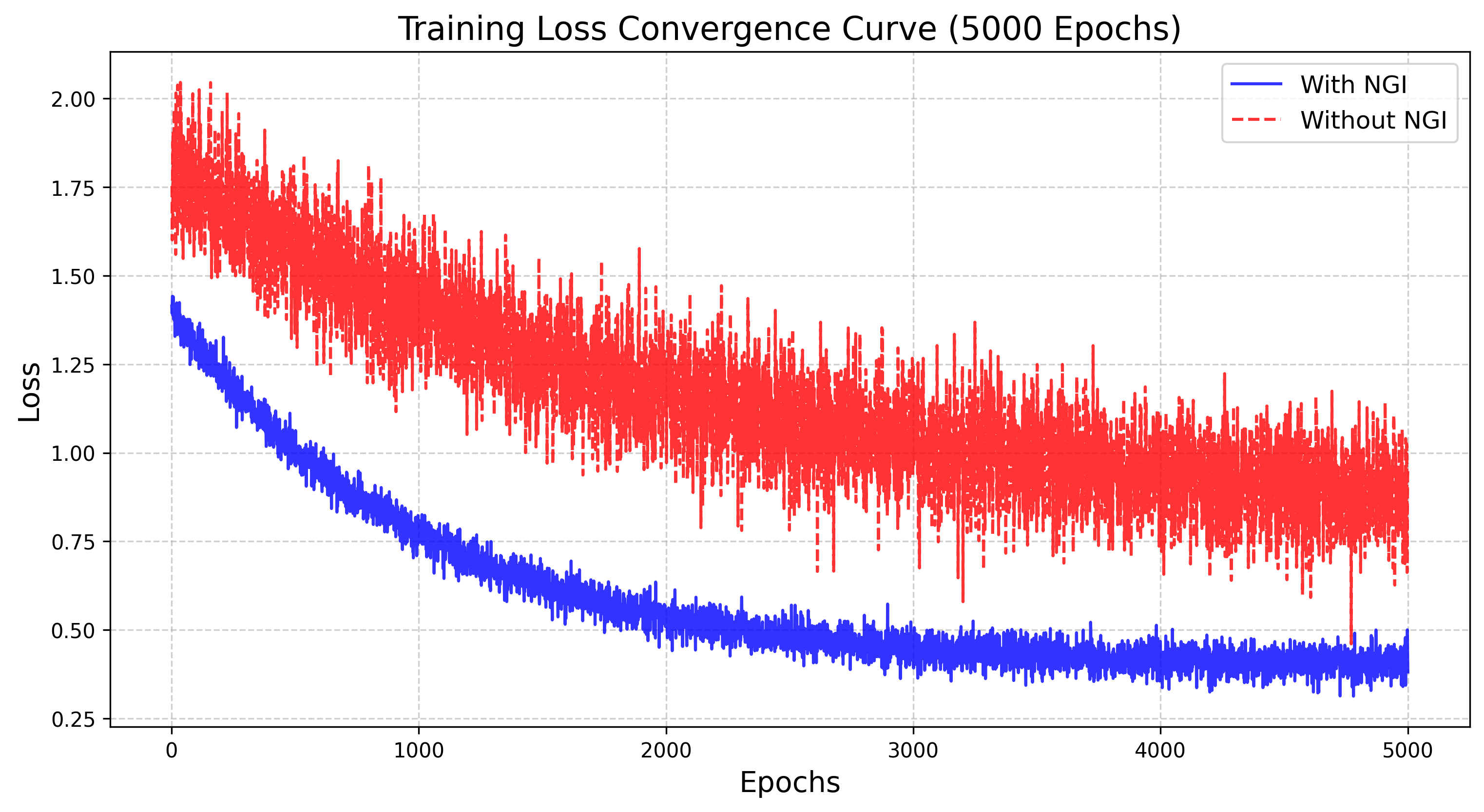
消融实验比主表更能说明机制。NGI 消融去掉 Stage 1,让 Stage 2 直接输出 final emotional Gaussian attributes,而不是 residual offsets。论文说这种设置训练难以收敛,loss 振荡明显;训练时间上,without NGI 需要约 10h+ 且仍难收敛,with NGI 只需 Stage 1 约 0.5h、Stage 2 约 3h。这说明 neutral state space 不只是初始化技巧,它把问题从“从零生成情绪 Gaussian”变成“在稳定身份空间上学残差”。
EGD 消融去掉 Stage 2,但不去掉 audio-to-expression module。结果是情绪表达能力受限,尤其强情绪和夸张表情难以捕捉。原因在于线性 facial expression base model 的表达能力有限;EGD 的作用就是让 Gaussian attributes 在 emotion space 里进一步非线性调整。

A2ET 消融说明,如果没有 audio-to-expression module,模型更依赖 tracking-derived expression coefficients,最终情绪表达不足。这个结果说明 A2ET 不只是前处理,它决定了 LBS 得到的 $M_{emo}$ 是否可靠,从而影响 $\Delta M$ 这个关键空间 cue。
Null Vector 消融显示去掉全零 global anchor 会导致 inter-frame instability 和 convergence difficulty。论文的解释是,null token 帮助 attention 解耦 motion-independent static attributes 和 long-term dynamics,避免静态区域被高频 speech features 拖着抖。这个 claim 有定量表支持,但更理想的验证应包括 temporal jitter / temporal LPIPS 一类直接稳定性指标。
Limitation, Discussion, Conclusion
论文明确承认两个限制。一个是 person-specific:每个模型只能生成单个 identity,需要为目标人物训练一个神经网络。这不是实现小缺口,而是方法设定本身。它适合 professional digital avatars 和 personal digital twins,因为这些场景更重视身份细节和稳定性;如果要跨身份泛化,需要转向 GAGAvatar 这类 identity-generalizable Gaussian model。
另一个限制是情绪强度不连续。GaussianEmoTalker 只能控制 level1、level2、level3,不能生成 1.5 或 2.5 这样的中间强度。作者提到可以尝试 facial prior 的 linear interpolation 或 Gaussian mixture interpolation,但这只是未来方向,不是本文已证明的能力。
Discussion 对边界讲得更具体:框架基于 identity-specific monocular training,每个模型使用 MEAD 中单个一致视角的视频片段训练。固定视角让生成 head pose 自然对齐原数据,但也意味着模型不尝试预测 arbitrary global camera trajectories 或 3D head movements。局部解剖合理性主要由 FLAME kinematic chain 的 jaw / neck rotations 维持。
论文还把动态表现归因于 spatial-audio-emotion attention:audio features 和 emotion labels 被映射到 Gaussian attribute offsets,从而产生嘴角轻微抽动、眉毛运动等 micro-expression。因为模型按身份训练,它能记住某个人的微表情习惯。这是 person-specific 的优势,也是泛化风险:换身份时这些习惯并不会自动迁移。
Conclusion 把方法压回两个阶段:Stage 1 基于 GaussianBlendShapes 构建 neutral state space;Stage 2 用 3D Gaussians 建 emotional Gaussian deformation space,并通过 neutral / emotional mesh offsets 构造 spatial-audio-emotion cross-attention,学习 audio、emotion label 和 intensity 如何影响 neutral state space 中的 Gaussian attribute offsets。
当前可确认的信息包括:arXiv v1 和 TeX source 可访问;项目页可访问并显示 under submission;项目网站仓库公开,但它是静态网页内容;论文给出 MEAD、512 x 512 crop、per-identity 9:1 clip split、Stage 2 5000 iterations、Adam、RTX 3090、LR 和 loss 权重。
缺失或未公开的信息也很关键:训练 / 推理代码、checkpoint、每个身份的 split list、face alignment 和 tracker 配置、Gaussian 数量、attention 层数 $L$、hidden dimensions、CLIP text encoder 版本、A2ET regression heads 的训练细节、baseline 版本和重训协议、Sync / LD / LVD / LMD / AUE 的完整评测脚本。若要复现,不能只按论文公式实现;这些细节会明显影响结果。
论文还有一些 v1 文稿痕迹,例如表头里 face velocity 列疑似重复写成 M-LVD,opacity 在公式和文字里有 $\alpha$ / $o$ 的记号混用。这些问题不改变主线,但说明当前稿件还在 active editing 状态。写 related work 时可以引用其方法思路和实验结论;做工程复现时需要等待代码或向作者确认细节。
概念补充与参考阅读
3D Gaussian Splatting
它把场景表示成许多显式 3D Gaussians,并通过 splatting 快速渲染到图像平面。GaussianEmoTalker 使用它,是因为每个 Gaussian 的 rotation、scale、color、opacity 都可以被直接调整,适合做实时头像的局部形变。
参考阅读:project page / arXiv:2308.04079
GaussianBlendshapes
它把 FLAME / Blendshape 的表情基思想移到 3D Gaussian head avatar 上,用 neutral base 加 expression bases 表示不同表情。GaussianEmoTalker 的 Stage 1 建立在这个思想上,只是后续又增加了情绪残差分支。
FLAME / LBS
FLAME 是可参数化的人脸模型,LBS 是把 pose 和 expression deformation 应用到 mesh 上的标准 skinning 机制。GaussianEmoTalker 用 A2ET 预测 FLAME expression 和 jaw/neck pose,再用 LBS 得到 $M_{emo}$,从而计算 $\Delta M$。
参考阅读:FLAME official page
A2ET / EAT
EAT 是 audio-driven talking-head 里的 emotion adaptation 方法。GaussianEmoTalker 复用它的 audio encoder 和 emotion-conditioning backbone,但把 landmark decoder 替换成 FLAME coefficient regression heads,所以这里的 A2ET 更像“音频到 FLAME expression / local pose”的桥。
参考阅读:EAT CVF paper
MEAD
MEAD 是多视角 emotional talking-face 数据集,包含 8 种情绪和 3 个强度等级,是这篇论文能讨论 intensity control 的数据基础。GaussianEmoTalker 在 MEAD 上按身份做 9:1 clip split。
参考阅读:MEAD project page
CLIP TextEncoder
CLIP 用自然语言和图像对齐训练出文本/图像表示。这里仅用 text encoder 把 emotion 和 intensity words 编成条件向量;它不是在本文里直接做图文匹配。
参考阅读:CLIP
FID / FVD / LPIPS / SyncNet
FID 看生成图像分布,FVD 看视频分布,LPIPS 用深层特征衡量感知差异,SyncNet confidence 常用于估计音画同步。GaussianEmoTalker 用这些指标分别支撑画面质量、视频质量、感知质量和 lip sync claim。
总结
一句话总结:GaussianEmoTalker 把实时情绪说话头像拆成“中性身份说话空间 + 情绪条件 Gaussian 残差”,用 3DGS 的显式可渲染表示来同时追求表情控制、身份细节和实时速度。
一句话评价:这是一条机制清楚、实验链条较完整的 person-specific emotional avatar 路线,但当前代码和评测脚本未公开,工程复现价值要等实现细节补齐后才能真正落地。
对研究阅读来说,它最值得借鉴的是 decomposition。先学稳定的 identity-specific base space,再把 style / emotion / intensity 学成条件残差,这个思想可以迁移到很多 avatar 控制问题里。对工程实现来说,最大风险也在同一个地方:一旦 base space、A2ET 或 tracker 的输出不稳,Stage 2 学到的 residual 就会建立在错误锚点上,强情绪表现和嘴型同步都会被连带影响。
Recommended citation: Yang et al., GaussianEmoTalker: Real-Time Emotional Talking Head Synthesis with Audio-Driven and Blendshape-Based 3D Gaussian Splatting. arXiv:2607.00959v1, 2026.
Download Paper