
AvatarForcing 精读:一步流式 diffusion 如何稳住分钟级 talking avatar
AvatarForcing 精读:一步流式 diffusion 如何稳住分钟级 talking avatar
AvatarForcing 讨论的是一个很具体的问题:系统一边接收语音,一边生成 talking avatar 视频,而且不能只在前几秒好看,长到一分钟、两分钟以后仍要维持同一个人的身份、肤色、衣着、头部运动和口型同步。
开篇导读
短视频 talking avatar 可以先拿到完整音频和完整条件,再用多步 diffusion 慢慢去噪。实时长视频不允许这样做:已经输出的帧不能回头重画,未来语音也只能提前看很短一段,推理成本还必须接近常数。AvatarForcing 的切入点就是在这个约束下重新安排 diffusion 的生成顺序。
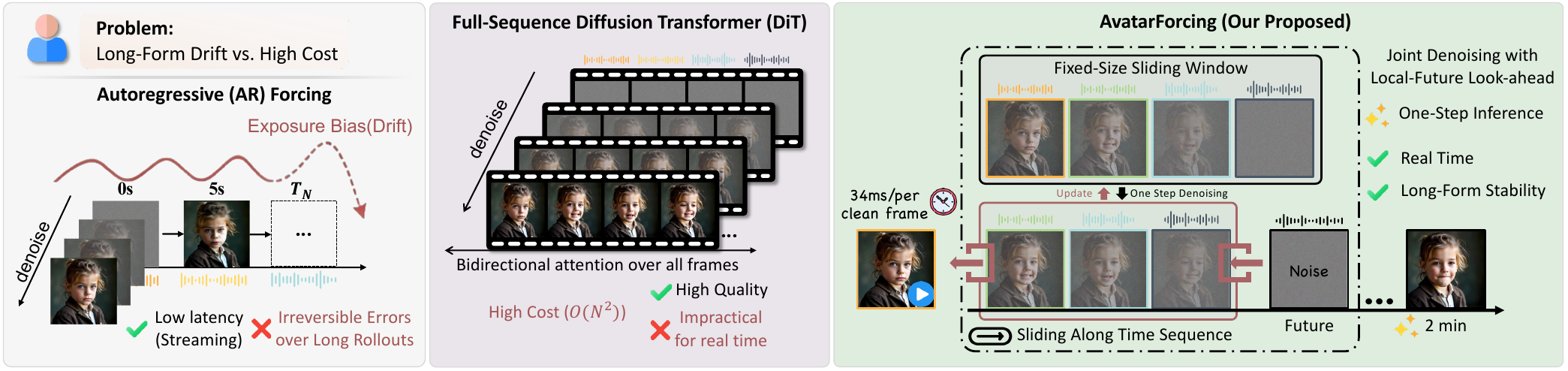
teaser 把三种路线放在一起。严格 autoregressive forcing 可以流式输出,但它每一步都把自己的输出当成后续条件,小错误容易变成长期漂移。Full-sequence DiT 能用双向 attention 看完整视频,所以更稳,但算力和延迟随序列长度变大,不适合实时长流。AvatarForcing 夹在二者之间:它不看完整未来,只看一个固定大小的 local-future window,并且每步只发出最左边已经足够干净的 block。
Abstract
摘要一开始就把任务目标压得很紧:real-time talking avatar 既要 low latency,又要 minute-level temporal stability。这里的“稳定”不是单帧好看,而是长时间生成后身份、颜色、表情风格、头部姿态和口型都不能慢慢偏掉。也就是说,本文评价的核心不是普通短片质量,而是长 rollout 中错误是否会累积。
AR forcing 看起来很适合这个任务,因为它能顺序生成,当前帧出来后马上交给用户;真正麻烦的是 exposure bias。这个概念可以理解为训练和推理看到的历史不一样:训练时历史更干净,推理时历史里混着模型自己早先犯过的错。因为视频帧一旦发出就不可逆,肤色、脸型、姿态或口型的小偏差会被后续帧继承,长时间后就变成漂移和闪烁。
full-sequence diffusion transformer 处在另一端。它能缓解漂移,是因为每次 denoising 可以在完整序列上做双向 attention,让前后帧互相约束。但这条路线要处理所有帧,视频越长,attention 和显存成本越高;对实时 long-form synthesis 来说,它不是模型能力不够,而是系统预算不允许。
AvatarForcing 的核心动作是维护一个固定 local-future window:窗口里不同 block 有不同噪声级别,每一步对整个窗口联合去噪,然后只发出一个 clean block。这里的 heterogeneous noise levels 很重要:左边 block 更接近 clean,适合输出;右边 block 更 noisy,但仍能提供未来运动和结构的大致线索。这样做让每一步的计算只依赖固定窗口,不随视频总长度增长。
长流稳定性靠 dual anchor 继续补上。style anchor 通过 RoPE re-indexing 保持 reference frame 和当前窗口的固定相对位置,避免参考图在长视频里变成“远古帧”;anchor-audio zero-padding 让这个参考只提供外观,不携带旧语音;temporal anchor 则复用最近已经输出的 clean blocks,让窗口边界处的运动更连续。
one-step inference 也不是直接把 teacher 压成一步就完事,而是 two-stage streaming distillation。offline ODE backfill 先给 student 一个从中间噪声回到 clean endpoint 的初始化,distribution matching 再让 student 在自己的 rolling-window 分布上被校正。实验报告 1.3B student 达到 34 ms/frame,并在标准 benchmark 和 400-video long-form benchmark 上保持视觉质量和唇形同步。这个数字说明 steady-state compute 很快,但不能替代端到端延迟分析。
Introduction
Introduction 从应用场景进入:talking-avatar video synthesis 是 digital human 里的核心问题,用在虚拟沟通、内容创作和 embodied AI。作者随即列出近年的进展来源,audio-conditioned DiT、text-conditioned video model、portrait input 都让短片的 fidelity 和 controllability 变好了。这里不是泛泛说已有方法强,而是在铺垫一个转折:短片质量提高,不等于能做 real-time long-form streaming。
本文把任务重新定义为系统约束:每帧延迟要接近常数,视频持续数分钟后 appearance 仍要稳定,不能出现 identity drift 或 color drift。作者把“分钟级稳定”放在和“实时”同等重要的位置,因为 talking avatar 一旦进入交互或直播场景,最破坏体验的往往不是某一帧不够锐,而是越说越不像同一个人。
这种要求马上暴露出 DiT attention 的矛盾。Full-sequence bidirectional attention 每个 denoising step 都处理所有帧,因此短视频可以用全局上下文换稳定性,长流时却无法维持 constant-latency streaming。很多 diffusion pipeline 还假设 control signals 预先可得,这对于边说边生成的交互式输入也不合适。换句话说,它们的默认问题设定和真实 streaming 不一致。
autoregressive denoising 解决了实时输出,却牺牲了纠错空间。AR 通过 causal conditioning 逐帧预测,所以支持 streaming;但是 strict causality 带来 exposure bias:发出的帧被固定成历史,后面不能修改。几千步以后,早期一个很小的表情、颜色或运动偏差都可能被不断放大。self-forcing 和 teacher-guided forcing 之类训练方法能缩小 train-test gap,但推理时仍然严格因果,没有可靠 look-ahead,也没有长期 identity re-anchor 机制。
AvatarForcing 先在保持常数延迟的前提下引入 bounded look-ahead。它不再只对一个当前 block 做因果去噪,而是维护一个固定长度的 latent block window,窗口内不同 block 处在不同噪声级别。每一步对整个窗口做一次 joint denoising,发出左侧 block,窗口左移,再在右侧追加 fresh noise。
这套动作对长 rollout 有双重作用:当前 generation frontier 能看到一小段未来,虽然未来 block 仍是 noisy latent,但其中已经带有粗运动和结构信息;同一个 block 从右侧进入窗口到左侧发出,会被反复访问和修正,而不是一次预测后立刻提交给历史。它保留了 streaming emission,又让当前帧在发出前经历局部联合修正。
这个机制可以抽象成预算分配问题。作者定义 $\mathcal{B}_{L,N}$:$L$ 是窗口里的 block 数,$N$ 是每个 streaming step 的 joint denoising pass 数。forcing-style causal methods 接近 $L=1$,靠更大的 $N$ 做 refinement;AvatarForcing 选择 $N=1$,把预算更多放到 $L$,也就是给模型一点固定长度的未来线索。
这里的判断很关键:在相同 $L\cdot N$ 计算预算下,扩大窗口往往比在短上下文里重复去噪更能改善 long-horizon stability。原因不是 noisy future 已经给出了答案,而是它减少了当前 frontier 的不确定性,比如未来头部运动方向、嘴部开合趋势和局部结构连续性。后面的 L vs N 消融就是为这句话提供证据。
bounded look-ahead 仍然不够。窗口长度固定,帧一旦离开窗口仍然不可修改,所以分钟级身份和颜色漂移还会出现。作者因此加入 dual-anchor KV cache。KV cache 是 Transformer attention 里的 key/value 缓存,这里不是为了无限记住所有历史,而是保存两个有限但关键的锚点:一个长期 style anchor,一个短期 temporal anchor。
style anchor 保存 reference frame 作为外观和身份提示。它的难点在 RoPE 上:RoPE 通过旋转相位编码位置,如果 reference frame 永远处在序列起点,当前窗口时间 index 越来越大,二者的相对相位会越来越远,attention 中的参考关系会变弱。RoPE re-indexing 的做法是把 style anchor 的 key 存在 pre-RoPE space,每一步用当前窗口附近的虚拟位置重新施加 RoPE,让 reference 像一直贴在当前窗口前方。temporal anchor 则缓存最近输出的 clean blocks,用来保持头部运动、嘴部轨迹和窗口边界的连续性。
audio 条件还需要避免污染 anchor。per-frame audio tokens 要和 active window 对齐,因为当前口型应该由当前语音决定;早期 reference frame 只应提供身份和外观。因此 anchor frames 的 audio features 被置零,避免旧语音内容通过 anchor pathway 影响当前嘴部运动。
one-step student 的训练则依赖 global bidirectional teacher 和两阶段蒸馏。offline ODE backfill 记录 teacher trajectory,用 audio-conditioned ODE regression 学会从中间噪声一步预测 clean endpoint;DMD-based distribution matching 再在 rolling-window student simulations 上训练,让 student 看到真实推理时会遇到的 heterogeneous-noise windows 和 KV cache。这里真正解决的是分布错位:如果 student 只在离线干净设置中训练,放进滑窗长流以后仍会漂。
评价范围也围绕这套机制展开。论文评估 diverse benchmarks,并引入 400-video long-form benchmark,同时报告短片质量指标和长程稳定指标。四条贡献对应前面的四个逻辑点:$\mathcal{B}_{L,N}$ 的 one-step local-future denoising、dual-anchor KV cache、two-stage distillation,以及 1.3B student 在 34 ms/frame 下的 long-form 实验结果。
Method
方法部分先把输入和目标重新落到系统形态上:给 reference image,以及 audio/text 等 control signals,生成 long-horizon audio-driven talking-avatar video。目标同时包含 real-time latency、stable identity 和 temporally consistent motion。随后作者把方法压成三根支柱:local-future window joint denoising、dual-anchor KV caching、two-stage streaming distillation。
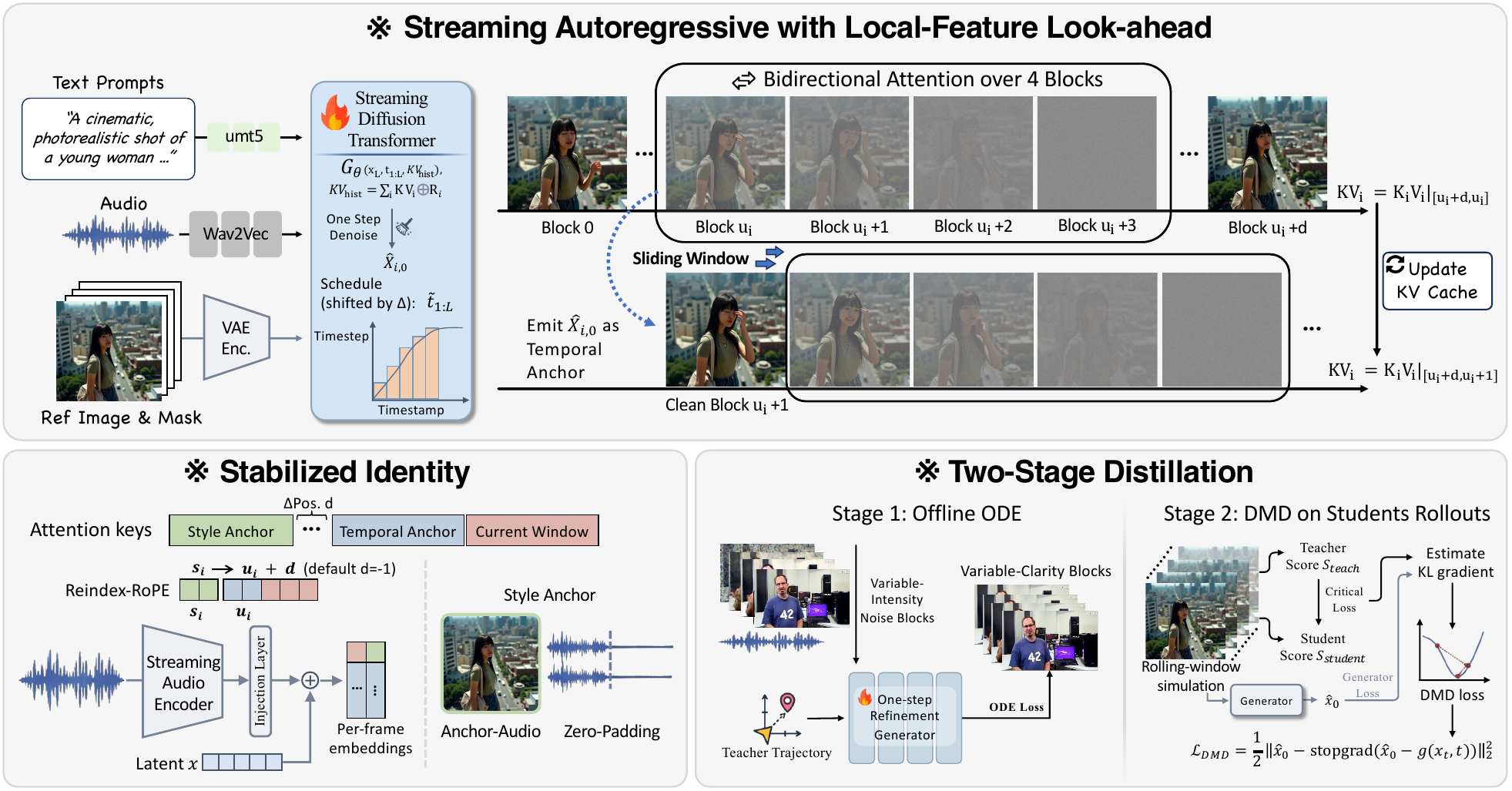
为了让滑窗机制可计算,论文把 $B$ 个连续 latent frames 合成一个 block,默认 $B=4$,这也是 KV cache 的粒度。窗口有 $L$ 个 block,每个 streaming step 对这个窗口做 $N$ 次 joint denoising,发出一个 clean block。因此一个 block 在发出前大约经历 $L\cdot N$ 次更新。这里的 one-step 指的是 $N=1$,也就是每个 streaming step 只有一次 joint denoising pass;它不意味着每个 block 从出生到发出只被处理一次。
Rolling-window sequential denoising 先批评传统单帧因果去噪。因果方式高效,但默认“局部最优帧连续起来仍然全局一致”。实践上这个假设很脆弱,appearance、geometry、motion 的小错误一旦提交成历史,就无法修正。AvatarForcing 要保留 streaming emission,同时让 generation frontier 附近能做 bounded joint refinement。
具体地,在 streaming step $i$,窗口写成:
每个 block $\mathbf{x}_k \in \mathbb{R}^{B\times C\times H\times W}$,噪声级别满足 $t_1<\cdots 这形成了一个 graded refinement band:左边 block 做细修,准备输出;右边 block 仍然粗糙,但可以承担更大结构更新。这样的设计把未来信息压缩成短窗口里的 noisy latents,既没有 full-sequence DiT 那样看完整未来,也比严格 AR 多了一点前方线索。 local-future guidance 的关键在窗口内 bidirectional self-attention。当前要发出的 block 可以 attend 到整个 $L$-block buffer,包括还没有 clean 的未来 block。look-ahead 被严格限制在 $(L-1)$ 个 blocks,因此系统成本不随总时长增长。对默认 $L=4,B=4,25$ FPS 来说,算法上需要 $(4-1)\times4=12$ 帧未来音频,也就是约 0.48 秒 audio look-ahead。 作者接着解释为什么 noisy-future correction 比 repeated sampling 更有效。在固定延迟预算下,增加 $N$ 只是对同一短窗口反复 refine,不会增加可用于消歧的上下文;如果模型已经受到因果历史偏差影响,重复 refine 还可能把系统性偏差变得更平滑。增加 $L$ 则不同,它把未来 block 的粗运动和结构趋势引进来,可以在当前 block 发出前减少边界不连续和姿态不确定性。 student forward 公式把实际输入列全了: 模型同时看窗口 latent、每个 block 的 timestep、历史 KV,以及窗口对齐的 audio embedding。输出是整个窗口的 clean prediction $\widehat{X}^{i}_0$,但真正发给用户的只有左侧 $\widehat{\mathbf{x}}_{i,0}$。窗口里的其他 block 会继续留下来,下一步再被更新。 论文随后写出窗口更新:发出左侧 block 后,下一窗口包含上一轮剩余的预测 block,再在右侧追加 fresh noise $\mathbf{x}_{i+L}^{t_L}\sim\mathcal{N}(0,I)$。这说明 AvatarForcing 的“流式”不是每次独立生成新片段,而是让片段在窗口里逐步移动、逐步变干净,直到到达最左侧才提交。 算法伪代码把在线流程排成循环:初始化窗口和 KV;计算 window audio features,把 anchor audio 设为零;重新索引 style-anchor RoPE 并组装 attention keys;运行 $N$ 次 denoising;发出左侧 block 并更新 temporal KV;滑动窗口并追加 fresh noise。读伪代码时要注意,style anchor、temporal cache、current window 共同组成 attention 上下文,而不是只有滑窗本身。 Dual-anchor KV caching 部分先承认 rolling window 的边界:它只能覆盖短范围,帧离开窗口后无法重访,所以 identity、color tone、expression style 仍可能慢慢漂。为此作者把 attention keys 组装成 `[style anchor | temporal cache | current window]`。temporal cache 长度有固定 token budget,所以 per-step compute 仍然保持常数。 temporal anchor 的作用很直接:发出 clean block 后,把对应 KV states 写入 rolling cache,只保留最近的 clean tokens。它稳定的是短期动态,比如头部运动、嘴部轨迹和窗口滑动时的边界 flicker。它不是长期身份记忆,因为缓存预算有限,旧内容会被替换。 style anchor 处理的是另一件事:reference frame 要长期作为身份和外观提示。论文把 keys 缓存在 pre-RoPE space,每一步用当前上下文首个非 anchor frame 的 index $u_i$ 加固定偏移 $d$ 重新应用 RoPE,默认 $d=-1$: 这句话背后的含义是:reference frame 不再被当成时间轴起点附近的老帧,而是每一步都被放在当前窗口前方的虚拟位置。这样做避免了随着 $u_i$ 增长产生的 RoPE phase mismatch,也让 style anchor 更像外观参考,而不是历史片段。 audio injection 的设计重点是避免连续音频在 sliding windows 和 non-consecutive visual frames 之间串扰,否则容易表现为 lip jitter 或 phoneme misalignment。作者没有新增复杂 cross-attention,而是用 pretrained streaming speech encoder 得到 per-frame embedding $a_t$,再投影到模型维度,加到 latent patch tokens 上: anchor-audio zero padding 在这里非常关键。早期 anchor frame 被反复使用,如果它携带原来的语音特征,就可能把旧 speech content 注入当前窗口,导致嘴部运动被错误语音牵引。把 anchor audio features 设为零后,anchor 只负责视觉身份,当前窗口的 per-frame audio 才负责实际口型控制。 Distribution-matching post-training 解释 student 如何适应真实推理分布。给定 rolling-window simulation 产生的 student prediction $\widehat{x}_0$,训练过程采样 timestep $t$,加噪得到 $x_t$,用 frozen teacher score 和 trainable critic 估计 KL gradient $g(x_t,t)$,再用 DMD loss 更新 generator: 这里的重点不是让读者记公式,而是理解训练分布。offline ODE backfill 提供 one-step denoising 初始化,DMD 在 student 自己的 rolling-window rollout 上做分布匹配。这样 student 训练时就会遇到 heterogeneous-noise windows、KV caching 和滑窗状态,而不是只在完整离线序列里学一个理想映射。
Experiments
实验设置先交代训练数据、teacher 和评测范围。训练使用 AVSpeech 和 extended EMO corpus,约 500 小时 paired audio-video data,覆盖不同说话人、情绪表达和录制条件。teacher 是从 WanS2V 初始化的 bidirectional audio-video diffusion teacher,用来提供 distribution-matching targets。这里能确定的是论文给出的数据规模和来源名称;extended EMO 的具体构成、清洗、授权和 split 没在正文完整展开。
为了评估 streaming generation,作者构建了 nearly 400 videos 的 long-form benchmark,视频长度从 40 秒到 2 分钟,并同时报告 CelebV-HQ 这个标准高分辨率 benchmark。这个设置对应全文主旨:短片指标只能说明普通生成质量,长视频 benchmark 才能暴露 identity drift、color drift、lip sync 退化和 flicker。
指标也分成几类。FID 和 FVD 衡量图像/视频分布质量;CSIM 衡量 identity preservation;Sync-C/Sync-D 衡量 audio-visual alignment;$\Delta E_{2000}$ 用来看颜色漂移,Adj-LPIPS 用 adjacent frames 的感知距离看 flicker。读这些指标时不能只看单一数值,因为 CSIM 依赖人脸 embedding,Sync 指标依赖同步模型,FID/FVD 也受裁剪和分布影响;更可靠的是看多个指标是否指向同一个结论。
系统设置给出复现实验的主要骨架:pretrained 1.3B video diffusion backbone,默认 $B=4$ frames/block,$\mathcal{B}_{4,1}$,25 FPS,VAE latent spatial resolution 对应 $832\times480$。训练阶段生成 16,000 teacher ODE trajectory pairs,先做 4,800 steps ODE regression pre-training,再做 2,500 steps DMD post-training。音频由 Wav2Vec 编码成 per-frame embeddings,并按窗口对齐后用轻量 additive modulation 注入。
State-of-the-art 比较覆盖 EchoMimic、Hallo3、HunyuanAvatar、FantasyTalking、OmniAvatar、MultiTalk、StableAvatar、LiveAvatar 和 WanS2V。作者说明 baseline 使用官方实现和推荐设置。主表中 AvatarForcing 在 long-form videos 上的 FID、FVD、CSIM、Sync-C 和 latency 都很强,Sync-D 略逊于 LiveAvatar,但 LiveAvatar 的延迟来自 5 GPUs pipeline,而 AvatarForcing 报告的是 single GPU、batch size 1、bfloat16 的 steady-state timing。
| Model | Long-form FID↓ | Long-form FVD↓ | Long-form CSIM↑ | Long-form Sync-C↑ | Long-form Sync-D↓ | Latency s/frame↓ |
|---|---|---|---|---|---|---|
| StableAvatar | 58.80 | 739.72 | 0.90 | 2.35 | 11.38 | 7.40 |
| LiveAvatar (5 GPUs) | 57.81 | 765.64 | 0.90 | 5.46 | 9.12 | 0.047 |
| WanS2V | 88.73 | 870.34 | 0.74 | 5.13 | 10.36 | 16.00 |
| AvatarForcing | 56.22 | 737.92 | 0.91 | 5.64 | 9.26 | 0.034 |

延迟协议单独列出来,是因为 34 ms/frame 容易被误读。论文定义的 steady-state latency 包括 streaming audio encoding、one DiT forward、KV cache update 和 VAE decoding,不包括模型初始化、数据加载、磁盘 I/O 和视频后处理。默认配置下它是 0.034 s/frame。端到端 audio-to-visual delay 还要加上 bounded local-future denoising 所需的 audio look-ahead:$(L-1)B/25=0.48$ 秒,论文报告默认 end-to-end delay 为 0.51 秒。
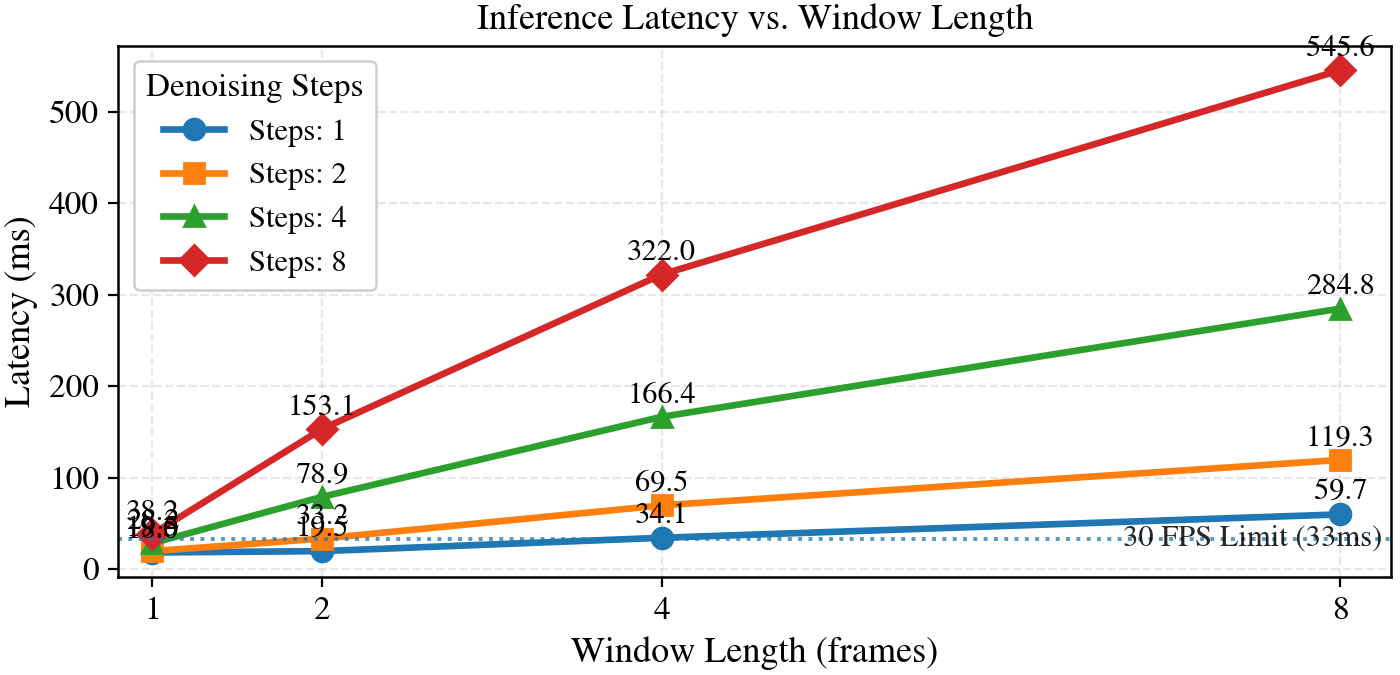
Ablation Studies 先隔离 $L$ 和 $N$。实验固定 dual-anchor KV cache、audio alignment 和 block size,只改变 bounded look-ahead 与 per-step refinement 的分配。$L=1$ 时没有 local-future look-ahead,变成 strictly causal block-level update;$N$ 增大则是在同一窗口上重复 denoising。
最关键的读法是 matched budget。$\mathcal{B}_{4,1}$ 与 $\mathcal{B}_{2,2}$ 都有 $L\cdot N=4$,延迟也相近,但前者 CSIM 0.90、Adj-LPIPS 1.06e-2、latency 34.14 ms,后者 CSIM 0.83、Adj-LPIPS 2.25e-2、latency 33.19 ms。这支持作者的核心判断:在 long-form avatar 里,引入有限未来上下文通常比在短上下文中反复 refine 更有效。与此同时,$L=8$ 或更大的 $L\cdot N$ 会显著增加延迟,并可能出现 over-smooth motion,所以默认 $\mathcal{B}_{4,1}$ 是折中,不是窗口越大越好。

Teacher/student 与 dual-anchor 消融关注长流稳定来源。Teacher 很强但 16 s/frame,无法实时;distilled student 更快但仍不够稳定;AvatarForcing 在 0.034 s/frame 下把 CSIM、$\Delta E_{2000}$ 和 Adj-LPIPS 拉到更好的长流区间。去掉 style anchor 后 CSIM 明显下降,说明 reference identity 不能只靠短窗口维持;去掉 temporal anchor 后 last-window CSIM 也下降,说明最近运动轨迹对后段稳定很重要。

One-step streaming baselines 用来排除一个误解:AvatarForcing 的收益不是来自“one-step”这个词本身。作者把 Self-Forcing 和 Causal ODE 改成 strictly causal one-step baselines。Self-Forcing (1-step) 的 CSIM 是 0.40/0.07,Causal ODE 是 0.58/0.32,而 AvatarForcing 是 0.90/0.86。这个差距说明,如果没有 local-future、dual anchor 和 rolling-window distribution matching,单纯一步化会带来严重 drift 或 blur。

最后的 additional ablations 针对 style anchor 的两个细节。没有 anchor-audio zero padding 时,style anchor 会接收不对齐的 speech dynamics,嘴部区域容易抖动或出现局部 artifact。没有 RoPE re-indexing 时,style anchor 随着 stream 变长在绝对时间上越来越远,phase mismatch 让 identity anchoring 变弱,表现为模糊、颜色漂移和身份退化。量化表里 w/o RoPE re-indexing 的 FVD 从 737.92 恶化到 1382.63,CSIM 从 0.90/0.86 降到 0.67/0.49,Sync-D 从 9.26 恶化到 19.23,这几乎是全篇最有力的设计证据之一。

Conclusion
Conclusion 回到总目标:AvatarForcing 是 real-time、long-form talking-avatar synthesis 的 one-step streaming diffusion framework,重点是 temporal consistency 和 accurate audio synchronization。它不是把 diffusion 全局生成问题简单压缩成一步,而是把一步推理放在固定 local-future window 里。
$\mathcal{B}_{L,N}$ 的作用在于让 sliding-window joint denoising 反复精修每个 block,再发出最左侧结果。bounded window 之外,系统还需要 dual-anchor KV cache:style anchor 用 RoPE re-indexing 稳定身份,temporal anchor 稳定过渡。audio 侧的边界也很清楚:per-frame audio 对齐 active window,anchor-audio zeroing 防止跨窗口干扰。
训练闭环由 two-stage distillation 完成:global bidirectional teacher 提供监督,distribution matching 支持 34 ms/frame inference。作者也保留了方法边界:larger windows 能减少 drift 但增加 latency,极长生成在 bounded context 不足时仍可能退化。未来工作会研究 stronger long-range memory 和 improved motion preservation。这说明 AvatarForcing 不是无限长视频的彻底解决方案,它仍是固定上下文和实时预算下的折中。
总结
一句话总结:AvatarForcing 把实时 talking avatar 的难点从“能不能一步生成”改写成“能不能在固定延迟里看见一点未来、记住身份,并把 student 训练到真实 rolling-window 分布”。
一句话评价:这篇论文的机制组合很清楚,long-form 证据也比较集中;但它仍依赖未完全公开的数据、benchmark 和训练细节,适合作为强工程路线参考,而不是完整闭合的复现实验包。
AvatarForcing 最有价值的地方是把实时长流 talking avatar 的问题拆成了清楚的机制组合:local-future window 解决严格因果缺少未来线索的问题,dual-anchor KV cache 解决窗口外身份和短期运动记忆的问题,two-stage distillation 解决 one-step student 与真实 rolling-window 推理分布不一致的问题。
$\mathcal{B}_{L,N}$ 是全文最值得带走的视角。它把“多跑几步”和“看远一点”放进同一个预算里比较,并用消融说明,在 long-form avatar 场景下,有限未来上下文往往比短窗口重复 refinement 更有用。但这个收益不是免费的:默认设置仍需要约 0.48 秒 audio look-ahead,窗口继续增大会推高延迟,甚至带来过平滑或运动冻结。
工程上可以把这篇论文看成一个 streaming diffusion 设计模板:不要只追求 one-step,要同时设计窗口、anchor、音频对齐和 rollout 分布训练。需要保留的边界也很明确:论文没有完整公开 extended EMO corpus 细节、long-form benchmark 列表、teacher/critic 全部训练 recipe 和完整评测脚本,因此公开推理能跑通并不等于主表可以完全复现。
概念补充与参考阅读
下面这些概念不是为了单独背术语,而是帮助读 AvatarForcing 时少卡壳:它们分别对应长流漂移、一步蒸馏、位置编码、attention 记忆、音频特征和评测指标。
Self-Forcing
Self-Forcing 关心的是 autoregressive video diffusion 的 train-test gap:训练时如果总看干净历史,推理时却只能接着自己生成过的历史走,模型就会在长 rollout 中暴露偏差。它的思路是在训练时也做 autoregressive rollout,并用 KV cache 让模型接触自己生成的上下文。AvatarForcing 提到它,是为了说明“让训练更像推理”很重要,但严格因果路线仍缺少 local-future look-ahead。
参考阅读:Self Forcing: Bridging the Train-Test Gap in Autoregressive Video Diffusion
Causal Forcing / Context Forcing
Causal Forcing 讨论的是把 bidirectional diffusion teacher 蒸馏成 autoregressive student 时的结构错位,并用 autoregressive teacher 做 ODE initialization,再接 DMD。Context Forcing 则强调 long-context teacher 对 long-context student 的监督,否则短上下文 teacher 很难教出长期一致性。它们和 AvatarForcing 的共同点是都在修正长视频推理分布,差别是 AvatarForcing 直接在固定窗口里放松严格因果,让当前输出能看见有限 noisy future。
DMD / Distribution Matching Distillation
DMD 的重点不是让 student 逐帧复刻 teacher 的某条采样轨迹,而是让 student 生成结果的分布靠近 teacher 或真实数据分布。直观地说,它不是问“这一张图必须长得和 teacher 这一步完全一样吗”,而是问“student 生成出来的整体样本像不像目标分布”。AvatarForcing 用 DMD post-training,是因为 one-step student 真正上线时面对的是 rolling-window、不同噪声级别和 KV cache 混合出来的分布。
RoPE / RoPE re-indexing
RoPE 把位置信息写进 attention 的旋转相位里,因此 token 之间的相对距离会影响 attention 关系。长视频里,如果 reference frame 永远停在时间轴起点,它和当前窗口的相对位置会越来越远,style anchor 的身份提示会被削弱。AvatarForcing 的 RoPE re-indexing 就是把 reference anchor 每一步重新放到当前窗口附近,让它继续像“贴身参考图”而不是“很久以前的一帧”。
参考阅读:RoFormer: Enhanced Transformer with Rotary Position Embedding
KV cache
Transformer 做 attention 时会为 token 计算 key 和 value;KV cache 就是把已经算过的 key/value 留下来,后续步骤可以继续拿它们参与 attention。大模型推理里它常用于加速自回归生成;在 AvatarForcing 里,它更像一个受控记忆槽。style anchor 用 KV 记住 reference identity,temporal anchor 用 KV 记住最近输出的 clean blocks,所以模型不用每步回看无限历史,也能维持身份和短期动作连续性。
Wav2Vec 2.0
Wav2Vec 2.0 是一种从原始语音中学习 speech representations 的自监督框架。放到 AvatarForcing 里,它不是直接输出嘴型,而是把连续音频转成 per-frame speech embedding,再和当前视频窗口对齐。这样模型得到的是“这一帧附近应该说什么”的语音条件,anchor audio zero-padding 则负责防止旧语音从参考帧路径混进来。
参考阅读:wav2vec 2.0
FID / FVD / CSIM / Sync-C / Sync-D
FID 看生成图像分布和真实图像分布的距离,FVD 把这个思路扩展到视频,额外关注时间动态。CSIM 通常可以理解为用人脸识别 embedding 做 identity similarity,回答“还像不像同一个人”。Sync-C/Sync-D 来自音画同步评估思路,关注嘴部视觉变化和语音是否对齐;所以 AvatarForcing 需要同时报告这些指标,因为画质、身份和口型同步不是同一件事。
参考阅读:FID / TTUR paper;FVD paper;SyncNet / VGG lip sync;ArcFace
exposure bias
exposure bias 指训练和推理看到的输入分布不一致:训练时模型常接触 ground-truth history,推理时却要接着自己之前生成的 imperfect outputs 往下走。对于文字生成,它可能表现为句子逐渐跑偏;对于 talking avatar,它会表现为身份、颜色、姿态和口型的小错误被不断继承。AvatarForcing 用 local-future window、anchor 和 rollout 分布训练,都是在不同层面压低这个问题。
参考阅读:Self Forcing
Recommended citation: Cui et al., AvatarForcing: One-Step Streaming Talking Avatars via Local-Future Sliding-Window Denoising. arXiv:2603.14331, 2026.
Download Paper