
生图 / 生视频 RL 后训练:从 DPO、GRPO 到 Diffusion / Flow Alignment
生图 / 生视频 RL 后训练:从 DPO、GRPO 到 Diffusion / Flow Alignment
来源:ChatGPT share: 领域生成数学原理 类型:技术对话整理,不是单篇论文深读 主题:生成式基础模型 post-training,重点是图像 / 视频生成中的 DPO、GRPO、DDPO、Flow-DPO、VADER 等 RL / preference alignment 方法 补充来源:DPO、RLHF、GRPO、DDPO、DPOK、Diffusion-DPO、DRaFT、AlignProp、VADER、VideoDPO、DenseDPO、OnlineVPO、Flow-GRPO、Linear-DPO、Pick-a-Pic、ImageReward、HPSv2、VideoReward 等一手论文页面 检索日期:2026-06-23
开篇点评:这个话题到底在问什么
这段对话里最关键的纠正是:“我说的是基于 DPO、GRPO 之类的 RL 的后训练,不是后处理。”这句话把问题从图像增强、补帧、超分、稳定化这些 output-side pipeline,拉回到生成模型参数本身的 post-training。
生图 / 生视频模型的 RL 后训练,关心的不是已经生成出一张图以后再把它修漂亮,而是让模型的生成分布变成另一种分布:更听 prompt,更符合人类审美,更会写字,更安全,更能保持视频运动和时间一致性。形式上,它从传统预训练的“拟合数据分布”:
\[p_\theta(x \mid c) \approx p_{\mathrm{data}}(x \mid c)\]转向一个带 reward 和 reference 约束的目标:
\[\max_\theta\ \mathbb{E}_{c \sim D,\ x \sim p_\theta(\cdot \mid c)}[R(c,x)] - \beta D_{\mathrm{KL}}\left(p_\theta(\cdot \mid c)\ \|\ p_{\mathrm{ref}}(\cdot \mid c)\right).\]其中 $c$ 是文本、图像、mask、control、首帧或视频条件,$x$ 是生成图像或视频,$R(c,x)$ 是偏好、审美、文字、数量、空间关系、安全、运动质量等评价信号。$\beta$ 控制“追 reward”与“不偏离 reference model”的平衡。
我的判断是,视觉生成后训练的核心难点不在于“有没有 DPO/GRPO 名字”,而在于 policy 的定义发生了变化。LLM 的 policy 是 token 分布;diffusion / flow 模型的 policy 更像一条连续采样轨迹。reward 往往只在最终图像或视频上给出,但参数更新要穿过几十步去噪、velocity 预测或 ODE/SDE 轨迹。这就是为什么把 LLM 的 DPO 或 GRPO 直接搬过来通常不够。
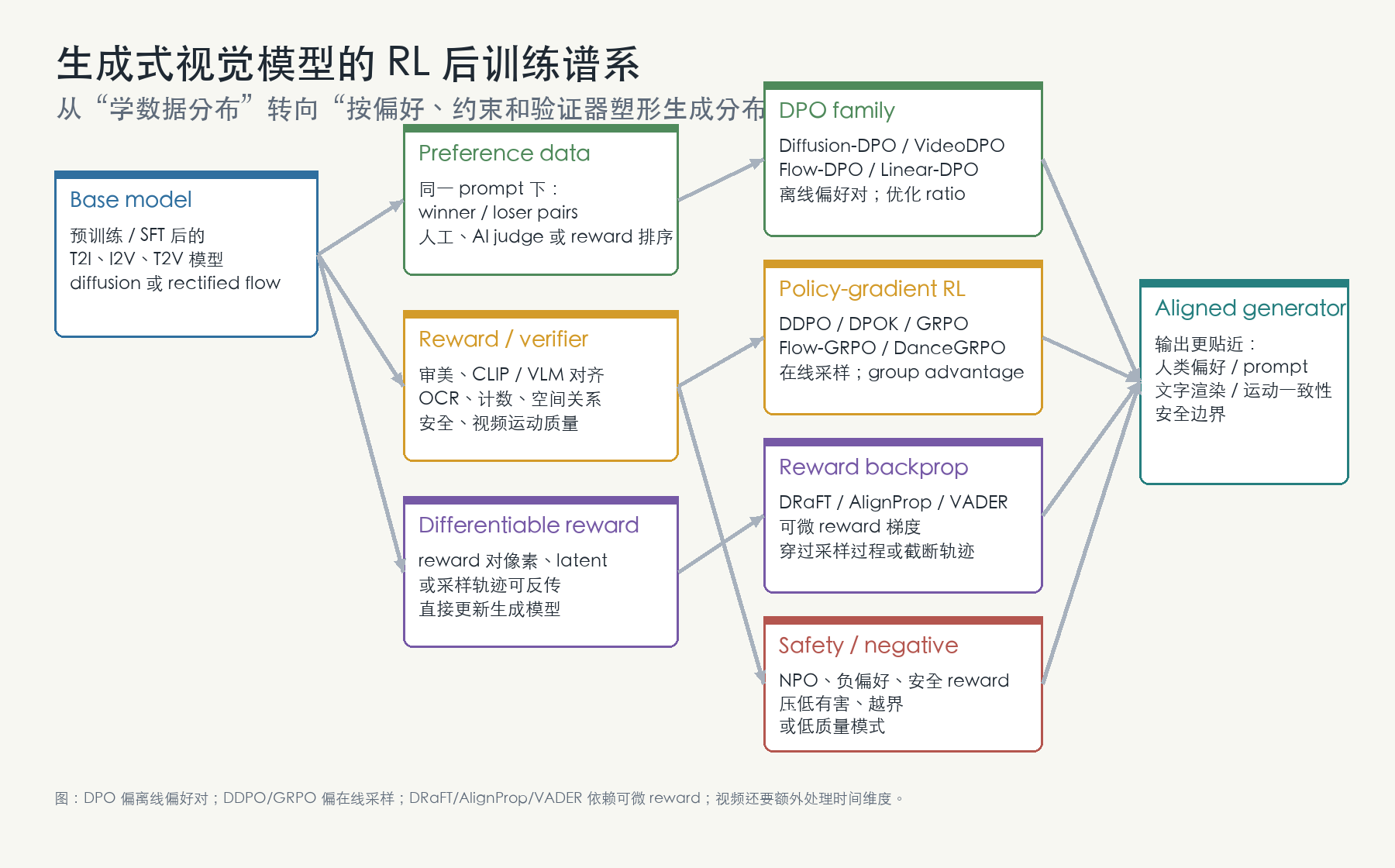
图:视觉生成 RL 后训练的方法谱系。DPO 偏离线偏好对,DDPO/GRPO 偏在线采样,DRaFT/AlignProp/VADER 依赖可微 reward,视频方法还要额外处理时间维度。
Source Card
| 项目 | 信息 |
|---|---|
| Main source | ChatGPT shared conversation: 领域生成数学原理 |
| Source type | 技术对话。本文把它当作待整理材料,而不是权威论文来源 |
| Main corrected topic | 生图 / 生视频生成模型本身的 RL post-training / preference alignment,不是后处理 |
| Key methods in source | SFT、RLHF、RLAIF、DPO、GRPO/RLVR、DDPO、DPOK、Diffusion-DPO、Flow-GRPO、DRaFT、AlignProp、VADER、VideoDPO、DenseDPO、OnlineVPO、Flow-DPO、Linear-DPO |
| Supplemented primary sources | InstructGPT/RLHF, DPO, DeepSeekMath/GRPO, DDPO, DPOK, Diffusion-DPO, DRaFT, AlignProp, VADER, Flow-GRPO, DanceGRPO, VideoDPO, DenseDPO, OnlineVPO, VideoReward / Flow-DPO, Linear-DPO |
| Reward / data sources | Pick-a-Pic, ImageReward, HPSv2 / HPD v2 |
| 复现状态 | 这是方法综述与工程整理;不同论文的代码、数据、reward model 开放程度不同,不能把所有方法视为同等可复现 |
先划清边界:后训练不是后处理
后处理是 output-side 的系统工程。模型已经生成了 $\hat{x}=G_\theta(c,z)$,后面再接一个 $H_\phi$ 去修复、增强、筛选或标记:
\[x^\ast = H_\phi(\hat{x}, c, \mathrm{mask}, \mathrm{control}, \mathrm{quality\ target}).\]典型后处理包括图像超分、去噪、锐化、脸部修复、视频补帧、temporal stabilization、去闪烁、安全水印、内容审核和 best-of-N 排序。这些模块有价值,但它们通常不改变主生成模型的参数。
本文讨论的后训练不同。它直接改变 $p_\theta(x \mid c)$,让模型在采样时更倾向于产生高 reward 样本。后处理可以把某次输出修好;后训练希望模型以后更少生成需要修的输出。两者可以组合,但优化对象不同:
| 维度 | 后处理 post-processing | 后训练 post-training |
|---|---|---|
| 改不改主模型参数 | 通常不改 | 会改,或至少改 LoRA / adapter |
| 发生时间 | 生成之后 | 训练或微调阶段 |
| 优化对象 | 单个输出样本 | 整个条件生成分布 |
| 典型技术 | 超分、补帧、修复、筛选、水印 | RLHF、DPO、DDPO、DPOK、GRPO、reward backprop |
| 主要风险 | 伪影、过修、时序不一致 | reward hacking、分布漂移、KL 失衡、偏好数据偏置 |
这个边界很重要。很多生图产品看起来“对齐变好了”,其实是加了 reranker、prompt enhancer 或后处理;而 RL post-training 的证据应当来自参数更新、偏好数据、reward model、训练目标和对比实验。
通用后训练框架:从模仿到偏好再到 RL
对任意生成模型,可以把后训练看成几个信号源的组合:人工示范、偏好排序、AI feedback、规则验证器、可微 reward、下游任务评价。不同方法只是把这些信号放进不同 loss。
1. SFT / Instruction Tuning:先学“应该怎么答”
监督微调最直接。给定数据 $(x,y^\ast)$,最大化标注输出的似然:
\[\mathcal{L}_{\mathrm{SFT}}(\theta) = -\mathbb{E}_{(x,y^\ast)\sim D_{\mathrm{sft}}}\log \pi_\theta(y^\ast \mid x).\]在 LLM 中,$y^\ast$ 是人写答案。在图像 / 视频生成里,对应的是高质量 caption-image pairs、精选 prompt-output pairs、风格数据、领域图像、人工修订样本。SFT 能快速改变行为,但它只会模仿数据,不会直接优化“哪个输出更好”。
2. 继续预训练 / 领域自适应:扩大某个分布
继续预训练仍然是 likelihood 或 denoising objective,只是数据分布换成目标领域。比如商业海报、医学图像、游戏资产、动漫风格、长文本渲染样本。它的效果像“补知识 / 补风格”,不是严格意义上的偏好对齐。
风险也明显:如果数据窄,模型会过拟合风格;如果数据噪,模型会把错误 caption、低质量构图和水印一起学进去。
3. PEFT / LoRA / QLoRA:改变更新载体
PEFT 不定义新的目标函数,只定义“更新哪些参数”。LoRA 把大矩阵更新限制为低秩分解:
\[W' = W + \Delta W,\qquad \Delta W = BA,\qquad \mathrm{rank}(\Delta W) \ll \min(d_{\mathrm{in}}, d_{\mathrm{out}}).\]在视觉生成后训练里,LoRA 常被用作安全的更新容器:少量参数、更容易回滚、也能降低 reward hacking 对 base model 的破坏范围。但 LoRA 容量有限,复杂 reward 或长视频一致性可能需要更大范围的更新。
4. Reward Model:把偏好变成分数
RLHF 的典型流程是先收集偏好对 $(y_w,y_l)$,再训练 reward model $r_\phi(x,y)$。常用 Bradley-Terry 形式:
\[P(y_w \succ y_l \mid x) = \sigma\left(r_\phi(x,y_w)-r_\phi(x,y_l)\right).\]图像领域的 Pick-a-Pic、ImageReward、HPSv2 都是在补这一层。Pick-a-Pic 收集真实用户对生成图像的偏好并训练 PickScore;ImageReward 用专家比较训练通用 text-to-image reward model;HPSv2 / HPD v2 则强调大规模、多来源的 human preference benchmark。它们的共同作用是把“好看”“符合 prompt”这种主观信号变成可训练、可排序、可评估的数值。
5. Best-of-N / Rejection Sampling:不改模型但改输出分布
Best-of-N 先从 $p_\theta$ 采样 $N$ 个候选,再用 reward 选最高分。它不改变参数,却改变用户看到的分布:
\[x^\ast = \arg\max_{x_i \sim p_\theta(\cdot \mid c)} R(c,x_i).\]这常常是最便宜的 alignment baseline。问题是推理成本随 $N$ 增长,且模型本身没有学到新能力。如果 reward 有偏,best-of-N 会把偏差放大。
6. RLHF / PPO:显式最大化 reward
RLHF 在 InstructGPT 中被系统化:先 SFT,再收集排序训练 reward model,最后用 PPO 在 reward 与 KL 约束之间优化。统一目标可以写成:
\[\max_\theta\ \mathbb{E}_{y\sim \pi_\theta(\cdot \mid x)} \left[r_\phi(x,y)-\beta \log \frac{\pi_\theta(y\mid x)}{\pi_{\mathrm{ref}}(y\mid x)}\right].\]这个式子是视觉生成后训练的母式。DDPO、DPOK、Flow-GRPO、VideoReward/Flow-DPO 等方法只是在“policy 是什么”“reward 怎么来”“KL 怎么估”“轨迹怎么采样”上做视觉化改造。
7. DPO:不显式训练 reward model 的偏好优化
DPO 的关键是把 KL-constrained RLHF 的最优 policy 重写成分类式 loss。给定 preferred output $y_w$ 和 rejected output $y_l$,核心比较项是 policy 相对 reference 的 log-ratio 差:
\[\Delta_\theta = \left[\log \pi_\theta(y_w\mid x)-\log \pi_{\mathrm{ref}}(y_w\mid x)\right] - \left[\log \pi_\theta(y_l\mid x)-\log \pi_{\mathrm{ref}}(y_l\mid x)\right].\]然后优化:
\[\mathcal{L}_{\mathrm{DPO}}(\theta)= -\mathbb{E}\log\sigma(\beta \Delta_\theta).\]对 LLM 来说,$\log \pi_\theta(y\mid x)$ 是 token likelihood。对 diffusion / flow 来说,难点是没有同样直接、便宜的序列 likelihood,于是 Diffusion-DPO、Flow-DPO、Linear-DPO 等方法需要改写成 ELBO、score matching、reverse-time SDE 或 velocity regression 形式。
8. GRPO / RLVR:用一组样本的相对分数替代 critic
GRPO 最早在 DeepSeekMath 的推理训练中被广泛讨论。它与 PPO 的差别之一是不用单独 critic,而是在同一 prompt 下采样一组输出,用组内 reward 估计 baseline 和 advantage:
\[A_i = \frac{R_i-\mathrm{mean}(R_1,\ldots,R_G)} {\mathrm{std}(R_1,\ldots,R_G)+\epsilon}.\]这个形式很适合视觉生成,因为同一 prompt 可以天然采样多个图像或视频,并且 reward 常常是相对的。比如“哪张更像 prompt”“哪段动作更自然”“哪张字更准”,组内比较比绝对打分更稳定。
视觉生成的关键变化:policy 是轨迹
在 LLM 中,一条 trajectory 是 token 序列:
\[\tau_{\mathrm{llm}}=(y_1,y_2,\ldots,y_T).\]在 diffusion 中,一条 trajectory 是反向去噪状态:
\[\tau_{\mathrm{diff}}=(z_T,z_{T-1},\ldots,z_0).\]在 flow / rectified flow 中,它更接近一条 ODE/SDE 采样路径:
\[\tau_{\mathrm{flow}}=(z_{t_K},z_{t_{K-1}},\ldots,z_{t_0}).\]动作不是“下一个词”,而是每一步的噪声、score 或 velocity 预测。终点 $z_0$ 解码成图像或视频 $x$ 后,reward 才被计算出来。这带来三个工程后果。
第一,credit assignment 更难。reward 只看最终图像时,很难知道错误来自哪一步 denoising,尤其是复杂文字、对象数量、空间关系和视频运动。
第二,log-prob 或 likelihood ratio 更难估。DPO 类方法必须把“偏好 winner/loser”落到 diffusion ELBO、score matching loss 或 flow matching path 上。
第三,采样成本更高。在线 RL 需要不断生成样本、打分、更新;视频比图像更贵,因为每个样本是一段时空张量,不是一张图。
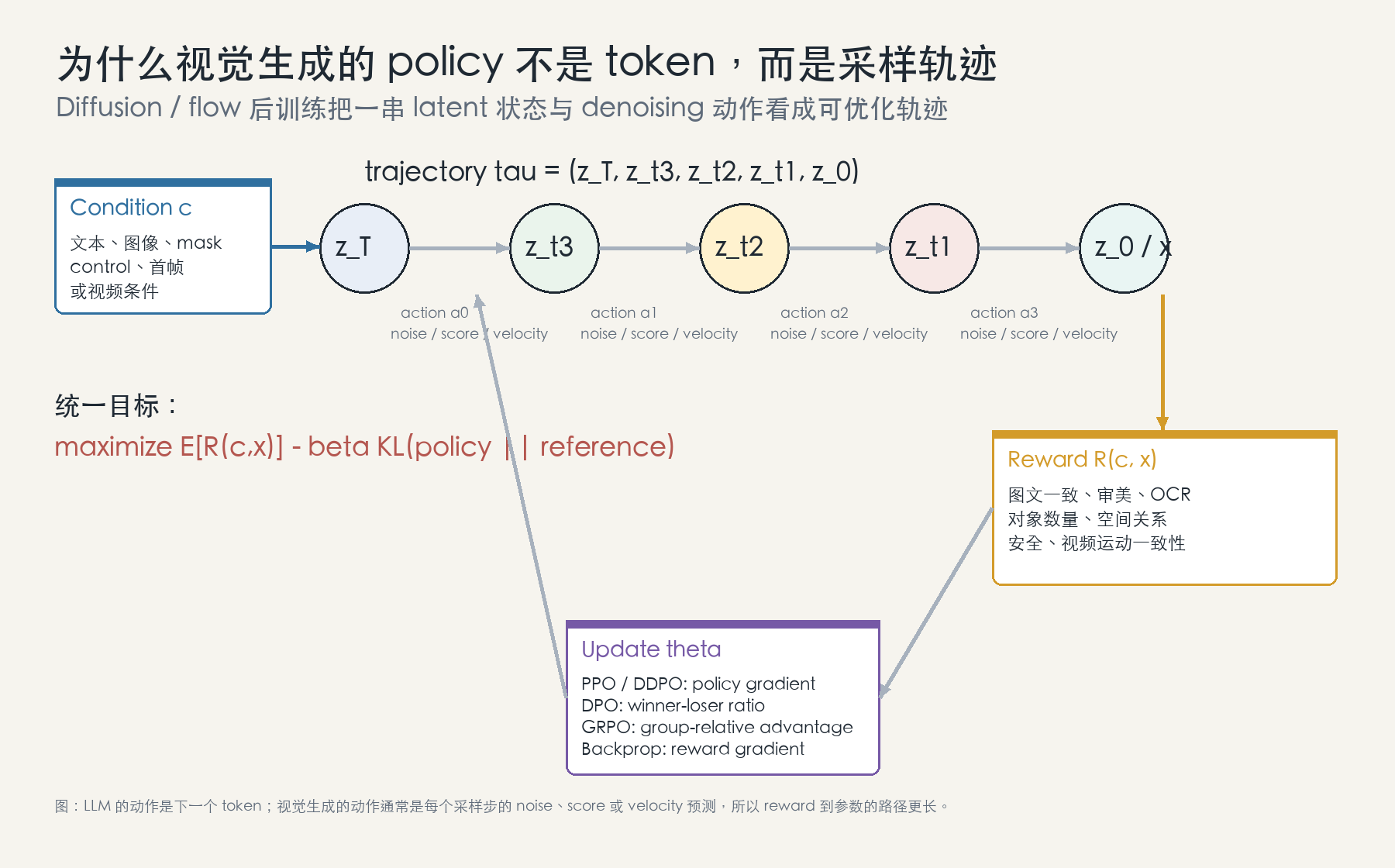
图:视觉生成的 policy 通常是一条 latent 采样轨迹。reward 在最终样本上给出,但梯度或 policy gradient 要回到多步噪声 / score / velocity 预测。
Reward 从哪里来
视觉生成的 reward 通常比 LLM 更混杂。一个图像或视频“好”,可能同时要求画面质量、prompt 对齐、文字准确、物体数量正确、空间关系正确、安全合规、运动自然、身份稳定。把这些都压成一个标量,会丢掉很多解释性;但如果不压成标量,RL 更新又很难做。
| Reward 来源 | 例子 | 优点 | 风险 |
|---|---|---|---|
| 人类偏好数据 | Pick-a-Pic、HPD v2、人工 winner/loser | 最接近真实偏好 | 标注贵,偏好有地域和平台偏差 |
| AI feedback | VLM judge、LLM-as-judge、自动 caption checker | 扩展便宜,适合大量 prompt | judge 可能偏、会奖励投机模式 |
| 专用 reward model | ImageReward、HPSv2、VideoReward | 可批量打分,可做训练目标 | reward hacking 和 domain shift |
| 可验证 reward | OCR、object counting、spatial relation、NSFW detector | 信号清晰,适合 GRPO/RLVR | 覆盖面窄,容易过优化 |
| 视频 reward | VQA、motion score、temporal consistency、physics score | 能处理时间维度 | 现有模型对真实人类视频偏好仍不稳 |
一个实用原则是:reward 越容易自动验证,越适合在线 RL;reward 越主观,越需要偏好数据和 KL 约束;reward 如果可微,可以考虑 DRaFT、AlignProp 或 VADER 这类直接反传方法。
方法一:DDPO / DPOK,把 diffusion 看成多步决策过程
DDPO 的贡献是把 denoising 明确建模成 multi-step decision-making。每一步从 $z_t$ 到 $z_{t-1}$ 的预测是动作,最终样本得到 reward。论文表明这种 policy gradient 方法可以优化一些 prompting 难以表达的目标,例如压缩率、审美、人类反馈和 VLM 反馈下的 prompt-image alignment。
DPOK 也把 text-to-image diffusion fine-tuning 定义为 online RL,并把 policy optimization 与 KL regularization 结合起来。它关注的问题是:只做 rejection sampling 或监督微调不一定能把 reward 真正写进模型参数;但没有 KL 约束,RL 又容易把模型推离原始分布。
这类方法的直觉很清楚:
- 用当前模型对 prompt 采样图像;
- 用 reward model 或 verifier 给图像打分;
- 对整条去噪轨迹做 policy gradient;
- 用 reference model 或 KL penalty 限制漂移。
优点是 reward 可以是黑盒,不需要 winner/loser 偏好对。缺点是方差大、采样贵、训练不稳定。视觉生成里如果 reward 不准,policy gradient 会非常直接地钻 reward 的漏洞。
方法二:Diffusion-DPO,把偏好对转成 diffusion 目标
Diffusion-DPO 是把 DPO 从 LLM 搬到 diffusion 的代表工作。它使用 Pick-a-Pic 的大规模 pairwise preference,在 SDXL base 上做偏好优化。关键不是简单套用 DPO 公式,而是重新定义 diffusion 模型里的 likelihood notion:用 ELBO 形式把 winner/loser 的偏好转成可微目标。
在语言模型中,winner 的概率更高意味着 token likelihood 更高。在 diffusion 中,模型不是直接给图像一个规范化概率,而是在多个 timestep 上预测噪声或 score。Diffusion-DPO 因此比较的是 preferred image 与 rejected image 在 diffusion training objective 下相对 reference 的优势。
这类方法适合:
- 已经有高质量 winner/loser 数据;
- 想避免在线 RL 的采样方差;
- reward 很主观,不容易写成 verifier;
- 训练预算比 PPO/DDPO 更保守。
它的问题也明确:偏好数据会决定模型学到什么。如果数据偏向某种“好看模板”,模型会收窄审美;如果偏好对的差别主要来自画质而不是 prompt alignment,模型可能更会讨好审美 reward,但复杂指令能力提升有限。
方法三:GRPO / Flow-GRPO / DanceGRPO,用组内相对 reward 做在线对齐
GRPO 的视觉版本有一个自然优势:同一 prompt 下采样一组图像或视频非常容易。对每组样本算 reward,再把组内相对优势作为更新信号,可以避免训练一个独立 critic。
Flow-GRPO 把在线 policy-gradient RL 接到 flow matching 模型上。它的关键设计包括 ODE-to-SDE 转换和 Denoising Reduction。前者让确定性的 ODE 采样变成可探索的随机过程,同时保持边缘分布;后者减少训练时 denoising 步数,提高采样效率。论文报告了 compositional generation、visual text rendering 和 human preference alignment 的提升。
DanceGRPO 则试图把 GRPO 做成视觉生成的统一框架,覆盖 diffusion、rectified flow、text-to-image、text-to-video、image-to-video、多种基础模型和多种 reward。它的价值在于强调 GRPO 不是只适用于数学推理,也可以服务于视觉生成的 group-relative preference optimization。
这类方法适合有自动 reward 或 verifier 的任务。比如:
- 文字渲染:OCR reward 可以判断生成文字是否正确;
- 数量关系:object counter 能判断“three red cubes”是否满足;
- 空间关系:VLM / spatial verifier 判断 left/right/on/under;
- 视频运动:motion score 或 video reward 给出相对评价。
风险在于 reward hacking。即便 Flow-GRPO 论文报告 reward hacking 较少,也不能把这当作普遍保证。换 reward、换模型、换 prompt 分布以后,过优化仍然可能出现。
方法四:DRaFT / AlignProp / VADER,直接把 reward 梯度反传回生成模型
如果 reward 对生成样本可微,就不一定需要 policy gradient。可以直接把 reward gradient 通过采样过程反传回模型。
DRaFT 的思路是 Direct Reward Fine-Tuning:对可微 reward,例如偏好模型分数或审美分数,把梯度穿过完整或截断的 sampling procedure,直接优化 diffusion model。论文还提出 DRaFT-K、DRaFT-LV 等更高效变体。
AlignProp 也做 reward backpropagation。它通过随机截断 denoising 步数、LoRA 和 gradient checkpointing 控制显存,并优化图文语义、审美、压缩率、对象数量等目标。需要注意的是,arXiv 页面显示 AlignProp 版本已被作者标记为 withdrawn,并说明被后续工作 VADER 吸收;因此引用它时应把它作为方法脉络,而不是最新独立结论。
VADER 把 reward gradient 推到视频扩散模型。视频空间更大,纯 gradient-free RL 采样成本高;VADER 的重点是利用预训练 reward models 对 RGB 像素提供 dense gradient,使视频模型能更高效地对齐下游 reward。
这类方法的优点是样本效率高,梯度信息密。限制也同样清楚:reward 必须可微或近似可微;反传 through sampling 的显存和稳定性很敏感;如果 reward model 本身不可靠,梯度会把模型推向 reward model 的盲点。
方法五:视频 DPO / OnlineVPO / DenseDPO,解决时间维度
视频后训练不能只把每帧当图片。一个视频可能单帧都不错,但整体闪烁、身份漂移、动作不自然、首尾因果错乱。视频 reward 至少有四类:
- frame quality:清晰度、构图、瑕疵、审美;
- text-video alignment:动作、对象、属性、空间关系是否符合 prompt;
- temporal consistency:身份、纹理、光照、几何和背景是否跨帧稳定;
- motion / physics:运动幅度、速度、因果和物理合理性。
VideoDPO 把 DPO 适配到 video diffusion,提出 OmniScore,同时考虑视觉质量和语义对齐,并据此自动构建偏好对。它指出,视频偏好不能只优化单一维度,否则容易牺牲其他方面。
OnlineVPO 的判断更直接:很多视频偏好学习方法沿用了 image-domain reward,但 image-level reward 与人类视频偏好之间存在 modality gap。它用 video quality assessment 作为更贴近视频感知的反馈,并做 online DPO 与 curriculum preference update。
DenseDPO 把问题推进到 temporal credit assignment。普通视频 DPO 常让标注者比较两段由独立噪声生成的视频,这会让偏好被整体运动差异污染,也可能偏向低运动样本,因为低运动更少出伪影。DenseDPO 改为从 corrupted copies of a ground-truth video 生成 temporally aligned pairs,并把偏好标注下沉到短片段,从而提供更密的学习信号。
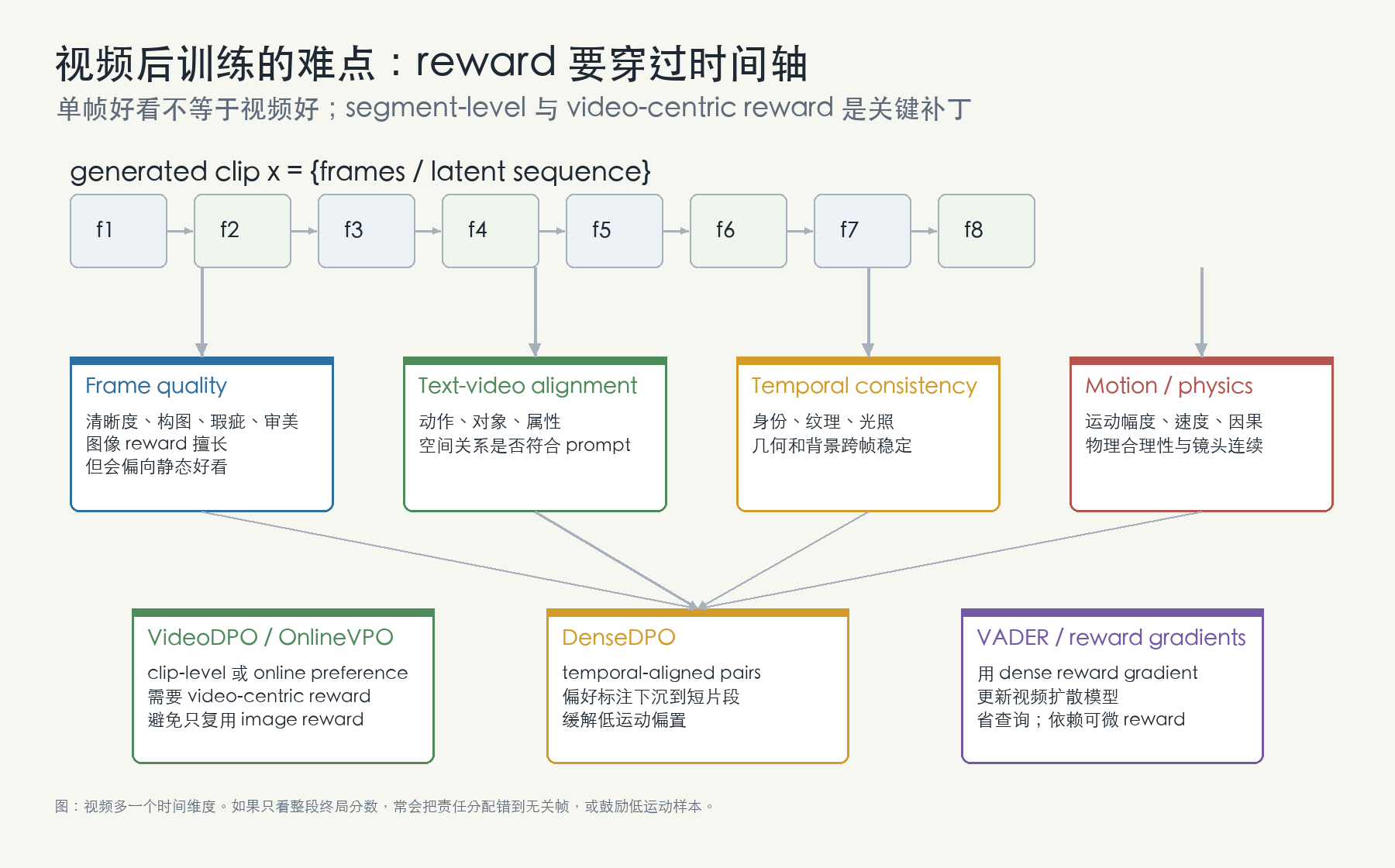
图:视频生成比图像多一个时间维度。clip-level reward 太粗时,常会把责任分配错到无关帧;segment-level preference 和 video-centric reward 是当前方法的重要补丁。
方法六:Flow-DPO / Flow-GRPO / Linear-DPO,适配 rectified flow 与 flow matching
现在很多强视觉生成模型已经从传统 diffusion schedule 走向 flow matching / rectified flow。问题是,DPO 和 DDPO 的许多推导默认 diffusion 形式;flow 模型的训练目标和 sampling path 不完全一样。
VideoReward / Improving Video Generation with Human Feedback 构建了视频偏好数据和多维 VideoReward,并提出 Flow-DPO、Flow-RWR 和 Flow-NRG。Flow-DPO 是 training-time preference optimization,Flow-NRG 则是在推理时对 noisy videos 做 reward guidance。这说明 flow-based video model 的对齐不只是“换个 sampler”,而是 reward、训练目标和推理引导都要重新适配。
Flow-GRPO 用 ODE-to-SDE 解决 flow 模型在线 RL 的探索问题。Linear-DPO 则指出,把 NLP 里离散序列的 sigmoid DPO 目标直接用到回归式生成任务可能存在 objective mismatch。它提出统一 diffusion 和 flow-matching 的 reverse-time SDE 视角,并用 linear utility 替代更激进的 sigmoid utility,同时引入 EMA reference model。
这一条线很值得关注,因为 2026 年的视觉生成基础模型大量采用 flow / rectified flow。未来的视觉 post-training 很可能不是“Diffusion-DPO 的小改名”,而是围绕 flow path、velocity field、SDE exploration 和 reference dynamics 重新设计目标。
一个典型生图 RL 后训练 pipeline
如果把上面的方法落成工程系统,图像生成后训练通常长这样:
- 固定一个 base model 和 reference model。reference 可以是 base checkpoint,也可以是 EMA copy。
- 准备 prompt pool。要覆盖常规审美、复杂组合、文字渲染、对象计数、空间关系、安全边界和目标领域 prompt。
- 采样候选图像。离线 DPO 通常需要 winner/loser pairs;在线 GRPO/DDPO 需要每个 prompt 多个样本。
- 打分或标注偏好。来源可以是人工、ImageReward/HPSv2/PickScore、OCR、object detector、VLM judge 或安全模型。
- 选择训练目标。偏好对充足用 Diffusion-DPO / Linear-DPO;自动 reward 可靠用 DDPO / GRPO;reward 可微用 DRaFT / VADER-like gradient。
- 加 KL 或 reference regularization。没有约束时,模型容易追 reward 追到画面塌缩或风格收窄。
- 评估分层做。不能只看 reward 均值,还要看人评、prompt following、text rendering、composition、diversity、safety 和失败样本。
我会特别强调第 7 步。很多 reward tuning 的论文曲线看起来很漂亮,但真实产品关心的是 reward 提升是否牺牲了多样性、是否变得模板化、是否在长尾 prompt 上崩、是否把安全拒绝学成过度保守。
一个典型生视频 RL 后训练 pipeline
视频 pipeline 更复杂:
- 构建 video prompt pool:动作、镜头、主体身份、物理交互、风格、时长、首帧约束、I2V 条件。
- 采样多段视频:同 prompt 多 seed,必要时保持 temporal alignment 以便局部比较。
- 计算多维 reward:画质、文本对齐、motion、temporal consistency、identity preservation、physical plausibility、安全。
- 构建偏好对:clip-level pair、segment-level pair 或 online generated pair。
- 选择优化目标:VideoDPO / OnlineVPO / DenseDPO / Flow-DPO / VADER / GRPO。
- 做 memory-aware training:视频样本大,训练常需要低分辨率 warm-up、短片段训练、梯度检查点、LoRA 或分阶段 fine-tuning。
- 评估时同时看 clip-level 和 segment-level:只看整体偏好会漏掉局部闪烁;只看单帧会漏掉运动。
视频任务最容易出现的伪进步是“少动就少错”。如果 reward 或偏好标注没有约束运动幅度,模型可能学会生成更静态、更保守的视频来避开伪影。这就是 DenseDPO 强调 temporal-aligned pairs 和 segment-level preference 的原因。
方法选择指南
| 你的条件 | 更合适的方法 | 原因 |
|---|---|---|
| 有高质量 winner/loser 偏好对 | Diffusion-DPO、VideoDPO、Flow-DPO、Linear-DPO | 离线稳定,不必在线采样大量样本 |
| 有自动 reward 或 verifier | DDPO、DPOK、GRPO、Flow-GRPO、DanceGRPO | 可以在线生成多样本,直接优化 reward |
| reward 对样本可微 | DRaFT、AlignProp、VADER | 利用 dense gradient,样本效率高 |
| 目标是文字、数量、空间关系 | GRPO / verifier-based RL | 同 prompt 组内比较清晰,reward 更可验证 |
| 模型是 flow / rectified flow | Flow-GRPO、Flow-DPO、Linear-DPO | 采样路径和训练目标需要 flow-specific 改造 |
| 视频任务 | VideoDPO、DenseDPO、OnlineVPO、VADER、Flow-DPO | 需要 video-centric reward 和 temporal credit assignment |
| 安全或负面样本压制 | NPO、negative preference、安全 reward | 目标是降低坏模式概率,而不是单纯提高审美 |
| 算力有限 | Best-of-N、reranking、LoRA-DPO、小规模 GRPO | 先验证 reward 有效性,再扩大训练 |
一个不太漂亮但很实用的结论是:先做 best-of-N 和离线偏好评估,再决定是否上 RL。若 reward 连 reranking 都不能稳定提升人评,直接拿它做 GRPO/DDPO 通常只会更快暴露 reward 的漏洞。
核心风险
Reward hacking
模型会学习 reward model 的盲点。OCR reward 可能鼓励巨大、居中的文字;审美 reward 可能鼓励高对比、浅景深、商业摄影模板;安全 reward 可能把正常内容也推向保守拒绝。解决办法不是只调小学习率,而是要做 reward ensemble、KL 约束、人工回看和失败样本挖掘。
KL 约束失衡
$\beta$ 太大,模型几乎不动;$\beta$ 太小,模型追 reward 过头。视觉生成还多一个问题:小的 latent shift 可能在像素空间表现为巨大的风格或结构变化,因此 KL / reference regularization 的设计比 LLM 更微妙。
Preference data bias
Pick-a-Pic、HPD v2、人工偏好、AI judge 都不是“人类偏好真值”。它们有平台、标注者、模型候选集、prompt 分布和文化偏差。DPO 类方法会把这些偏差直接写进生成分布。
Credit assignment
生图里错误可能来自早期布局,也可能来自后期纹理;视频里错误可能只发生在第 37 帧。终局 reward 太粗时,训练会把责任分配给错误的 timestep 或 frame segment。
Modality gap
把 image reward 用到 video,是一个常见但危险的捷径。单帧好看不代表动作自然;CLIP 相似不代表视频符合 prompt 动作;VLM judge 能解释视频,但也可能受抽帧策略影响。
Reproducibility
视觉 RL 后训练常依赖内部 prompt pool、内部 reward、未公开偏好数据、昂贵采样和复杂训练技巧。即使论文开源代码,也不代表完整训练可复现。读这类论文时要分清:目标函数是否清楚、reward 是否公开、偏好数据是否公开、reference model 是否可得、评估 prompt 是否可复用。
这段对话整理后的完整结构
原 share 的内容其实分成三层:
第一层是通用后训练:SFT、领域继续预训练、PEFT、reward model、best-of-N、RLHF、RLAIF、DPO、IPO/KTO/ORPO/SimPO、RLVR/GRPO、process supervision、自训练、蒸馏、工具调用。这一层回答“生成式基础模型后训练有哪些数学范式”。
第二层是概念边界:后处理不是后训练。超分、补帧、修复、稳定化、筛选、水印和安全标记都可以改善最终产物,但它们不是 DPO/GRPO 式参数更新。
第三层才是本文重点:生图 / 生视频的 RL 后训练。这里的主线不是“把 LLM RLHF 照搬”,而是把 diffusion / flow 的采样轨迹变成 policy,把图像 / 视频 reward 变成可训练信号,再用 DPO、DDPO、GRPO、reward backprop 或 flow-specific objective 去更新模型。
我的整理选择是把三层压成一个从基础到视觉特殊性的路径:先解释通用 post-training,再解释视觉 policy 变化,最后按方法族和工程 pipeline 展开。这样不会丢掉原对话里的方法清单,也不会让读者陷在几十个缩写里。
总结
生图 / 生视频 RL 后训练的本质,是把“生成像训练数据”改成“生成更符合某种偏好和约束的样本”,同时尽量不破坏 base model 的分布能力。
如果只记一句话:DPO 适合离线偏好对,DDPO/DPOK 适合黑盒 reward 的 diffusion policy gradient,GRPO/Flow-GRPO 适合同 prompt 多样本的相对 reward,DRaFT/AlignProp/VADER 适合可微 reward,VideoDPO/DenseDPO/OnlineVPO/Flow-DPO 则是在视频时间维度上补 credit assignment 和 modality gap。
真正难的不是写出 loss,而是 reward 是否可靠、偏好数据是否覆盖真实需求、KL 是否控制住分布漂移、评估是否能发现 reward hacking。对工程实践来说,最稳的路线通常是:先做 reward 和 reranking 验证,再做小规模 LoRA / DPO,最后再上在线 GRPO/DDPO 或视频级 RL。这样可以把最容易失败的部分,提前暴露在便宜实验里。
参考链接
- Training language models to follow instructions with human feedback
- Direct Preference Optimization: Your Language Model is Secretly a Reward Model
- DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
- Training Diffusion Models with Reinforcement Learning
- DPOK: Reinforcement Learning for Fine-tuning Text-to-Image Diffusion Models
- Diffusion Model Alignment Using Direct Preference Optimization
- Directly Fine-Tuning Diffusion Models on Differentiable Rewards
- Aligning Text-to-Image Diffusion Models with Reward Backpropagation
- Video Diffusion Alignment via Reward Gradients
- Flow-GRPO: Training Flow Matching Models via Online RL
- DanceGRPO: Unleashing GRPO on Visual Generation
- VideoDPO: Omni-Preference Alignment for Video Diffusion Generation
- OnlineVPO: Align Video Diffusion Model with Online Video-Centric Preference Optimization
- DenseDPO: Fine-Grained Temporal Preference Optimization for Video Diffusion Models
- Improving Video Generation with Human Feedback
- Linear-DPO: Linear Direct Preference Optimization for Diffusion and Flow-Matching Generative Models
- Pick-a-Pic: An Open Dataset of User Preferences for Text-to-Image Generation
- ImageReward: Learning and Evaluating Human Preferences for Text-to-Image Generation
- Human Preference Score v2
Recommended citation: ChatGPT shared conversation, 领域生成数学原理, retrieved 2026-06-23; supplemented with primary papers and official arXiv/OpenReview sources.