
SeFi-Image 深读:Semantic-First Diffusion 如何把语义先行带进文生图基础模型
SeFi-Image 深读:Semantic-First Diffusion 如何把语义先行带进文生图基础模型
论文:SeFi-Image: A Text-to-Image Foundation Model with Semantic-First Diffusion 作者:SeFi-Team;source 中列出 Core Contributors: Ruoyu Feng, Jinming Liu 时间 / 版本:arXiv v1, submitted 2026-06-21 类别:Text-to-Image Foundation Model / Latent Diffusion / Semantic-First Diffusion / Text Rendering 链接:Paper / Project / Code / Models 本文基于 arXiv TeX source、PDF、官方 GitHub README、Project Page 和 Hugging Face 页面阅读;检索日期:2026-06-23。
开篇点评:这篇论文到底解决了什么问题
SeFi-Image 讨论的是 text-to-image foundation model 里一个容易被“更大模型、更大数据”掩盖的问题:latent 到底应该保存什么信息。
常规 latent diffusion 依赖 VAE 把图像压到 latent space,再让 diffusion model 在这个空间里建模。VAE 如果保留更多边缘、文字和纹理,重建会更好,但 diffusion 要学习的分布也更复杂;VAE 如果更偏语义、更强压缩,模型更容易训练,但小字、细节和编辑一致性会受损。SeFi-Image 的核心判断是:不要让一个 latent 同时承担语义组织和纹理重建。它把图像拆成 semantic latent 和 texture latent,让 semantic latent 在扩散时间轴上先 denoise,作为 texture latent 生成时的结构锚点。
我的判断是,这篇报告的价值不只在 SFD 这个机制本身,而在于它把一个原本主要在 ImageNet 小模型上验证的 semantic-guided diffusion 思路,做成了 1B/2B/5B 的文生图基础模型栈:数据标注、合成文本数据、VAE 改造、DiT 训练、SFT、RL post-training、DMD2 turbo distillation 和开源推理 checkpoint 都放到了一条链路里。强项是机制与工程闭环完整;弱项是训练数据和 reward/eval 细节大量依赖内部系统,社区很难完整复现。
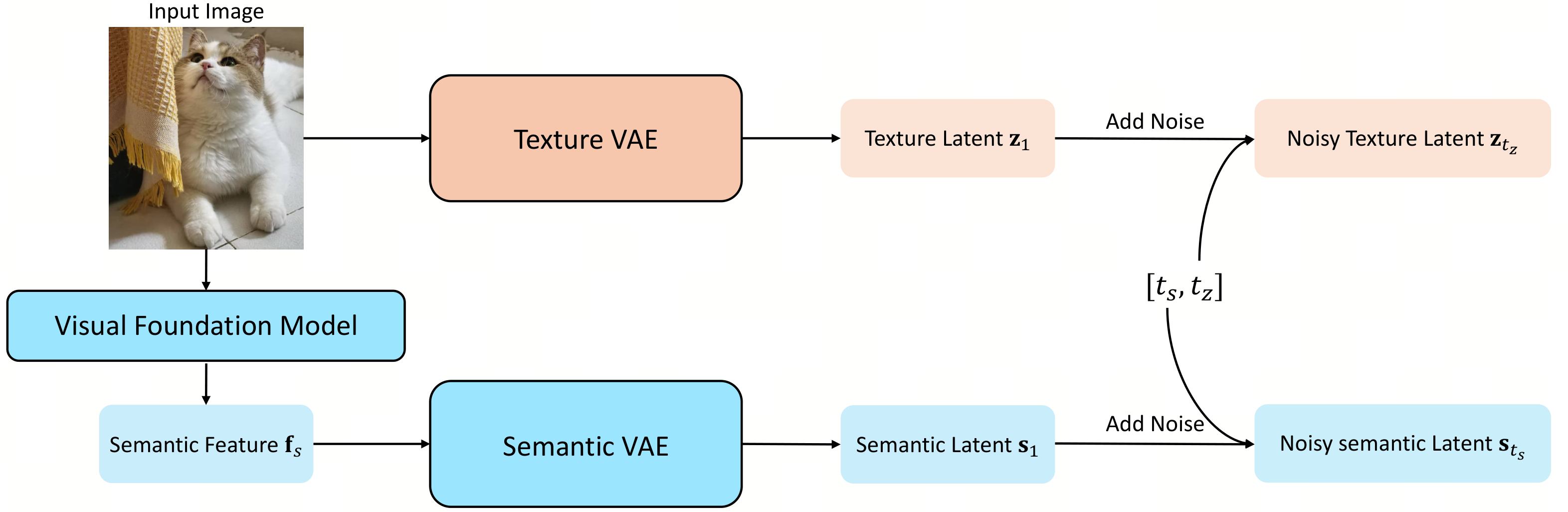
图:官方论文图,展示 semantic latent 和 texture latent 的来源。上路的 texture VAE 保存低层重建细节,下路的 DINOv2 + SemVAE 把对象、布局和场景结构压成 semantic latent。
Paper Card
| 项目 | 信息 |
|---|---|
| Paper | arXiv:2606.22568 |
| Title | SeFi-Image: A Text-to-Image Foundation Model with Semantic-First Diffusion |
| Authors | SeFi-Team;source 列出 Ruoyu Feng, Jinming Liu 等 contributors |
| Date / Version | Submitted 2026-06-21, v1 |
| Category | cs.CV |
| Project / Code | Project Page, GitHub inference repo |
| Models | Hugging Face organization: 1B/2B/5B Base, 5B-RL, 1B/2B/5B Turbo |
| 主要能力 | 双语 text-to-image、复杂 prompt following、text rendering、少步数 turbo generation |
| 复现状态 | 推理 repo 和 checkpoint 已公开;训练数据、完整训练代码、reward model、完整 evaluation scripts 未公开 |
Abstract:论文摘要解读
摘要的第一句话不是说“我们生成效果很好”,而是先指出训练 image generation foundation model 的资源成本很高。已有 semantic guidance 方法确实能加速 diffusion training,但主要停留在 ImageNet、低分辨率、小模型、class-conditional 这些简化设定。SeFi-Image 想验证的是:semantic-first modeling 能不能迁移到真实 T2I foundation model。
论文实例化了三个规模:1B、2B 和 5B。最大的 5B 模型据称只用了 125K A800 GPU hours,大约是 Z-Image 训练 compute 的 10-20%,但在 GenEval、DPG、LongTextBench、OneIG 和 CVTG-2K 上达到和 Qwen-Image、Z-Image 相近或更好的结果。摘要还强调他们提供了 DMD2-distilled few-step turbo variants,覆盖不同硬件和 latency 需求。
这段摘要的真实含义是:论文并不只 claim 一个更好的 benchmark 分数,而是 claim 一种更省算力的文生图训练范式。证据是否成立,要看 SFD 的对照实验、训练 compute 的披露程度,以及 main benchmark 是否真的全面领先。后面会看到,SeFi-Image 在 long text 和 text rendering 上很强,但 DPG 和中文 OneIG 并不是全项第一。
Motivation
文生图模型的训练成本常被归因于数据量、参数量和算力。但 latent diffusion 还有一个更底层的瓶颈:VAE latent 既要适合重建,又要适合生成。论文把这个矛盾叫做 reconstruction-generation trade-off。
纯 semantic representation 让 diffusion 更容易学,因为语义特征比像素细节更低熵、更结构化;但如果只依赖视觉基础模型特征,重建到像素时会丢失小字、纹理和局部几何。传统 VAE 保存更多低层信息,重建好,但 generative model 需要处理更复杂的 latent distribution,收敛更慢。
SeFi-Image 的设计不是在两者之间选一边,而是把它们拆开:
| 问题 | 传统 latent diffusion 的压力 | SeFi-Image 的处理 |
|---|---|---|
| 语义组织 | prompt、布局、对象关系都压在同一个 texture-like latent 上 | DINOv2 + SemVAE 形成 semantic latent |
| 纹理重建 | VAE 既要易学又要高保真 | fine-tuned FLUX.2 VAE 更偏高保真 texture latent |
| 训练收敛 | 高保真 latent 让 denoising 更难 | semantic latent 提前 denoise,给 texture 分支 cleaner anchor |
| 推理成本 | 双分支可能增加步数 | timestep range 扩展,但总 denoising steps 保持不变 |
这个 motivation 比“换一个 backbone”更有意思。它把生成模型的瓶颈移到 representation design:一个好的 latent 不只是压缩图像,还应该让后续生成过程更容易组织信息。
直观效果:先看它能做什么
官方 qualitative figure 里最值得看的是 text-rich examples。SeFi-Image 展示了招牌、海报、菜单、地图、书封、商品图和中英文混排文本。它不是只生成“像文字的纹理”,而是强调字符级可读性、布局和多 block 排版。

图:官方 text-rich qualitative examples。它支持论文关于 text rendering 和 multi-layout generation 的直观 claim,但 qualitative figure 不能替代 CVTG-2K、LongTextBench 和 OneIG 这样的量化评估。
我会谨慎解读这张图。它说明模型有很强的文本渲染样张能力,但真实能力还要看两个问题:第一,prompt 是否公开和可复现;第二,是否存在 cherry-picking。论文确实给了 CVTG-2K 和 LongTextBench 数字,因此这部分不完全停留在 teaser。
方法总览:核心思想和系统结构
SeFi-Image 的方法由四个层次组成。
第一层是 representation。图像 $\mathbf{x}$ 同时经过两条编码路径:frozen DINOv2-Large 提取 semantic feature,再由 SemVAE 压成 semantic latent $\mathbf{s}_1$;fine-tuned FLUX.2 VAE 直接把图像压成 texture latent $\mathbf{z}_1$。最终图像只从 texture latent 解码,semantic latent 的作用是训练和采样时提供结构。
第二层是 SFD denoising schedule。训练时给 semantic 和 texture 分支不同 timestep,保证 $t_s \geq t_z$。语义分支更接近 clean latent,纹理分支在更 noisy 的状态下被语义结构引导。
第三层是 DiT backbone。模型采用 FLUX.2 [klein]-style MMDiT,输入 noisy composite latent、dual timestep embeddings 和 Qwen3-VL text embeddings,输出 semantic 与 texture 的 velocity。
第四层是完整训练栈。它不是只训练一个 base model,还包括 continual training、SFT、DMD2 turbo distillation 和 DiffusionNFT RL post-training。
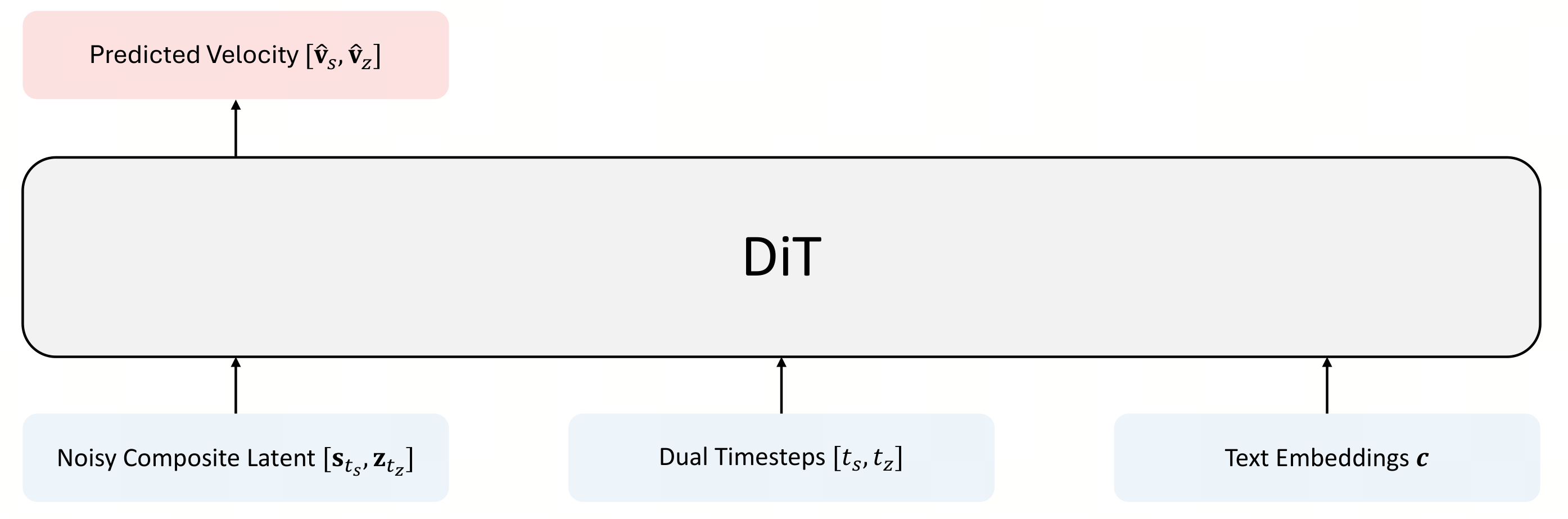
图:官方 framework 图。DiT 接收 noisy composite latent、dual timesteps 和 text embeddings,联合预测 semantic / texture 两条流的 velocity。
自绘流程图把训练和推理放到一条线上看:
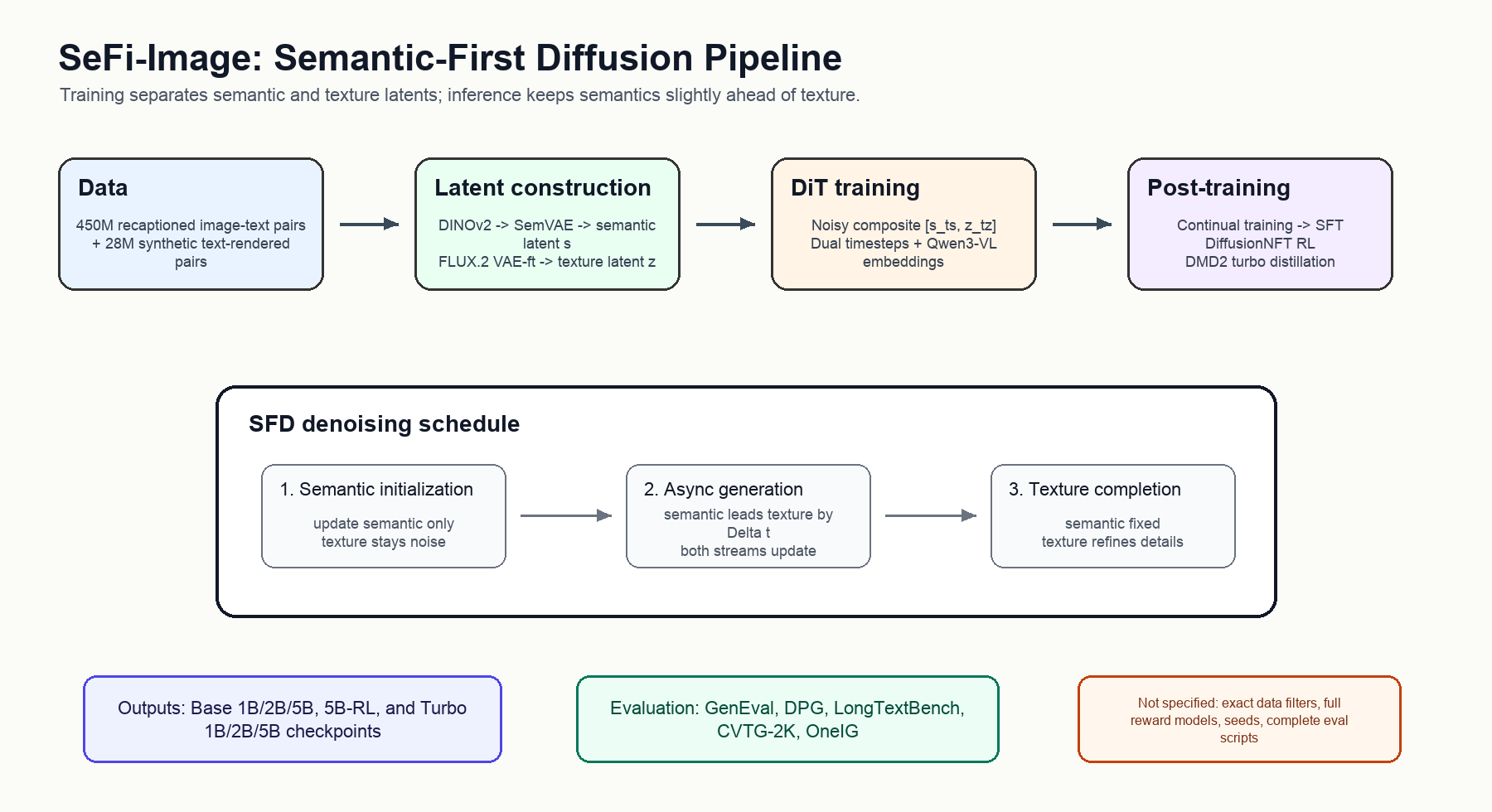
图:基于论文描述重绘的 SeFi-Image 训练与推理流程。它强调数据、双 latent 构造、DiT 训练、post-training 和三阶段 SFD schedule 的关系。
数据全流程:输入、表示、shape 和语义
Pre-training data
预训练数据由两部分构成:450M internal image-text samples 和 28M synthetic text-rendered image-text pairs。450M 内部图文样本以自然图像为主,论文使用 Qwen3.5-2B 重新标注全部图像,标注原则是 accuracy、objectivity 和 selective thoroughness。
caption 设计很细:每张图有中英双语 caption,每种语言有 dense 和 short 两种版本。训练时 dense 和 short 的采样比例是 4:1。这个设计的目标是让模型更多看到信息量更高的描述,同时不丢掉用户真实输入里常见的短 prompt。
文本渲染数据分两阶段:
| 阶段 | 数量 | 分辨率 / 布局 | 作用 |
|---|---|---|---|
| Plain text rendering | 8M | $512\times512$ canvas,单文本块,简单背景 | 学字符级映射,四个 bucket: dense EN, dense ZH, short EN, short ZH |
| Structured layout rendering | 20M | 多 block、多颜色、多字体、多形状,多 aspect ratios | 学位置、相对大小、阅读顺序和多语混排 |
论文强调在 pre-training 阶段,文字内容和图像语义是否相关并不重要;重要的是文本内容足够多样,prompt-image 是严格对齐的。自然分布下的 text-rich images 放到 continual training 和 SFT 阶段再引入。
Continual training and SFT data
Continual training 使用 9M image-text mixture,包括 Fine-T2I 和内部数据,覆盖 natural scenery、UI design、graphic design、anime 等。SFT 使用约 650K high-quality images,包括 open-source data、200K Chinese text-rich images 和内部 high-aesthetic samples。
SFT 的 annotation pipeline 明显依赖 proprietary VLM。第一轮抽取 semantic category、multilingual tags、safety attributes、watermark、OCR text、quality assessment 和初始 caption;第二轮再 refine caption。过滤维度包括 aesthetics、technical quality、composition、subject clarity、captionability、training value、artifact 和 political sensitivity。
这里的复现风险很高。论文公开了 caption prompt 的原则和部分 prompt 模板,但没有公开 450M 内部数据、proprietary VLM、过滤阈值、各来源比例和完整 SFT 数据。因此外部读者可以复现思路,很难复现结果。
Latent 和 shape:双分支到底传了什么
对图像 $\mathbf{x}$,semantic branch 是:
\[\mathbf{f}_s = \Phi(\mathbf{x}), \qquad \mathbf{s}_1 = \mathcal{E}_s(\mathbf{f}_s)\]其中 Phi 是 frozen DINOv2-Large,E_s 是 SemVAE encoder。论文给出 semantic feature 的形状写作 L x C_in,SemVAE encoder 输出写作 L x 2C_s,再拆成 Gaussian posterior 的 mean 和 variance。具体的 L、C_in 和 C_s 数值没有在正文中给出。
texture branch 是:
\[\mathbf{z}_1 = \mathcal{E}_z(\mathbf{x})\]E_z 是 fine-tuned FLUX.2 VAE。FLUX.2 VAE 使用 32 latent channels,是 FLUX.1 的两倍。作者认为原始 FLUX.2 VAE 的 posterior variance 较大,利于 diffusion learning,但会限制重建保真度;在 SFD 里,因为 texture generation 有 cleaner semantic latent 引导,可以更激进地把 texture VAE 往重建质量 fine-tune。
加入噪声的 flow path 是:
\[\mathbf{s}_{t_s} = (1-t_s)\mathbf{s}_0 + t_s\mathbf{s}_1,\qquad \mathbf{z}_{t_z} = (1-t_z)\mathbf{z}_0 + t_z\mathbf{z}_1\]训练时先从扩展区间采样 $t_s$,再设 $t_z = \max(0, t_s-\Delta t)$,并把 $t_s$ clamp 到 1。这样保证 $t_s$ 和 $t_z$ 都在 $[0,1]$,且 semantic latent 永远不比 texture latent 更 noisy。
Training:监督信号、loss 和优化目标
VAE training
Texture VAE 的目标是:
\[\mathcal{L}_{\mathrm{TexVAE}} = \mathcal{L}_{\mathrm{MSE}} + \lambda_{\mathrm{LPIPS}}\mathcal{L}_{\mathrm{LPIPS}} + \lambda_{\mathrm{KL}}\mathcal{L}_{\mathrm{KL}}\]论文设置 $\lambda_{\mathrm{LPIPS}}=0.1$,$\lambda_{\mathrm{KL}}=10^{-12}$,不使用 GAN loss。训练用 pre-training data,$256\times256$ random crops,global batch size 32,150K iterations,8xA800 约 12 小时。
SemVAE 的目标是 feature reconstruction、cosine alignment 和 KL:
\[\mathcal{L}_{\mathrm{SemVAE}} = \mathcal{L}_{\mathrm{MSE}} + \mathcal{L}_{\mathrm{cos}} + 10^{-7}\mathcal{L}_{\mathrm{KL}}\]SemVAE 训练时 frozen DINOv2-Large,只优化 encoder/decoder。global batch size 64,1M iterations,8xA800 约 48 小时。
DiT training
DiT 输出两条 velocity:
\[[\hat{\mathbf{v}}_s, \hat{\mathbf{v}}_z] = \mathbf{v}_{\theta}([\mathbf{s}_{t_s}, \mathbf{z}_{t_z}], [t_s,t_z], \mathbf{c})\]prediction loss 同时监督 semantic 和 texture:
\[\mathcal{L}_{\mathrm{pred}} = \mathbb{E} \left[ \left\|\hat{\mathbf{v}}_z-(\mathbf{z}_1-\mathbf{z}_0)\right\|^2 + \beta \left\|\hat{\mathbf{v}}_s-(\mathbf{s}_1-\mathbf{s}_0)\right\|^2 \right]\]再加上 REPA-style representation alignment:
\[\mathcal{L}_{\mathrm{total}} = \mathcal{L}_{\mathrm{pred}} + \lambda \mathcal{L}_{\mathrm{REPA}}\]完整训练日程如下:
| Stage | Data | Resolution | Batch size | $\Delta t$ | $\beta$ | Iterations | LR |
|---|---|---|---|---|---|---|---|
| Pre-training | 450M + synthetic text data | 256px | 768 | 0.2 | 2 | 250K | $1\times10^{-4}$ |
| Pre-training | same | 512px | 768 | 0.2 | 2 | 300K | $5\times10^{-5}$ |
| Pre-training | same | 768px | 384 | 0.1 | 2 | 100K | $2\times10^{-5}$ |
| Pre-training | same | 1024px | 192 | 0.1 | 2 | 100K | $2\times10^{-5}$ |
| Continual training | 9M | 1024px | 192 | 0.1 | 1 | 180K | $1\times10^{-5}$ |
| SFT | 650K | 1024px | 192 | 0.1 | 1 | 10K | $1\times10^{-5}$ |
所有尺度模型都遵循这个 resolution curriculum。论文还使用 free-aspect-ratio buckets,包括 16:9、4:3、3:2、1:1、3:4、2:3、9:16,并在预训练和后续阶段使用 EMA 0.9999。
Inference:测试时到底怎么生成结果
推理时 SFD 使用三阶段 asynchronous denoising schedule。
| 阶段 | 条件 | 更新对象 | 作用 |
|---|---|---|---|
| Semantic initialization | $t_s \in [0,\Delta t)$, $t_z = 0$ | semantic only | 先建立全局语义、对象和布局 |
| Asynchronous generation | $t_s \in [\Delta t,1]$, $t_z \in [0,1-\Delta t)$ | semantic + texture | 语义先行,纹理在 cleaner anchor 下生成 |
| Texture completion | $t_s = 1$, $t_z \in [1-\Delta t,1]$ | texture only | 语义固定后细化外观 |
实现上,论文用两个 mask 控制哪条 latent stream 被更新:
\[[\mathbf{M}_s, \mathbf{M}_z] = \begin{cases} [\mathbf{1}, \mathbf{0}], & t_s \in [0,\Delta t),\; t_z = 0 \\ [\mathbf{1}, \mathbf{1}], & t_s \in [\Delta t,1],\; t_z \in [0,1-\Delta t) \\ [\mathbf{0}, \mathbf{1}], & t_s = 1,\; t_z \in [1-\Delta t,1] \end{cases}\]实际 velocity 是:
\[\hat{\mathbf{v}} = [\mathbf{M}_s \odot \hat{\mathbf{v}}_s,\; \mathbf{M}_z \odot \hat{\mathbf{v}}_z]\]结束后,semantic latent 被丢弃,只解码 fully denoised texture latent $\mathbf{z}_1$。这个细节很关键:semantic latent 是生成过程中的结构条件,不是最终图像的直接解码来源。
GitHub README 显示公开推理接口已经支持 Base、RL 和 Turbo checkpoint。Base/RL 默认 50 steps、guidance 4.0;Turbo 默认 4 steps、guidance 1.0。README 也给出 inference.py 和 SEFIInferencePipeline.from_pretrained(...) 两种入口。
Evaluation:验证集、指标和 baseline 是否公平
论文的主要 baselines 包括 Qwen-Image、Z-Image、FLUX.2-Klein-9B、JoyAI-Image 和 Z-Image-Turbo。评价覆盖 prompt following、compositional reasoning、long-text rendering、visual text generation 和 bilingual instruction generation。
SFD 本身是否有用
作者先在受限设定下做了 SFD 对照:50M internal image-text samples,$256\times256$,LR $1\times10^{-4}$,global batch 512,32xA800。对比三组:
- fine-tuned FLUX.2 VAE without SFD;
- vanilla FLUX.2 VAE without SFD;
- fine-tuned FLUX.2 VAE with SFD。
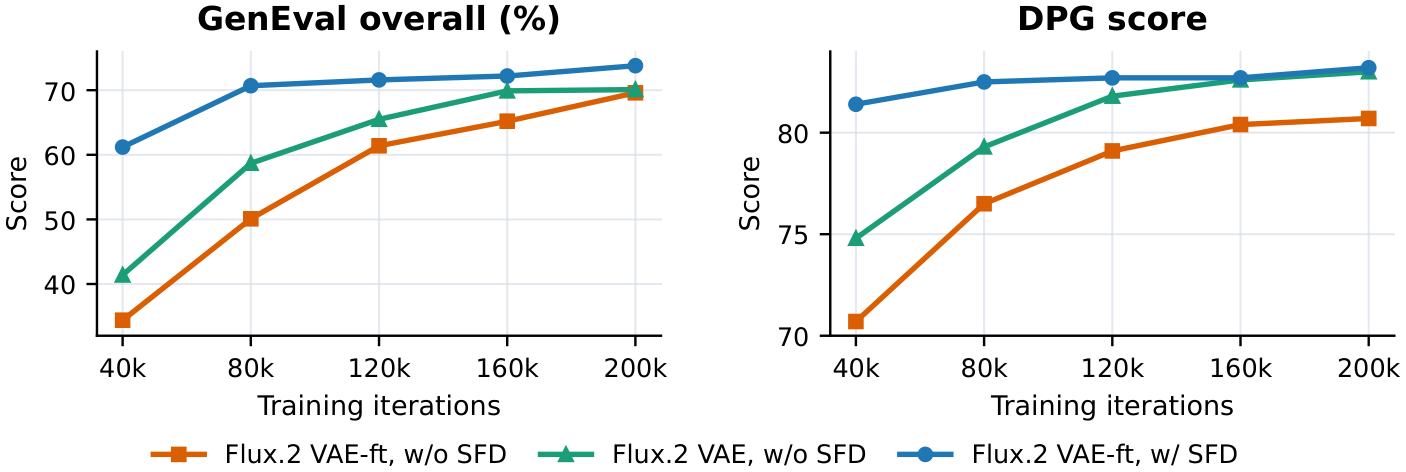
图:官方 convergence figure。SFD 在相同 50M 内部数据设定下更快提升 GenEval 和 DPG,支持“semantic guidance 改善 learnability”的 claim。
这张图是本文最关键的证据之一。它避免了只用最终 5B 分数证明机制,因为最终分数混合了数据、SFT、RL 和模型规模。这个 constrained setting 更接近机制验证。不过它仍然使用内部数据,外部读者不能直接复查数据分布。
VAE 结果也支持 trade-off 叙事。Kodak 上,fine-tuned FLUX.2 VAE 把 PSNR 从 FLUX.2 的 33.18 提到 36.40,LPIPS 从 0.0442 降到 0.0235。OmniDoc-TokenBench 上,fine-tuned FLUX.2 VAE 在 PSNR、SSIM、LPIPS、FID 和 NED 上超过列出的 selected baselines,包括 Qwen-Image-VAE-2.0-f16c128。论文的解释是:SFD 给 texture generation 提供 semantic anchor,所以可以把 texture VAE 更大胆地推向高保真重建。
Main benchmark 数字
| Benchmark | SeFi-Image-5B 结果 | 主要对比 | 判断 |
|---|---|---|---|
| GenEval overall | 0.88 | Qwen-Image 0.87, FLUX.2-Klein-9B 0.85, Z-Image 0.84 | 领先,但优势不大 |
| DPG-Bench overall | 87.27 | Qwen-Image 88.32, Z-Image 88.14 | 不领先,接近强 baseline |
| LongTextBench avg | 0.978 | JoyAI 0.963, Qwen-Image-2512 0.960, Z-Image 0.936 | 明显强项 |
| CVTG-2K Word Acc. | 0.8947 | JoyAI 0.8739, Z-Image 0.8671, Qwen-Image 0.8288 | text rendering 强项 |
| OneIG-EN overall | 0.5606 | Z-Image 0.5460, Qwen-Image 0.5390 | 领先 |
| OneIG-ZH overall | 0.5379 | Qwen-Image 0.5480, Z-Image 0.5350 | 高于 Z-Image,低于 Qwen-Image |
这里需要把 claim 说准确。SeFi-Image-5B 在 long text、CVTG text rendering 和 OneIG-EN 上很强;在 DPG 上低于 Qwen-Image 和 Z-Image;在 OneIG-ZH 上没有超过 Qwen-Image。它的优势更像“用更少 compute 达到强综合水平,并在文本渲染/长 prompt 上突出”,不是每个 benchmark 都 SOTA。
RL post-training 的真实收益
附录里有 5B w/ RL 和 w/o RL 的消融。RL 主要提升 text rendering 和 prompt following:
| 指标 | w/o RL | w/ RL | 变化 |
|---|---|---|---|
| LongTextBench Avg | 0.9665 | 0.9780 | +0.0115 |
| CVTG-2K Word Acc. | 0.8783 | 0.8947 | +0.0164 |
| OneIG-ZH Overall | 0.5335 | 0.5379 | +0.0044 |
| OneIG-EN Overall | 0.5541 | 0.5606 | +0.0065 |
| DPG Overall | 87.45 | 87.27 | -0.18 |
DPG overall 略降,Global 子项从 93.06 降到 88.24。我的理解是,RL 的 reward design 更偏 text rendering、prompt following、visual quality 和 artifact suppression,不保证所有 compositional metrics 单调提升。这是一个诚实的 trade-off 信号。
Turbo variants
DMD2 把模型蒸馏成 4-step turbo variants。5B-Turbo 在 GenEval 是 0.86,DPG 是 86.45,低于 full-step teacher,但高于 Z-Image-Turbo 的 0.82 和 84.86。text-heavy benchmarks 上退化更明显:LongTextBench 和 CVTG-2K 更依赖细粒度字符和布局,少步数会损失中间修正机会。
这个结果符合直觉。semantic branch 先建立结构,所以 turbo 对 compositional structure 的损伤较小;但字符渲染和细节对 denoising trajectory 更敏感,压到 4 steps 后更容易掉。
实验与证据:哪些 claim 被支持,哪些还不够
我把论文的核心 claim 分成三层:
| Claim | 证据强度 | 说明 |
|---|---|---|
| SFD 改善训练收敛 | 较强 | constrained 50M 对照中 with SFD 明显更快;但数据仍是 internal |
| SFD 改善 reconstruction-generation trade-off | 中等偏强 | VAE 重建指标提升,同时 SFD 对照保持生成优势;但没有公开可复查训练数据 |
| 5B 用 125K A800 GPU hours 达到强 T2I 水平 | 中等 | 多 benchmark 支持 strong performance;但 compute 对比依赖不同硬件、训练栈和数据质量 |
| Text rendering 是强项 | 较强 | LongTextBench、CVTG-2K、qualitative examples 都支持 |
| 全面优于 Qwen-Image/Z-Image | 不支持 | DPG 和 OneIG-ZH 上并非第一 |
| 方法适合 image editing | 尚未验证 | 局限性中作者也承认未验证 multimodal / image-conditioned generation |
最值得肯定的是,论文没有只展示最终 leaderboard,而是给了 SFD convergence、VAE reconstruction、model scaling、RL ablation 和 turbo evaluation。最需要保留问号的是数据闭源与 reward/eval 细节。对于 foundation model 报告,这通常是判断可复现性和外推性的核心。
复现与工程风险
官方 GitHub 是 inference repository。它提供 inference.py、Python API、Model Zoo 和依赖安装说明,但不是完整训练仓库。模型包括:
| Family | Checkpoints | Steps | Guidance |
|---|---|---|---|
| Base | SeFi-Image-1B/2B/5B-Base | 50 | 4.0 |
| RL | SeFi-Image-5B-RL | 50 | 4.0 |
| Turbo | SeFi-Image-1B/2B/5B-turbo | 4 | 1.0 |
推理复现的主要风险是 checkpoint 权限、显存、依赖版本和 HF 下载。训练复现的风险更大:
- 450M internal data 不公开;
- 28M synthetic text-rendering pipeline 有描述,但完整生成脚本未公开;
- Qwen3.5-2B recaptioning 细节、过滤阈值、数据比例不完整;
- proprietary VLM annotation/scoring pipeline 不公开;
- RL reward model、prompt groups、reward fusion、DiffusionNFT 超参不完整;
- evaluation scripts 和完整 prompt sets 未在论文中给出。
如果要做可控复现,我不会从 5B 训练开始。更合理的路径是:在公开小数据集上复现 dual latent + dual timestep SFD,对比同一 texture VAE 下 with/without semantic branch 的收敛曲线;然后再尝试小规模 text rendering synthetic curriculum。
总结
SeFi-Image 最有价值的地方,是把“语义先行”从一个 representation trick 变成了文生图基础模型的完整训练范式。它的核心思想很清楚:semantic latent 负责提前组织对象、布局和场景结构;texture latent 负责高保真图像细节;DiT 在 dual timesteps 下联合预测两条流,最后只从 texture latent 解码。
这篇文章给我的启发有三点。
第一,latent 不是越高保真越好,也不是越语义越好。真正的问题是:这个 latent 是否让生成过程更容易学习,同时保留任务所需的细节。SeFi-Image 的双 latent 设计是一个值得继续跟踪的折中。
第二,text rendering 的进步不只来自模型结构。28M synthetic text-rendered data、双语 dense/short captions、OCR-preserving SFT annotation 和 RL post-training 共同构成了结果。只复现 SFD,而不复现数据栈,很难得到同样的文本能力。
第三,论文的 claims 要分层看。SFD 收敛和 text rendering 的证据比较扎实;“全面优于所有强模型”并不成立;image editing 和 video generation 还只是未来方向。作者在 limitations 里也承认 scale、数据多样性、multimodal generation 都还有明显空间。
如果你关心的是开源可用模型,SeFi-Image 值得先跑 1B/2B/5B Base 和 Turbo,看真实显存、速度和中文文本渲染效果。如果你关心研究方向,它更像是一个提示:下一阶段的 diffusion foundation model 竞争,不会只在 denoiser backbone 上,也会在 latent representation、captioning/data engine 和 post-training reward 设计上。
Recommended citation: SeFi-Team, SeFi-Image: A Text-to-Image Foundation Model with Semantic-First Diffusion, arXiv:2606.22568, 2026.
Download Paper