
Self-Flow:把表征学习塞回 Flow Matching 训练目标里
Self-Flow:把表征学习塞回 Flow Matching 训练目标里
论文:Self-Supervised Flow Matching for Scalable Multi-Modal Synthesis
作者:Hila Chefer, Patrick Esser, Dominik Lorenz, Dustin Podell, Vikash Raja, Vinh Tong, Antonio Torralba, Robin Rombach
机构:Black Forest Labs / MIT
版本:arXiv v1,submitted 2026-03-06 UTC;官方 GitHub README 标注 ICML’26
链接:Paper / PDF / Project / Code / Model
本文基于 arXiv PDF、arXiv TeX source、BFL project page、官方 GitHub README 和 Hugging Face model card 阅读,检索日期:2026-05-24
开篇点评:这篇论文到底解决了什么问题
Self-Flow 讨论的不是一个新的 sampler 小技巧,而是生成模型训练目标里的一个结构性问题:Flow Matching / diffusion 训练很擅长学从噪声到数据的速度场,但这个去噪目标本身没有强烈动机去形成全局语义表征。
这就是 REPA 这类方法能生效的原因。REPA 用 DINOv2 之类的外部表征模型给生成模型的中间层加一个 alignment loss。工程上看,它像是在训练阶段给生成模型接了一个语义老师;推理时老师被丢掉,所以推理开销不变。
Self-Flow 的判断更激进一点:如果生成模型需要语义老师,问题不一定在模型容量,而可能在训练任务本身。标准 flow matching 对所有 token 使用同一个噪声时间步,模型可以大量依赖局部相关性去做 velocity prediction。它未必需要理解“这是一只猫”“这是手部结构”“这段视频的动作应该连续”。
作者提出的解法是把自监督任务放回 flow matching 内部。它不依赖外部 DINO、SigLIP、V-JEPA、MERT,也不需要每个模态挑一个合适的 encoder。核心机制叫 Dual-Timestep Scheduling:同一个样本里,不同 token 用两个不同的噪声时间步,让模型看到一个“部分更干净、部分更脏”的输入。随后用 EMA teacher 在更干净的输入上产生特征,让 student 从混合噪声输入中重建 teacher feature。
我的判断是,这篇论文最有价值的点有两个。
第一,它把“为什么生成模型学不好表征”从经验观察推进到训练目标层面的解释:uniform denoising 可以被局部线索解决,因此语义表征不是必需品。第二,它给出一个可以跨图像、视频、音频使用的自监督机制,而不是继续为每个模态寻找一个外部 teacher。
它的弱点也很明显:完整训练代码和多模态权重没有公开,文本图像、视频、音频都用了内部数据或部分内部 caption,最强的多模态实验更接近 research preview。能复现的是 ImageNet 256 x 256 inference 和官方 checkpoint,而不是论文里的完整多模态训练管线。
Paper Card
| 项目 | 信息 |
|---|---|
| Paper | Self-Supervised Flow Matching for Scalable Multi-Modal Synthesis |
| Authors | Hila Chefer, Patrick Esser, Dominik Lorenz, Dustin Podell, Vikash Raja, Vinh Tong, Antonio Torralba, Robin Rombach |
| Date / Version | arXiv v1,submitted 2026-03-06 UTC |
| Category | cs.CV;flow matching, self-supervised representation learning, multimodal generation |
| 核心方法 | Dual-Timestep Scheduling + EMA teacher feature reconstruction |
| 主模型 | ImageNet 用 SiT-XL/2;其他实验用 FLUX.2-style Transformer,约 625M 参数;定性文字图像还展示 4B multi-modal model |
| 数据 | ImageNet-1K;内部 image/video research datasets;FMA audio;RT-1 robotics |
| Project / Code / Model | BFL project / GitHub / HF checkpoint |
| 公开状态 | arXiv source 和官方 project page 公开;GitHub 主要是 ImageNet 256 inference code;HF 提供 ImageNet checkpoint |
| 复现判断 | ImageNet 采样和 ADM evaluation 路径较清楚;完整 Self-Flow 训练、多模态训练、内部数据、视频/音频模型不可完整复现 |
Abstract:论文摘要解读
摘要的逻辑很直接。强语义表征可以改善 diffusion 和 flow model 的收敛速度与生成质量,但很多现有方法靠外部模型来补这个能力。外部模型有三个问题:要单独训练或下载、目标函数和生成目标不完全一致、缩放行为不稳定。
Self-Flow 的核心说法是:依赖外部表征不是必然的。生成模型之所以需要外部 teacher,是因为标准 denoising / flow matching objective 本身没有鼓励模型学习全局语义。只要把训练任务改成必须跨 token 推断缺失信息,模型就会在学习生成的同时形成更好的内部表征。
Dual-Timestep Scheduling 是这件事的具体实现。它对 token 使用不同噪声水平,制造信息不对称:更干净的 token 提供上下文,更脏的 token 需要被推断。然后 student 在 mixed-noise input 上同时做两个任务:预测 flow velocity,以及重建 EMA teacher 在 cleaner input 上的特征。
摘要最后强调多模态。Self-Flow 不是只在 ImageNet 上做一个外部 DINO 的替代品,而是试图变成一种统一训练范式:图像、视频、音频都变成 latent token sequence 后,共享同一个 Transformer backbone 和同一套自监督机制。
Motivation
论文的 motivation 可以拆成两层。
第一层是对 REPA 的反思。REPA 的强处是推理无开销,并且在 ImageNet 上能明显加速和改善生成。但 Self-Flow 作者认为,这个效果有潜在偏差:DINOv2 本身大量使用了 ImageNet 相关数据,ImageNet class-to-image 可能正好是 DINO teacher 的舒适区。到了文本图像、视频、音频,外部 encoder 的目标和生成目标之间会更容易错位。
第二层是对 scaling 的反思。论文做了一个很关键的 sanity check:把 REPA teacher 从 DINOv2-B 换成更强的 DINOv2-L、DINOv3-B、DINOv3-H+。如果“更强表征 teacher 必然更好”,FID 应该改善。但实验结果相反:更强 DINO 反而让生成更差。作者把这解释为外部表征瓶颈,生成模型被迫贴近一个固定 teacher,而 teacher 的表征目标不一定对应生成质量。
这不是说 DINOv2 没价值。更合理的读法是:外部 alignment 是一个短期有效的训练捷径,但它把“生成模型应该学什么表征”的决定权交给了另一个模型。Self-Flow 想把这个决定权拿回来,让表征学习由生成任务自身诱导出来。
直观效果:先看它能做什么
论文主图很适合先看。左侧是 text-to-image FID 收敛曲线,Self-Flow 比 REPA 更快越过 vanilla flow matching,并且到 1M steps 还继续下降。右侧是定性结果:相比 vanilla flow matching,Self-Flow 在文字渲染、结构一致性和视频时间连续性上更稳。
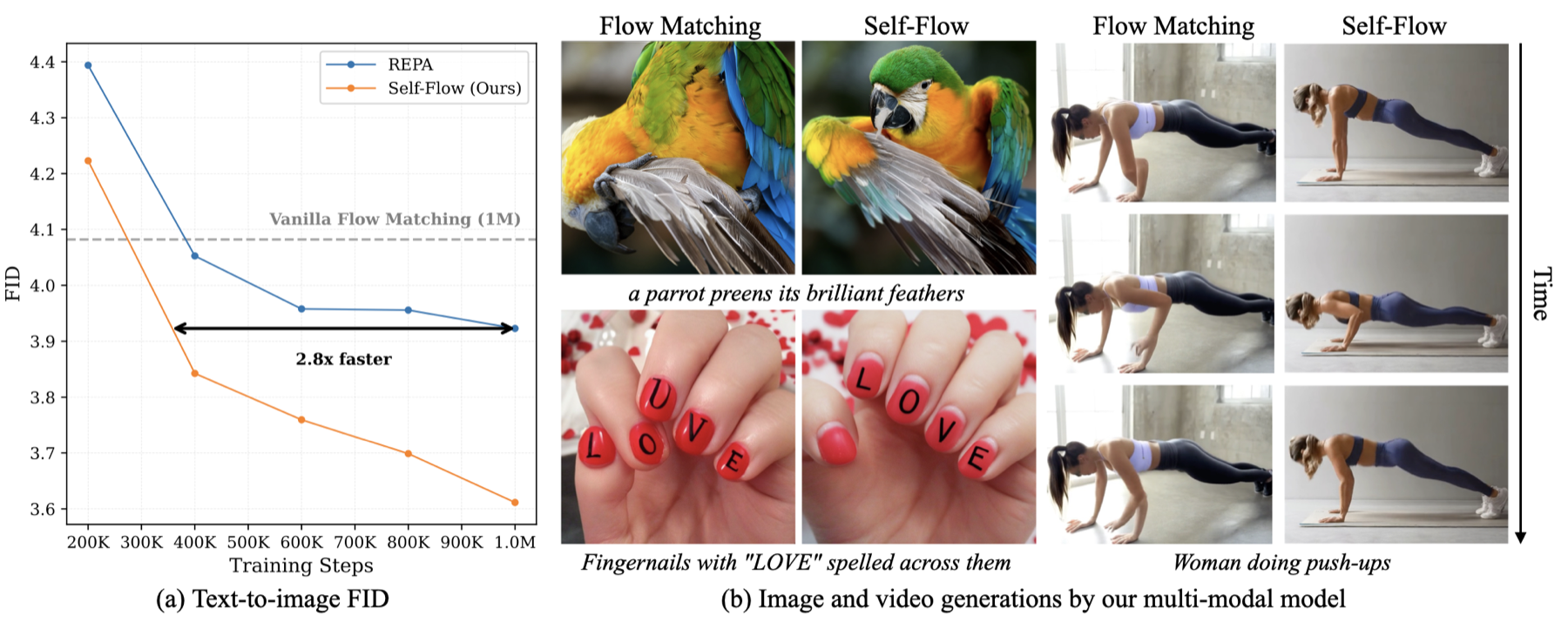
图:论文 teaser。左侧展示 text-to-image FID 收敛速度,右侧展示图像结构、文字和视频连续性的定性改善。它支持的理解点是:Self-Flow 的收益不是只在一个 ImageNet 指标上,而是在收敛、结构和时间一致性上同时出现。
这张图的证据强度要分开看。FID 收敛曲线是定量证据,可以支撑“Self-Flow 收敛更快”。右侧图像和视频帧是定性证据,可以说明 failure mode,但不能替代大规模用户评测。论文后面用 FID、FVD、FAD 和 ablation 来补定量支撑。
方法总览:核心思想和系统结构
标准 rectified flow matching 先把干净数据和噪声写成线性路径:
\[\mathbf{x}_t=(1-t)\mathbf{x}_0+t\mathbf{x}_1,\qquad t\in[0,1],\]其中 \(t=0\) 是干净数据,\(t=1\) 是纯噪声。目标速度场是:
\[\mathbf{v}_t=\frac{d\mathbf{x}_t}{dt}=\mathbf{x}_1-\mathbf{x}_0.\]模型训练目标是预测这个速度场:
\[\mathcal{L}_{gen}= \mathbb{E}\left\|f_\theta(\mathbf{x}_t,t)-(\mathbf{x}_1-\mathbf{x}_0)\right\|^2.\]这个目标的问题在于,所有 token 的噪声水平相同。局部相邻 token 之间仍然有很多可利用的低层统计关系,模型可能通过局部纹理、短程时间冗余或音频局部连续性解决训练任务,而不必形成强语义表征。
Self-Flow 增加了两个东西:
| 模块 | 做什么 | 解决什么问题 |
|---|---|---|
| Dual-Timestep Scheduling | 对同一样本采样两个时间步 \(t,s\),用 mask 把不同 token 分配给不同噪声水平 | 制造信息不对称,逼模型用 cleaner tokens 推断 noisier tokens |
| EMA teacher feature reconstruction | teacher 看更干净的输入,student 看 mixed-noise input,student 重建 teacher 中间特征 | 把“跨 token 推断”变成显式自监督表征目标 |
官方方法图如下。
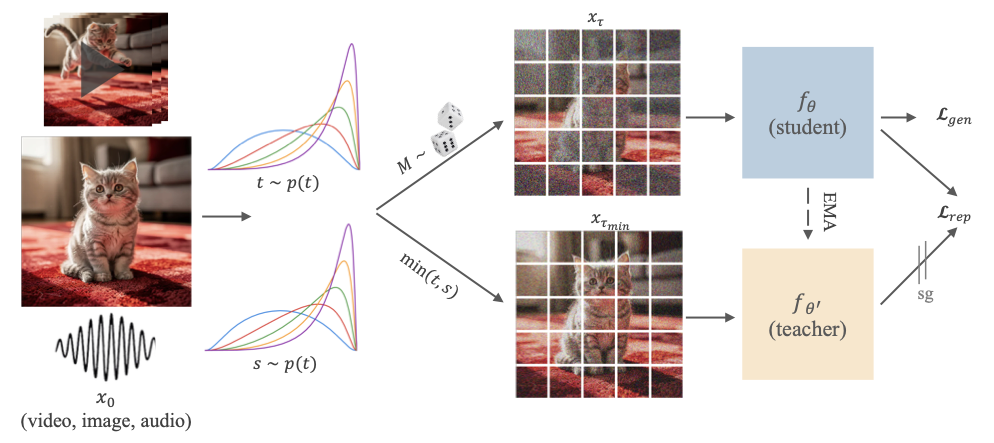
图:论文 Figure 3,对应 arXiv source 中 figures/architecture.pdf。它展示了 clean input 同时构造 student mixed-noise input 和 teacher cleaner input,student 同时承担 flow velocity prediction 和 teacher feature reconstruction。
这张图里有几个细节值得注意。
第一,student 和 teacher 不是两个独立训练的模型。teacher 是 student 的 EMA copy,论文实现里 EMA decay 是 0.9999。teacher 不反传梯度,只提供更稳定、更干净视角下的特征。
第二,teacher 的输入不是完全干净的 \(x_0\),而是所有 token 统一使用 \(\tau_{min}=\min(t,s)\) 加噪后的输入。也就是说 teacher 的优势来自“比 student 中一部分 token 更干净”,不是来自外部标签或外部 encoder。
第三,推理时没有 teacher、没有 projection head、没有 dual timestep mask。推理仍是普通 flow matching ODE 或 SDE sampling。训练时加任务,推理时不加组件。
Dual-Timestep Scheduling:为什么不是普通 masking
最容易把 Self-Flow 误解成 masked autoencoder。其实它更谨慎。
一个朴素做法是 full masking:随机把一部分 token 直接设成纯噪声,等价于 \(t=1\)。另一个做法是 diffusion forcing:每个 token 独立采样一个时间步。论文说这两种都产生明显训推差距。
原因在于推理时模型面对的是所有 token 处于同一时间步的输入。例如 ODE 从 \(t=1\) 逐步走向 \(t=0\),每一步的 latent 全体处于同一个噪声强度。如果训练时经常看到“部分 token 是纯噪声,部分 token 很干净”这种分布,模型会习惯不自然的局部条件,推理时反而退化。
Dual-Timestep 的折中是:
- 从同一个噪声时间步分布 \(p(t)\) 采样两个时间步 \(t,s\)。
- 采样 mask \(M\),mask ratio \(\mathcal{R}_M\leq0.5\)。
- 对第 \(i\) 个 token 使用
- 构造 mixed-noise input:
关键是每个 token 的边际时间步仍来自同一个 \(p(t)\)。训练输入局部是异质噪声,但单个 token 看起来并没有脱离正常 flow matching 的时间步分布。这是它和 full masking / diffusion forcing 的差别。
自监督表征目标:student 要重建谁的特征
Self-Flow 的 representation loss 写成:
\[\mathcal{L}_{rep}= -\mathbb{E}\cos\left( h_\theta^{(l)}(\mathbf{x}_{\boldsymbol{\tau}},\boldsymbol{\tau}), f_{\theta'}^{(k)}(\mathbf{x}_{\tau_{min}},\tau_{min}) \right).\]这里:
| 符号 | 含义 |
|---|---|
| \(f_\theta\) | student flow model,接收 mixed-noise tokens |
| \(f_{\theta'}\) | EMA teacher,接收统一 cleaner timestep input |
| \(h_\theta^{(l)}\) | student 第 \(l\) 层后接 MLP projection head |
| \(f_{\theta'}^{(k)}\) | teacher 第 \(k\) 层 feature |
| \(l<k\) | student 用较浅层去对齐 teacher 较深层,论文默认 \(l=0.3D,k=0.7D\) |
总损失是:
\[\mathcal{L}=\mathcal{L}_{gen}+\gamma\mathcal{L}_{rep}.\]论文 appendix 给出的默认实现包括:\(\gamma=0.8\),EMA decay 0.9999;image mask ratio 0.25,audio 0.5,video 0.1。video 的 mask ratio 更低,是因为视频存在显著时间冗余,mask 过多可能让训练任务偏离正常生成。
这个 loss 的机制不是“让 student 模仿自己”。teacher 的参数是 EMA,所以更平滑;teacher 的输入更干净,所以 feature 更有信息;student 的输入局部更脏,所以必须利用其他 cleaner tokens 补全语义。这个信息差才是自监督信号。
数据全流程:输入、表示、shape 和语义
论文把图像、视频、音频统一写成 token sequence:
\[\mathbf{x}_0\in\mathbb{R}^{N\times C}.\]不同模态先通过各自 autoencoder 进入 latent token 空间,再用 modality-specific input/output projection 接到共享 Transformer。
| 模态 | Autoencoder | 输入设置 | Token / Dim | 说明 |
|---|---|---|---|---|
| ImageNet image | SD-VAE | 256 x 256 | 256 tokens,dim 16 | 用于 ImageNet 和 T2I 可比实验 |
| image in multimodal | FLUX.2 AE | 256 x 256 | 256 tokens,dim 128 | FLUX.2 AE 使用 2 x 2 patching,总压缩因子 16 |
| RAE image | RAE | 256 x 256 | 256 tokens,dim 768 | 验证 Self-Flow 和 semantic latent 可互补 |
| video | WAN2.2 AE | 45 frames,192p | 约 3k tokens,dim 48 | 时间上压缩为 \(\lfloor1+(T-1)/4\rfloor\) 个 temporal latents |
| audio | Songbloom AE | 10 seconds | 250 latents,dim 64 | 25 latents / second;视频音轨任务使用 48 latents |
共享 Transformer 的配置来自 FLUX architecture 及 FLUX.2 修改:hidden size 1152,MLP ratio 4,16 attention heads,7 个 double MMBlocks 加 14 个 single Blocks,总规模约 625M。位置编码使用 3D RoPE,每个维度 24 channels。
训练流程可以按一个 batch 来读:
| 阶段 | 数据对象 | 训练时发生什么 | 推理时是否存在 |
|---|---|---|---|
| 1 | raw image / video / audio | modality-specific autoencoder 编成 latent tokens | 推理时从 noise latent 开始,最后 decode |
| 2 | clean latent \(x_0\) 和 noise \(x_1\) | 构造标准 flow path | 存在,对应 sampler state |
| 3 | timesteps \(t,s\) 和 mask \(M\) | 生成 mixed timestep vector \(\boldsymbol{\tau}\) | 不存在,推理用统一 timestep |
| 4 | student input \(x_{\boldsymbol{\tau}}\) | 输入 student,预测 velocity 和中间 feature | 推理只保留 student velocity |
| 5 | teacher input \(x_{\tau_{min}}\) | 输入 EMA teacher,提供 feature target | 不存在 |
| 6 | losses | \(\mathcal{L}_{gen}+\gamma\mathcal{L}_{rep}\) | 不存在 |
| 7 | output projection / decoder | 训练中回到模态 latent target;推理中解码成样本 | 存在 |
混合多模态训练时,每个 mini-batch 只包含单一模态,不在同一个 batch 里混合 image/video/audio。论文 appendix 说 batch size 分别为 image 38、video 8、audio 16,这是为了让不同模态的 step time 接近。模态采样概率是 image 57%、video 30%、audio 13%。剩下的 tradeoff 通过模态 loss weights \(w_I,w_V,w_A\) 控制。
这意味着“统一多模态模型”不是把所有模态 token 粗暴拼到每个 batch 里,而是共享 Transformer backbone,保留模态专属投影层,训练时在不同模态 batch 之间交替。
Training:监督信号、loss 和优化目标
Self-Flow 的训练目标有两个层次。
第一层是标准 flow matching。模型要预测从数据到噪声的 velocity \(x_1-x_0\)。注意在 Dual-Timestep 下,每个 token 对应自己的 timestep condition,所以模型的 timestep conditioning 从单个 scalar 扩展为长度为 \(N\) 的 vector。
第二层是 feature reconstruction。student 第 \(l\) 层经过 projection head 后,要和 teacher 第 \(k\) 层 feature 做 cosine similarity。论文默认选择较浅 student 层和较深 teacher 层,是因为较深 teacher 更可能包含语义信息,而 student 太深会干扰生成主干。
训练数据和步数如下:
| 任务 | 数据 | 训练规模 | Backbone |
|---|---|---|---|
| ImageNet class-to-image | ImageNet-1K,1.28M train / 50k val | 4M steps | SiT-XL/2,约 675M |
| text-to-image | 内部 20M text-image pairs,来自 200M image research dataset subset | 1M steps | FLUX.2-style,约 625M |
| text-to-video | 内部 6M videos,5k val | 600K steps | FLUX.2-style + WAN2.2 AE |
| text-to-audio | 1M CC-licensed FMA audio,20k val | 350K steps | FLUX.2-style + Songbloom AE |
| mixed multimodal | image/video/audio mixed datasets | 1M steps | shared FLUX.2-style backbone |
| joint video-action | RT-1,73.5k episodes | 100K finetune | initialized from video-weighted multimodal model |
定性样本使用 50 inference steps,image CFG scale 3.5,video/audio CFG scale 5。定量指标不使用 classifier-free guidance,这是为了避免 guidance 让不同方法的评估不公平。
Inference:测试时到底怎么生成结果
推理路径和普通 flow matching 基本一致:
- 采样纯噪声 latent \(x_1\sim\mathcal{N}(0,I)\)。
- 选择目标模态的 input/output projection 和 autoencoder decoder。
- 用训练好的 student model 预测 velocity。
- 通过 ODE 或 SDE sampler 从 \(t=1\) 积分到 \(t=0\)。
- 用对应 decoder 还原成图像、视频或音频。
teacher、EMA feature target、projection head、Dual-Timestep mask 都不在推理中出现。这个性质很重要,因为它让 Self-Flow 和 REPA 一样保持零额外推理开销。
但训练成本不是零。每步训练需要额外跑一次 EMA teacher forward,外加 projection head 和 representation loss。论文的论证是:更快收敛和更好 scaling 可以抵消这部分训练成本。从 FLOPs 视角看,Self-Flow 在相同 compute 下仍优于 REPA。
Evaluation:验证集、指标和 baseline 是否公平
论文的评测覆盖单模态、多模态和 joint prediction。主要指标包括:
| 任务 | 指标 | 评估方式 |
|---|---|---|
| ImageNet | FID, sFID, IS, Precision, Recall | 50k samples vs ImageNet validation;ADM evaluation code/reference batch |
| text-to-image | FID, sFID, IS, Precision, Recall, FD-DINOv2, CLIP | 内部 holdout set;FD-DINOv2 用 DINOv2 features |
| text-to-video | FVD, framewise FID | FVD 用 VideoMAEv2 features;framewise FID 用 Inception features |
| text-to-audio | FAD with CLAP / CLAP-M / CLAP-A | CLAP 系列音频表征上的 Frechet distance |
| robot video-action | SIMPLER success rate | RT-1 finetune,每个 checkpoint 运行任务组评估 |
baseline 选择大体合理。外部 encoder alignment 选择 REPA,并额外测了看似更适合各模态的 encoder:T2I 用 SigLIP 2,video 用 V-JEPA2 和 Depth Anything 3,audio 用 MERT。无外部 encoder 的 alignment baseline 选择 SRA,并在 appendix 用小规模实验解释为什么没有选 LayerSync。
最大风险不在 baseline 名字,而在数据公开性。T2I、T2V 和多模态核心结果都依赖内部数据集,holdout 也不是公开 benchmark。指标趋势可以读,但第三方很难完全复核。
实验与证据:哪些 claim 被支持,哪些还不够
ImageNet 上,Self-Flow 在不使用外部 representation 的情况下达到 FID 5.70,优于 REPA 的 5.89。这个结果有象征意义,因为 REPA 的 DINOv2 teacher 本身大量接触 ImageNet 相关数据。Self-Flow 能在这里追上并超过 REPA,说明它不是只靠“避开 DINO 不擅长的分布”取胜。
| Model | Steps | FID ↓ | sFID ↓ | IS ↑ | Precision ↑ | Recall ↑ |
|---|---|---|---|---|---|---|
| SiT-XL/2 | 7M | 8.30 | 6.30 | 130.57 | 0.69 | 0.67 |
| SRA | 4M | 7.27 | 5.87 | 143.06 | 0.69 | 0.68 |
| REPA | 4M | 5.89 | 5.73 | 157.66 | 0.70 | 0.69 |
| Self-Flow | 4M | 5.70 | 4.97 | 151.40 | 0.72 | 0.67 |
T2I 结果更能说明外部 alignment 的局限。Self-Flow 的 FID 3.61,优于 SRA 3.70、REPA 3.92、SigLIP 2 3.97。更关键的是 FD-DINOv2:REPA 直接对齐 DINOv2,FD-DINOv2 是它应该占优的指标,但 Self-Flow 仍从 173.35 进一步降到 167.98。
| Model | FID ↓ | FD-DINOv2 ↓ | CLIP ↑ |
|---|---|---|---|
| Vanilla Flow | 4.08 | 204.49 | 30.66 |
| SRA | 3.70 | 176.79 | 30.78 |
| REPA | 3.92 | 173.35 | 30.67 |
| SigLIP 2 alignment | 3.97 | 196.75 | 30.68 |
| Self-Flow | 3.61 | 167.98 | 30.88 |
video 和 audio 支撑了“外部 encoder 不易跨模态泛化”的 claim。video 上 Self-Flow FVD 47.81,REPA with DINOv2 是 49.59,SRA 是 49.75,vanilla flow 是 50.95。V-JEPA2 和 Depth Anything 3 这两个看似更 video/geometry-friendly 的 encoder 反而更差。
audio 上,Self-Flow 在 CLAP、CLAP-M、CLAP-A 三个 FAD variant 都最好。MERT alignment 的 CLAP FAD 148.883,几乎和 vanilla flow 148.874 持平,说明“找一个音频 encoder 来对齐”没有自然解决问题。
消融:Self-Flow 到底靠什么起作用
论文的 ablation 比较关键,因为 Dual-Timestep 和 representation loss 容易被误解成可以分开随便替换。
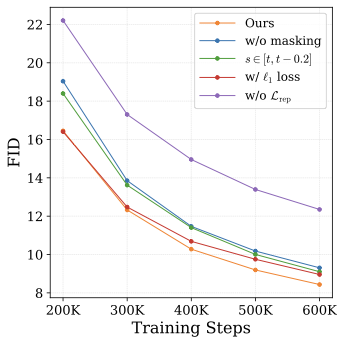
图:论文 ablation figure。移除 representation loss 退化最大;保留 loss 但去掉 masking 也明显退化;把第二时间步限制在接近原时间步的范围会削弱信息不对称;用 L1 替代 cosine similarity 会在训练后期不稳定。
从结果看,Self-Flow 不是单靠“多加一个 teacher loss”生效。去掉 masking mechanism 后,即使还有 feature reconstruction,FID 仍然明显变差。这说明信息不对称本身是必要条件。
第二个要点是,两个时间步需要有足够差异。把 \(s\) 限制在 \([t,t-0.2]\) 这种很近的范围,退化接近去掉 masking。直觉是:如果 teacher 和 student 看到的信息差不够,student 就没有被迫做跨 token 推断。
第三个要点是 cosine similarity。替换成 \(\ell_1\) loss 后,论文报告训练后期 feature norm 增大并导致数值不稳定。这符合很多 feature distillation 经验:直接回归 feature magnitude 容易把表征空间的尺度问题带进主训练目标。
Scaling:为什么它比 REPA 更像一个长期方案
论文在 290M、420M、625M、1B 四个 T2I 模型规模上比较 Self-Flow 和 REPA。结果趋势是模型越大,Self-Flow 相对 REPA 的优势越大,625M Self-Flow 甚至优于 1B REPA。
这支持了一个较强的结论:外部 alignment 可能在小模型或早期训练阶段很有用,但当生成模型继续扩展时,固定外部 teacher 会变成瓶颈。Self-Flow 的 teacher 跟着 student 通过 EMA 更新,表征目标会随生成模型能力一起变化。
这里要保留一个未知:论文没有公开完整训练代码和内部数据,所以 scaling curve 目前主要依赖论文报告。它的机制解释是合理的,但第三方很难低成本复刻。
多模态:统一的是 backbone,不是所有东西都混成一个 token soup
Self-Flow 的多模态实验容易被标题误导。它不是一个 fully any-to-any model,也不是每个 batch 都混合 image/video/audio tokens。它统一的是训练范式和大部分 Transformer 参数。
具体做法是:
| 部分 | 是否共享 |
|---|---|
| Transformer attention / FFN / modulation 主体 | 共享 |
| image/video/audio input projection | 模态专属 |
| image/video/audio output projection | 模态专属 |
| autoencoder decoder | 模态专属 |
| Dual-Timestep + Self-Flow loss 形式 | 共享 |
混合训练结果显示,在 5 组不同 \(w_I,w_V,w_A\) loss weights 下,Self-Flow 对 image FID、video FVD/framewise FID、audio FAD 都有改善。appendix 表格里每组权重的相对变化都为改善,例如 image-weighted、video-weighted、audio-weighted settings 下都没有出现某个模态被 Self-Flow 明显牺牲。
joint video-action 和 joint video-audio 更像是验证“表征能否迁移到联合预测”。RT-1 / SIMPLER 上,Self-Flow 在 100K finetune 内持续优于 vanilla flow matching,复杂任务如 Move Near、Open and Place 差距更明显。video-audio prediction 中,multi-modal initialization 优于 video-only initialization;有意思的是 video-only Self-Flow 还能优于 multi-modal vanilla flow matching。
我的读法是:这些实验支持“Self-Flow 学到的表征对复杂预测任务有帮助”,但还不能直接证明它已经是通用 world model。因为机器人实验只用 RT-1 subset,评估在 SIMPLER,任务数量有限;video/audio 数据也依赖内部 pipeline。
复现与工程风险
官方 GitHub 仓库的定位很清楚:它包含 ImageNet 256 x 256 的 inference code,可以加载 Hila/Self-Flow checkpoint 生成 50k images,然后用 ADM evaluation suite 评估 FID、IS、Precision、Recall。
公开复现路径大致是:
python -c "
from huggingface_hub import hf_hub_download
hf_hub_download(
repo_id='Hila/Self-Flow',
filename='selfflow_imagenet256.pt',
local_dir='./checkpoints'
)
"
torchrun --nnodes=1 --nproc_per_node=8 sample.py \
--ckpt checkpoints/selfflow_imagenet256.pt \
--output-dir ./samples \
--num-fid-samples 50000
README 里还给了 sampling 参数:默认 --num-steps 250,--mode SDE,--seed 31,--cfg-scale 1.0。HF model card 报告 ImageNet 256 checkpoint 的 FID 5.7、IS 151.40、sFID 4.97、Precision 0.72、Recall 0.67。
但训练复现存在明显缺口:
| 项目 | 状态 |
|---|---|
| ImageNet checkpoint | 公开 |
| ImageNet inference code | 公开 |
| Self-Flow training code | not publicly specified / not included in README |
| T2I/T2V/T2A training data | 大量内部数据,not publicly available |
| multimodal model weights | not publicly specified |
| full evaluation scripts for internal holdouts | not publicly specified |
| exact data filters / captioning pipeline | partially specified,细节不足 |
工程上还有几个风险。
第一,训练成本更高。每步多一次 EMA teacher forward,大规模 video/audio 训练下成本不小。论文用收敛和 FLOPs 曲线说明这笔成本值得,但具体到自己的集群,需要重新算 wall-clock、显存和吞吐。
第二,noise scheduler 敏感。appendix 明确讨论 timestep distribution,ImageNet/T2I 用 uniform,FLUX.2 AE、WAN2.2、Songbloom 各自有不同 shift。Self-Flow 的 mask 行为和 timestep distribution 耦合,换任务时不能只照搬一个默认 scheduler。
第三,mask ratio 不是统一超参。image 0.25、audio 0.5、video 0.1。视频因为时间冗余强而使用更低比例,这说明方法虽然跨模态,但仍需要模态经验。
第四,多模态训练的数据配比和 loss weights 会直接影响每个模态的质量。论文用了 batch size、sampling probability、loss weight 三层手段调平,这些都不是无脑默认值。
总结
Self-Flow 这篇论文的核心贡献不是“又一个更好的 FID”,而是提出了一个机制上更干净的问题重构:生成模型表征弱,可能不是因为缺一个外部 teacher,而是因为标准 flow matching 的 denoising 任务没有迫使模型学习全局语义。
Dual-Timestep Scheduling 用两个时间步在 token 之间制造信息不对称,EMA teacher feature reconstruction 把这种信息不对称变成自监督目标。训练时多一个 teacher 视角,推理时回到普通 flow matching。这个设计解释了它为什么能同时保留 REPA 的零推理开销,又避免每个模态依赖外部 encoder。
论文证据最强的部分是:ImageNet、T2I、T2V、T2A 多个任务都优于 REPA/SRA 等 baseline;ablation 明确显示 representation loss、masking、足够的 timestep gap 都不可或缺;scaling 实验显示 Self-Flow 比 REPA 更能利用更大模型。
需要谨慎的地方也很明确:完整训练代码和多模态权重没有公开,核心 T2I/T2V 数据是内部数据,许多 evaluation holdouts 无法第三方复核。因此它目前更适合作为“训练范式和研究方向”来读,而不是一个可以马上完整复现的工程 recipe。
对后续研究,我觉得有三条线最值得看:
- 把 Self-Flow 放到公开视频/音频数据上复核,确认跨模态收益不是内部数据选择带来的。
- 研究 mask ratio、timestep distribution 和 token topology 的关系,尤其是视频和长音频这种高冗余序列。
- 和 semantic autoencoder、RAE、REPA-E 类方法结合,判断“更语义化的 latent space”和“训练中自监督表征目标”到底是互补还是冗余。
如果只记一句话:Self-Flow 的意义在于,它把生成模型的表征学习从外部 encoder alignment 改成了内部训练任务设计。模型不是被 DINO 教会语义,而是在 flow matching 自己的 denoising 过程中被迫学会语义。
Recommended citation: Hila Chefer, Patrick Esser, Dominik Lorenz, Dustin Podell, Vikash Raja, Vinh Tong, Antonio Torralba, Robin Rombach. Self-Supervised Flow Matching for Scalable Multi-Modal Synthesis. arXiv:2603.06507, 2026.
Download Paper