
LPM 1.0:从 talking head 到实时对话角色 Performance Model
LPM 1.0:从 talking head 到实时对话角色 Performance Model
论文:LPM 1.0: Video-based Character Performance Model
作者:Ailing Zeng et al.
时间 / 版本:arXiv v1 2026-04-09,v2 2026-04-14
类别:Video generation / Character performance / Audio-visual conversation
链接:Paper / arXiv / Project
检索日期:2026-05-24
开篇点评:它不是在做更好的 talking head,而是在定义一个更难的任务
这篇论文真正有意思的地方,不是“又做了一个音频驱动人物视频模型”,而是把任务边界从 talking head 往外推了一圈:一个可交互角色不只需要张嘴同步,还要在沉默时能听、能反应、能维持人格化动作节奏,并且在实时流式生成里不丢身份。
作者把这个约束称为 Performance Trilemma:expressive quality、real-time inference、long-horizon stability 很难同时满足。我的判断是,这个三角说法有一定营销包装,但它确实抓住了当前 avatar / digital human 系统的真实矛盾:高质量离线扩散模型通常慢,实时模型常常动作保守,长序列自回归又容易身份漂移或结构崩坏。
LPM 1.0 的路线不是单点模块创新,而是系统工程式组合:先构造包含 speaking / listening / idle 的人类对话视频数据,再训练一个多模态条件化的 17B Base LPM,最后把离线 bidirectional 生成器蒸馏成 causal streaming 的 Online LPM。它的价值主要在这个全栈闭环:数据定义了任务,Base model 学到行为空间,Online model 把能力压到可交互延迟。

图:论文 teaser。它想展示的不是单帧照片级质量,而是三类能力同时成立:表达性动作、多角色/多风格泛化,以及长时身份稳定。图源为官方 arXiv source 中的 imgs/teaser.pdf。
Paper Card
| 项目 | 信息 |
|---|---|
| Paper | LPM 1.0: Video-based Character Performance Model |
| Authors | Ailing Zeng et al., 25 authors |
| Date / Version | submitted 2026-04-09, revised 2026-04-14, arXiv:2604.07823v2 |
| Project | large-performance-model.github.io |
| Code / Model | as of 2026-05-24, project page exposes demos and paper link; official code/checkpoint not publicly specified |
| Dataset | internal curated multimodal human-centric dataset; raw data, split, labels and LPM-Bench data are not publicly released in the paper |
| Backbone | paper consistently states final Base LPM is 17B; backbone wording is not perfectly consistent: introduction says 14B pretrained image-to-video foundation model, training/eval sections refer to Wan2.1-I2V (16B) |
| Core claim | full-duplex conversational character performance can be learned from video and served online with low latency |
| 复现状态 | method-level readable, system-level hard to reproduce because data, model, benchmark, training schedule details and weights are mostly closed |
Abstract:论文摘要解读
论文对 “performance” 的定义很关键:它不是单纯的面部动画,而是意图、情绪、人格在视觉、声音和时间行为上的外化。换句话说,角色是否“活着”,不只看口型是否对齐,还看它是否在对话节奏中持续表现出注意、迟疑、反应、情绪和姿态。
作者认为从视频中学习 performance 是传统 3D pipeline 的一种替代路径。传统角色制作依赖建模、绑定、动画和渲染,优点是可控,但扩展到大量身份、行为、情绪和交互场景时成本很高。大规模视频模型则可能把这种 authoring effort 摊薄到一个统一模型里。
但现有视频模型同时卡在三个维度:表达丰富度、实时推理、长时身份稳定。LPM 1.0 选择最苛刻的 conversational performance 作为目标,因为对话里角色要在 speaking、listening、reacting、emoting 之间不断切换。它给出的系统方案包括三层:构造 speaking-listening 对齐的数据和多粒度身份参考;训练 17B Diffusion Transformer 作为 Base LPM;再蒸馏成 causal streaming generator 作为 Online LPM,用于低延迟、无限长度的交互生成。
这段摘要隐含了一个判断:conversation 不是 talking-head 的子集,而是 human performance 的压力测试。 如果一个模型只能在“角色说话”时工作,它还没有真正解决交互角色生成。
Motivation
论文的动机可以拆成四个缺口。
第一,现有 speech-driven 头像模型通常忽略 listening。现实对话里,一半时间角色可能不说话,但它依旧要通过眼神、点头、身体姿态和微表情表达“我在听”。如果模型把沉默等同于静止,交互感会立刻消失。
第二,多模态控制仍然粗糙。对话角色不是由单一路音频决定的:speaking audio 约束口型、节奏和说话时动作;listening audio 触发对用户语音的非语言反应;text prompt 控制情绪、动作、视线、场景和风格。三者对应的时序粒度不同,不能简单拼在一起。
第三,单张参考图对身份约束不足。一个正脸 reference 不告诉模型角色侧脸、后脑、牙齿、笑纹、衣服背面 logo 长什么样。短视频里这种幻觉可能不明显,长对话里每一次转头、笑、皱眉都会暴露不一致。
第四,缺少面向 human-centric video 的大规模基座。很多 talking-head 数据集只覆盖窄域脸部或短视频,无法支撑全身动作、互动场景、长时稳定和多风格角色泛化。
因此,LPM 的核心假设是:Performance Trilemma 不是单靠一个 attention trick 能解决的架构问题,而是数据、条件控制、训练、推理系统必须一起设计的问题。
直观效果:先看它能做什么
项目页给了大量 demo,论文 teaser 和 qualitative figures 想证明三件事:第一,角色不仅说话,还可以表现倾听、唱歌、情绪表达和全身动作;第二,输入角色可以是写实人物、动画角色、3D 渲染风格或艺术风格;第三,长视频里身份和场景不要随时间明显漂移。
这里要分清证据强度。Demo 和 qualitative examples 能帮助理解目标任务和视觉效果,但它们不能替代完整 benchmark。真正支撑论文主张的是后面的 LPM-Bench 人评:GSB pairwise preference 和 1-5 Likert absolute score。
方法总览:三层系统,而不是单个模型
LPM 1.0 可以按三个层次理解。
- Data layer:从 raw video 中过滤出高质量 human-centric clips,做 speaking / listening / idle 三状态标注,构造 speaker-only / listener-only audio,并生成文本 caption 与多粒度身份参考图。
- Base LPM:一个离线高质量生成模型。它在 DiT 里同时接收 noisy video latent、first frame、identity reference images、text、speak audio、listen audio,学习可控且身份稳定的 conversational performance。
- Online LPM:一个实时流式模型。它把 Base LPM 蒸馏成 causal backbone + causal refiner,用 chunk-wise causal attention、KV cache、sink tokens 和流水线执行,支持固定延迟的在线输出。
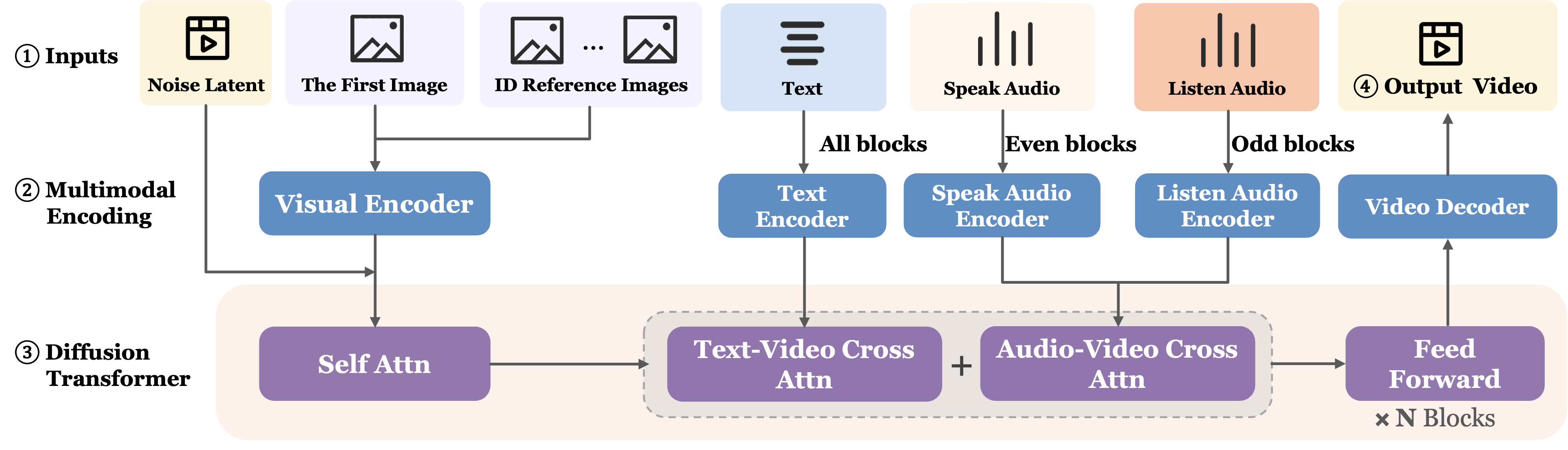
图:Base LPM 架构。官方图强调 visual tokens 走 self-attention,text/audio 走 cross-attention,identity references 被注入到视觉 token 序列中。图源为 arXiv source imgs/framework.png。
这张图里最重要的不是 “DiT blocks” 这个框,而是条件信号怎么进入模型。视频 latent、first frame 和多参考图处在同一个 visual latent/token 空间;text、speak audio、listen audio 则通过各自 encoder 变成条件 embedding,再在 DiT block 中注入。
数据全流程:输入、表示、shape 和语义
论文的数据部分写得很重,这不是偶然。LPM 的目标任务依赖“谁在说、谁在听、谁只是 idle”的精确区分,如果数据里只有说话人,模型就不可能学到自然 listening。
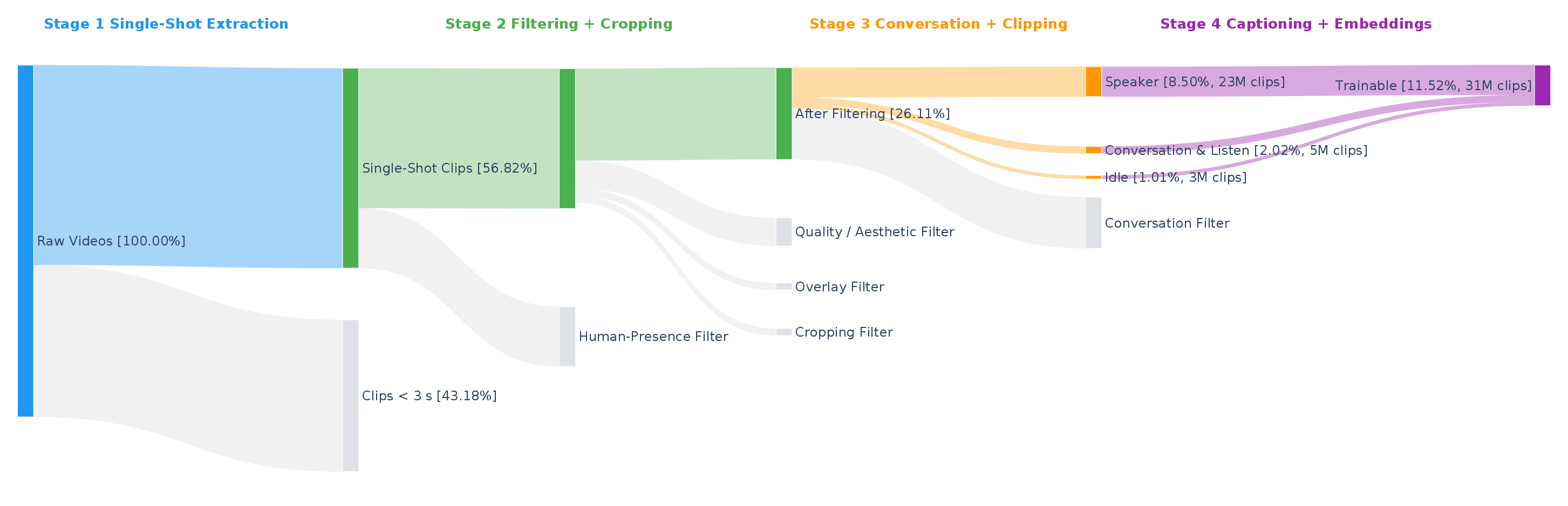
图:官方数据过滤漏斗。Raw videos 经过 single-shot extraction、quality filtering + cropping、conversation + clipping、captioning + embeddings,最终得到 31M trainable clips,约 11.52% 留存。图源为 arXiv source imgs/video_filter_pipeline_realnumber.pdf。
| 阶段 | 对象 | Shape / Dim | 语义 | 主要消费者 |
|---|---|---|---|---|
| Raw videos | heterogeneous long videos | not specified | 原始人类表演、对话、动作和场景来源 | filtering pipeline |
| Single-shot clips | temporally coherent clips | duration > 3s after filtering | 去掉镜头切换和过短片段 | human detection / quality filters |
| Person-centric clips | per-person tracks / crops | bbox trajectory; exact crop resolution not specified | 把多人镜头拆成单人视角,便于角色条件化 | LR-ASD, semantic verifier |
| Frame labels | speak / listen / idle | frame-level class sequence | 角色在每一帧的音频状态 | audio separation, training data curation |
| Audio variants | speaker-only / listener-only tracks | audio length aligned to clip; exact feature dim not specified | 区分说话驱动和倾听驱动 | speak / listen audio encoder |
| Captions / tags | dense natural language + structured tags | fixed-length clip and sentence-bounded segment | 动作、情绪、环境、镜头、人格/关系等控制语义 | text encoder / prompt distribution |
| Identity refs | global refs, 1-4 body views, 1-8 expression refs | image resolution not specified; encoded by same 3D VAE/patch embedding | 外观、视角和表情身份约束 | visual self-attention tokens |
| Video latent | $x_t$, symbolic shape B x C x T x H x W | paper specifies symbolic shape, not exact C/T/H/W | denoising target space | Base / Online DiT |
| Output video | generated character performance | 720P Base, 480P Online in eval | 说话、倾听、对话和长时表演视频 | user-facing output |
Speaking / Listening / Idle 三状态标注
论文把 conversational audio-video labeling 建成一个三状态问题:
| 音频状态 | 口型/视觉状态 | 标签 |
|---|---|---|
| 有语音,当前人物口型与语音同步 | synchronized lip motion | speaking |
| 有语音,当前人物口型静止但行为与语音相关 | still mouth + reactive behavior | listening |
| 无语音,口型静止 | silence | idle |
| 有语音但口型运动不同步,或无语音但口型异常运动 | inconsistent | discard |
作者在 LR-ASD 上做迁移学习,用 20K single-shot clips、约 95 小时人工帧级标注训练三状态分类器。测试时在两个 domain 的 2K 人工标注 clips 上评估,Domain 1 frame-level accuracy 为 89.75%,Domain 2 为 87.63%。更有意思的是失败模式:Domain 2 的 speak recall 到 94.05%,但 listen recall 只有 81.05%,说明噪声、画外音、低能量语音会把真实 listening 搅乱。
为了解决这种低层同步信号不够语义化的问题,论文又加了一个 fine-tuned Qwen3-Omni 做六类 semantic verification:Conversation、Listen_dialogue、Listen_nondialogue、Silence、Speak、Unknown。它在 overall F1 上达到 78.37,比 Gemini 2.5 Pro baseline 高 +7.90 absolute。最明显的收益在 Silence 和 Speak,分别 +19.40 和 +10.67。
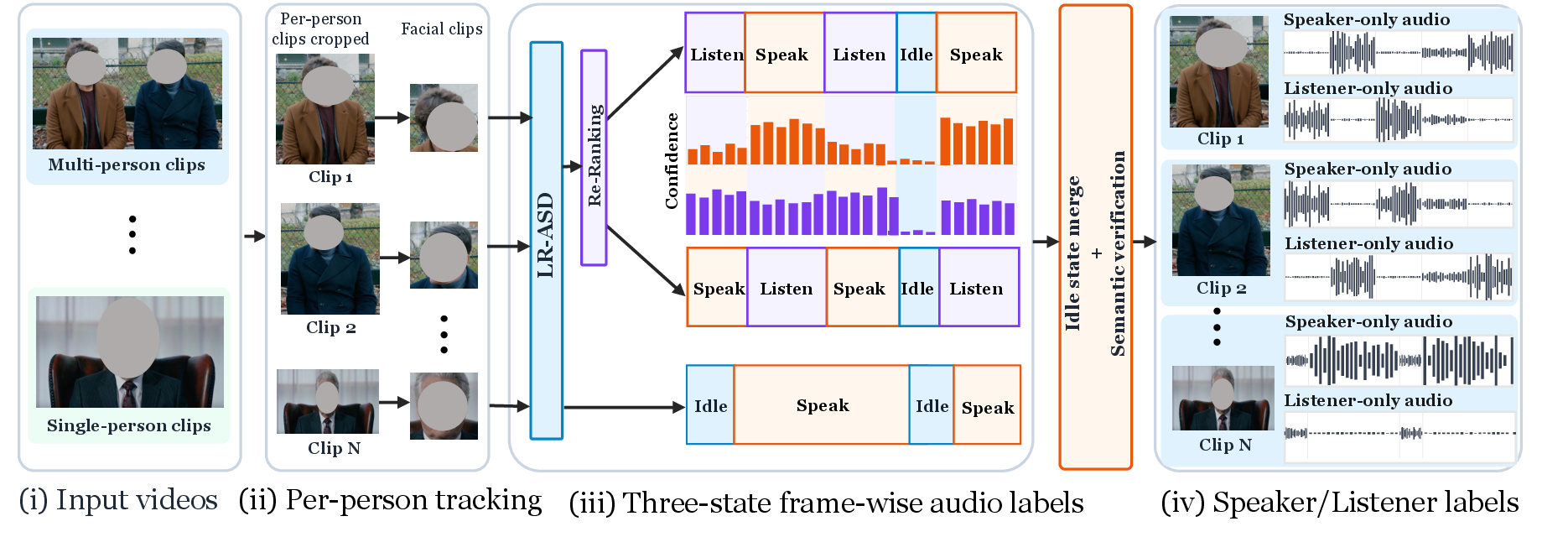
图:对话数据处理流程。multi-person clips 先被 tracking/cropping 成 per-person clips,再由 LR-ASD 给出三状态帧级标签,最后经过 reranking、idle merge 和 semantic verification,输出 speaker/listener audio variants。图源为 arXiv source imgs/conversation_pipeline_illustration_updated.pdf。
Listener 数据为什么要特殊处理
论文指出 listener-centric segments 只占 conversational segments 约 10%,而且 3.5M listener clips 里 70% 以上集中在 neutral / cognitive 类别,约 90% 是低 motion intensity。直接训练会把 listening 学成“安静坐着”。
所以作者筛出约 470K 高表现力或高参与度 listener clips 做 SFT,并按 emotion、expression、energy、motion 做重采样。这个设计很关键:listening 的难点不是让嘴别动,而是让身体和表情对语音内容产生低幅度但有语义的反应。
另一个细节是 listener captions 只保留 time-invariant attributes,例如外貌、人格、关系,而不是逐帧行为描述。原因很现实:在线推理时用户音频刚到,系统没有时间先生成 frame-level caption 再驱动视频。模型必须直接学习 audio -> visual reaction 的映射。
多粒度身份参考图
LPM 用三类 reference images 解决单图身份欠规约:
| Reference 类型 | 数量 | 解决的问题 |
|---|---|---|
| Global appearance reference | several candidates, exact count not specified | 整体外观、服装、场景和身份锚点 |
| Multi-view body references | 1-4 | 侧面、背面、转身时的结构和衣物细节 |
| Facial expression references | 1-8 | 笑容、牙齿、皱纹、表情形变等个体特征 |
Multi-view body references 的构造用 GVHMR 估计人体朝向,用 DROID-SLAM 估计相机姿态,再按相机和 SMPL root joint Z-axis 的夹角分成 frontal、rear、left-profile、right-profile。Expression references 则只从原始分辨率 >= 1080P 的视频中选,先用 EmotiEffLib 找 8 类表情,再用 Gemini 2.5 Pro 做二次语义验证。
这部分最像工程生产系统:它不追求一个漂亮模块,而是承认“身份稳定”本质上需要更多观测证据。
Base LPM:离线高质量生成器
Base LPM 是一个基于 continuous patchified video latent 的 Diffusion Transformer。给定 noisy video latent $x_t$、diffusion timestep $t$、text condition $c_{text}$、speak audio $c_{speak}$、listen audio $c_{listen}$ 和 reference images ${I_k}$,模型预测噪声:
\[\epsilon_\theta(x_t, t, c_{text}, c_{speak}, c_{listen}, \{I_k\})\]每个 DiT block 包含三段:self-attention with AdaLN、multi-modal cross-attention、FFN with AdaLN。
交错双音频注入
最值得拆开的设计是 interleaved dual-audio injection。Speaking 和 listening 是两类不同运动分布:
| Audio 分支 | 主要驱动 | 时序特性 | 需要的 attention 范围 |
|---|---|---|---|
| Speak audio | 口型、面部局部高频运动、说话节奏 | frame-level precise alignment | local audio window |
| Listen audio | 点头、眼神、姿态、情绪微反应 | 低频、语义驱动、有延迟 | larger audio context |
如果把两路 audio 都注入所有层,cross-attention 参数和 FLOPs 会增加,且两种信号会在同一表示空间里竞争。LPM 的做法是偶数层注入 speak audio,奇数层注入 listen audio:
\[K_s = W_k^{spk} c_{speak}, \quad V_s = W_v^{spk} c_{speak}\] \[K_l = W_k^{lis} c_{listen}, \quad V_l = W_v^{lis} c_{listen}\]text attention 和 audio attention 的输出用独立 projection 合并:
\[out = W_o^{txt} A_{text} + W_o^{aud} A_{audio}\]这个设计的机制意义是把 speaking/listening 的梯度路径拆开,同时保留同一个 DiT 主干。它不是纯粹为了省参数;更重要的是让相邻层的 self-attention 和 FFN 可以自然形成 speak-tuned / listen-tuned 的子网络。
身份参考图如何进入模型
参考图没有走额外 cross-attention,而是 encode 成 visual tokens 后直接拼到 video token sequence 末尾,参与 self-attention。这样身份约束和视频生成共享同一套 visual attention 权重。
为了区分 expression refs 和 body-view refs,论文使用 segment-wise 3D RoPE,把不同 reference type 和 subtype 分配到不同 temporal offset:
\[RoPE_{ij} = RoPE(t + o_i + so_j, h, w)\]其中 $i$ 是 reference type,$j$ 是 subtype,例如不同 expression 类别。这个设计比较轻:不额外引入 reference type embedding,而是让位置编码成为弱条件。它的风险是可解释性有限,但参数效率高,且适合可变数量 reference images。
Training:Base 与 Online 的训练目标不同
Base LPM 训练目标是高质量、可控、身份一致;Online LPM 训练目标是把这种能力迁移到低延迟 causal rollout。两者不能混为一谈。
Base LPM 训练流程
| 阶段 | 训练内容 | 目的 |
|---|---|---|
| Speak audio alignment | speaking-only + silence data,audio value projection zero-init | 先学口型和说话动作,不破坏预训练视觉能力 |
| Listen audio alignment | balanced mixture of speak/listen data | 学用户语音驱动的非语言反应 |
| Multi-reference identity training | global reference always; expression/body refs on 30% clips after audio alignment | 让模型在 reference 缺失或组合变化时都能工作 |
| Temporal extension training | clean global reference latent + random drop first 2-5 GT video latents | 缓解 chunk-wise continuation 的 training-inference mismatch |
| DPO post-training | preference pairs from multiple seeds + Flow Matching regularization | 减少手部/肢体伪像,提高 listening 自然性,防止 color shifting |
DPO 阶段的动机很明确:Flow Matching reconstruction loss 对“手是否合理”“听的时候是否僵硬”“动作是否自然”这类感知偏好不敏感。作者用多个 noise seed 生成候选,再用 Pareto-efficient selection 选 preferred sample:至少一个维度更好,且没有其他维度变差。这个标准比简单挑最漂亮样本更保守。
Online LPM 的训练:把 rollout 错误纳入训练分布
Online LPM 面临的问题不是“少采样几步”这么简单,而是因果自回归时历史上下文本身来自模型输出,误差会进入下一步条件。论文把它称为 self-induced history shift。
它的核心设计是 sequential relaxation:先用 backbone 维持轨迹稳定,再用 refiner 恢复细节。
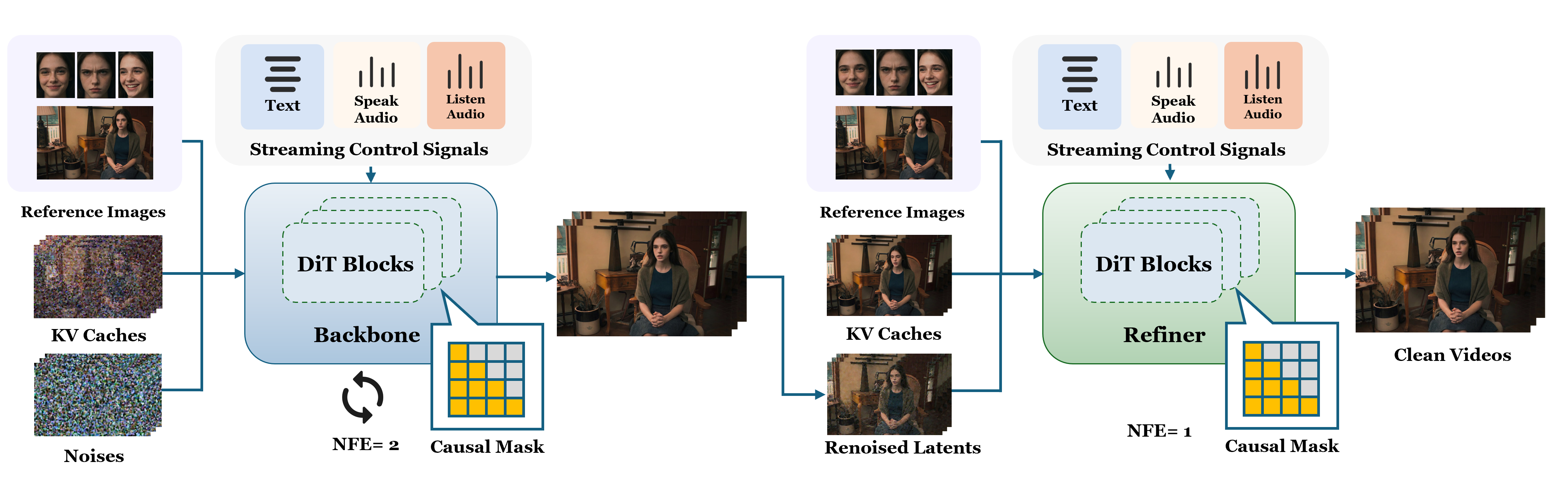
图:Online LPM 架构。Backbone 使用 noisy-history KV cache 生成稳定粗轨迹,Refiner 使用 clean-history KV cache 恢复最终 clean video chunks。图源为 arXiv source imgs/online_model.png。
| Stage | 模型 | 输入分布 | Loss / 目标 | 作用 |
|---|---|---|---|---|
| 1. ODE-based initialization | 2NFE causal backbone | teacher denoising trajectories | $L_2$ regression to clean latent | 给 causal student 一个稳定初始化 |
| 2. Off-policy DMD | backbone | re-noised teacher clean latents | DMD + LPIPS | 从 teacher manifold 上学分布匹配,降低 mode collapse |
| 3. On-policy DMD | backbone | current backbone autoregressive rollouts | DMD | 让训练输入分布等于推理 rollout 分布,缓解 exposure bias |
| 4. Refinement DMD | 1NFE causal refiner | re-noised backbone outputs | DMD to clean teacher target | 在真实 online 误差上恢复高频细节 |
这里最关键的是 Stage 3。很多蒸馏工作只从 teacher 轨迹采样,推理时 student 却必须面对自己的历史错误。LPM 明确把 backbone rollout 放回训练输入,让模型学会从自己的偏差中恢复。这个设计和 offline-to-online 的任务匹配度很高。
Inference:Base 是长视频续写,Online 是实时服务
Base LPM 和 Online LPM 的推理边界不同。
Base LPM 的输入准备包括三步:生成或给定角色 first-frame portrait 和多粒度 reference images;为每个片段准备 dual-stream audio,speaking track 来自目标台词的 speech generation,listening track 来自用户语音;再由 LLM 生成每 125 frames 的 chunk-level text prompt。它可以开关 speak/listen 分支,支持 speaking-only、listening-only、conversation。虽然训练 clips 只有 3-8 秒,但通过 latent-level chunk-wise continuation 和 overlap blending,论文称可生成约 10 分钟视频而无明显退化。
Online LPM 解决的是另一件事:控制信号流式到达,未来不可见,输出必须持续播放。它使用 1 秒 chunk、24 fps 的单位做流水线:
| 组件 | 论文报告的延迟 |
|---|---|
| Generator / Backbone, 2-step | about 700 ms |
| Refiner, 1-step | about 700 ms |
| VAE decode | about 180 ms |
| Text/audio encoders | negligible in reported runtime |
系统通过流水线并行让 Generator 处理当前 chunk、Refiner 处理上一 chunk、VAE decode 再上一 chunk。为了长时稳定,Online LPM 还用 pre-RoPE KV caching、sliding-window decoding 和 attention sink tokens。上下文结构是 sink tokens spanning 3 chunks + sliding window 2 chunks + current chunk,总共 5 chunks 的有效上下文,内存不会随会话长度线性增长。
音频流式处理也有单独设计:audio encoder 每次处理 3 秒窗口,其中 2 秒历史 + 1 秒当前,stride 为 1 秒,并在 600K streaming-formatted samples 上微调。这个 overlap-aware audio encoding 是为了减少 chunk boundary artifacts。
Evaluation:LPM-Bench 是否支撑 claim
LPM-Bench 有 1000 个 test cases,分成 functional layer 和 generalization layer。
| 子集 | 数量 | 关注点 |
|---|---|---|
| Speaking | ~400 | 78 emotions、22 expression bases、co-speech gesture、singing、bilingual pronunciation、full-body motion |
| Listening | ~200 | 关系、人格、语音内容、情绪背景、双语场景下的非语言反应 |
| Conversation | ~200 | 多轮说/听切换、单轮到 extended multi-turn dialogues |
| Diverse Human Motion | ~100 | 对话外的人体动作、物体/环境交互 |
| Character Generalization | ~100 | 写实、anime、3D-rendered、artistic characters |
评估维度包括 Motion Dynamics、Identity Consistency、Text Controllability、Audio-Video Synchronization。协议包括 GSB pairwise human preference 和 1-5 Likert absolute scoring。每对视频由 3 个独立评审员判断,最终多数投票。
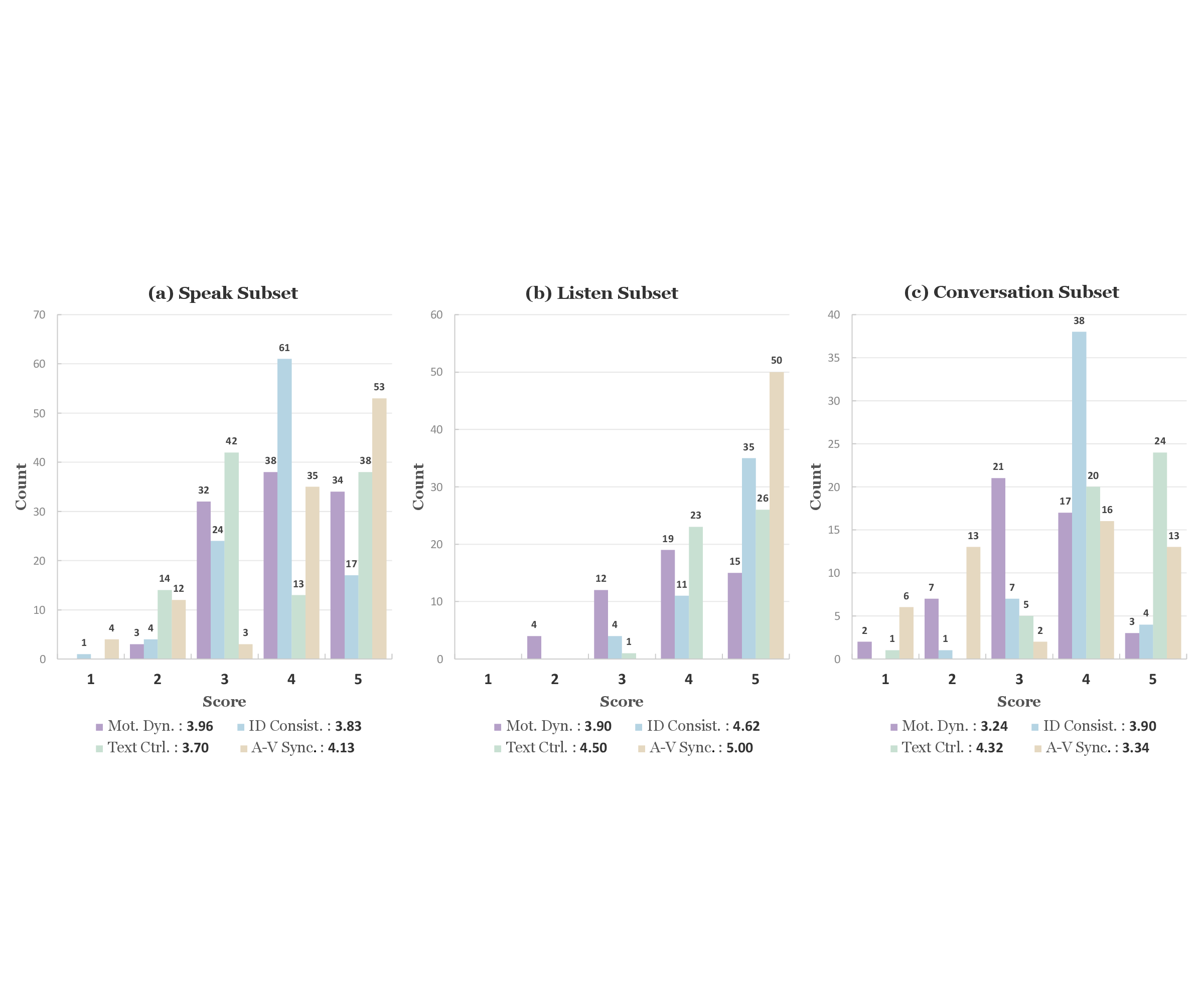
图:Base LPM 在 Speak、Listen、Conversation 三类场景上的 1-5 Likert 绝对评分分布。Listen 的 A-V Sync 达到 5.00,而 Conversation 的 Motion Dynamics 和 A-V Sync 是明显短板。图源为 arXiv source imgs/base_model_evaluation_absolute.pdf。
主要结果
| 模型 / 对比 | 结论 | 论文解释 |
|---|---|---|
| Base LPM vs Kling-Avatar-2 | Overall 64.3% preferred | 身份一致性、动作动态和 text controllability 更强 |
| Base LPM vs OmniHuman-1.5 | Overall 42.5% preferred,30.1% same,27.5% other | 对 OmniHuman 的优势较小,但 identity/text 更稳 |
| Online LPM vs LiveAvatar | Overall 82.5% preferred | Motion dynamics 和 A-V sync 优势大 |
| Online LPM vs SoulX | Overall 64.1% preferred,但 SoulX 在 identity consistency 上更占优 | SoulX 更保守,近正脸小幅动作更稳;Online LPM 行为更丰富 |
| Online LPM vs Base LPM | Speak 大体接近;Listen Base 更好;Conversation Online identity 更稳 | Online distillation 牺牲部分低幅度 listening 表现,但提升长时 rollout 鲁棒性 |
我认为实验基本支撑两个 claim:第一,LPM 的任务定义确实比单纯 speech-driven 头像更宽;第二,Online LPM 不是简单降质加速,而是在某些长时对话维度上重新分配质量。不过,“state-of-the-art” 仍要谨慎读:benchmark、测试集和评审协议都是作者自建,LPM-Bench 没有公开,外部复核难度很高。
实验与证据:哪些 claim 强,哪些还不够
强证据:listening 是一个真实数据问题。 论文不仅说缺 listening,还展示了 listener data 的分布偏斜、LR-ASD 的误差结构、semantic verifier 的 F1 改善,以及 listener SFT 数据的再平衡策略。这条证据链比较扎实。
强证据:多参考图对身份有帮助。 Ablation 中 emotion references 改善笑容、牙齿、微表情这类 person-specific expressive traits;view references 改善转身时身体结构和背部衣物细节。这个结论符合任务机制,也有 qualitative ablation 支撑。
中等证据:interleaved dual-audio injection 是必要的。 论文给了明确机制解释和参数/FLOPs 优势,但公开材料里对“交错注入 vs 双路全层注入 vs 单路融合”的定量 ablation 不够完整。它是合理设计,但必要性证据没有数据 pipeline 那么强。
中等证据:Online backbone-refiner 分解有效。 Base vs Online 的人评说明 few-step causal generation 能保留不少质量,Conversation identity 甚至更稳;但 DMD 四阶段每个 stage 的单独 ablation 没有充分展开。读者能理解它为什么合理,但很难判断每一阶段的边际贡献。
弱证据:安全措施的实际有效性。 论文写了 invisible watermarking、检测模型、input filtering、tiered access control,但没有给出 watermark 鲁棒性、detector ROC、绕过攻击或真实部署审计结果。这部分更像责任声明,不是技术验证。
复现与工程风险
这篇论文的工程信息量很大,但复现门槛也很高。
| 风险 | 具体原因 | 影响 |
|---|---|---|
| 数据不可复现 | 31M trainable clips、1.7T multimodal tokens、95h frame-level labels、15K semantic verifier labels、470K listener SFT clips 都是内部构建 | 外部团队很难复现 listening 能力和 long-horizon 稳定性 |
| Benchmark 不公开 | LPM-Bench 的 1000 cases、评审界面、具体 prompts/audio/reference 未公开 | 无法独立验证 SOTA claim |
| 模型权重未公开 | Project page 当前只有 demos/paper,无 code/checkpoint/data release | 只能做 paper-level 分析,不能 smoke test |
| Backbone scale 表述不一致 | paper 同时出现 14B pretrained model、Wan2.1-I2V (16B)、17B final model 等说法 | 复现时无法准确确定初始化模型和新增参数规模 |
| Online 系统细节不足 | DMD fake score estimator、timestep schedule、chunk latent layout、KV cache implementation、serving scheduler 未完全展开 | 难以复现低延迟长时服务 |
| 人评偏主观 | Overall realism、motion dynamics、listening appropriateness 依赖主观评审 | 结果方向可信,但精确数值需要外部复核 |
如果只想从这篇论文借工程思路,最值得复用的不是 17B 模型本身,而是三件事:三状态 conversational data labeling、multi-reference identity specification、offline teacher -> online causal student 的 on-policy distillation 思路。
总结
LPM 1.0 是一篇系统论文。它的主要贡献不是某个孤立模块,而是把 conversational character performance 拆成一个完整链条:任务定义、数据标注、身份 reference、Base DiT、多模态条件、DPO 偏好对齐、DMD 在线蒸馏、流式 runtime、LPM-Bench 评估。
我觉得它最有价值的地方是重新校准了数字人视频生成的目标。过去很多工作把“能说话”当作完成任务;LPM 把“能参与对话”作为目标。参与对话意味着角色在 speaking 和 listening 之间不断切换,在长时间里维持身份、动作风格和情绪连贯性。这比口型同步难得多。
问题也同样清楚:它高度依赖闭源数据和闭源系统,外部可复现性弱;Performance Trilemma 和 LPM-Bench 都是作者自定义框架,需要未来公开 benchmark 或第三方复核;Online LPM 在 subtle listening motion 上仍然有质量损失;安全部分还没有达到技术验证级别。
对后续研究来说,最有潜力的切入点不是“再做一个更大模型”,而是围绕 LPM 暴露出的真实瓶颈继续拆:如何公开构建可复现的 listening data,如何评价 listening appropriateness,如何让低延迟 causal rollout 不压制低幅度非语言反应,以及如何把对话记忆、多人互动和 3D/world consistency 纳入同一个 performance model。
参考来源
- arXiv:2604.07823 - LPM 1.0: Video-based Character Performance Model
- Official PDF
- Project page and demos
- Official arXiv TeX source, retrieved 2026-05-24, including
main.tex,1_introduction/,4_dataset/,2_base_model/,3_online_system/,3.5_infra/, and5_eval_sections/.
Recommended citation: Ailing Zeng et al. LPM 1.0: Video-based Character Performance Model. arXiv:2604.07823v2, 2026.
Download Paper