
RAEv2:Representation Autoencoder 的三个关键改进
RAEv2:Representation Autoencoder 的三个关键改进
论文:Improved Baselines with Representation Autoencoders 作者:Jaskirat Singh, Boyang Zheng, Zongze Wu, Richard Zhang, Eli Shechtman, Saining Xie 时间 / 版本:2026-05-18, arXiv v1 链接:PDF / Project / Code / Models / Data
开篇点评:这篇论文到底解决了什么问题
RAEv2 不是“又发明了一个新的 diffusion 架构”。它更像一份非常扎实的 baseline recipe:在 Representation Autoencoder 这条线上,把原始 RAE 的几个关键短板逐个补齐,然后证明这些补丁不是孤立 trick,而是可以形成一个一致的训练和推理机制。
原始 RAE 的方向很自然:用 pretrained vision encoder 替代传统 VAE encoder,让 diffusion 直接工作在更有语义的 latent space 中。但它也有几个现实问题:只用 encoder 最后一层,重建细节不够;高维 latent 让 diffusion 训练更慢;传统 CFG 在 RAE 上并不好用,原论文需要 AutoGuidance 这类额外弱模型。RAEv2 的核心回答是:同一个 pretrained representation 可以有三个角色,分别是 tokenizer、REPA target,以及 internal guidance 的弱预测分支。
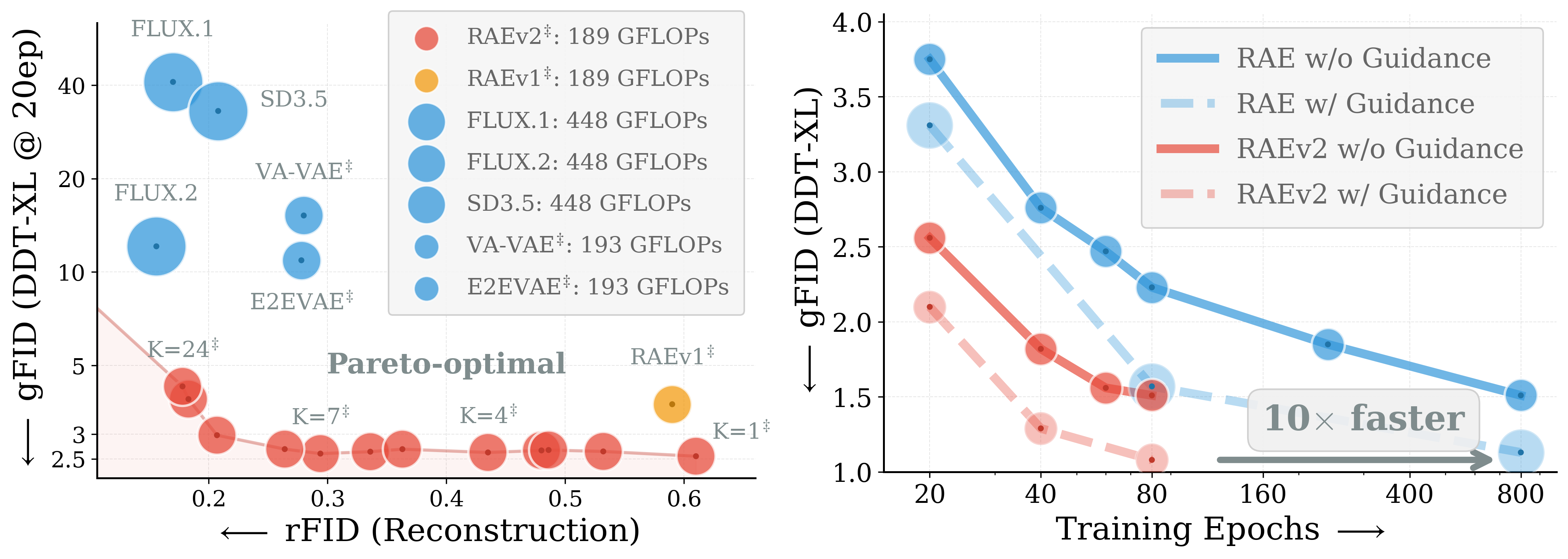
图:官方项目页 / 代码仓库中的结果总览。左图强调 reconstruction-generation Pareto tradeoff,右图强调相对原始 RAE 的训练收敛速度。
我的判断是,这篇论文最值得读的不是“gFID 1.06 又刷新了多少”,而是它解释了为什么 RAE 和 REPA 可以互补,以及为什么 x-prediction 在 RAE latent space 里能把训练监督和 guidance 串起来。这个机制对后续图像、视频、world model 的 latent tokenizer 设计都有参考价值。
Paper Card
| 项目 | 信息 |
|---|---|
| Paper | Improved Baselines with Representation Autoencoders |
| 任务 | Representation Autoencoder for latent generative modeling |
| 默认 encoder | ImageNet / NWM 用 DINOv3-L;T2I 用 SiGLIP2-B |
| 默认 backbone | DiT$^{DH}$-XL / DDT-style in-context conditioning |
| 主要结果 | ImageNet-256, 80 epochs, RAEv2 $K=7$: guided gFID 1.06, FD$_r^6$ 2.17 |
| 代码 | nanovisionx/RAEv2,包含 configs、数据和 pretrained models 下载入口 |
| 复现状态 | 代码和配置公开,但完整复现依赖大规模数据与 4x8 H100 级别训练资源 |
Abstract:论文摘要解读
论文说自己研究了三个 design choices:
第一,RAE 不应该只取 pretrained encoder 的最后一层 feature。不同层包含不同粒度的信息,最后几层的聚合可以在不微调 encoder、不引入新 learned 参数的情况下改善 reconstruction。
第二,RAE 并不会让 REPA 失去意义。虽然 RAE 已经把 pretrained representation 当输入 latent,但 REPA 对 diffusion 中间层的约束关注的是 spatial self-similarity,而 RAE latent 更偏 global semantics。两者不是重复监督。
第三,当 RAE latent 本身就是 encoder representation 时,REPA head 其实是在做 latent space 里的 x-prediction。把主模型输出也改成 x-prediction 后,REPA/base head 可以直接作为 internal guidance 的弱分支,不需要额外 AutoGuidance 模型,也不需要 CFG 的额外 unconditional forward pass。
这三个点合起来,形成了 RAEv2 的主线:representation 不只是编码器输出,而是贯穿 tokenizer、training target 和 inference guidance 的统一对象。
Motivation:为什么原始 RAE 还不够
传统 VAE latent 的优势是工程上成熟、分布比较稳定,但语义能力弱。RAE 用 DINO、SigLIP、CLIP 这类 pretrained vision encoder 作为 encoder,目标是把理解模型学到的语义直接带入生成模型。问题是,pretrained vision encoder 的最后一层通常更抽象、更语义化,不一定保留重建像素需要的局部结构。
如果直接把多层 feature 全部拼起来,代价又太高。按 sequence 拼接会把 latent token 数从 $N$ 变成 $LN$;按 channel 拼接会把维度从 $d$ 变成 $Ld$。这对 latent diffusion 都不友好,因为 Stage 2 需要在这个 latent space 里建模噪声到数据的连续路径。
所以 RAEv2 的第一步很克制:只从最后 $K$ 层拿 feature,但保持原始 latent shape $N \times d$ 不变。
方法总览:一张图看懂 RAEv2
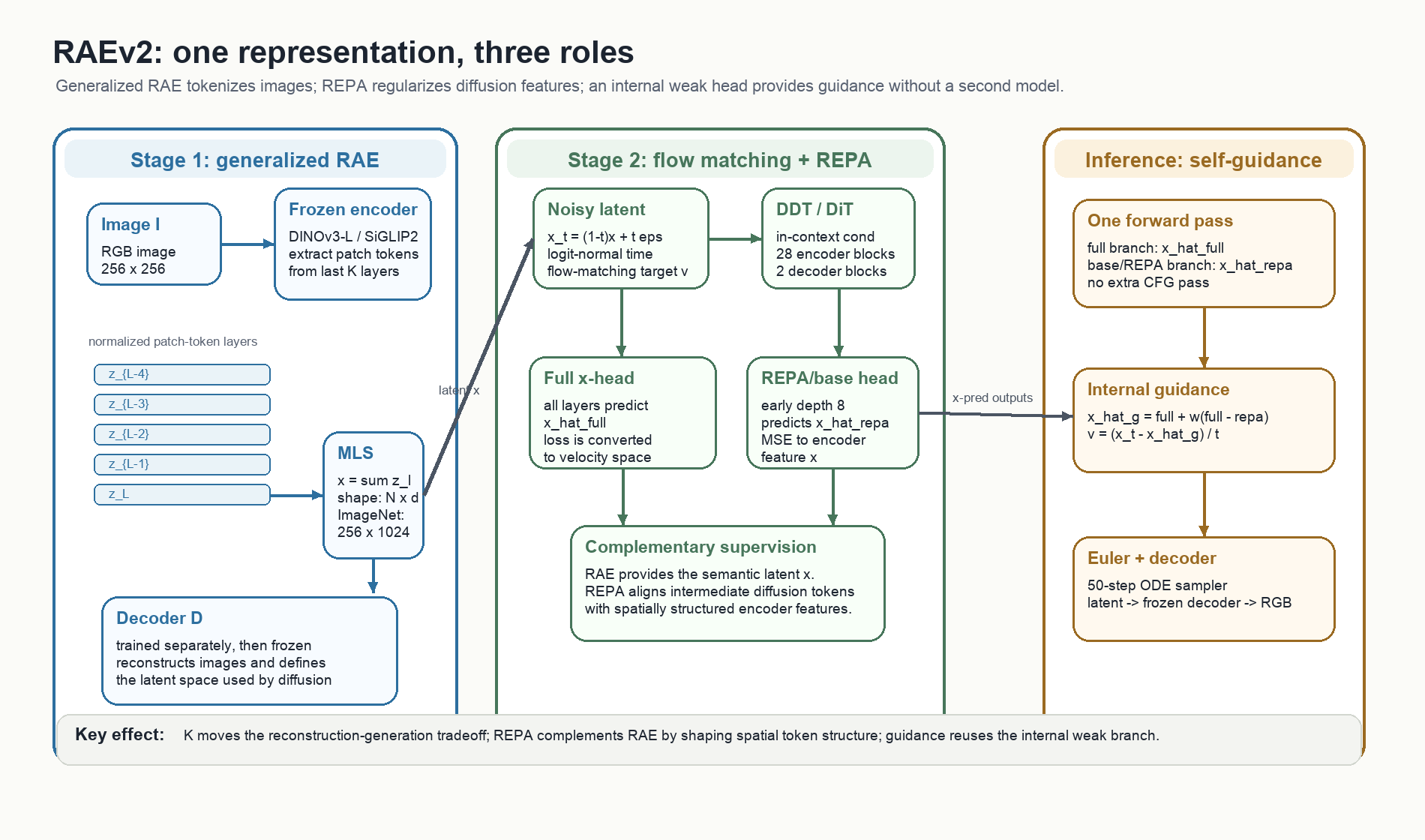
图:基于论文和官方代码重绘的 RAEv2 机制图。重点是三个角色:multi-layer RAE 产生 latent,REPA 约束中间 diffusion feature,x-pred base head 在推理时提供 internal guidance。
以 ImageNet-256 为例,数据流大致是:
- 输入 RGB image $I$,经过 frozen DINOv3-L encoder。
- 取最后 $K$ 层 normalized patch tokens,聚合成 latent $x$。
- Stage 1 decoder 单独训练,训练后冻结,用于 latent 到 RGB reconstruction。
- Stage 2 在 latent 上做 flow matching,模型输出 clean latent 的 x-prediction。
- REPA/base head 从第 8 层附近的 early feature 预测同一个 clean latent,训练时提供 MSE 对齐,推理时成为 weak branch。
- 最终用 internal guidance 得到 guided x-prediction,再通过 Euler ODE sampler 和 frozen decoder 得到图像。
这里真正重要的是训练和推理没有两套完全不同的辅助模块。REPA head 在训练时约束中间层,在推理时复用为 guidance 的弱分支。
方法一:Generalized RAE 不是只看最后一层
论文定义了一个 generalized representation encoder。设 encoder 有 $L$ 层,每层输出 patch-token feature $z_\ell \in \mathbb{R}^{N \times d}$。原始 RAE 等价于 $K=1$,也就是只取 $z_L$。RAEv2 考虑最后 $K$ 层。
Simple addition / MLS:
\[x = \sum_{\ell=L-K+1}^{L} z_\ell,\quad x \in \mathbb{R}^{N \times d}\]Random projection / MLR:
\[x = [z_{L-K+1} \Vert \cdots \Vert z_L]R,\quad R \in \mathbb{R}^{Kd \times d}\]两者都不改变 latent 的 token 数和 channel 数,也不需要 finetune encoder。实验中 MLS 更稳,所以后续默认用 MLS。DINOv3-L 上,$K=2$ 时 MLS 的 gFID 为 2.586,MLR 为 3.085;$K=8$ 时 MLS 为 2.688,MLR 为 3.580。重建指标接近,但生成质量差距明显。
我看官方代码时也确认了这一点:DINOv3MultiLayerSimpleAddEncoder 会解析 layers=11.13.15.17.19.21.23 这类配置,调用 get_intermediate_layers(..., norm=True),再对多层 patch tokens 做平均,并加入最后层 token mean。对应的 ImageNet $K=7$ 配置是 dinov3mls-vit-l16[layers=11.13.15.17.19.21.23]。
K 的含义:它不是越大越好
$K$ 控制的是 reconstruction 和 generation 的权衡。论文里最有意思的现象是,$K=23$ 重建最好,但生成不一定最好;$K=7$ 是 guided generation 的最佳点。
| Method | rFID | PSNR | gFID | IS |
|---|---|---|---|---|
| RAE | 0.602 | 18.93 | 2.23 | 214.8 |
| RAEv2 $K=7$ | 0.29 | 22.57 | 1.65 | 228.0 |
| RAEv2 $K=23$ | 0.18 | 27.03 | 3.02 | 206.0 |
$K=23$ 把更多层的信息带进 latent,像素重建自然更强。但 diffusion model 不只是重建,它要学习一个好建模、好采样的分布。过多细节可能提升 reconstruction,却让 generative modeling 更难。$K=7$ 的价值在于它保留了足够结构,又没有把 latent 变得过分复杂。
同时,论文检查了 linear probing:$K=1,4,7,23$ 的 ImageNet LP top-1 分别是 85.39、85.15、85.10、85.24。也就是说,多层聚合并没有明显破坏 encoder 的语义表征能力。
方法二:RAE 和 REPA 为什么是互补的
一个容易误解的地方是:RAE 已经把 pretrained representation 当 latent 了,为什么还要用同一个 representation 做 REPA target?这不会只是重复监督吗?
论文给出的解释是,两者约束的是不同性质。
RAE 主要改变 diffusion 的输入空间。更强的 vision encoder 给出语义更强的 latent,所以 RAE 的收益更接近 global semantic quality。REPA 则对 diffusion 中间层做 representation alignment,它更像是在规范 token-token spatial structure,让中间 feature 的局部相似性结构更合理。
| 论文对 27 个 encoder 做了相关性分析。REPA alone with VAE 时,LDS 对 gFID 的预测最强,$ | r | =0.89$,而 LP 甚至出现反相关。RAE alone 时,LP 主导,$ | r | =0.81$,LDS 很弱。RAE + REPA 时,LP 和 LDS 的平均指标相关性最好,$ | r | =0.83$。这组结果支持一个机制判断:RAE 用全局语义改善 latent,REPA 用空间结构改善 diffusion feature。 |
encoder sweep 也很直观:
| Encoder | LP | LDS | RAE gFID | RAEv2 gFID |
|---|---|---|---|---|
| MoCov3-B | 76.4 | 0.15 | 13.84 | 8.35 |
| WebSSL-1B | 84.1 | 0.18 | 8.60 | 4.16 |
| DINOv3-B | 84.5 | 0.38 | 4.25 | 2.76 |
| DINOv2-B | 83.9 | 0.41 | 3.75 | 2.81 |
| DINOv3-L | 87.0 | 0.42 | 3.30 | 2.61 |
DINOv3-L 同时有最高 LP 和 LDS,所以在 RAEv2 中最强。这个结果对工程很有用:选择 encoder 时不能只看 classification/linear probe,也要看局部空间结构是否适合生成。
方法三:REPA as x-prediction
RAEv2 最漂亮的机制是把 REPA 解释成 x-prediction。
在 RAE latent space 中,clean latent 就是 encoder representation:
\[x = E(I)\]REPA projection head 从 diffusion 的早期 hidden feature $h_t$ 预测这个 clean latent:
\[\hat{x}_{repa}=h_\phi(h_t)\]这其实就是一个早期、较弱的 x-prediction head。如果主模型输出也改成 x-prediction,full head 和 REPA/base head 就处于同一空间:
\[\hat{x}_{guided} = \hat{x}_{full} + w(\hat{x}_{full} - \hat{x}_{repa})\]再换回 velocity:
\[v = \frac{x_t - \hat{x}_{guided}}{t}\]这就解释了为什么它可以替代 AutoGuidance 的弱模型。AutoGuidance 需要额外训练一个 weaker model;CFG 需要额外 unconditional branch。RAEv2 的 REPA/base head 本来就在一次 forward 里出现,所以几乎是“免费”的 guidance source。
官方代码中,imagenet-dinov3l-k7.yaml 设置 transport.prediction: x,Stage 2 模型是 DiTwDDTHeadIG,并设 base_model_depth: 8。forward_with_internalguidance 的公式是 base + ig_scale * (full - base);Transport.convert_model_pred 在 prediction == "x" 时把 x-prediction 转成 velocity。这和论文里的机制是对齐的。
Training:监督信号和优化目标
Stage 1 是 decoder training。encoder 冻结,decoder 学 latent 到 RGB 的 reconstruction。官方 general decoder config 混合了 ImageNet、BLIP3o、RenderedText 和 FLUX synthetic 数据,训练 16 epochs;ImageNet-only config 也给出。
Stage 2 是 latent flow matching。代码里的核心路径可以概括为:
\[x_t = (1-t)x_1 + tx_0,\quad x_0 \sim \mathcal{N}(0,I)\]velocity target 为:
\[v_t = \frac{x_t - x_1}{t}\]但模型参数化为 x-prediction,所以训练时会把输出转换到 velocity 空间再算 loss。若启用 REPA,模型额外返回中间层 projection,和同一个 target encoder 的 patch tokens 做 MSE:
\[\mathcal{L}_{repa} = \lambda \lVert \hat{z}_t - z_{clean} \rVert_2^2\]官方默认 repa_coeff 为 0.5,alignment depth 为 8。ImageNet Stage 2 的 batch size 是 1024,80 epochs,bf16,EMA 0.9995,Euler sampler 50 steps。
Inference:为什么不用额外弱模型
推理时,模型可以走三种路线:
- 不 guidance:直接使用 full x-prediction。
- CFG:需要 conditional/unconditional 分支。
- Internal guidance:一次 forward 得到 full branch 和 base branch,做差后放大。
RAEv2 采用第三种。相比 AG,它不需要第二个模型;相比 CFG,它不需要额外 unconditional forward。这个点不是简单的工程省时,而是来自 RAE latent 的特殊性:REPA head 和 full head 都预测同一个 clean representation。
在实验上,RAEv2 $K=7$ 的 guidance ablation 是:
| Guidance | gFID | IS |
|---|---|---|
| no guidance | 1.65 | 228.0 |
| CFG | 1.49 | 242.1 |
| AutoGuidance | 1.14 | 255.3 |
| REPA Guidance | 1.06 | 255.3 |
CFG 有提升但不够;AG 很强但工程复杂;REPA Guidance 同时最好且最省结构。
Evaluation:训练效率比最终小数点更重要
论文提出 EP_FID@2:达到 unguided gFID $\le 2$ 需要多少 epochs。这个指标比单看最终 gFID 更能反映训练效率,尤其当很多方法都在 1.x gFID 附近时。
| Method | Epochs | EP_FID@2 | guided gFID | FD$_r^6$ |
|---|---|---|---|---|
| SiT-XL/2 | 800 | >800 | 2.12 | 8.44 |
| REPA-E | 800 | 480 | 1.12 | 3.04 |
| RAE-XL | 800 | 177 | 1.13 | 3.26 |
| RAEv2 $K=7$ | 80 | 35 | 1.06 | 2.17 |
这张表支持的是一个很具体的工程 claim:RAEv2 不只是最终分数高,而是在少一个数量级训练 epoch 的情况下达到同等级甚至更好的结果。论文/项目页还提到 ImageNet 训练约 10.5-12 小时,这对 baseline 迭代的意义大于单纯刷新 gFID。
Reconstruction:它和生成质量不是同一个目标

图:官方代码仓库中的 reconstruction comparison。RAEv2 $K=23$ 更偏重重建细节,$K=7$ 更偏向 generation tradeoff。
这张 reconstruction 图能解释为什么 $K$ 是必要旋钮。文本和局部纹理重建依赖更多中间层信息,$K=23$ 明显更强。论文还报告,用更多 decoder training data 后,$K=23$ 的 PSNR 从 27.04 提到 29.13,rFID 从 0.185 降到 0.158。也就是说 encoder 冻结不代表 decoder 不重要,decoder 数据和训练时长仍会影响最终 reconstruction。
但 generation 不是 reconstruction 的直接函数。论文里 $K=23$ 的 rFID 最好,gFID 却比 $K=7$ 差很多。我的理解是,$K=23$ 的 latent 更像一个细节密集的重建空间,而 diffusion 更喜欢可建模、语义清晰、复杂度适中的 latent。这个 tradeoff 在视频/world model 里可能更明显,因为过细 latent 会把时序建模难度也放大。
Generalization:T2I 和 Navigation World Model
T2I 部分使用 DiT$^{DH}$-XL,把 ImageNet 的 8 个 class in-context tokens 换成 Qwen3-0.6B text encoder 的 256 个 text tokens。训练包括 JourneyDB 和 BLIP3o long/short-caption 预训练 150K iterations,再用 BLIP3o-60k finetune 50 epochs。评测包括 GenEval、DPG-Bench、GenAI-Bench。
| Method | Pretrain GenEval | Pretrain DPG | Finetune GenEval | Finetune DPG |
|---|---|---|---|---|
| Flux-VAE | 41.7 | 77.6 | 78.3 | 79.2 |
| RAE | 58.4 | 80.1 | 81.5 | 80.6 |
| RAEv2 | 62.4 | 81.7 | 82.7 | 82.3 |
Navigation World Model 部分更能说明 latent 是否适合时序预测。模型条件是 4 帧历史画面,每帧编码成 $16 \times 16=256$ tokens,总共 1024 context tokens,再加 4 个 action tokens 和一个 rollout-time token。任务是在 RECON 上做 action-conditioned future-frame prediction。
| Method | FVD |
|---|---|
| DIAMOND | 762.73 |
| NWM | 200.97 |
| RAE | 312.01 |
| RAEv2 | 105.61 |
NWM 的提升很大,但也要注意:论文主要报告视频预测指标,不是 closed-loop navigation success rate。因此它证明的是 latent 和生成模型更适合 frame prediction,不应直接外推成机器人控制能力。
复现与工程风险
官方仓库给出的复现路径比较完整:uv sync 安装依赖,nanovisionx/RAEv2-data 下载数据,nyu-visionx/RAEv2-models 下载 pretrained encoders、Stage 1 和 Stage 2 checkpoints。训练入口分成 src/train_stage1.py 和 src/train.py,配置覆盖 ImageNet、T2I、NWM 的 $K=1,7,23$。
真正的成本在三处:
第一是数据。T2I 和 general decoder training 涉及 BLIP3o、RenderedText、Scale-RAE synthetic、RECON 等多个数据源,协议和预处理要对齐。
第二是算力。论文级别结果用 4x8 H100 环境,完整复现不是单机消费卡级别任务。
第三是评测。ImageNet gFID/IS 相对容易复现,FD$_r^6$、GenEval、DPG-Bench、GenAI-Bench、NWM rollout 指标都需要更严格的评测脚本和数据组织。
如果只是验证机制,我会优先做三个小实验:
- 固定 DINOv3-L encoder,比较 $K=1,7,23$ 的 Stage 1 rFID/PSNR。
- 固定 $K=7$,比较 RAE-only、RAE+REPA、RAE+REPA+x-pred base head 在 20 epochs 的 gFID。
- 固定 checkpoint,比较 no guidance、CFG、internal guidance 的采样成本和 gFID/IS。
Limitations:哪些结论还不能过度外推
第一,多层聚合方法仍然很简单。MLS 和 MLR 都是 training-free aggregation,没有学习 layer weights,也没有根据 token/location 自适应选择层。论文证明了简单方法够强,但没有证明这是最优聚合。
第二,encoder 选择仍然依赖经验搜索。LP 和 LDS 的分析很有启发,但还不是一个可以直接预测任意新 encoder 效果的理论模型。
第三,T2I 结果是 256 分辨率、短 schedule 的验证,不等同于高分辨率产品级 T2I 系统。它证明 RAEv2 recipe 能迁移到 text conditioning,但没有覆盖复杂高分辨率美学、长文本组合、编辑一致性等问题。
第四,论文里有少量小歧义,例如 ImageNet 训练时长有 10.5 小时和 12 小时两种说法,tab_xpred_ablation 的 caption 中 “without guidance” 和上下文略不完全一致。这不影响主结论,但复现时要以代码配置和实际日志为准。
总结
RAEv2 的价值在于把 Representation Autoencoder 从“换一个 encoder 的 VAE 替代品”推进成一个更完整的 generative tokenization recipe。它告诉我们:
- 不要默认最后一层视觉 feature 就是最适合生成的 latent;$K$ sweep 很重要。
- RAE 和 REPA 可以互补,因为一个偏 global semantic latent,一个偏 spatial token structure。
- 当 latent 本身就是 encoder representation,x-prediction 会让 auxiliary head、main head 和 guidance 落到同一空间,从而省掉额外弱模型。
对工程实践来说,我会把 RAEv2 看成一个优先级很高的 baseline:如果一个项目已经在考虑 DINO/SigLIP latent、视频 tokenizer、world model latent 或高效 T2I 训练,那么从 $K=7$ MLS encoder、frozen decoder、x-pred flow matching、depth-8 internal guidance 这条最小 recipe 开始,比直接复刻更大更复杂的 VAE/T2I 系统更有性价比。
Recommended citation: Singh et al., Improved Baselines with Representation Autoencoders, arXiv:2605.18324, 2026.
Download Paper