
ELF:把扩散语言模型留在连续 embedding 空间里
ELF:把扩散语言模型留在连续 embedding 空间里
论文:ELF: Embedded Language Flows
作者:Keya Hu, Linlu Qiu, Yiyang Lu, Hanhong Zhao, Tianhong Li, Yoon Kim, Jacob Andreas, Kaiming He
机构:MIT
时间 / 版本:arXiv v1,submitted 2026-05-11
类别:Diffusion Language Models, Flow Matching, Continuous Embedding Language Modeling
链接:Paper / PDF / Code / Models & Data
检索日期:2026-05-25
开篇点评:这篇论文真正推迟的是“离散化”
ELF 这篇论文最有意思的地方,不是简单地把 diffusion 或 Flow Matching 套到文本上,而是把文本生成里最麻烦的离散化操作尽量往后推。模型先把 token 序列编码成连续的 contextual embeddings,然后几乎整个 denoising trajectory 都在连续 embedding 空间里运行;只有到最后一步 $t=1$,才通过一个共享权重的 decode mode 和 unembedding layer 把 embedding 映射回离散 token。
这和很多 diffusion language model 的路线不一样。离散 DLM 通常在 token、mask、categorical distribution 或 semi-autoregressive block 上做扩散;连续 DLM 过去也常见,但效果经常落后,所以社区容易形成一个直觉:语言本质上是离散的,continuous diffusion 可能天然不适合文本。ELF 的回答更工程化:也许不是连续路线不行,而是 representation、prediction target、decode objective、guidance 和 sampler 还没有被组合到正确的位置。
我的判断是:ELF 的证据强度足以说明“continuous embedding DLM 在 100M 到 600M 量级、OWT/WMT14/XSum 这类设置下可以很有竞争力”,但还不能推出“它已经能替代 autoregressive LLM”。它的优势主要体现在 few-step diffusion language generation、continuous CFG、embedding-space refinement 和训练 token 效率;它的未知也很明显:更大模型、更长上下文、instruction following、复杂 factuality 和真实对话体验还没有被验证。
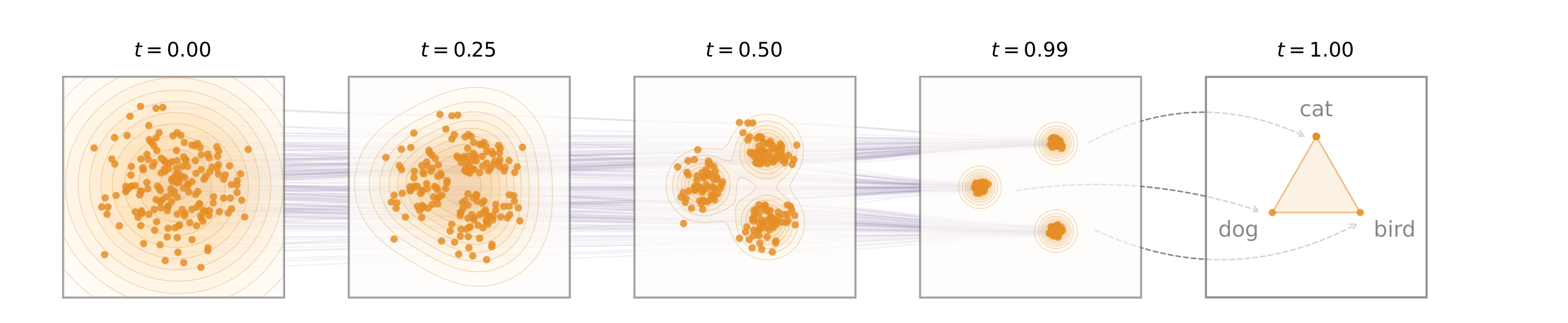
图:来自官方 GitHub / 论文 source 的 ELF conceptual illustration。橙色点表示连续 embedding 空间中的数据,轨迹从 Gaussian noise 走向 clean embeddings,离散化只在最终 $t=1$ 执行。
Paper Card
| 项目 | 信息 |
|---|---|
| Paper | ELF: Embedded Language Flows |
| Authors | Keya Hu, Linlu Qiu, Yiyang Lu, Hanhong Zhao, Tianhong Li, Yoon Kim, Jacob Andreas, Kaiming He |
| Date / Version | arXiv:2605.10938v1,submitted 2026-05-11 |
| Category | cs.CL, cs.AI, cs.LG |
| Code | lillian039/ELF,官方 JAX/TPU 实现;README 说明 PyTorch version 在 pytorch_elf branch |
| Checkpoints / Data | embedded-language-flows:ELF-B/M/L OWT checkpoints、ELF-B De-En/XSum checkpoints、T5-tokenized data、JAX T5-small encoder |
| Default model | ELF-B,105M diffusion model parameters;conditional setting 额外使用 35M T5-small encoder |
| Core representation | frozen pretrained T5-small encoder contextual embeddings,embedding dim 512,bottleneck dim 128 |
| Main tasks | OpenWebText unconditional generation;WMT14 De-En translation;XSum summarization |
| Core claim | continuous DLM 只要主要停留在 embedding space,并把 final discretization 训练成同一个网络的 decode mode,就可以超过多种 discrete / continuous DLM baseline,并用更少 sampling steps 和训练 tokens |
| 复现状态 | 论文给出 TeX source、官方 JAX code、HF checkpoints 和预处理数据;完整训练需要 TPU v5p ×64 级别资源,官方 README 的 sanity check 使用 validation set,和论文 test set 数字要分开看 |
Abstract 解读:把图像 diffusion 的武器搬到语言里
论文摘要的逻辑分三层。
第一层是背景判断:diffusion 和 flow-based models 已经是连续数据生成里的主流路线,尤其在 image/video 中很成熟;但当前表现最强的 diffusion language models 多数还是围绕离散 token 设计。
第二层是方法定义:ELF 是一种 continuous-time Flow Matching language model。它不是每一步都预测 token,也不是每一步都离散化,而是在 T5 encoder 的 embedding 空间里从 Gaussian noise 流到 clean embeddings。final step 才用共享权重网络把 embedding 读回 token。
第三层是实验结论:作者声称 ELF 在 generation quality、sampling steps 和 training-token efficiency 上优于 leading discrete and continuous DLMs。更关键的是,因为模型状态是连续量,CFG 这类 image diffusion 中非常成熟的技术可以直接迁移,而不需要重新发明离散 CFG。
所以 ELF 的核心不是“文本也可以做 diffusion”这个泛泛命题,而是一个更具体的设计假设:
语言的表层是离散 token,但生成轨迹不一定要在离散空间中完成;只要连续 representation 足够好,离散化可以被压缩成最后一步的 readout 问题。
Motivation:连续语言模型以前为什么弱
Diffusion language model 里有一个长期张力:文本 token 是离散的,但 diffusion / flow 的数学工具更自然地作用在连续空间。离散 DLM 的优势是任务接口贴近 token,训练目标和评估也比较直接;缺点是很多连续 diffusion 里已经验证有效的技巧,例如 CFG、ODE/SDE sampler、continuous-time schedule、trajectory-level refinement,都不能直接照搬。
连续 DLM 的反方向问题是 representation。若只是给 token 一个 embedding table,再对 embedding 加噪,模型未必能学到稳定的语言流形。embedding 既要承载语义和上下文,又要能被 decoder 精确读回 token;如果 decoder 另训、denoiser 另训,中间还会出现 train-test mismatch。
ELF 的 motivation 可以拆成三个具体问题:
- 表示问题:用什么连续空间表示 language data?ELF 默认选择 frozen pretrained T5-small encoder 的 contextual embeddings,而不是从零学习 token embedding。
- 目标问题:Flow Matching 里预测 velocity、noise 还是 clean data?ELF 选择 $x$-prediction,因为它同时适配 denoising MSE 和最终 token CE。
- 离散化问题:怎样从 continuous embeddings 回到 tokens?ELF 不单独训练一个 decoder,而是让同一个 Transformer 在 decode mode 下输出 clean embeddings,再用 learnable unembedding matrix $W$ 读出 token logits。
这三个问题合在一起,才是这篇论文的真正贡献。单独说“embedding diffusion”并不新,单独说“Flow Matching”也不新;ELF 的新意在于把 representation、shared-weight decode、training-time CFG 和 SDE sampling 拼成一个能跑出强指标的系统。
方法总览:训练时双分支,推理时最后一步才 decode
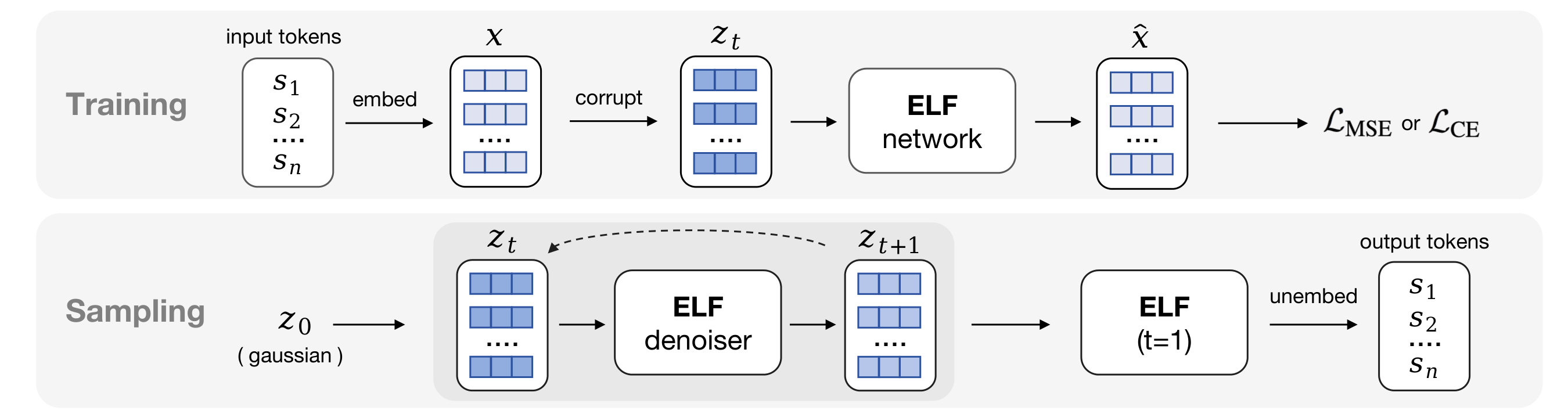
图:来自论文 TeX source 中 figures/training_inference_pipeline.pdf 的官方方法图。左侧训练时从 token 到 clean embeddings,再进入 denoise / decode 两种监督分支;右侧推理时从 Gaussian noise 开始迭代 denoise,最后一步切换到 decode mode 输出 token。
ELF 的数据流可以按训练和推理分开理解。
训练时,给定 token 序列 $s=[s_1,\ldots,s_L]$,先用 T5 encoder 得到 clean embeddings $x$。之后模型有两个 mode:
| 分支 | 输入 | 模型输出 | 监督 |
|---|---|---|---|
| denoise mode | 加噪后的 embedding $z_t$ | clean embedding prediction $\hat{x}$ | Flow Matching MSE |
| decode mode | 在 $t=1$ 附近被 corruption 的 $\tilde{z}$ | clean embedding prediction,再经 $W$ 得到 logits | token-level CE |
论文默认把 80% 训练样本分配给 denoising MSE,20% 分配给 decoding CE。注意它不是训练两个模型,而是同一个网络通过 mode token 区分 denoise / decode。
推理时,ELF 从 Gaussian noise $z_0 \sim \mathcal{N}(0,I)$ 出发,用 ODE 或 SDE sampler 在 embedding space 里迭代:
- 当前状态是连续 embedding $z_t$。
- 网络预测 clean embedding $\hat{x}$。
- 根据 $\hat{x}$ 转换出 velocity,推进到下一个 time step。
- 到 $t=1$ 时切换到 decode mode,用 $W\hat{x}$ 得到 token logits。
- 通过
argmax得到最终离散文本。
这就是“离散化只发生一次”的含义。模型不是一步步改 token,而是一步步改 embedding。

图:我根据论文方法和官方配置整理的数据流图。重点是 shared-weight denoise/decode 结构、MSE/CE 训练分支,以及推理时从 $z_0$ 连续走到 final decode。
关键数学:为什么是 $x$-prediction
ELF 使用 rectified-flow 风格的线性路径。令 $x$ 是 clean embedding,$\epsilon$ 是 Gaussian noise,则:
\[z_t = t x + (1-t)\epsilon,\qquad t\in[0,1]\]这里时间方向是从 noise 到 data:$z_0=\epsilon$,$z_1=x$。对应 velocity 是:
\[v = \frac{dz_t}{dt}=x-\epsilon\]标准 Flow Matching 可以直接训练网络预测 $v$。ELF 不这么做,而是让网络直接预测 clean embedding:
\[x_\theta = f_\theta(z_t,t)\]再由 clean prediction 转换成 velocity:
\[v_\theta(z_t,t)=\frac{x_\theta(z_t,t)-z_t}{1-t}\]于是 denoising loss 可以写成:
\[\mathcal{L}_{\mathrm{MSE}} =\mathbb{E}_{t,x,\epsilon}\left\|v_\theta(z_t,t)-v\right\|^2 =\mathbb{E}_{t,x,\epsilon}\frac{1}{(1-t)^2}\left\|x_\theta(z_t,t)-x\right\|^2\]这一步非常关键。论文的解释有两点:
第一,clean data prediction 在高维 representation 上更稳定。附录里比较了 $x$-, $v$-, $\epsilon$-prediction:$x$-prediction 在 T5-small/base/large 对应的 512/768/1024 维 embedding 上最稳定;$v$-prediction 维度变大后明显退化;$\epsilon$-prediction 基本会 collapse 到低 entropy 或高 Gen. PPL 区域。
第二,$x$-prediction 和 final decode objective 对齐。decode branch 也需要输出 clean embedding,然后用 unembedding matrix $W$ 读 token:
\[\mathcal{L}_{\mathrm{CE}} =\mathbb{E}_{\tilde{z}}\left[\mathrm{CrossEnt}\left(Wx_\theta(\tilde{z}),s\right)\right]\]如果 denoising branch 预测的是 $v$,decode branch 预测的是 token logits,那么同一个网络的输出语义会被撕裂。ELF 让两个分支都先预测 clean embedding,只是监督不同:一个用 embedding-level MSE,一个用 token-level CE。这是 shared-weight denoiser-decoder 能成立的基础。
训练机制:不是简单加噪,而是把最后离散化也训练进去
ELF 的训练 pipeline 有几个容易被忽略的细节。
1. Frozen T5 contextual embeddings
默认 representation 来自 frozen pretrained T5-small encoder,encoder 参数 35M,embedding dimension 512。ELF-B 本体 105M;在 conditional generation 表里写成 105M (+35M),就是因为还要算上 T5 encoder。
论文做过 embedding ablation:pretrained contextual embeddings 最好;从 OWT 训练的 scratch contextual encoder 也可以,但略差;非 contextual embedding 表现更弱;learnable embeddings 最差。这个结果说明 ELF 并不是“任意 embedding space 都能 flow”,它依赖一个已经有语言结构的连续空间。
2. Bottleneck 128
T5 encoder 输出维度是 512,ELF 不是直接把它当 Transformer hidden,而是先投到 bottleneck dimension 128,再投回 model hidden size。ELF-B 的 hidden size 是 768,depth 12,heads 12。附录比较 32/128/512 bottleneck:32 的 Gen. PPL 可能更低但 entropy 掉得多,512 保持更高 entropy 但 PPL 更差,128 是折中点。
这背后的直觉是:自然语言 embedding 可能在高维空间里落在较低维流形上。bottleneck 太小会压掉多样性,太大又让 denoising 目标变难。
3. Denoise / decode 训练比例
默认 80% denoise,20% decode。作者专门扫过 denoising-mode probability,结论是 0.8 在 ODE 和 SDE 下的 Gen. PPL / entropy trade-off 最好。比例太低时,模型没有足够 denoising 动态监督;比例太高时,final discretization 的 token readout 又可能不稳。
4. Decode branch 的 corruption
理论上 $t=1$ 时 $z_t=x$,如果直接拿 clean embedding 训练 decoder,任务过于简单,推理时 denoiser 输出稍有偏差就可能读错 token。ELF 因此在 decode branch 对 clean embedding 做 token-level corruption:
\[\tilde{z}=p x+(1-p)\epsilon\]$p$ 从另一个 logit-normal schedule 采样。OWT 上 decoder noise scale 是 5,conditional generation 上是 1。这样 decode mode 学到的是“从有误差的 final embedding 里恢复 token”,而不是只记住 clean embedding 到 token 的静态映射。
5. Self-conditioning 和 training-time CFG
ELF 没有 class label,于是用 self-conditioning 构造 CFG 的 condition。训练时 denoise branch 有 50% 概率先做一次 forward 得到中间预测 $\hat{x}’$,stop-gradient 后和 $z_t$ 拼接,再投回原维度。剩下样本用 zero condition。推理时则用上一时刻的预测作为 self-conditioning,不需要额外 forward pass。
CFG scale、time 和 mode 不是通过 adaLN-Zero,而是作为 in-context control tokens prepend 到序列前面。默认有 4 个 time tokens、4 个 CFG-scale tokens、4 个 model-mode tokens。附录显示,相比 adaLN-Zero,这个设计让 ELF-B 参数从 148M 降到 105M,且表现略好。
推理机制:ODE 是基线,SDE 是 few-step 关键
ELF 推理支持 ODE 和 SDE-inspired sampler。ODE 很直接:从 $z_0$ 出发,按时间离散点用 Euler 之类的方法解:
\[\frac{dz_t}{dt}=v_\theta(z_t,t)\]SDE-inspired sampler 则在每一步重新注入一小段 Gaussian noise,并把时间变量向 noise regime 做相应移动。论文说它是对 Flow Matching 相关 SDE 动态的简化近似。工程上可以把它理解成:few-step 时 deterministic ODE 误差太大,适度 stochasticity 可以减少错误积累。
这个设计在实验里很重要。默认 ablation 里,SDE 在 few-step regime 明显优于 ODE。系统级 OWT 比较使用 SDE sampling、time schedule、self-conditioning CFG scale 3:
| Sampling steps | SC CFG | SDE $\gamma$ | Gen. PPL ↓ | Entropy ↑ |
|---|---|---|---|---|
| 8 | 3 | 2.0 | $67.32 \pm 2.25$ | $5.14 \pm 0.085$ |
| 16 | 3 | 2.0 | $33.66 \pm 1.09$ | $5.16 \pm 0.026$ |
| 32 | 3 | 1.5 | $24.08 \pm 0.16$ | $5.15 \pm 0.002$ |
这里的重点不是 32 steps 绝对多快,而是相比此前 DLM baseline,ELF 在更少 sampling steps 下把 Gen. PPL 拉到了更低区间,而且没有额外蒸馏。
条件生成:把 source prefix 保持 clean
ELF 扩展到 conditional generation 的方式也很自然。对于翻译、摘要这类 seq2seq 任务,模型把 source sequence 的 clean embeddings 放在 control tokens 后、target sequence 前,并在训练和推理中保持 source prefix 不被 corruption。目标区间仍然从 noise denoise 到 clean embeddings。
条件 CFG 通过两种 condition 工作:
- self-conditioning prediction;
- source prefix clean embeddings。
unconditional counterpart 则通过 zeroing condition 得到。论文最终在 WMT14 De-En 和 XSum 上使用 64-step ODE sampler,self-conditioning CFG scale 1,input-condition CFG scale 2。附录还显示,conditional CFG scale 从 1 增到 2 会明显提升翻译和摘要指标,但继续增大会开始退化。
这说明 ELF 的 conditional generation 更像 text-to-text diffusion:source prefix 不是 prompt string 被 autoregressive attention 逐 token 读取,而是 continuous embedding condition 被放进同一个 bidirectional self-attention 序列里。
实验设置:指标要读准
ELF 的实验分三块:OWT unconditional generation、WMT14 De-En translation、XSum summarization。
OpenWebText
训练数据是 OpenWebText,约 9B tokens,sequence length 1024,packed sequence。评估时生成 1,000 个样本,报告:
| 指标 | 含义 | 注意点 |
|---|---|---|
| Gen. PPL | 生成样本在 pretrained GPT-2 Large 下的 perplexity | 这是外部语言模型代理指标,不是 ELF 自身 likelihood |
| unigram entropy | 生成文本 unigram entropy | 粗略衡量 diversity,不能替代 human eval |
论文明确没有使用 validation perplexity,因为 flow-based language model 做 likelihood evaluation 可能需要额外 likelihood-specific training。这一点很重要:Gen. PPL 低不等于模型真实 likelihood 高,而是“生成文本被 GPT-2 Large 看起来更像自然文本”。
WMT14 De-En
sequence length 128,其中 condition length 64,target length 64;训练目标 token 约 144M;指标是 BLEU。
XSum
sequence length 1088,其中 condition length 1024,target length 64;训练目标 token 约 6M;指标是 ROUGE-1/2/L。
训练预算
ELF-B 默认用 Muon optimizer,learning rate 0.002,global batch size 512。OWT 训练 5 epochs,约 95K steps;WMT14 和 XSum 训练 100 epochs,分别约 880K 和 40K steps。OWT 上训练设备是 TPU v5p ×64,论文表里写每个 epoch 约 1.5 小时。
这不是轻量级个人 GPU 复现设置。你可以用官方 checkpoint 做 inference / eval sanity check,但从零训练 ELF-B 需要比较重的 TPU 资源。
主要结果:ELF 的强项在哪里
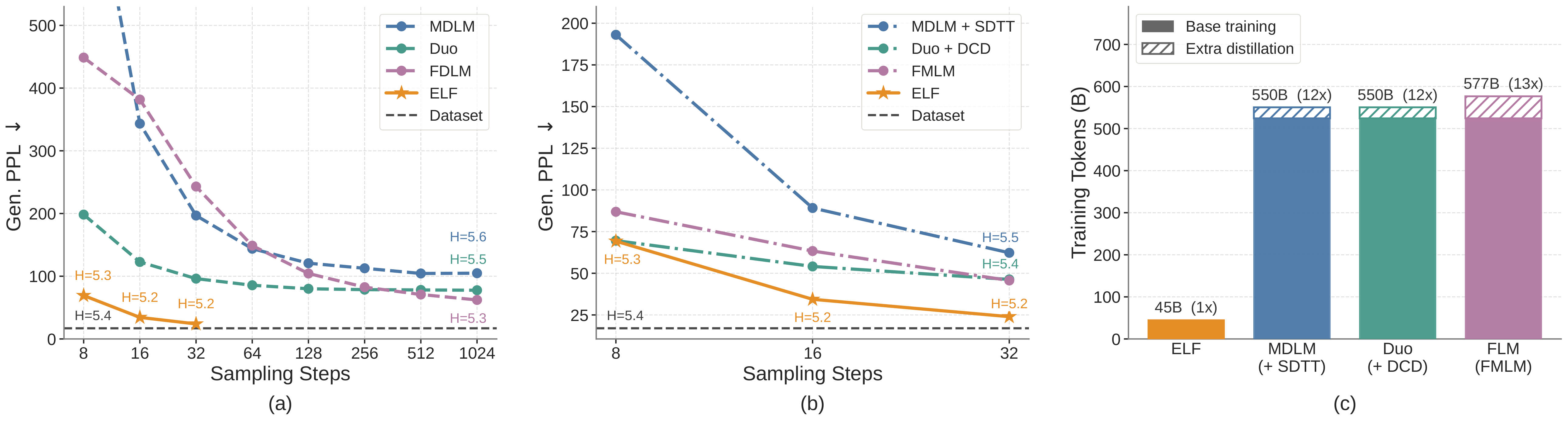
图:来自论文 TeX source 中 figures/system_level_comparison.pdf 的官方系统级对比。它比较了 ELF-B 与离散/连续 DLM baseline 的 OWT Gen. PPL、distilled variants,以及 estimated training tokens。
OWT 系统级比较里,ELF-B 是 105M 参数,而比较的 DLM baselines 大多约 170M。论文把 ELF-B 和 discrete DLMs,例如 MDLM、Duo,以及 continuous DLMs,例如 FLM、LangFlow 放在同一 OWT 设置下比较。结论是 ELF-B 使用 32-step SDE sampling 时达到约 24 的 Gen. PPL,并且推理步数少于 prior methods。
训练 token 预算是另一个关键点。OWT 约 9.04B tokens,ELF 默认 5 epochs,因此 effective training tokens 是 45.2B。论文图里其他 DLM 通常超过 500B tokens。作者因此强调 ELF 用了约一个数量级更少的训练 tokens。这个 claim 值得重视,但也要注意:training-token budget 是按各方法论文和额外 distillation / flow-map stages 估算的,跨论文比较总有 protocol 差异。
条件生成表更直接:
| Model | Size | WMT14 De-En BLEU ↑ | XSum R1 ↑ | XSum R2 ↑ | XSum R-L ↑ |
|---|---|---|---|---|---|
| AR | 99M | 25.2 | 30.5 | 10.2 | 24.4 |
| MDLM | 99M | 18.4 | 33.4 | 11.6 | 25.8 |
| Duo | 170M (+35M) | 21.3 | 31.4 | 10.1 | 25.0 |
| E2D2 | 99M | 24.8 | 28.4 | 8.3 | 22.0 |
| SeqDiffuSeq | - | 21.3 | 19.3 | 1.7 | 14.1 |
| CDCD | - | 24.9 | - | - | - |
| ELF-B | 105M (+35M) | 26.4 | 36.0 | 12.2 | 27.8 |
这里 ELF-B 同时超过了 AR baseline 和多个 diffusion baseline。XSum 的标准误很小,说明在样本层面指标比较稳定。不过表格也标注了结果来源差异:De-En 默认多为 prior work reported,XSum 默认多为 reproduced public code。也就是说,这张表有说服力,但仍然不是完全同一代码库、同一训练预算、同一 tuning protocol 下的闭环 benchmark。
Ablation:哪些设计是真正撑住结果的
我认为 ELF 的 ablation 比主表更有价值,因为它解释了连续 DLM 为什么这次能工作。
1. CFG 是质量-多样性旋钮
提高 self-conditioning CFG scale 会降低 Gen. PPL,但同时降低 entropy。这和 image diffusion 很像:guidance 越强,样本更“像高概率文本”,但 diversity 下降。ELF 的连续 formulation 让这种 trade-off 比离散 DLM 更自然。
2. Contextual embeddings 比 token embeddings 更关键
pretrained T5 contextual embeddings 最好,scratch contextual encoder 次之,non-contextual embeddings 更弱,learnable embeddings 最差。这说明 continuous language flow 不是在裸 token embedding 表上随便加噪就能成功;需要一个已经整理过语义和上下文的 embedding manifold。
3. Shared-weight decoder 不只是简化工程
论文比较了 shared-weight denoiser-decoder 和 two-stage separate decoder。两者大体能达到类似 trade-off,但 shared-weight 方案在低 Gen. PPL 区域延伸更好,而且避免额外训练阶段。我的理解是,这让 denoising output 的语义和 final readout 的语义更一致,减少了“denoiser 觉得 clean、decoder 不认”的 mismatch。
4. SDE sampler 支撑 few-step 质量
在相同 sampling steps 下,SDE-inspired sampler 明显降低 Gen. PPL。对 diffusion language model 来说,这一点尤其实际:如果 few-step 质量差,DLM 相比 AR 的并行生成优势就很难兑现。
5. Scaling frontier 是正向的,但不完全单调看单点
论文比较 ELF-B 105M、ELF-M 342M、ELF-L 652M。总体上更大模型给出更好的 Gen. PPL / entropy frontier:在 matched entropy 下 PPL 更低,或者在 matched PPL 下 entropy 更高。64-step SDE 的表里,ELF-B 在 SC CFG 3 下 Gen. PPL 19.72、entropy 5.10;ELF-L 在 CFG 4 下 Gen. PPL 21.37、entropy 5.26。单点数字不一定永远是大模型 PPL 更低,因为 CFG scale 影响 diversity;真正要看的是 frontier。
6. Muon 有帮助,但不是唯一原因
附录比较 Muon 和 AdamW,Muon 在相同训练步数下 loss 和 Gen. PPL / entropy trade-off 更好。但这不是把结果全部归因于 optimizer 的证据,因为 representation、$x$-prediction、shared decoder、CFG、SDE sampler 都有独立 ablation 支持。
定性样例:流畅,但不是没有语义风险

图:来自论文 TeX source 中 figures/qualitative_generation_examples.pdf 的官方样例。它展示了 OWT unconditional sample、WMT14 De-En translation 和 XSum summarization。
定性样例能说明 ELF 的语言确实比较流畅,尤其 OWT 长文本看起来不像传统 early diffusion text model 那种碎片化输出。翻译和摘要也能跟随 source context。
但我不建议只看图就得出“语义完全可靠”的结论。自动指标能覆盖 corpus-level overlap 或外部 LM fluency,但对于 factual correctness、细粒度数字、实体保持、长程一致性,它们仍然有限。图中的 summarization / translation 样例本身也提醒我们:扩散式 refinement 生成的是一个整体句子,不是逐 token left-to-right 地条件化事实;当 embedding trajectory 最后被一次性 decode 成 token 时,局部语义偏差可能不会像 AR decoding 那样逐步暴露。
这不是 ELF 的硬伤,而是当前评估还不够覆盖真实 LLM 使用场景。把它看成一个强 diffusion-language-model research prototype 更合理。
官方代码怎么用:先 eval,不要从零训练起步
官方仓库是 lillian039/ELF。README 写明主分支是 JAX 实现,代码在 TPU 上测试;PyTorch version 在 pytorch_elf branch。官方 checkpoints 和预处理数据都在 Hugging Face embedded-language-flows 下,eval.py 可以直接用 HF repo id 作为 --checkpoint_path,不需要手动下载 checkpoint。
最实用的入门方式是先跑 evaluation sanity check。
OWT unconditional ELF-B:
cd src/
python eval.py \
--config configs/training_configs/train_owt_ELF-B.yml \
--checkpoint_path embedded-language-flows/ELF-B-owt
XSum:
cd src/
python eval.py \
--config configs/training_configs/train_xsum_ELF-B.yml \
--checkpoint_path embedded-language-flows/ELF-B-xsum
WMT14 De-En:
cd src/
python eval.py \
--config configs/training_configs/train_de-en_ELF-B.yml \
--checkpoint_path embedded-language-flows/ELF-B-de-en
README 里给的 sanity check 是 validation set:De-En validation BLEU 约 26.7,XSum validation ROUGE-1/2/L 约 36.3 / 12.5 / 28.1。论文表里的 26.4 和 36.0 / 12.2 / 27.8 是 test set 数字。复现时不要把这两组数混在一起。
自定义数据也有明确格式:unconditional generation 每条样本需要 input_ids;conditional generation 需要 condition_input_ids 和 input_ids。官方建议先用 T5 tokenizer 预处理成 Hugging Face Dataset / Arrow,再在 config 里指向 data_path。
我会怎么评价这篇论文
学术价值
ELF 的主要贡献是重新打开 continuous DLM 这条路线。过去很多结果容易让人觉得文本 diffusion 必须离散化;ELF 证明,在好的 contextual embedding space 中做 continuous Flow Matching,再把 token readout 训练成 final-step decode objective,是一个有竞争力的选择。
它还把 image diffusion 的一些成熟工具带进 language modeling:training-time CFG、self-conditioning CFG、SDE sampler、logit-normal time schedule、in-context control tokens。这些不是表面技巧,而是因为模型状态本身是连续 embedding,所以可以比较自然地复用。
工程价值
工程上 ELF 的接口很清楚:T5-tokenized data -> frozen T5 encoder embeddings -> DiT-like Transformer -> shared decode -> token logits。官方已经提供 JAX code、HF checkpoints、tokenized data 和 eval scripts,入门复核门槛不高。
但从零训练门槛仍然高。论文默认 OWT 训练是 TPU v5p ×64,每 epoch 约 1.5 小时;这不是普通单机 GPU 项目。更现实的工程使用是基于 checkpoints 做 evaluation、采样策略研究、conditional CFG tuning、custom dataset adaptation 或 PyTorch branch 迁移。
方法边界
ELF 目前主要证明的是“diffusion language generation 在 OWT/WMT14/XSum 上可以很强”。它还没有证明:
- 能在 billion-scale 或更大 LLM 级别继续稳定 scaling;
- 能替代 autoregressive decoding 做开放域问答、tool use、multi-turn instruction following;
- 能在 factuality、数学推理、长上下文一致性上达到强 AR LLM;
- final-step argmax decode 是否是最优离散化策略;
- 对 T5 encoder representation 的依赖在其他 tokenizer / multilingual / code domain 中是否稳定。
这些边界不削弱论文价值,反而说明后续研究空间很明确。
可能的后续研究方向
1. 更强 encoder 或 joint encoder
T5-small contextual embeddings 已经有效,但它不是为 diffusion trajectory 专门训练的。一个自然方向是研究 encoder representation 和 flow objective 的共同设计:比如 frozen T5 vs encoder co-training vs contrastive / denoising pretraining 的 embedding manifold 差异。
2. 更好的 final discretization
ELF 现在最后一步用 unembedding matrix 和 argmax。可以研究 beam-like decode、temperature sampling、iterative final refinement、token confidence correction,或者把 final decode 变成一个小型 consistency correction stage。
3. 语义保真评估
Gen. PPL 和 ROUGE/BLEU 不足以评估 language diffusion。后续应该加入 factual consistency、entity preservation、numeric accuracy、long-range coherence、instruction following 等指标,尤其是摘要和翻译之外的开放任务。
4. Few-step / one-step distillation
ELF 已经在 32-step SDE 下很强,但和 AR 的单 pass 体验相比仍有 NFE 成本。它和 MeanFlow、Shortcut Models、Consistency Models 这类 one/few-step generative modeling 技术可能很适合结合。
5. 多模态语言接口
连续 embedding flow 和图像/视频 diffusion 的数学接口更接近。一个有意思方向是把 ELF 的 text embedding trajectory 和 multimodal diffusion backbone 对齐,让文本不是离散 prompt token,而是可流动、可 refinement 的 semantic condition。
总结
ELF 的核心思想可以用一句话概括:语言最终必须离散化,但生成过程不一定要离散化。
它把 token 序列映射到 T5 contextual embedding space,在连续空间里用 Flow Matching 从 Gaussian noise denoise 到 clean embeddings,再在最后一步通过共享权重 decode mode 读回 token。这个设计让 CFG、SDE sampler、self-conditioning 等 image diffusion 里的成熟技巧可以迁移到 language generation,并在 OWT、WMT14 De-En、XSum 上给出了强结果。
我最看重的是它的系统完整性。很多论文只提出一个 continuous text diffusion idea,却在 representation、decoder、sampler 或评估某一环留下缺口。ELF 把这些环都补上了:representation 用 pretrained contextual encoder,目标用 $x$-prediction,decode 用 shared weights,guidance 用 training-time CFG,few-step 用 SDE sampling,复现用 HF checkpoint 和 official eval script。
但它还不是“非自回归 LLM 的终局答案”。它更像是一个强信号:continuous embedding space 可能是 diffusion language model 的正确战场;真正的问题从“文本能不能 diffusion”转成了“什么 embedding manifold、什么 final decoder、什么 sampler 和什么评估协议,能把 diffusion 的并行生成优势转化成真实语言能力”。
Recommended citation: Hu et al., ELF: Embedded Language Flows, arXiv:2605.10938, 2026.
Download Paper