
PC-Talk:用隐式关键点做可精细控制的 talking face
PC-Talk:用隐式关键点做可精细控制的 talking face
论文:PC-Talk: Precise Facial Animation Control for Audio-Driven Talking Face Generation 作者:Baiqin Wang, Xiangyu Zhu, Fan Shen, Hao Xu, Zhen Lei 时间 / 版本:2025-03-18 arXiv v1;2026-06-04 arXiv v3 会议:CVPR 2026, pp. 25153-25162 链接:Paper / PDF / CVF OpenAccess / Project / Supplement 检索日期:2026-06-15
开篇点评:这篇论文到底解决了什么问题
PC-Talk 的目标不是再做一个“嘴能对上音频”的 talking head,而是把 audio-driven talking face 里的控制问题拆开:嘴部如何以不同说话习惯对齐音频,以及 表情如何以可调强度、可分区域的方式叠加到同一张脸上。
很多 talking face 方法在 lip-sync 上已经足够强,但生成结果常常只有一种平均化运动方式:同一个音素对应差不多的嘴形,同一种 emotion label 对应差不多的表情。PC-Talk 认为这不够。真实视频里,同样说 “duck”“too”“bee”,不同人嘴张开的程度、嘴唇外撅、嘴角宽度都会不同;真实情绪也不是一个单标签,可能是“嘴在笑、眉眼在难过”的复合状态。

图:论文 Figure 1。PC-Talk 把控制拆成 Lip-Audio Alignment Control 和 Emotion Control:前者处理 speaking style、lip movement scale 和 articulation-level editing,后者处理 emotion type、intensity 和 region-specific compound emotion。
我的判断是,这篇论文最值得看的是“控制接口”而不是单个指标。它没有直接在 pixel 上硬做编辑,而是把控制落到 implicit keypoint deformation 上:先从参考图像得到原始隐式关键点 $K_{ori}$,再预测 lip-sync deformation $D_l$ 和 emotional deformation $D_e$,最后把它们加到关键点上交给 renderer。这种结构让控制信号有明确落点,也让 LAC 和 EMC 可以相对独立地训练和组合。
Paper Card
| 项目 | 信息 |
|---|---|
| Paper | PC-Talk: Precise Facial Animation Control for Audio-Driven Talking Face Generation |
| Authors | Baiqin Wang, Xiangyu Zhu, Fan Shen, Hao Xu, Zhen Lei |
| Venue | CVPR 2026, pp. 25153-25162 |
| Category | audio-driven talking face, controllable facial animation, implicit keypoint deformation |
| Core modules | Lip-Audio Alignment Control (LAC), EMotion Control (EMC) |
| Representation | implicit keypoints, lip-sync deformation $D_l$, emotional deformation $D_e$ |
| Project / Code | Project page;页面显示 Code Coming Soon |
| Supplement | CVF OpenAccess 提供 supplemental zip,包含 PDF 和 demo videos |
| 复现状态 | 论文、项目页、supplement 已公开;正式代码截至 2026-06-15 未公开,训练细节只能读到方法级和部分补充说明 |
Abstract:论文摘要解读
摘要把问题定义得很直接:audio-driven talking face 在 lip synchronization 上进步明显,但缺少对 facial animation 的精细控制,尤其是 speaking style 和 emotional expression。PC-Talk 关注两个控制方向。
第一是 lip-audio alignment control。它不只是让嘴和音频同步,还要让同步发生在不同 speaking style 下:可以从参考视频中适配一个说话习惯,也可以选择预设风格;可以调整 lip movement scale 来模拟音量变化;还可以对某些 articulation 做更细的编辑,例如 lip pursing、mouth widening、mouth openness。
第二是 emotion control。它不只是输入一个 emotion label,而是希望支持 intensity control、不同情绪源、以及不同 facial region 的 compound emotion。比如嘴角可以是 happy,眉眼可以是 sad,这比单一 emotion label 更接近真实表达。
方法上,PC-Talk 的共同底座是 implicit keypoint deformation。LAC 估计嘴部/说话风格相关的 $D_l$,EMC 估计情绪相关的 $D_e$,两者一起驱动渲染器生成最终 talking face。论文声称该方法在 HDTF 和 MEAD 上达到 SOTA,并展示了较强控制能力。
Motivation
talking face 的可控性有两个层面容易被忽略。
第一个层面是 speech-to-lip 不是唯一映射。音频只决定“说了什么”,但不完全决定“怎么说”。同一个音素可以有不同嘴形幅度和习惯:有人张嘴更大,有人嘴唇更紧,有人嘴角更宽。只用 audio 直接回归运动,模型很容易学成平均嘴形。
第二个层面是 emotion 也不是单标签。很多方法把情绪当作 happy、sad、angry 这类类别输入,但现实里的表情常是混合的、局部的、强度连续的。一个人可以嘴在笑、眼睛却表达伤心;也可以只是轻微生气,而不是固定强度的 angry face。
PC-Talk 的 motivation 是把这两个控制问题都落在 motion space,而不是交给后端 renderer 盲修。它选择 implicit keypoints 做中间表示,理由是这种表示兼顾视觉质量和效率,并且部分关键点能通过 landmark constraint 具有嘴、眉眼等语义区域含义。补充材料也强调,这种两阶段思路并不局限于当前 renderer,理论上可以替换成 landmarks、3DMM 或更强的 diffusion generator,只是效率和控制精度会变。
直观效果:先看它能控制什么
PC-Talk 的定性图覆盖了两类效果:左侧是 lip-audio alignment 与 mouth shape,右侧是 emotion generation。

图:论文 Figure 3。左侧比较 lip shape 和 video/image input 的 talking face 质量;右侧比较 emotional talking face。论文用彩色框标出其他方法的 blurry teeth、错误 lip shape 和情绪表达错误。
这张图的重点是:PC-Talk 不是只做表情,也不是只做嘴形。左侧说明它在 lip shape GT 附近更稳定;右侧说明它在 sad、surprised、angry、happy 等 emotional cases 里能保持比较清晰的表情差异。
但定性图仍有局限。它是论文选择的样例,不能单独证明跨域稳定性。真正支撑主张的是:主表在 HDTF / MEAD-Neutral 上比较 lip-sync、FID、NIQE、FVD,情绪表在 HDTF / MEAD 上比较 Acc_emo 和 E-FID,supplement 又补了 VoxCeleb2 和 LRW。尽管如此,style control 本身仍缺少一个特别直接的自动指标,很多结论还依赖可视化和用户研究。
方法总览:把控制落在隐式关键点变形上
PC-Talk 的框架可以写成一个非常清楚的加法结构。
先从参考图像 $I_{ref}$ 里提取原始隐式关键点 $K_{ori}$。motion extractor 包含 pose estimator、expression estimator 和 canonical keypoint detector。论文写成:
\[K_{ori}=s\cdot(K_c\cdot R+\delta)+t\]其中 $R$、$t$、$s$ 是 pose/transform/scale,$\delta$ 是 expression deformation,$K_c$ 是 canonical keypoints。
然后 LAC 产生 lip-sync deformation $D_l$,EMC 产生 emotional deformation $D_e$。二者加到原始关键点上:
\[K_d=K_{ori}+D_l+D_e\]最后用 warping module 和 decoder 渲染:
\[I_{res}=\operatorname{Decoder}(\operatorname{Warp}(f_a,K_{ori},K_d))\]这里 $f_a$ 是 identity encoder 从参考图像提取的 appearance feature。
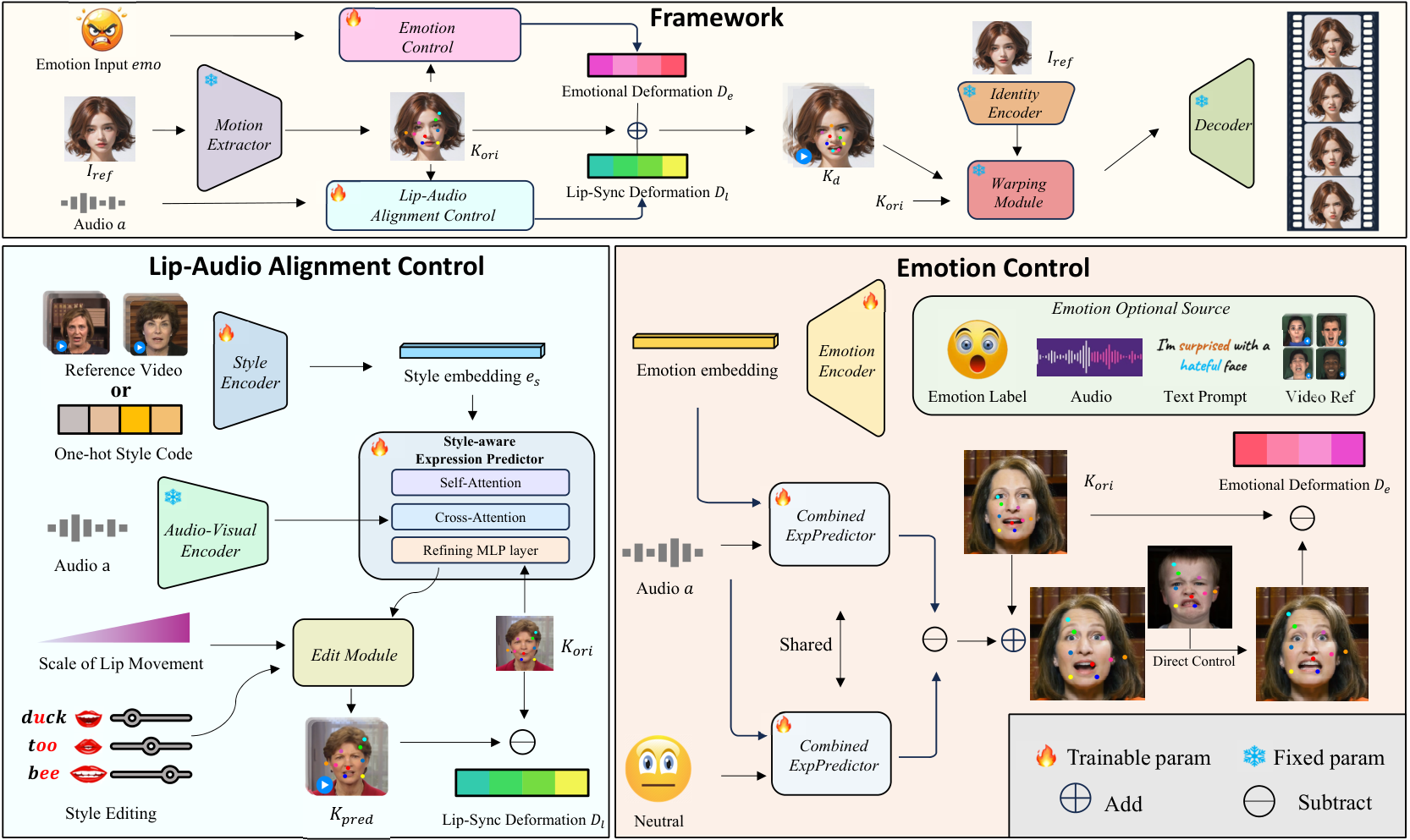
图:论文 Figure 2。上方是总体框架:motion extractor 得到 $K_{ori}$,LAC 输出 $D_l$,EMC 输出 $D_e$,两者合成 $K_d$ 后进入 warping/decoder。下方展开 LAC 和 EMC 的控制路径。
这个设计的好处是接口清晰。LAC 不需要直接生成图像,只需要回答“嘴部和说话习惯如何移动关键点”;EMC 也不需要重做 lip-sync,只需要回答“在保持同步的基础上怎样增加情绪变形”。renderer 负责把关键点驱动成图像。
数据全流程:输入、表示、shape 和语义
论文没有给出所有 tensor shape,但数据对象和语义边界比较明确。
| 阶段 | 对象 | Shape / Dim | 语义 | 产生者 | 消费者 |
|---|---|---|---|---|---|
| Reference image | $I_{ref}$ | 512 x 512 output setting;输入尺寸 not fully specified | identity / appearance source | user input | motion extractor, identity encoder |
| Audio | $a$ | 16 kHz audio after preprocessing | speech content | user input / dataset | audio-visual encoder |
| Original keypoints | $K_{ori}$ | number/dim not specified | source identity under current pose/expression | motion extractor | LAC, EMC, renderer |
| Audio embedding | $e_a$ | not specified | audio-lip aligned feature | audio-visual encoder pretrained on 2D AV sync | style-aware expression predictor |
| Style embedding | $e_s$ | not specified | speaking style from video reference or preset one-hot style | style encoder / one-hot projector | LAC expression predictor |
| Lip-sync deformation | $D_l$ | same keypoint deformation space | mouth/speaking-style motion | LAC | keypoint composition |
| Emotional deformation | $D_e$ | same keypoint deformation space | pure emotional expression | EMC | keypoint composition |
| Driven keypoints | $K_d$ | same as $K_{ori}$ | final controlled motion target | $K_{ori}+D_l+D_e$ | warping module |
| Appearance feature | $f_a$ | not specified | identity/texture appearance | identity encoder | warping + decoder |
| Output frame/video | $I_{res}$ | 512 x 512 | final talking face | decoder | evaluation / demo |
训练和推理边界也要分清楚:motion extractor、identity encoder、warping module 和 decoder 初始化自 LivePortrait 并保持冻结;PC-Talk 主要训练 LAC 和 EMC 这些控制模块。换句话说,它更像一个可控 motion/deformation controller,而不是从零训练完整 talking-head generator。
LAC:说话风格、嘴部幅度和 articulation editing
LAC 的目标是:在保持 lip-sync 的同时允许用户控制 speaking style。
Style-aware expression predictor 采用 auto-regressive Transformer Decoder。它包含 self-attention,用于捕捉时间一致性;包含 cross-attention,用于和 audio embedding $e_a$ 交互;最后通过 MLP refine 输出。论文强调,final MLP 直接在 implicit keypoints 上调输出,而不是只在 expression deformation 上操作,这样可以缓解隐式表示中的 residual entanglement。
Style source 有两种:reference video 或 preset one-hot code。reference video 会先提取 expression deformations,再通过 Transformer Encoder 编到 style embedding;one-hot preset style 会通过 MLP 投影到同一个 style space。训练时随机在两类输入之间切换,使推理时既能“上传参考视频模仿风格”,也能“没有参考时选择预设风格”。
LAC 还有两个更细的控制。
第一是 lip movement scale。方法把 $D_l$ 乘上一个 scaling factor $f$,用来模拟不同音量或嘴部运动幅度。这个控制很直接,也有风险:scale 太大或太小都会损害同步。
第二是 speaking style editing。作者先构造特定 articulation 的 implicit keypoint deformation vectors,例如 lip pursing、mouth widening、mouth openness,再把 $D_l$ 投影到目标 articulation vector 上,通过 scale 调整局部嘴形。
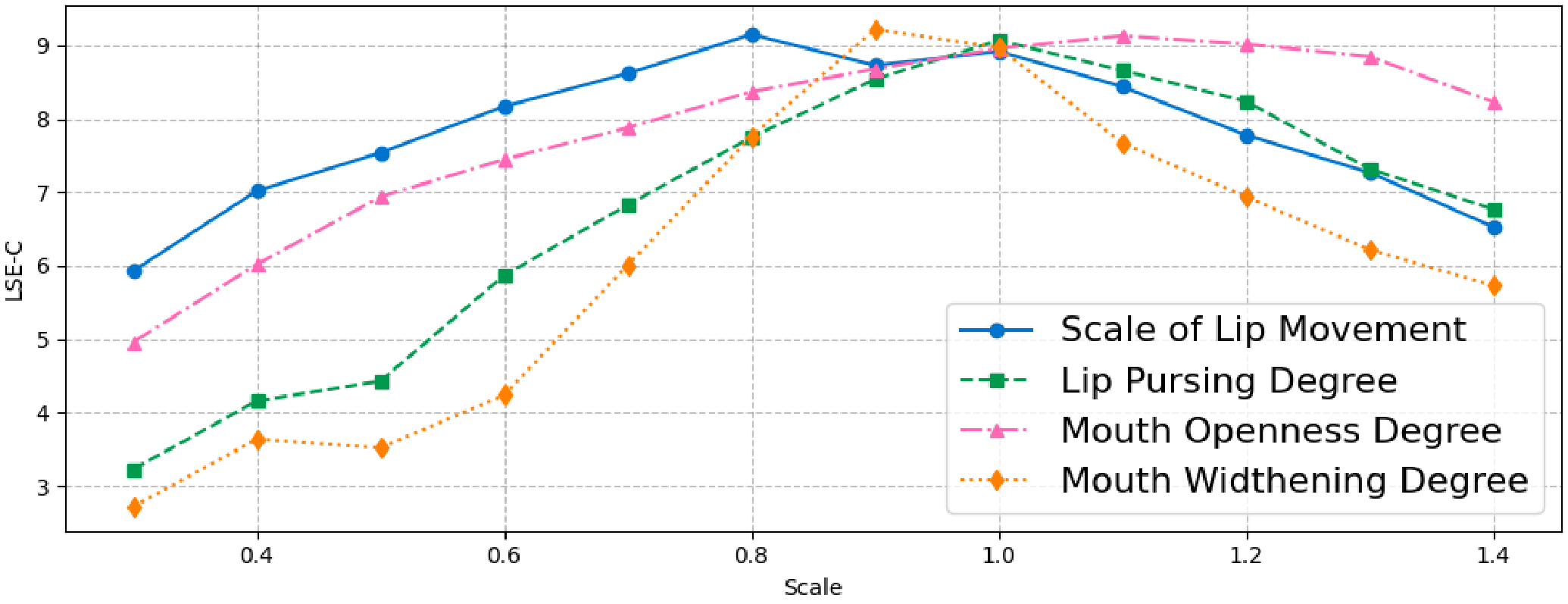
图:论文 Figure 5。lip movement scale 的最佳 LSE-C 约在 0.8 附近;style editing 在 0.8 到 1.2 区间较稳定,超出范围后 lip-sync 明显变差。mouth openness 对 scale 更不敏感,lip pursing 和 mouth widening 更敏感。
这张图说明一个很实际的问题:可控并不等于可以任意调。PC-Talk 给了 articulation-level editing 的接口,但控制范围仍受 lip-sync 约束,过度编辑会破坏音画一致性。
EMC:把情绪从 lip-sync 里拆出来
EMC 的核心是 pure emotional deformation decomposition。论文认为,emotional talking face 里的 lip region 同时包含 lip-sync deformation 和 emotion deformation,这两者纠缠在一起。如果直接预测 emotional face deformation,嘴部同步容易被情绪干扰。
PC-Talk 用同一个 audio 输入分别预测 emotional expression 和 neutral expression,然后相减:
\[D_e=\operatorname{CPred}(emo,e_a)-\operatorname{CPred}(\text{neutral},e_a)\]因为两边使用同一段 audio,lip-sync 部分理论上可以抵消,剩下的是更“纯”的 emotion deformation。之后 $D_e$ 与 LAC 的 $D_l$ 相加,形成最终关键点。
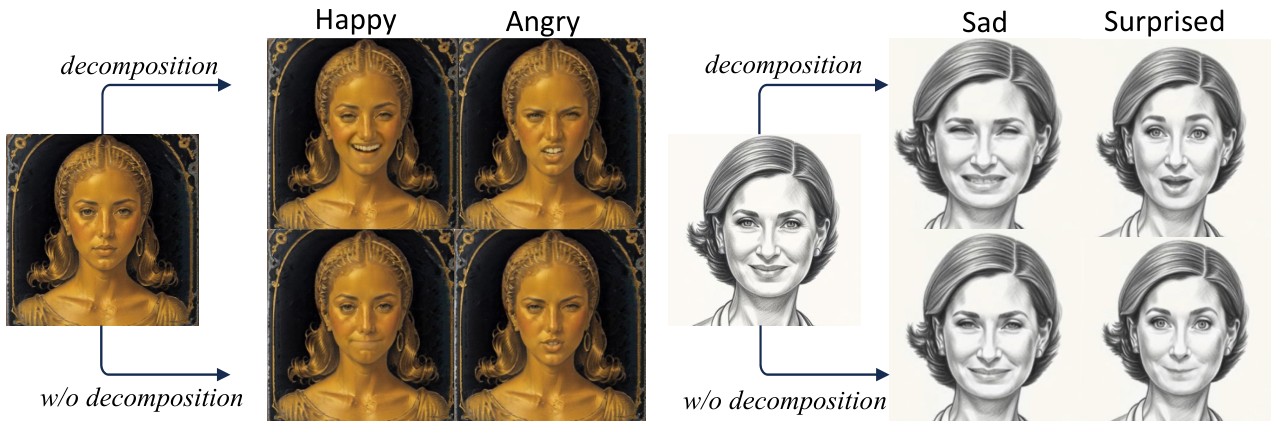
图:论文 Figure 4。decomposition 能生成更自然的 emotional faces;不做 decomposition 时,嘴部和表情容易纠缠,例如口型异常闭合或情绪表达不自然。
EMC 的情绪源也比较多。直接控制可以来自 image/video reference;复杂控制可以来自 audio intonation 或 text semantics。补充材料写到 audio emotion embedding 使用 Wav2Vec,text emotion embedding 使用 Emoberta。对于 compound emotion,方法利用 implicit keypoints 与 facial landmarks 的区域语义关系,在不同 facial region 分别生成情绪,再组合。

图:论文 Figure 6。上方是 sad 到 happy 的 emotion interpolation,下方是两个 speaking styles 之间的 interpolation。它支持论文关于连续控制空间的 claim,但仍属于定性证据。
Training:监督信号和训练策略
LAC 的 loss 在主文和补充材料中写得最完整:
\[\mathcal{L}_{LAC}= \mathcal{L}_{sync} +\lambda_{kp}\mathcal{L}_{kp} +\lambda_{reg}\mathcal{L}_{reg} +\lambda_{vel}\mathcal{L}_{vel} +\lambda_{style}\mathcal{L}_{style}\]$\mathcal{L}_{sync}$ 借鉴 Wav2Lip,用 image sequence 和 audio input 的 embedding cosine similarity 约束同步。论文写成:
\[\mathcal{L}_{sync}= -\frac{ S_v(I_{gt:gt+4})^T\cdot S_a(a_{gt:gt+4}) }{ \|S_v(I_{gt:gt+4})\|_2\|S_a(a_{gt:gt+4})\|_2 }\]$\mathcal{L}{kp}$ 是 keypoint L1 loss,$\mathcal{L}{reg}$ 约束过大的 deformation,$\mathcal{L}{vel}$ 约束 temporal consistency,$\mathcal{L}{style}$ 用预训练 style classifier 监督生成风格类别。
EMC 的 loss 描述有一点需要谨慎。主文写 EMC 使用 $\mathcal{L}{kp}$、$\mathcal{L}{reg}$ 和 $\mathcal{L}_{vel}$;补充材料又补充了 emotion embedding 的 classifier loss:
\[\mathcal{L}_{cls}=-\sum_{c=1}^{M}y_c\log p_c\]论文没有给出所有 loss 权重、网络层数、关键点数量等完整可复现配置。这里不能把它当成代码级复现说明。
训练策略方面,主文写 LAC 和 EMC 分开训练,Adam,learning rate $1e-4$,使用一张 RTX 4090,LAC 训练两天,EMC 训练一天。补充材料把 LAC 拆得更细:style-aware expression predictor 先以 window size 50 在 implicit keypoints 上训练 24 小时;加入 final MLP 后为了计算 image-space $\mathcal{L}_{sync}$,window size 降到 5,并继续训练 72 小时。
另外,补充材料说明使用同一框架做 unsupervised video-driven portrait animation 进行数据增强:HDTF 作为 driving video/audio,使用 SyncNet 过滤 lip-sync 质量。推理时还对 implicit keypoint deformation 使用 Kalman filter 来降低不稳定性。
数据与评测设置
PC-Talk 主要在 HDTF 和 MEAD 上评测。HDTF 包含 16 小时高分辨率视频、300+ subjects;MEAD 包含 40+ identities 和 8 种 emotion types。LAC 用 HDTF 和 MEAD neutral clips 训练;EMC 用 MEAD emotional content 训练。训练集和测试集无重叠,测试使用 10 秒 audio clips 做 cross-identity inference。
预处理方面,视频转成 25 fps,音频采样到 16 kHz。输出分辨率为 512 x 512。论文报告整体框架可达约 30 FPS,supplement 中具体效率表为:SadTalker 10.76 FPS,EchoMimic 0.84 FPS,Hallo-v2 0.69 FPS,Ours without control 34.75 FPS,Ours 30.13 FPS。
评价指标分三类:
| 类别 | 指标 | 含义 |
|---|---|---|
| Lip sync | LSE-C higher, LSE-D lower | SyncNet based synchronization |
| Image quality | FID lower, NIQE lower | 全参考和无参考视觉质量 |
| Temporal consistency | FVD lower | 视频时序分布质量 |
| Emotion | Acc_emo higher, E-FID lower | emotion classification accuracy / expression-distance |
这里要注意两个 metric caveat。第一,LSE 系列与训练中的 sync loss 都和 SyncNet 风格的 audio-visual embedding 有关,可能对同类优化目标更友好。第二,Acc_emo 取决于 emotion classifier,能证明“分类器认为情绪更明显”,但不等价于人类对真实复杂情绪的完整判断。
实验与证据:哪些 claim 被支持
在 lip-audio alignment 主表中,PC-Talk 在视频输入和图像输入两组都很强。
| Setting | Dataset | 代表结果 |
|---|---|---|
| Video input | HDTF | Ours LSE-C 9.03, LSE-D 6.69, FID 15.51, NIQE 13.49, FVD 100.85,均为表中最佳 |
| Video input | MEAD-Neutral | Ours LSE-C 8.29, FID 24.88, NIQE 12.04, FVD 170.56 最佳;LSE-D 不是最佳 |
| Image input | HDTF | Ours LSE-C 9.37, LSE-D 6.44, NIQE 13.29, FVD 205.55 最佳;FID 33.07 不如 EchoMimic 28.13 |
| Image input | MEAD-Neutral | Ours LSE-C 8.19, LSE-D 7.69, FID 35.22, NIQE 12.48, FVD 153.81 均为表中最佳 |
在 emotion 表中,PC-Talk 对 EAMM、EAT、ED-Talk 全面占优。HDTF 上 Acc_emo 为 46.19;MEAD 上 Acc_emo 为 72.32,E-FID 为 1.88,都是表中最佳。
消融实验也比较关键。主文中的 LAC ablation:
| AV Encoder | $\mathcal{L}_{sync}$ | $\mathcal{L}_{kp}$ | LSE-C |
|---|---|---|---|
| no | no | no | 6.23 |
| yes | no | no | 7.17 |
| yes | yes | no | 8.92 |
| yes | yes | yes | 9.37 |
补充材料中的 LAC ablation:
| Lip-related keypoint | Final MLP layer | Data augmentation | LSE-C |
|---|---|---|---|
| no | no | no | 8.26 |
| yes | no | no | 8.47 |
| yes | yes | no | 9.26 |
| yes | yes | yes | 9.37 |
这些结果支持三个结论:audio-visual encoder 比通用 ASR/Whisper 风格特征更贴近 lip-sync;$\mathcal{L}_{sync}$ 提升明显;final MLP 和数据增强对最终同步质量有实质贡献。
supplement 还在 VoxCeleb2 和 LRW 上补充了泛化评测。PC-Talk 在 VoxCeleb2 上 LSE-C 7.74、FID 32.37、FVD 205.55;在 LRW 上 LSE-C 7.14、FID 24.83、FVD 163.70,整体优于 Wav2Lip、MuseTalk、SadTalker、Hallo-v2。这个结果支持跨数据集鲁棒性,但样本量是随机 50 clips,规模不大。
用户研究方面,论文使用 10 个生成片段、每段超过 5 秒,20+ participants,按 1 到 5 分评价 lip-sync accuracy、image quality、temporal consistency、emotional expressive 和 overall realistic。PC-Talk 在所有维度最高。这能补充自动指标不足,但样本量和问卷设计细节仍然有限。
复现与工程风险
这篇论文的最大复现风险很明确:代码还没有公开。项目页按钮显示 Code(Coming Soon),OpenAccess 提供的是论文 PDF、supplement PDF 和 demo videos。当前只能做方法级复现规划,不能做代码级核验。
工程依赖也比较多。PC-Talk 初始化了 LivePortrait 的 motion extractor、identity encoder、warping module 和 decoder,audio encoder 来自 Wav2Lip 风格的 audio-visual sync model。也就是说,控制模块的效果依赖底座关键点的语义质量。如果 implicit keypoints 在大姿态、遮挡、跨身份或非真人风格上不稳定,LAC/EMC 的控制也会受影响。
训练细节仍不完整。论文提供了学习率、训练时长、数据集、loss 类型,但没有完整代码、loss 权重、关键点数量、模型层数、数据过滤脚本、SyncNet 过滤阈值、style preset 构造细节。补充材料给了不少信息,但还不足以一键复现。
评测也需要谨慎读。PC-Talk 使用 SyncNet 相关的 $\mathcal{L}_{sync}$,再用 LSE-C/LSE-D 评价 lip-sync,指标和训练目标之间存在相近 inductive bias。emotion 的 Acc_emo 也依赖分类器。论文用用户研究补充了主观评价,但样本规模有限。
最后是伦理风险。补充材料明确提到高保真 talking face 与精细控制可能被滥用在隐私侵犯、冒名视频或误导性内容上。对于这类数字人技术,水印、授权、身份验证和使用场景边界不应该放到最后才考虑。
对我的启发
PC-Talk 给我的第一个启发是:如果目标是可控,不一定要把所有控制都塞进 prompt 或 latent。更稳的做法是找到一个“可被 renderer 消费、又有局部语义”的 motion representation。implicit keypoints 在这里承担了这个角色。
第二个启发是:控制模块可以拆开训练。LAC 关心嘴部同步和 speaking habit,EMC 关心纯情绪变形,两者在关键点空间相加。这个结构比单网络同时学所有控制更容易解释,也更容易暴露失败点。
第三个启发是:fine-grained control 必须有控制范围。Figure 5 说明 scale 和 articulation editing 太大都会伤 lip-sync。工程系统里应该给 slider 设置推荐区间,而不是把任意数值开放给用户。
总结
PC-Talk 是一篇很适合放在 digital human controllability 技术线里读的论文。它把 audio-driven talking face 从“输入音频生成视频”推进到“可控的 facial animation”:用户可以控制 speaking style、lip movement scale、局部 articulation、emotion type、emotion intensity 和 region-specific compound emotion。
它真正的结构价值在于隐式关键点加法:$K_d=K_{ori}+D_l+D_e$。LAC 和 EMC 都不直接碰最终像素,而是生成可解释的 deformation,再交给 frozen renderer。这让控制逻辑更模块化,也让实时性保持在 30 FPS 左右。
它的边界同样清楚:代码未公开,底座依赖 LivePortrait/Wav2Lip,训练细节仍缺,评测指标和训练目标之间存在一定重合。我的结论是:PC-Talk 在“可控接口设计”上很值得借鉴,但在正式代码发布前,还不能把它当成一个已经可工程复现的完整方案。
Recommended citation: Wang et al., PC-Talk: Precise Facial Animation Control for Audio-Driven Talking Face Generation, CVPR 2026.
Download Paper