
StyleTalk:从参考视频里抽取 speaking style 的 one-shot talking head
StyleTalk:从参考视频里抽取 speaking style 的 one-shot talking head
论文:StyleTalk: One-shot Talking Head Generation with Controllable Speaking Styles 作者:Yifeng Ma, Suzhen Wang, Zhipeng Hu, Changjie Fan, Tangjie Lv, Yu Ding, Zhidong Deng, Xin Yu 时间 / 版本:2023-01-03 arXiv v1;2023-06-10 arXiv v2 会议:AAAI 2023 Oral 链接:Paper / PDF / Code & Project / Demo 检索日期:2026-06-15
开篇点评:这篇论文到底解决了什么问题
StyleTalk 解决的不是普通 lip-sync,而是 同一段语音应该如何带着不同人的说话风格动起来。传统 one-shot talking head 方法通常把音频到嘴形、头部姿态、表情生成看成一个较确定的映射:输入一张人脸和一段语音,输出一个说话视频。这样能做同步,但容易把所有人都生成成某种“平均说话方式”。
真实说话不是这样。有人嘴形幅度大,有人眉眼动作明显,有人同样发一个音时嘴角、眼睑、眉毛和面部肌肉的节奏都不同。StyleTalk 的核心判断是:speaking style 不应该只用离散 emotion label 表示,也不应该逐帧复制另一个视频的表情,而应该被建模成 3DMM expression parameters 的时序动态模式。

图:论文 Figure 1。相同 identity reference 和 driving audio 可以结合不同 style reference video,生成不同 speaking style 的输出。这里的关键约束是:style reference 只提供风格动态,不提供 speech content。
我的判断是,这篇论文最有价值的地方有两个。第一,它把 talking head 里的 style 控制从“emotion 类别”推进到“参考视频中的时序运动模式”。第二,它没有直接在 pixel space 里硬做风格迁移,而是先预测 3DMM 表情参数,再交给 PIRenderer 渲染,这让风格、内容、身份之间的接口更清楚,也暴露出它的工程边界。
Paper Card
| 项目 | 信息 |
|---|---|
| Paper | StyleTalk: One-shot Talking Head Generation with Controllable Speaking Styles |
| Authors | Yifeng Ma, Suzhen Wang, Zhipeng Hu, Changjie Fan, Tangjie Lv, Yu Ding, Zhidong Deng, Xin Yu |
| Venue | AAAI 2023 Oral |
| Task | One-shot audio-driven talking head generation with controllable speaking styles |
| Inputs | target identity image $I^r$, driving audio $A$, style reference video $V$ |
| Output | talking video $\hat{I}_{1:T}$ with target identity, audio content, and reference speaking style |
| Core representation | 3DMM expression parameters $\delta \in R^{64}$, phoneme labels, style code $s$ |
| Code / Demo | GitHub / YouTube demo |
| 复现状态 | 官方代码、checkpoint 下载链接和 demo script 已公开;训练数据处理依赖 PIRenderer / AVCT / Deep3DFaceRecon 等外部链路 |
Abstract:论文摘要解读
摘要可以拆成一个问题和一个机制。
问题是:已有 one-shot talking head 方法在 lip-sync、自然表情和稳定头动上已经有进展,但它们没有很好地生成多样化 speaking style。这里的 style 不是简单的情绪标签,而是一个人在说话时面部动态的个性化模式。
机制是:给定任意 style reference video,StyleTalk 先从该视频的动态表情序列里抽取一个 style code;再把 driving audio 转为偏 articulation 的 phoneme feature;最后通过 style-controllable decoder 生成带风格的 3DMM expression parameters,并由 image renderer 合成目标人的 talking face。为了让 style code 真正影响解码过程,作者设计了 style-aware adaptive transformer:style code 不只是拼接到特征上,而是用来调节 transformer feed-forward layer 的权重。
这篇论文的核心 claim 是:仅用一张目标人像、一段任意驱动音频、一个任意风格参考视频,就能生成带参考说话风格的视频,同时保持较好的 lip-sync 和视觉真实感。实验在 MEAD 和 HDTF 上用量化指标、定性比较、消融和 style space 可视化支撑这个 claim。
Motivation
talking head 生成里的一个长期矛盾是:音频内容和面部风格并不是一一对应。相同发音可以有不同嘴形幅度、不同眉眼参与、不同表情节奏。只从 audio 预测表情,本身就是 one-to-many mapping。
早期或常见 one-shot 方法更关注 lip-sync、pose 和视觉质量。即使有 emotion-controllable talking head,也常把风格压成离散 emotion class。论文指出,这种表示很难覆盖真实场景中的个体差异:同一个 emotion 下,不同人说话的面部动态也可能差别很大。
另一类做法是引入 emotional source video,然后逐帧迁移表情。作者认为这会忽略 facial expression 的 temporal dynamics:一帧表情像不像并不等于整段说话节奏像不像。StyleTalk 因此把 speaking style 定义为 personalized dynamic facial motion patterns,并把参考视频先转换成 3DMM 表情参数序列,用 transformer 去建模时序相关性。
这个 motivation 是成立的。它抓住了 talking head 里经常被 lip-sync 指标掩盖的问题:嘴对上了不代表说话像真人,更不代表说话像参考风格。
直观效果:先看它能做什么
论文的定性比较给了两个例子:目标身份、style reference 和 audio 都未在训练中出现。对比方法包括 Wav2Lip、PC-AVS、AVCT、EAMM 和 GC-AVT。

图:论文 Figure 3。上方给出 speaker、style reference 和 audio/mouth GT,下方比较不同 one-shot 方法。论文强调 EAMM/GC-AVT 主要控制上半脸或表情迁移,StyleTalk 更关注全脸 speaking style 与 mouth style 的一致性。
这张图最值得看的不是单帧是否清晰,而是“style reference 的动作幅度有没有进入生成结果”。Wav2Lip 这类方法在嘴部同步上很强,但它基本不承担全脸风格控制;EAMM 和 GC-AVT 能做表情相关控制,但论文指出它们对 mouth shape style 和身份/背景保持仍有问题。StyleTalk 试图把 style 从参考视频的整段表情动态里提取出来,再用 3DMM 参数约束输出。
定性图当然不能单独证明方法可靠,尤其视频任务需要看连续运动。但它能说明论文的目标边界:不是做最高保真人脸渲染,也不是做任意人脸 reenactment,而是让 audio-driven talking face 多一个可控的 speaking style 条件。
方法总览:StyleTalk 的四个模块
StyleTalk 的 pipeline 比较清楚:style reference video 走 3DMM expression extraction,audio 走 phoneme encoder,两者进入 style-controllable dynamic decoder,最后由 PIRenderer 合成图像。
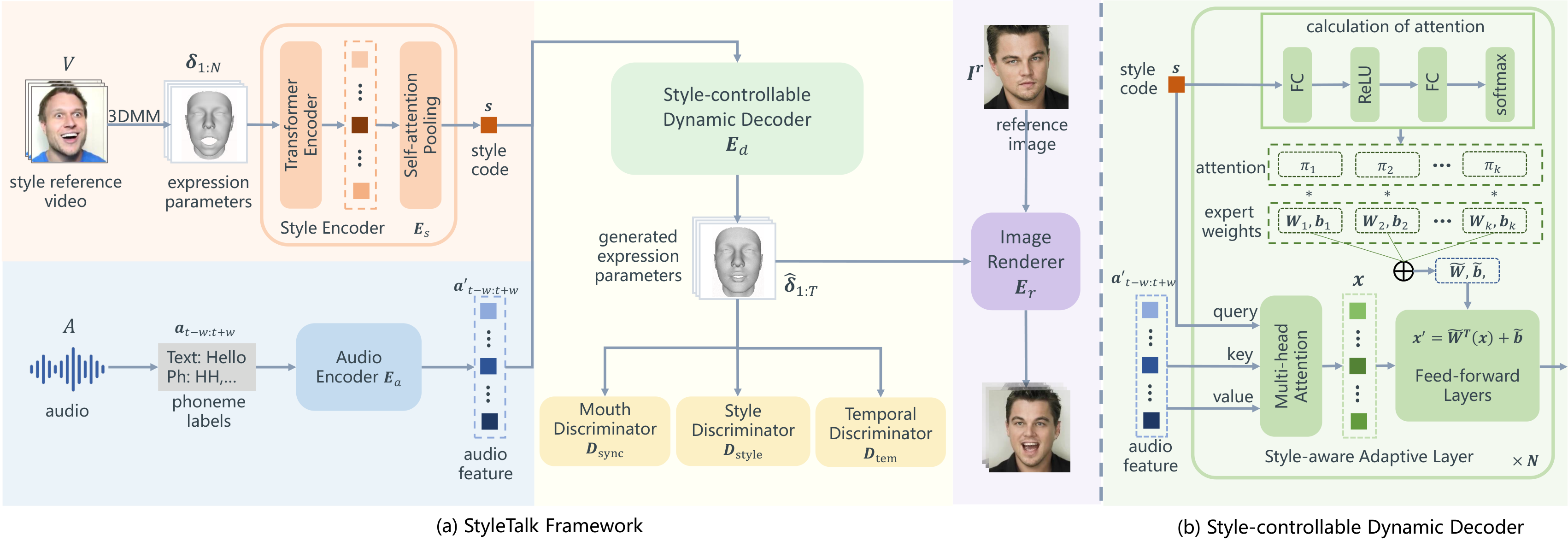
图:论文 Figure 2。左侧是完整 StyleTalk framework,右侧是 style-controllable dynamic decoder。这个图说明 style code 既作为 decoder query 条件,也用于动态生成 feed-forward layer 的 expert 权重组合。
四个模块分别承担不同信息:
| 模块 | 输入 | 输出 | 作用 |
|---|---|---|---|
| Audio Encoder $E_a$ | phoneme labels $a_{t-w:t+w}$ | audio feature $a’_{t-w:t+w}$, 每个 token 256 dim | 提取 articulation content,尽量去掉音频里的情绪/强度泄漏 |
| Style Encoder $E_s$ | style video 的 3DMM expression sequence $\delta_{1:N}$ | style code $s$ | 建模参考视频的动态面部运动模式 |
| Style-controllable Decoder $E_d$ | audio feature + style code | generated expression parameters $\hat{\delta}_{1:T}$ | 生成带风格的 3DMM 表情参数 |
| Image Renderer $E_r$ | target image $I^r$ + $\hat{\delta}_{1:T}$ | output video $\hat{I}_{1:T}$ | 用 PIRenderer 把参数变成 photo-realistic frames |
论文里 $w=5$,也就是 decoder 看当前帧附近 $2w+1=11$ 个 phoneme window。官方代码的默认配置与论文对齐:WIN_SIZE=5、FACE3D_DIM=64、D_MODEL=256,content/style encoder 都是 3 层 Transformer,decoder 使用 DisentangleDecoder,动态 FFN 的 dynamic_K=8。
数据全流程:输入、表示、shape 和语义
这篇论文的关键不是 pixel-to-pixel,而是中间 representation 的选择。把人脸动态压到 3DMM expression parameters 后,style encoder 可以更少受 identity、texture 和 illumination 干扰。
| 阶段 | 对象 | Shape / Dim | 语义 | 产生者 | 消费者 |
|---|---|---|---|---|---|
| Target identity | $I^r$ | RGB image, 论文输出分辨率 256 x 256 | 目标人物身份和外观 | 输入图像 | PIRenderer |
| Driving audio | $A$ | length $T$ audio | speech content | 输入音频 | phoneme extraction |
| Phoneme window | $a_{t-w:t+w}$ | 11 tokens when $w=5$ | 当前帧附近的发音内容 | ASR / phoneme tool | Audio Encoder |
| Audio feature | $a’_{t-w:t+w}$ | 每 token 256 dim | articulation-related feature | Audio Encoder | Decoder |
| Style reference | $V=I^s_{1:N}$ | $N$ frames | speaking style source,不提供 speech content | 输入视频 | 3DMM extraction |
| Style expression sequence | $\delta_{1:N}$ | $N \times 64$ | 去掉纹理/身份后的表情动态 | 3DMM estimator | Style Encoder |
| Style code | $s$ | $d_s$, 代码默认 256 dim | 整段 reference 的 speaking style embedding | Style Encoder + self-attention pooling | Decoder / dynamic FFN |
| Generated expression | $\hat{\delta}_{1:T}$ | $T \times 64$ | 目标视频的 3DMM 表情参数 | Decoder | Renderer / discriminators |
| Output video | $\hat{I}_{1:T}$ | $T$ RGB frames | 目标身份说 driving audio,风格来自 reference | PIRenderer | evaluation / demo |
一个容易忽略的设计是 audio 不直接用 MFCC 等 acoustic feature,而是用 phoneme label。论文的理由是:音频里有 intensity、emotion、timbre 等 articulation-irrelevant 信息,如果直接喂给模型,style control 会被音频自身的风格泄漏污染。换成 phoneme 后,audio 更像内容条件,style reference 才更有机会控制表情动态。
Style Encoder:把风格定义成动态 3DMM 序列
Style encoder 的输入不是原始视频帧,而是 style clip 的 3DMM expression parameters:
\[\delta_{1:N} \in R^{N \times 64}\]这一步的语义很重要:identity、纹理、光照都不应该是 speaking style。作者希望只保留表情运动模式,所以把每帧转换成 64 维 expression coefficients。
然后,Transformer encoder 对 $\delta_{1:N}$ 做时序建模,输出每个 token 的 style vector。最后用 self-attention pooling 聚合为整段视频的 style code:
\[s = \operatorname{softmax}(W_s H)H^T\]其中 $H=[s_1,\ldots,s_N] \in R^{d_s \times N}$。这比平均池化更有表达力,因为风格可能由少数典型帧决定,例如夸张张嘴、皱眉、抬眉等关键动作。
为了让 style space 有语义结构,论文加入 triplet constraint:同一 style 的 style clips 应该更近,不同 style 应该更远。训练时,对 style clip $V_c$ 采正样本 $V_c^p$ 和负样本 $V_c^n$,约束:
\[\mathcal{L}_{trip}=\max\left\{\|s_c-s_c^p\|_2-\|s_c-s_c^n\|_2+\gamma,0\right\}\]论文给出 $\gamma=5$。

图:论文 Figure 5。t-SNE 可视化显示,同一 speaker 的 style code 倾向聚在一起;单个 speaker 内部又能按 emotion/intensity 呈现一定结构。这支持了 style encoder 学到有语义的 style space,但 t-SNE 只能作为辅助证据。
我的理解是,StyleTalk 的 style code 不是纯 emotion code。Figure 5(a) 里同一 speaker 聚得很明显,说明模型学到的首先可能是个体化运动习惯;Figure 5(b) 才在单个 speaker 内部显示 emotion/intensity 结构。这和论文定义的 personalized dynamic facial motion patterns 是一致的。
Dynamic Decoder:style code 不是拼接,而是改 FFN 权重
如果只把 style code 拼到 decoder 输入里,模型仍可能把它当弱条件,尤其在大幅表情运动时出现嘴形缺陷或 artifact。StyleTalk 的关键设计是 style-aware adaptive transformer:用 style code 动态组合 feed-forward layer 的权重。
论文把 feed-forward layer 的参数改成 $K$ 组 expert weights。style code 先通过一个小网络产生 attention weights $\pi_k(s)$,再线性组合 expert:
\[\tilde{W}(s)=\sum_{k=1}^{K}\pi_k(s)\tilde{W}_k,\qquad \tilde{b}(s)=\sum_{k=1}^{K}\pi_k(s)\tilde{b}_k\]约束为:
\[0 \leq \pi_k(s) \leq 1,\qquad \sum_{k=1}^{K}\pi_k(s)=1\]动态 FFN 的输出是:
\[y=g\left(\tilde{W}^{T}(s)x+\tilde{b}(s)\right)\]官方代码里这个机制落在 DynamicLinear -> DynamicConv:style code cond 被 reshaped 后经过两层 1x1 conv 产生 K 维 softmax attention,再用矩阵乘法把 $K$ 组 kernel 聚合成每个样本自己的权重。默认 K=8,与论文 Full model 设置一致。
这件事的直觉是:不同 style 可能需要不同的 audio-to-expression 映射。张嘴幅度大的人和嘴形克制的人,说同一个 phoneme 时的 expression coefficient 不应该完全走同一套 FFN 参数。动态 FFN 让 decoder 在样本级别切换或混合若干“风格专家”。
上下脸解耦:为什么分两个 decoder
论文还做了一个实用观察:上半脸和下半脸的运动频率不同。眼睛、眉毛等上半脸区域变化较低频;嘴部则与 phoneme 更强相关,变化更高频。
因此 StyleTalk 把 64 维 expression parameters 拆成两组:13 个 mouth-related PCA expression bases 作为 lower face group,其余作为 upper face group。两个 parallel style-controllable dynamic decoders 分别生成上下脸参数,再拼回完整 64 维表达。
官方代码中也能看到这个实现边界:DisentangleDecoder 内部有 upper_decoder 和 lower_decoder,分别输出上半脸和下半脸 indices,再写回同一个 face3d tensor。
这个设计不是形式上的多分支。它对应了真实信号差异:嘴部必须紧跟发音,上半脸则更多承载风格、情绪和自然性。如果用同一 decoder 拟合所有参数,模型容易在 lip-sync 和 expression style 之间互相牵制。
Training:监督信号、loss 和优化目标
训练时,StyleTalk 不是直接生成视频再用图像损失端到端训所有东西。它的主生成对象是连续 $L=64$ 帧的 3DMM expression parameters,然后用多个 discriminator 和重建损失约束。
主要监督项如下:
| Loss / 模块 | 作用 | 关键细节 |
|---|---|---|
| Reconstruction loss | 让生成 expression 接近 ground truth | L1 + SSIM,论文给出 $\mu=0.1$ |
| Lip-sync discriminator $D_{sync}$ | 约束嘴形和 phoneme 同步 | 用 3D mouth mesh + phoneme,而不是图像嘴部 + acoustic feature |
| Style discriminator $D_{style}$ | 约束生成序列表达对应 style class | PatchGAN 结构,预训练后冻结 |
| Temporal discriminator $D_{tem}$ | 约束 3DMM expression sequence 的时序真实感 | PatchGAN + GAN hinge loss,与主模型联合训练 |
| Triplet loss | 让 style space 有聚类结构 | margin $\gamma=5$ |
total loss 写成:
\[\mathcal{L}= \lambda_{rec}\mathcal{L}_{rec} +\lambda_{trip}\mathcal{L}_{trip} +\lambda_{sync}\mathcal{L}_{sync} +\lambda_{tem}\mathcal{L}_{tem} +\lambda_{style}\mathcal{L}_{style}\]论文给出的权重是 $\lambda_{rec}=88$,其余四项都是 1。
这里有一个工程上很有意思的点:$D_{sync}$ 不是直接复用 SyncNet 的图像/声学输入,而是把 expression parameters 转成 face mesh 后选 mouth vertices,用 PointNet 得到 mouth embedding,同时 phoneme encoder 得到 audio embedding,再用 cosine similarity 计算同步概率。也就是说,lip-sync 监督也发生在 3D 几何/phoneme 空间,而不是 pixel/audio 空间。
数据和训练配置
StyleTalk 的训练数据来自 MEAD 和 HDTF。MEAD 是实验室环境 talking-face corpus,包含 60 个 speaker、8 种 emotion、3 个 intensity level;HDTF 是 in-the-wild 高分辨率 audio-visual 数据集。
论文构造 speaking style 的方式带有假设:
| 数据集 | style consistency 假设 |
|---|---|
| MEAD | 同一 speaker、同一 emotion、同一 intensity level 的 clips 共享 speaking style |
| HDTF | 同一 speaker 的 clips 共享 speaking style |
最终训练集中得到 1104 个 speaking styles。原始视频按 FOMM 的方式 crop/resize 到 256 x 256,并以 30 FPS 采样。
训练配置方面,论文写明:
| 组件 | 训练设置 |
|---|---|
| Renderer $E_r$ | 在 VoxCeleb、MEAD、HDTF 组合上训练 |
| $D_{sync}$ / $D_{style}$ | 在 HDTF + MEAD 上训练 12 小时,4 x RTX 3090,lr 0.0001,然后冻结 |
| $E_a$ / $E_s$ / $E_d$ / $D_{tem}$ | 在 HDTF + MEAD 上联合训练 4 小时,2 x RTX 3090,lr 0.0001 |
| Optimizer | Adam |
论文没有把所有数据清洗、split、3DMM 提取、phoneme extraction 的可执行细节都写全;官方 README 补充说输入需要 3DMM 参数 .mat 和 phoneme labels *_seq.json,分别参考 PIRenderer 和 AVCT 的流程生成。
Inference:测试时到底怎么生成
推理阶段的输入是:
src_img_path:目标身份图像;audio_path:phoneme sequence json;style_clip_path:style reference 的 3DMM.mat;pose_path:pose 参数;wav_path:用于最终视频合成音轨。
官方 demo script 的流程是:
- 加载 StyleTalk checkpoint,拆出 content encoder、style encoder、decoder;
- phoneme sequence 经过
get_audio_window形成窗口输入; - style clip 通过
get_video_style_clip取最多 256 帧 3DMM expression; - decoder 输出 generated expression parameters;
- 把 expression 和 pose 拼接成 renderer 所需参数;
- PIRenderer 逐段渲染视频帧;
- 用 ffmpeg 把 silent video 和 wav 合成最终 mp4。
官方 README 给出的 demo 命令大致是:
python inference_for_demo.py \
--audio_path samples/source_video/phoneme/reagan_clip1_seq.json \
--style_clip_path samples/style_clips/3DMM/happyenglish_clip1.mat \
--pose_path samples/source_video/3DMM/reagan_clip1.mat \
--src_img_path samples/source_video/image/andrew_clip_1.png \
--wav_path samples/source_video/wav/reagan_clip1.wav \
--output_path demo.mp4
这个推理接口说明了一件事:StyleTalk 的公开实现不是“给一个 wav 和一个 mp4 就全自动完成”。它依赖预处理后的 3DMM / phoneme / pose 文件。真实工程落地时,前处理稳定性会直接决定最终效果。
Evaluation:指标和 baseline 是否公平
论文在 MEAD 和 HDTF 上做 self-driven evaluation,test set 里的 speaker 和 speaking style 未见过。输入使用每个视频第一帧作为 reference image,对应 audio 作为 audio input。对比方法包括 MakeitTalk、Wav2Lip、PC-AVS、AVCT、GC-AVT 和 EAMM。
指标分三类:
| 指标 | 方向 | 衡量内容 |
|---|---|---|
| SSIM | 越高越好 | 图像结构相似度 |
| CPBD | 越高越好 | 清晰度 / blur perception |
| F-LMD | 越低越好 | 全脸 landmark distance,反映表情/脸部运动 |
| M-LMD | 越低越好 | 嘴部 landmark distance,反映 lip movement |
| Sync_conf | 越高越好 | SyncNet confidence,反映音画同步 |
主表中 StyleTalk 在多数指标上最好。几个关键结果:
| Dataset | Method | SSIM | CPBD | F-LMD | M-LMD | Sync_conf |
|---|---|---|---|---|---|---|
| MEAD | Wav2Lip | 0.795 | 0.178 | 2.718 | 4.052 | 5.257 |
| MEAD | AVCT | 0.832 | 0.139 | 2.923 | 5.520 | 2.525 |
| MEAD | Ours | 0.837 | 0.164 | 2.122 | 3.249 | 3.474 |
| HDTF | AVCT | 0.755 | 0.233 | 2.733 | 3.610 | 3.147 |
| HDTF | Ours | 0.812 | 0.302 | 1.941 | 2.412 | 3.165 |
这里要注意评价的 caveat。Wav2Lip 在 MEAD 上 Sync_conf 最高,甚至高于 ground truth,论文解释为 Wav2Lip 本身使用 SyncNet discriminator,因此这个指标对它偏友好;同时 Wav2Lip 只生成嘴部,其他区域不动,所以 CPBD 也可能更高。换句话说,Sync_conf 和 CPBD 不能完整衡量 style control。
StyleTalk 更有说服力的指标是 F-LMD 和 M-LMD 同时下降:它说明全脸表情和嘴部运动更接近目标协议。但 F-LMD/M-LMD 仍然是 landmark 层面的 proxy,不等价于人类感知中的“风格像不像”。
实验与证据:消融真正支持了什么
消融实验在 MEAD 上比较了 DyFFN、expert 数量、style discriminator、triplet loss 和 sync discriminator。

图:论文 Figure 4。定性消融显示 Full model 在 mouth shape 和参考风格表达上更接近目标;量化表进一步说明 DyFFN、style discriminator、triplet loss 和 sync discriminator 分别影响不同指标。
量化消融的核心结果如下:
| Variant | SSIM | CPBD | F-LMD | M-LMD | Sync_conf |
|---|---|---|---|---|---|
| w/o DyFFN | 0.830 | 0.165 | 2.414 | 4.178 | 3.059 |
| $K=4$ | 0.831 | 0.163 | 2.327 | 3.524 | 3.331 |
| $K=16$ | 0.835 | 0.161 | 2.133 | 3.396 | 3.473 |
| w/o $D_{style}$ | 0.836 | 0.160 | 2.483 | 3.628 | 3.430 |
| w/o $\mathcal{L}_{trip}$ | 0.837 | 0.160 | 2.401 | 3.771 | 3.532 |
| w/o $D_{sync}$ | 0.834 | 0.164 | 2.281 | 4.351 | 2.305 |
| Full ($K=8$) | 0.837 | 0.164 | 2.122 | 3.249 | 3.474 |
这些结果支持几个具体判断:
DyFFN 对风格化嘴形和全脸动作有用。去掉 DyFFN 后,F-LMD、M-LMD、Sync_conf 都下降,说明 style code 只作为普通条件还不够强。
$K=8$ 是这个任务上的经验平衡。$K=4$ 容量偏小,$K=16$ 接近 Full 但没有继续优于 $K=8$,可能存在过拟合或冗余 expert。
style discriminator 和 triplet loss 更影响 style perception。去掉它们后 F-LMD/M-LMD 变差,说明风格空间结构和风格分类监督确实在推动模型捕捉动态面部模式。
sync discriminator 主要守住 lip-sync。去掉 $D_{sync}$ 后 Sync_conf 从 3.474 掉到 2.305,M-LMD 也明显变差。
复现与工程风险
StyleTalk 的推理复现状态比只发论文的工作好:官方 GitHub 已有代码、requirements、checkpoint 链接和 demo script。README 明确说代码在 2023-04-14 available,且给出 StyleTalk checkpoint、Renderer checkpoint 的 Google Drive 链接。
但完整训练复现仍有几个风险。
第一,前处理链路比较长。README 说明模型输入是 3DMM 参数和 phoneme labels,3DMM 需要参考 PIRenderer,phoneme 需要参考 AVCT。任何一个 extractor 版本、crop 策略、失败样本过滤不同,都会影响 style code 和 expression supervision。
第二,style label 的构造依赖数据集假设。MEAD 里“同 speaker + emotion + intensity = same style”,HDTF 里“同 speaker = same style”。这些假设足够实用,但不是严格人工标注的 speaking style。模型学到的 style space 会混合 identity、emotion、个人习惯和数据集偏差。
第三,renderer 是单独训练并冻结的。论文中 $E_r$ 在 VoxCeleb、MEAD、HDTF 上训练,推理时最终视觉质量依赖 renderer 的表达能力。如果 style decoder 生成了极端 expression,renderer 是否能稳定渲染并不完全由 StyleTalk 本体决定。
第四,评价指标仍不直接等价于 style similarity。F-LMD/M-LMD 能衡量 landmark 接近,Sync_conf 能衡量音画同步,但“说话风格像不像参考视频”仍然需要更强的人评或专门 style metric。论文提到 user study 在 supplementary materials,但主文里没有展开。
第五,GitHub 代码确认了默认结构细节,但不是所有训练脚本和数据 split 细节都能仅靠 README 一次性复现。实际复现建议先跑官方 demo,再固定 3DMM/phoneme preprocessing,最后再尝试重训 $E_a/E_s/E_d$。
对我的启发
这篇论文对数字人系统有一个很直接的启发:可控性最好落在一个语义足够明确、又足够接近生成结果的中间表示上。StyleTalk 没有直接让 style reference frame 去 warp target face,也没有让 audio feature 承担所有信息,而是把 style、content、identity 分别放在 3DMM dynamics、phoneme window 和 reference image 里。
另一个启发是 decoder conditioning 的强度。很多模型把条件拼接进去就结束了,但 StyleTalk 认为 one-to-many mapping 下普通条件不够,于是让 style code 去调 FFN 权重。这个思想和后来很多条件生成里的 adapter、dynamic kernel、LoRA routing、MoE routing 有相通之处:当条件代表一种生成机制差异时,只改变输入特征可能不够,改变局部参数化会更直接。
最后,它也提醒我们不要过度相信单一 lip-sync 指标。一个 talking head 看起来真实,除了嘴对上音,还要有个体化表情节奏、上半脸参与、背景稳定、身份保持和 temporal coherence。StyleTalk 用 speaking style 这个入口把这些问题重新组织了一遍。
总结
StyleTalk 是一篇很适合放在 digital human / talking head 技术线里读的论文。它把任务从“音频驱动嘴动”推进到“音频内容 + 参考风格 + 目标身份”的组合生成,并给出了一个相对清晰的工程拆解:phoneme content encoder、3DMM style encoder、style-aware dynamic decoder、PIRenderer。
它的价值在于:speaking style 被定义为动态面部运动模式,而不是离散 emotion label 或逐帧表情迁移;style code 不只是附加条件,而是参与 FFN 权重生成;上下脸解耦也把 lip-sync 与表情风格之间的频率差异显式建模。
它的边界也很清楚:依赖 3DMM/phoneme/pose 前处理,style label 构造有启发式假设,renderer 是单独模块,style similarity 的评价仍不够直接。对于工程落地,我会把它看成一个结构清楚的 style-conditioned 3DMM talking head pipeline,而不是一个端到端通吃真实场景的方案。
如果要继续沿这个方向做,比较自然的改进点有三类:用更强的 audio/content 表示但避免 style leakage;用更连续或自监督的 style similarity objective 替代粗粒度 style label;把 renderer 升级到更强的 diffusion/3D-aware renderer,同时保留 3DMM 或 FLAME 这类可控中间表示的可解释性。
Recommended citation: Ma et al., StyleTalk: One-shot Talking Head Generation with Controllable Speaking Styles, AAAI 2023 Oral.
Download Paper