
DreamX-World 1.0 深读:交互式世界模型不是视频生成,而是全栈系统工程
DreamX-World 1.0 深读:交互式世界模型不是视频生成,而是全栈系统工程
论文:DreamX-World 1.0: A General-Purpose Interactive World Model 作者:DreamX Team; Yancheng Bai, Rui Chen, Xiangxiang Chu, Rujing Dang, Hao Dou, Bingjie Gao, Qiwen Gu, Siyu Hong, Jiachen Lei, Geng Li, Jifan Li, Ruimin Lin, Qingfeng Shi, Bingze Song, Lei Sun, Jing Tang, Ruitian Tian, Jun Wang, Jiahong Wu, Pengfei Zhang, Shen Zhang, Jiashu Zhu 时间 / 版本:arXiv v1, submitted 2026-06-15 类别:Interactive World Model / Camera-Controlled Video Generation / Autoregressive Diffusion / Long-Horizon Simulation 链接:Paper / Project / Code / DreamX-World-5B / DreamX-World-5B-Cam 本文基于 arXiv TeX source、PDF、官方项目页、GitHub README 和 Hugging Face model metadata 阅读;检索日期:2026-06-23。
开篇点评:这篇论文到底解决了什么问题
DreamX-World 1.0 不是单纯把 text-to-video 做成长视频。它真正面对的是 interactive world model 的状态一致性问题:用户或 agent 给出 camera action、image anchor、event prompt 以后,系统要连续生成一个可探索、可返回、可触发事件的世界。
这比普通视频生成多了几层约束。移动相机时,视角变化要跟轨迹一致;离开局部上下文后,重新回到旧位置不能变成另一个相似但不同的场景;事件 prompt 不只是“画面里出现什么”,还要让多对象状态变化持续存在;如果要交互,latency 又不能像离线 diffusion 视频那样慢。
我的判断是,这篇报告的价值不在于某个 isolated trick,而在于它把 world model 拆成一条完整工程链路:数据系统、camera conditioning、memory retrieval、autoregressive distillation、event tuning、RL alignment 和 streaming deployment。它更像一份可操作的系统路线图,而不是一篇只靠单一网络结构取胜的论文。
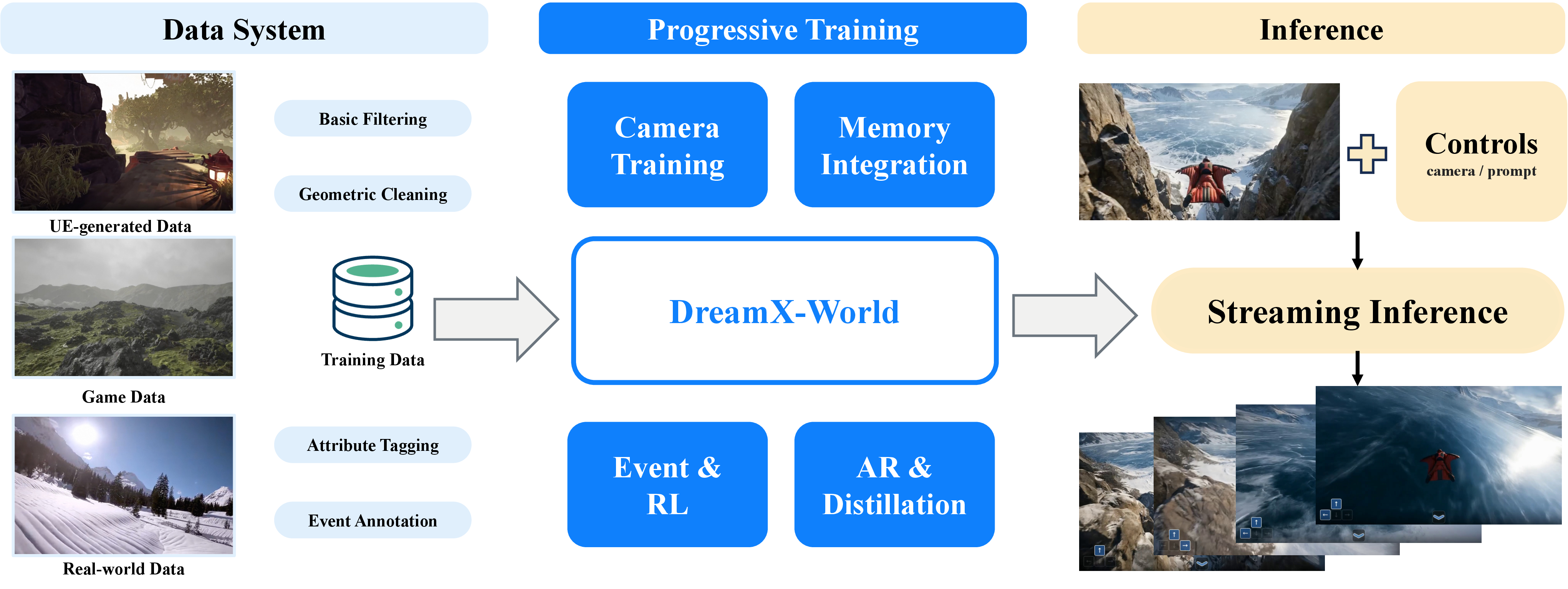
图:官方 source 中的 system overview。左侧是 UE/game/real-world 数据系统,中间是 progressive training,右侧是带 controls 的 streaming inference。这个图基本概括了论文的“全栈系统”定位。
Paper Card
| 项目 | 信息 |
|---|---|
| Paper | arXiv:2606.16993 |
| Title | DreamX-World 1.0: A General-Purpose Interactive World Model |
| Authors | DreamX Team and 22 named authors |
| Date / Version | Submitted 2026-06-15, v1 |
| Base model | Wan2.2-TI2V 5B |
| Open models | DreamX-World-5B-Cam, DreamX-World-5B |
| Code | AMAP-ML/DreamX-World |
| 主要能力 | camera navigation, revisits, promptable / composable events, long-horizon autoregressive generation |
| 复现状态 | 推理代码和 5B 权重已公开;训练数据引擎、完整训练 recipe、event quantitative evaluation、RL reward model 和 16 FPS serving stack 未完整公开 |
Abstract:论文摘要解读
论文的摘要可以压缩成一句话:DreamX-World 1.0 是一个 general-purpose interactive text/image-to-video world model,支持 camera navigation、revisits to previously observed regions 和 promptable events,覆盖 photorealistic、game-style 和 stylized domains。
它的技术路线分成四条主线:
- 数据层面,把 UE5 synthetic trajectories、gameplay recordings 和 real-world videos 统一成带 camera/action/event 标注的训练池。
- 控制层面,用 E-PRoPE 在 DiT attention 中引入轻量 projective camera geometry。
- 长程层面,用 Memory-Conditioned Scene Persistence、causal forcing、DMD-style distillation 和 long-rollout training 减少 chunk-wise autoregressive drift。
- 部署层面,用 mixed-precision DiT、residual reuse、75% pruned VAE decoding 和 asynchronous pipeline parallelism,把系统推到 8 张 RTX 5090 上最高 16 FPS。
摘要里的数字也值得拆开看:5 秒 basic evaluation 上,DreamX-World-1.0-5B 的 camera-control score 是 73.75,overall 是 84.76,高于 HY-WorldPlay 1.5 的 80.79 和 LingBot-World 的 80.45。这个结果支持它在综合指标上更均衡,但不意味着每个单项都赢。
Motivation
普通视频扩散模型的目标通常是生成一段看起来合理的视频。interactive world model 的目标更苛刻:它必须像一个可被操作的环境。
论文在 introduction 里把难点分成三类。第一是 camera control。用户给出轨迹后,模型不能只生成“像是在动”的画面,而要让旋转、平移和尺度变化跟 camera signal 对齐。第二是 scene persistence。早先看到的区域如果离开 local context,重新访问时很容易变成另一个合理但不一致的版本。第三是 latency。少步数蒸馏能提升吞吐,但也会伤害 visual quality、camera control 和 rollout stability。
所以 DreamX-World 的核心问题不是“如何生成更漂亮的视频”,而是:
| 约束 | 失败形态 | DreamX-World 的应对 |
|---|---|---|
| Camera control | 相机轨迹和画面运动不匹配 | E-PRoPE 和 camera-aware training |
| Long horizon | style/color/identity/background drift | causal forcing, DMD, long rollouts, Infinity-RoPE |
| Revisit memory | 回到旧位置时布局或物体身份改变 | geometry-guided memory retrieval |
| Event control | prompt 触发不了多对象交互或状态变化不持续 | Event Instruction Tuning |
| Low latency | 交互时延过高 | mixed precision, cache, pruned VAE, async serving |
这套 framing 很重要。它把 world model 从“生成质量”这个单指标里拉出来,变成一个需要同时优化状态、控制、记忆和系统吞吐的工程问题。
直观效果:先看它能做什么
官方 qualitative figure 展示的是多种场景类型和 camera controls 下的生成关键帧。它说明 DreamX-World 不只做 photorealistic 室内/城市场景,也覆盖 fantasy、game-like 和 stylized visual domains。

图:官方 qualitative results。每行是一个 generated video sequence 的均匀采样关键帧,用来展示不同视觉域和 camera movement 下的连贯性。
这里要谨慎解读。qualitative figure 能说明模型有较强的视觉 prior 和局部连续性,但真正决定 interactive world model 是否成立的不是单次样张,而是长程 rollout、revisit consistency 和 camera/action alignment。因此论文后面的 evaluation 比 teaser 更重要。
方法总览:核心思想和系统结构
DreamX-World 初始化自 Wan2.2-TI2V 5B,然后通过 progressive training pipeline 逐步引入世界模型所需的能力:
- camera-aware training: 让 bidirectional video generator 接受 6-DoF camera trajectory;
- E-PRoPE: 用更轻量的 projective positional encoding 进入 DiT attention;
- memory-conditioned scene persistence: 通过 camera geometry 检索早先视角,并和 recent history、target noisy frames 一起打包;
- event instruction tuning: 把 structured event records 渲染成自然语言 prompt,训练模型响应多对象事件;
- autoregressive long-video generation: 用 causal forcing 和 DMD-style distillation 把 bidirectional teacher 变成 few-step AR student;
- RL post-training: 用 camera-control reward 和 video-quality reward 修复 distillation 后的控制和质量损失;
- streaming inference: chunk-wise AR generation + rolling KV cache + VAE/DiT 推理优化。
这条 pipeline 的设计逻辑是先让模型“能看懂控制”,再让它“能记住世界”,然后让它“能连续滚动生成”,最后把 few-step AR model 用 RL 和推理工程拉回可用质量。
数据全流程:输入、表示、shape 和语义
训练 interactive world model 的关键不是只收集视频,而是收集带可靠 control signals 的视频。DreamX-World 把数据分成三类。
| 数据来源 | 作用 | 标注 / 处理 |
|---|---|---|
| UE5-generated data | 提供精确 camera/action/event ground truth | first-person free camera、third-person character、event subsets;每帧记录 WASD/IJKL-style action vector 和 camera pose |
| Real-world videos | 提供真实视觉多样性 | 来自 SpatialVID、RealEstate10K、Sekai、DL3DV;用 MegaSaM 估 sparse poses,再插值和几何清洗 |
| Game data | 提供 action-rich dynamics 和游戏风格域 | Sekai-Game、OmniWorld-Game;engine-exported poses 转换到统一 camera coordinate system |
过滤流程分三步:basic filtering、geometric camera-pose cleaning、video captioning and attribute tagging。basic filtering 会去掉时长/帧率不足、overlay text 过多、黑边、视觉变化不足的 clips。real-world poses 会经过 SLERP rotation interpolation、linear translation interpolation、trajectory normalization 和异常检测。最后每个 clip 会被打上 aesthetic quality、motion intensity、scene category、visual style、subject type 和 motion category 等标签。
Event Instruction Data 是单独构造的。它从 cleaned and tagged pool 中选择包含可见状态变化的 clips,标注 global description 和 time-aligned entity-level event records。每个 event record 包括 entity reference、event predicate、spatial anchor 和 temporal interval。对 composable events,每个对象有自己的 event record,对象间交互写在 global caption 里。
这里的复现风险很明显:论文没有公开 UE scenes、数据规模、各来源比例、过滤阈值、caption/tagging 模型、event annotation guideline 和质量控制细节。数据系统是论文最关键的部分之一,也是最难复现的部分。
Camera Control:E-PRoPE 为什么要存在
Wan2.2-TI2V 本身不接受 camera trajectories。DreamX-World 首先训练 bidirectional model,让它支持 explicit 6-DoF camera control。基础做法借鉴 PRoPE:把 projective camera geometry 注入 self-attention 的 query/key。
完整 PRoPE 的问题是贵。长视频 token 很多,如果在每层 DiT attention 上对 full-resolution video tokens 做 projective attention,训练和推理成本都会显著增加。DreamX-World 的 E-PRoPE 做了一个工程上合理的折中:只在 spatially downsampled tokens 上做 PRoPE attention,然后再 upsample 回原 token resolution 并加到原 DiT attention output 上。
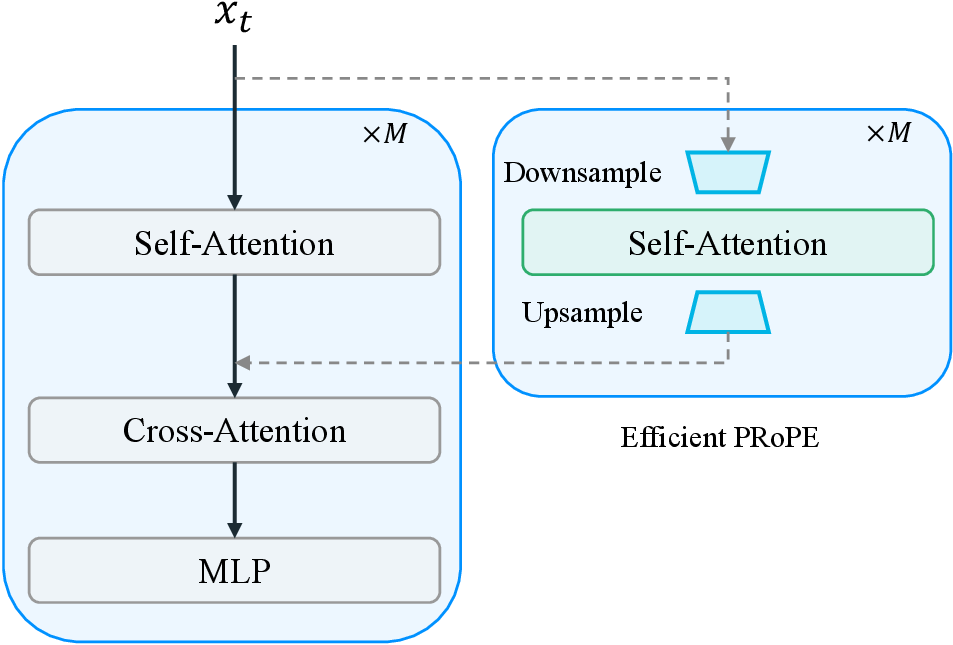
图:官方 E-PRoPE module。它把 camera-aware PRoPE attention 放在 downsampled tokens 上,再把结果回写到原 DiT attention 路径。
论文给了一个具体规模:5 秒 720P video 经过 Wan2.2 5B VAE 后是 $S=18480$ tokens,E-PRoPE 下采样到 $N=4096$ tokens,空间 token 数减少超过 4.5 倍。同时它省略 PRoPE 中的 $D_s^{RoPE}$,只保留 projective submatrix $D_s^{Proj}$,因为原 DiT backbone 已经有足够的 spatiotemporal position bias。
训练策略也很克制:freeze DiT backbone,只反传到 PRoPE parameters。表格结果显示,E-PRoPE 的 camera control 分数 73.75,完整 PRoPE 是 73.89;但 latency 从 80 降到 59。换句话说,它牺牲极小的 camera score,换来约 30% inference latency reduction。
Memory:它怎么处理“回到旧地方”
自回归视频模型最容易出问题的地方是 revisit。早先看到的建筑、道路、物体离开上下文窗口后,模型重新生成时往往只会生成一个“语义合理”的区域,而不是同一个区域。
DreamX-World 的 Memory-Conditioned Scene Persistence 不是另加一个外部 memory decoder,而是把 memory frames、recent history 和 noisy target frames 打包进同一个 DiT self-attention stream:
\[z_{\mathrm{pack}} = [z_{\mathcal{M}} \mid z_{\mathcal{H}} \mid z^{\tau}_{\mathcal{C}}]\]其中 $z_{\mathcal{M}}$ 是通过 camera pose 和 view overlap 从历史中找出的 memory latent frames,$z_{\mathcal{H}}$ 是最近生成历史,$z^{\tau}_{\mathcal{C}}$ 是当前要 denoise 的 target latents。训练时只对 target frames 算 loss。
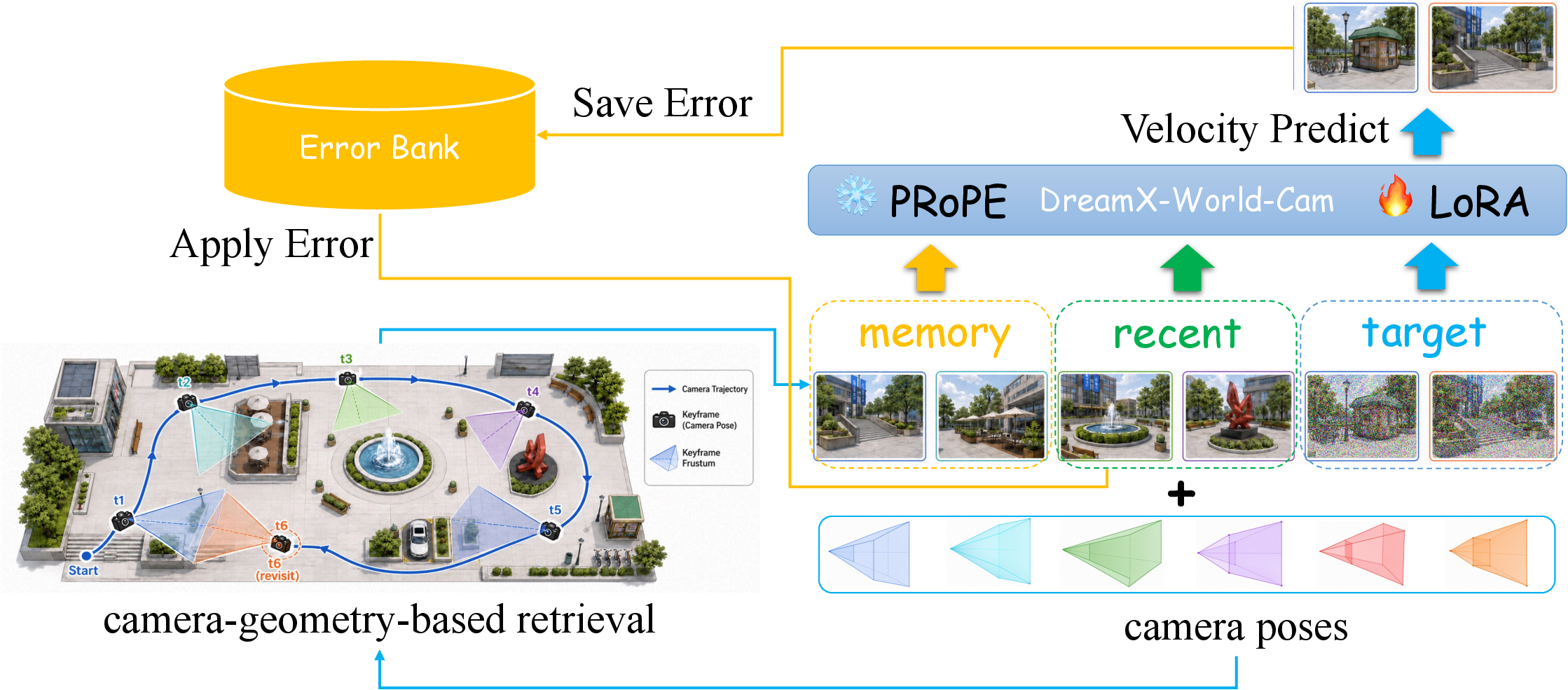
图:官方 memory training framework。左侧通过 camera geometry 找 revisit-relevant memory,右侧把 memory、recent、target 放进同一个 DiT stream;error bank 用来模拟推理时 conditioning tokens 的生成误差。
这个设计有两个关键点。第一,memory retrieval 用几何相关性,而不是简单按时间距离取帧。第二,retrieved memory frames 保留原始 temporal location 的 RoPE embedding,避免模型把远处 memory 当成 target 附近的 recent context。
论文还处理了 exposure bias:训练时 conditioning frames 来自真实数据,推理时 conditioning frames 来自模型生成,会带误差。它借鉴 Stable Video Infinity 的 error injection,只扰动 conditioning tokens,不改变 target latent,让模型学会在 memory 有误差时不要过度信任它。
Training:从 bidirectional video generator 到 few-step AR world model
DreamX-World 的训练不是一步到位,而是逐层增加能力。
| 阶段 | 训练目标 | 关键机制 |
|---|---|---|
| Camera-aware training | 让 Wan2.2-TI2V 接受 6-DoF camera control | E-PRoPE, freeze DiT backbone for PRoPE modules |
| Memory training | revisit 时保持非局部场景一致 | geometry retrieval, packed self-attention, residual recycling |
| Event Instruction Tuning | 支持 promptable/composable events | structured event records rendered as natural-language prompts |
| DMD / causal forcing | bidirectional teacher 转成 few-step AR student | long rollouts, local temporal windows, Infinity-RoPE, DMD supervision |
| RL post-training | 修复 distillation 后的质量和控制损失 | video-quality reward, camera-control reward, DiffusionNFT soft update, KL regularization |
DMD-forcing 是长视频能力的核心。模型先用 causal forcing 训练 few-step autoregressive generator,再在 long sequences 上用 long rollouts 和 local windows 适配。camera-controlled 版本把 E-PRoPE branch 加进 AR student,并用 bidirectional E-PRoPE teacher 监督 student 的 local temporal windows。
I2V 蒸馏还有一个额外细节:每个 DMD window 的 first latent frame 被 VAE decode 成 image condition,送给 teacher,让 teacher 在局部窗口上监督 camera-controlled AR student。这是为了保持 I2V quality,而不是只优化 T2V AR rollout。
RL 阶段的设计也偏工程。DMD-distilled AR model 先生成 long-horizon rollout candidates,再从 rollout 中采 short clips,分别送给 video-quality reward model 和 camera-control reward model。融合 reward 后做 DiffusionNFT soft model update。这样做的原因是 reward model 和 backprop 都不必吃完整长视频,但 rollout 仍保留长程上下文。
论文说 RL 使用 gradual update 和 KL regularization 防止 few-step model 早期 collapse。这里缺失的细节很多:reward model 怎么训练、用什么数据、怎样融合 reward、DiffusionNFT 的具体超参和 RL rollout/window 设置都没有完整展开。
Inference:测试时到底怎么生成结果
推理时,DreamX-World 采用 chunk-wise autoregressive streaming。
每个 chunk 从 noise 开始,在 text prompt、chunk-relative camera trajectory 和 rolling KV cache 条件下被 few-step sampler denoise。生成后的 tokens 写回 KV cache,下一个 chunk 继续使用这段历史。T2V 和 I2V 的差别只在第一 chunk:I2V 会把 first frame 替换成 input image,用它锚定后续视频。
Camera controls 用 chunk-relative form。第一 chunk 的 camera poses 相对首帧,之后每个 chunk 的 poses 相对上一个 chunk 的最后一帧。这种 local relative parameterization 可以让 camera condition 始终对齐当前 AR context,减少长序列中控制信号变弱的问题。
部署侧的加速栈很重:
| 部分 | 做法 | 目的 |
|---|---|---|
| DiT attention | INT8 SageAttention | 降低 attention 成本 |
| DiT FFN | FP8 AngelSlim | 降低 FFN 计算和显存 |
| Long tokens | sequence parallelism | 多 GPU 分摊长时空序列 |
| Transformer ops | fused Triton kernels | 减少 kernel launch 和中间张量 |
| Denoising | TeaCache-style residual reuse | 在稳定 timestep 跳过部分 block |
| VAE decoding | Matrix-Game 3.0 VAE, 75% pruning | 把单 chunk decode 降到约 0.25 秒 |
| VAE parallel | ParaVAE-style spatial splitting | 降低单 GPU memory peak |
| Serving | async pipeline parallelism | overlap chunk $k$ decoding 和 chunk $k+1$ denoising |
论文报告最终在 8 张 RTX 5090 上最高 16 FPS。需要注意,这个 16 FPS 指的是论文中的 optimized asynchronous deployment,不等同于 GitHub README 里普通推理脚本的默认速度。README 中 DreamX-World-5B-Cam 是 5 秒 camera model,默认 50 steps;DreamX-World-5B 是 autoregressive long-horizon model,支持 up to 1 minute at 16 FPS,但仍需要准备 Wan2.2-5B-TI2V checkpoints 和相应 GPU 环境。
Evaluation:验证集、指标和 baseline 是否公平
论文的 evaluation 分四块:5 秒 basic evaluation、约 30 秒 long-horizon evaluation、10 秒 revisit memory evaluation 和 human preference study。baseline 是 HY-WorldPlay 1.5 8B 和 LingBot-World 14B。
5 秒 basic evaluation
| Model | Params | Camera | Quality | Trans. | Flicker | Smooth. | Dynamic | Artifact | Overall |
|---|---|---|---|---|---|---|---|---|---|
| HY-WorldPlay 1.5 | 8B | 65.12 | 68.23 | 98.33 | 96.45 | 99.05 | 66.67 | 71.66 | 80.79 |
| LingBot-World | 14B | 71.73 | 67.76 | 85.00 | 94.94 | 97.06 | 88.33 | 58.33 | 80.45 |
| DreamX-World-1.0-5B | 5B | 73.75 | 66.75 | 98.33 | 96.17 | 98.79 | 85.83 | 73.75 | 84.76 |
这个表支持 DreamX 的 overall 最强,camera 和 artifact 领先。但它不是全项碾压:HY 的 quality、flicker、smoothness 更高,LingBot 的 dynamic degree 更高。更准确的说法是 DreamX 在 camera controllability、artifact robustness 和综合平衡上更好。
camera control metric 参考 WorldScore,但 pose estimator 换成 MegaSaM。artifact detection 用 Gemini-3.1-Pro 对 sampled frames 做 binary pass/fail。这里有一个评价风险:pose recovery 和 VLM artifact judgment 本身会引入外部模型偏差。
30 秒 long-horizon evaluation
| Model | Params | Camera | Quality | Trans. | Flicker | Smooth. | Dynamic | Artifact | Overall |
|---|---|---|---|---|---|---|---|---|---|
| HY-WorldPlay 1.5 | 8B | 65.86 | 63.02 | 91.00 | 97.00 | 99.11 | 52.00 | 14.00 | 68.85 |
| LingBot-World | 14B | 63.76 | 60.81 | 54.00 | 96.59 | 97.86 | 87.00 | 12.00 | 67.43 |
| DreamX-World-1.0-5B | 5B | 62.03 | 64.11 | 80.00 | 96.35 | 98.41 | 75.00 | 17.00 | 70.41 |
长程表更有信息量。DreamX overall 仍最高,但优势没有 5 秒表那么大,只比 HY 高 1.56。它的 camera 分数低于 HY,transition 也低于 HY,dynamic 低于 LingBot。它赢在 quality 和 artifact,但 artifact 的绝对数值很低,只有 17.00。我的解读是:DreamX 的长程路线确实有收益,但 long-horizon world generation 远未解决。
Revisit memory evaluation
memory evaluation 是这篇报告里最有针对性的评测。作者构造三类 revisit trajectories:
- out-and-back: 返回接近相同位置和朝向,测 appearance stability;
- closed-loop: 沿闭环回到起点,测 global layout consistency;
- translation-rotation: 带 heading changes 的 revisit,测 viewpoint variation 下的 place identity。
revisit pair 由 camera extrinsics 找出,要求 yaw 差和位置差小于阈值,并有足够 temporal gap。指标不是直接报相似度,而是报相对 non-revisit baseline 的 gain,这样可以减少“相机本来就动得慢所以相似”的干扰。
| Model | Delta PSNR | Delta SSIM | Delta LPIPS | Delta DINO-Sim | Delta VPR-Sim | Delta SP-Match | CLIP-V |
|---|---|---|---|---|---|---|---|
| LingBot-World | 0.61 | 0.019 | 0.039 | 0.090 | 0.100 | 0.088 | 0.987 |
| HY-WorldPlay 1.5 | 3.19 | 0.079 | 0.202 | 0.200 | 0.110 | 0.251 | 0.992 |
| DreamX-World-1.0-5B | 3.92 | 0.098 | 0.232 | 0.246 | 0.142 | 0.216 | 0.991 |
DreamX 在 pixel-level、perceptual、semantic 和 place-recognition gains 上领先,说明 geometry-guided memory 的确帮助 revisit consistency。但 HY 在 SP-Match 和 CLIP-V 上领先,这提醒我们:DreamX 的 memory 更强并不等于局部几何匹配和全程平滑都最强。
Human preference
blind side-by-side human study 中,DreamX 对 HY-WorldPlay 1.5 的 overall win/tie/loss 是 57.5/14.4/28.1;对 LingBot-World 是 61.9/10.6/27.5。visual quality 和 artifact detection 上 DreamX 的 win rate 也较高。camera-control judgments 更接近,tie 较多。
这个 human study 支持 automatic evaluation 的方向,但还缺少评审人数、样本规模、prompt distribution 和统计显著性细节。适合作为补充证据,不宜当作唯一证据。
实验与证据:哪些 claim 被支持,哪些还不够
我会把论文 claim 分成三层。
第一层,证据比较强:DreamX 在 5 秒综合指标、30 秒综合指标和 revisit consistency 上相对两个 open-source baseline 有优势。E-PRoPE 的消融也比较清楚,camera score 基本不掉,latency 明显下降。
第二层,证据中等:autoregressive distillation、DMD-forcing、RL post-training 和推理侧优化共同带来长程和实时能力。论文描述了机制和结果,但没有足够细的 ablation 把每个组件的边际贡献拆开。比如 long-horizon overall 领先,但我们看不到去掉 DMD、去掉 RL、去掉 memory 后完整 30 秒表会怎样变化。
第三层,证据较弱:composable event control。论文给了 capability comparison table,也在 project page 有 demo,但正式 source 里 event occurrence / event reasonableness 的 quantitative table 被注释掉了。也就是说,event 能力可以作为 demo-supported claim 写,但不能写成已经被严谨 benchmark 充分验证。
复现与工程风险
这篇报告的复现状态比很多闭源系统好,因为它公开了 GitHub repo、5B-Cam 权重和 5B autoregressive 权重。但它仍然不是完整可复现论文。
主要风险如下:
| 风险点 | 具体影响 |
|---|---|
| 数据引擎未完整公开 | UE scenes、game data、real data mixture、filtering thresholds、annotation pipeline 都会影响 world dynamics 和 controllability |
| 训练 recipe 缺失 | camera training、memory training、DMD windows、long rollout schedule、RL reward 权重都不是完整可复现 |
| reward models 未公开细节 | RL 后的质量和控制恢复难以独立验证 |
| event quantitative eval 缺失 | composable event 能力主要依赖 demo 和能力表,不如 camera/memory 证据扎实 |
| 16 FPS 依赖部署栈 | 8x RTX 5090、mixed precision、sequence parallelism、Triton kernels、pruned VAE、async serving 都是额外工程条件 |
| evaluation protocol 自建 | World model 评测仍处探索阶段,VLM artifact detection 和 MegaSaM pose recovery 会带外部模型偏差 |
如果工程上尝试复现,我会优先从公开的 inference path 入手,而不是试图复现训练。先跑 DreamX-World-5B-Cam 的 5 秒 camera control,再跑 DreamX-World-5B 的 long-horizon AR generation;如果要评估,先做小规模 camera action consistency 和 revisit prompt set,而不是直接复刻论文完整 benchmark。
总结
DreamX-World 1.0 的核心信息是:交互式世界模型不是“更长的视频生成”,而是一套带状态、控制、记忆和延迟约束的系统工程。
它把 Wan2.2-TI2V 底座推进到 world simulation 方向:E-PRoPE 让相机控制变得便宜,geometry memory 让 revisit 有可用证据,DMD/causal forcing 让 bidirectional model 变成 few-step AR generator,RL 把蒸馏损失的质量和控制拉回来,推理栈则把系统推向实时。
我的结论是:这篇报告值得作为 interactive video/world model 的工程蓝图来读。它的强项是系统完整、公开权重、指标覆盖 camera/memory/long-horizon;它的短板是训练不可完整复现、event quantitative evidence 不够、长程 artifact 绝对分数仍低。真正的后续空间不只是“更大模型”,而是更好的 world-state memory、更可靠的 event benchmark、更低成本的 serving,以及能被 agent 真实使用的闭环交互协议。
Recommended citation: DreamX Team et al., DreamX-World 1.0: A General-Purpose Interactive World Model, arXiv:2606.16993, 2026.
Download Paper