
Follow the Mean:把参考样本变成 Flow Matching 的控制信号
Follow the Mean:把参考样本变成 Flow Matching 的控制信号
论文:Follow the Mean: Reference-Guided Flow Matching
作者:Pedro M. P. Curvo, Maksim Zhdanov, Floor Eijkelboom, Jan-Willem van de Meent
机构:University of Amsterdam / AMLab
版本:arXiv v2,published 2026-05-11,updated 2026-05-12
链接:Paper / PDF / Project / Code / Demo
本文基于 arXiv TeX source、官方项目页和官方 GitHub README 阅读,检索日期:2026-05-23
开篇点评:这篇论文到底解决了什么问题
这篇论文抓住了一个很现实的问题:现在要控制一个图像生成模型,常见办法都偏重。你可以 fine-tune 或训练 LoRA,但每个新目标都要动参数;你可以加 classifier 或 reward,但很多结构目标根本不好写成稳定分数;你也可以 best-of-N 或 prompt optimization,但那是在用推理时间换命中率。
作者换了一个入口:能不能只给一组参考样本,让 frozen model 在采样时跟着这组样本的“均值方向”走?
这个说法听起来像经验技巧,但论文的核心贡献是把它落在 flow matching 的一个干净恒等式上。对于线性 interpolant,velocity field 不是孤立预测出来的向量,它等价于“当前状态应该走向哪个 endpoint mean”。如果 endpoint mean 变了,flow 就变了。
我的判断是,这篇论文真正有价值的地方不在于“粉色大象”这种 demo 本身,而在于它把 controllable generation 重新表述成一个数据操作:不一定要训练新参数,也不一定要定义 reward,只要 reference set 能表达目标分布,采样轨迹就可以被这个 reference-induced mean 拉过去。
这会让一些原来很笨重的控制问题变得轻一点。比如风格、颜色、类别、部分结构先验,很多时候人类也不是靠一句 prompt 理解的,而是靠看一组例子理解的。
Paper Card
| 项目 | 信息 |
|---|---|
| Paper | Follow the Mean: Reference-Guided Flow Matching |
| Authors | Pedro M. P. Curvo, Maksim Zhdanov, Floor Eijkelboom, Jan-Willem van de Meent |
| Date / Version | arXiv v2,2026-05-12 更新 |
| Category | cs.LG;flow matching, controllable generation, reference-guided generation |
| 核心方法 | Reference-Mean Guidance (RMG), Semi-Parametric Guidance (SPG) |
| 使用模型 | frozen FLUX.2-klein (4B) for RMG;DiT-B/4-style model for SPG |
| 数据 / benchmark | two moons, MNIST, GenEval, AFHQv2, FLUX.2 reference-bank experiments |
| Project / Code / Demo | Project / GitHub / HF Demo |
| 模型与数据状态 | 代码公开;RMG 需要 FLUX.2-klein 权限;reference banks 通过 repo make download 获取;SPG 完整训练依赖 4 A100 和 AFHQv2 |
| 复现判断 | RMG demo 和轻量实验较可复现;SPG 训练可读性强,但仍需要 GPU 和完整环境 |
Abstract:论文摘要解读
论文摘要的逻辑很紧。作者先指出,现有 controllable generation 通常依赖三类东西:fine-tuning、auxiliary networks 或 test-time search。这些方法都能增加控制力,但都把控制做成了额外负担:要么更新模型,要么调用新模型,要么反复采样。
Flow matching 给了另一个接口。对于 deterministic interpolants,velocity field 完全由 conditional endpoint mean 决定。这里的 endpoint mean 可以理解为:在当前 noisy state \(x_t\) 下,模型认为最后的 clean sample \(x_1\) 平均会在哪里。改变这个 endpoint mean,就等于改变采样方向。
作者提出两种实现:
| 方法 | 需要训练吗 | 控制信号 | 用在哪里 |
|---|---|---|---|
| RMG | 不需要 | reference bank 诱导出的 closed-form endpoint mean correction | frozen FLUX.2-klein (4B) |
| SPG | 需要 | 显式 mean anchor + learned residual refiner | AFHQv2 上训练的 reference-conditioned image model |
RMG 的特点是轻。prompt、seed、model weights 都固定,只换 reference set,就能控制颜色、identity、style 和部分 structure。SPG 则更像把这套思想训练进模型结构里,让模型学会从 reference set 中提取有用属性,同时压掉不想复制的 nuisance correlation,比如 reference bank 共同的白色背景。
摘要最后那句话很重要:generative models that adapt through data, not parameter updates。它不是说 fine-tuning 没用了,而是在提示一个方向:当目标经常变、样本很少、reward 不好写时,reference set 可能是比参数更新更自然的控制接口。
Motivation
很多生成控制需求并不适合只靠 prompt。颜色和风格还好,prompt 往往能表达;但结构、姿态、空间关系、属性绑定就麻烦得多。GenEval 这类 benchmark 里的位置关系、两个物体、颜色归属,本质上就是这种问题:文本里写得清楚,不代表生成轨迹会照着做。
这篇论文的 motivation 可以拆成两个层次。
第一层是工程层面的:如果每个新控制目标都要 fine-tune,成本和管理复杂度会很快失控;如果依赖 reward 或 classifier,控制能力又受限于 reward 本身会不会看图、会不会看结构;如果靠 search,推理成本会变成硬伤。
第二层是 flow matching 自己的结构机会。论文不是凭空说“用例子引导生成”,而是利用了 endpoint mean 这个对象。对线性 bridge:
\[u_t(x)=\frac{\mu_t(x)-x}{1-t},\qquad \mu_t(x)=\mathbb{E}[x_1\mid x_t=x].\]这意味着模型在每一步预测 velocity 时,其实隐式给出了“我认为最终样本应该在哪里”。如果 reference set 能提供另一个 endpoint mean,控制就不必通过外部 reward 迂回进入,而是直接作用在生成动力学上。
这个动机比“参考图控制生成效果更好”更具体。它真正要验证的是:reference set 是否可以作为 endpoint posterior mean 的替代来源,从而改变 flow field。
直观效果:先看它能做什么
论文主图对应 TeX source 中 images/main/fig1.pdf,图注明确说的是 reference-guided flow matching 的 overview:noisy state 和 reference set 匹配后,prediction endpoint mean 相对 pretrained model 的预测发生偏移,进而让 flow 带上 reference set 的特征。
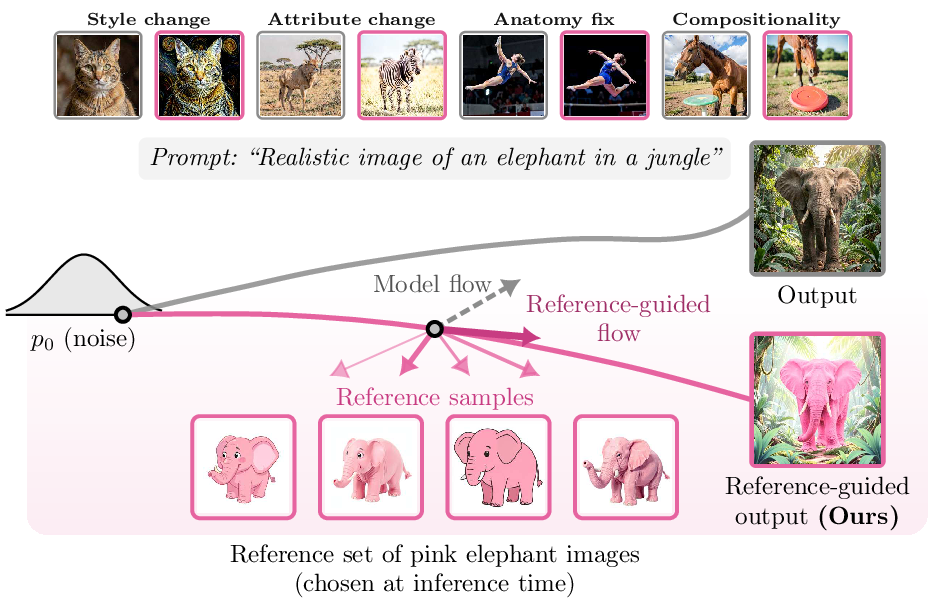
图:论文 Figure 1。灰色是 base model flow,粉色是 reference-guided flow。它支持的理解点是:RMG 不是在输出后筛选图片,而是在采样轨迹中改变 velocity 的 endpoint mean。
FLUX.2-klein 的 reference swap 图更直观。同一列里 prompt、seed、model weights 固定,唯一变化是 reference bank。粉色/蓝色大象、棚拍/Van Gogh 猫、素描/电影感房子、长颈鹿/斑马,都是 reference set 换掉后得到的方向变化。

图:基于论文 Figure 3 重组。它说明 RMG 的控制对象不是 prompt token,而是一组 reference images 在 latent space 中诱导出的 posterior mean。
结构控制那张图更值得谨慎看。keyhole silhouette、hand pose、gymnastics pose 都是 qualitative evidence,不是大规模定量证明。但它们说明 reference bank 不只能转移颜色和风格,也能对几何先验产生影响。

图:基于论文 Figure 4 重组。右列 nearest reference 不是生成结果,而是 reference bank 中最近的样本,用来说明方法不是简单复制参考图。
方法总览:核心思想和系统结构
先把核心机制说清楚。Flow matching 用一个 bridge 把 noise \(x_0\) 和 data \(x_1\) 连起来。论文主要讨论线性形式:
\[x_t=(1-t)x_0+t x_1,\qquad t\in[0,1].\]在这个设定下,velocity field 可以写成 endpoint mean 的函数:
\[u_t(x)=\frac{\mu_t(x)-x}{1-t}.\]所以两个目标分布的 flow 差异,只需要看它们的 endpoint mean 差异:
\[u_t^\pi(x)-u_t(x)=\frac{\mu_t^\pi(x)-\mu_t(x)}{1-t}.\]RMG 做的事,就是用 reference set \(\mathcal{R}=\{x^{(1)},...,x^{(M)}\}\) 估计一个 reference endpoint mean:
\[\hat{\mu}_t^\rho(x)=\sum_{m=1}^{M}w_t^{(m)}(x)x^{(m)}.\]权重来自 Gaussian bridge 下的 closed-form posterior:
\[w_t^{(m)}(x)=\mathrm{Softmax}_m\left( -\frac{1}{2}\frac{\|x-tx^{(m)}\|^2}{(1-t)^2} \right).\]最后把 pretrained model 的 velocity 修正为:
\[u_t^\pi(x)\simeq u_t^\theta(x)+ \beta_t\frac{\hat{\mu}_t^\rho(x)-\mu_t^\theta(x)}{1-t}.\]直觉上,这个 correction 是一句很具体的话:base model 认为终点均值在 \(\mu_t^\theta(x)\),reference bank 认为终点均值在 \(\hat{\mu}_t^\rho(x)\),那就把当前速度往 reference mean 的方向拉一点。
这篇论文已经有一张足够好的官方方法总览图,也就是前面贴出的 Figure 1。这里不再重画一张不必要的流程图。更适合记住的是下面这个三行关系:
| 对象 | 怎么得到 | 它在采样里做什么 |
|---|---|---|
| Base endpoint mean \(\mu_t^\theta(x)\) | 由 frozen model velocity 反推:\(x+(1-t)u_t^\theta(x)\) | 表示 base model 原本想走向的平均终点 |
| Reference endpoint mean \(\hat{\mu}_t^\rho(x)\) | 对 reference latents 做 posterior softmax weighted sum | 表示 reference bank 希望当前状态走向哪里 |
| Guided velocity \(u_t^\pi(x)\) | 把 \(\hat{\mu}_t^\rho-\mu_t^\theta\) 加回 velocity | 在同一次采样轨迹中注入 reference 属性 |
把这三行对应回 Figure 1:灰色路径来自 base endpoint mean,粉色路径来自 reference endpoint mean correction。图里那些粉色 reference samples 不是“额外条件网络输入”,而是在估计一个新的 posterior mean。
SPG 是另一条线。RMG 直接用 closed-form reference mean,优点是无需训练,问题是 reference bank 里的 nuisance correlation 也可能被带走。比如一组白底动物 reference 可能把白底也转移到生成结果里。
SPG 把 reference mean 变成模型内部结构:
\[\mu^\theta_t(x_t,\mathcal{R})= (1-g_t)x_t+g_t\bar{x}+\alpha_t f^\theta(\bar{x},x_t,t).\]这里 \(\bar{x}\) 是 cross-attention 得到的 anchor,\(f^\theta\) 是 residual refiner。anchor 负责从 reference set 里抓方向,refiner 负责学哪些东西该保留、哪些东西该压掉。
数据全流程:输入、表示、shape 和语义
论文里有两条流程,不能混在一起讲。RMG 是 training-free inference-time guidance;SPG 是一个训练出来的 reference-conditioned model。
RMG:frozen FLUX.2-klein 上的测试时控制
| 阶段 | 对象 | Type / Shape | 语义 | 来源 |
|---|---|---|---|---|
| Prompt | text prompt | string | 基础语义条件,比如 an elephant in a jungle | paper / repo configs |
| Initial state | \(x_t\) | FLUX latent / packed latent representation;exact shape not specified | 当前采样状态 | FLUX.2 sampler |
| Base velocity | \(u_t^\theta(x)\) | same latent coordinate | frozen model 的原始速度场 | FLUX.2-klein (4B) |
| Base endpoint mean | \(\mu_t^\theta=x+(1-t)u_t^\theta(x)\) | same latent coordinate | base model 预测的最终样本均值 | 由 velocity 反推 |
| Reference set | \(\mathcal{R}\) | main experiments 常用 20 images;VAE latent exact shape not specified | 目标属性、风格、identity 或结构的样本集合 | paper reference banks |
| Reference endpoint mean | \(\hat{\mu}_t^\rho\) | same latent coordinate | reference posterior weighted average | closed-form weights |
| Guidance schedule | \(\beta_t=\beta_0(1-t)^2\) | scalar | 控制 guidance 强度和时机 | appendix C/E |
| Output | generated image | 768 x 768 in FLUX experiments | 带 reference 属性的生成图 | sampler decode |
RMG 的测试时流程可以按实际执行顺序读:
- Prompt 和 noise seed 进入 frozen FLUX.2-klein,得到当前 latent state \(x_t\) 和 base velocity。
- Reference images 先用同一个 frozen VAE 编码到 FLUX sampler 使用的 latent coordinate system。
- 对每个采样时刻,用 Gaussian bridge posterior softmax 给 reference latents 加权,得到 \(\hat{\mu}_t^\rho(x)\)。
- 从 base velocity 反推 \(\mu_t^\theta(x)\),再用均值差修正 velocity。
- 继续原本的 sampler,最后 decode 成 768 x 768 image。
这里最容易误解的一点是:RMG 没有把 reference images 作为 ControlNet 那种空间条件塞进模型。它更像在每一步问:“按这一组 reference endpoints,当前 noisy latent 的平均终点应该往哪里偏?”
RMG 的关键数据含义不是“参考图作为条件图输入模型”,而是“参考图作为 endpoint distribution 的 empirical support”。每个 reference image 都是潜在终点,softmax 权重衡量当前 noisy state 更像哪一个 reference endpoint 的中间状态。
SPG:把 reference mean 训练进模型
| 阶段 | 对象 | Type / Shape | 语义 | 来源 |
|---|---|---|---|---|
| Dataset | AFHQv2 dog/cat | all dog and cat images from huggan/AFHQv2 training split | 训练图像分布 | appendix C.2 |
| Encoder | frozen REPA-E VAE | encodes to 256 x 256 latents;channel count not specified | 把图像变成 latent endpoint | appendix C.2 |
| Noisy sample | \(x_t=(1-t)x_0+t x_1\) | latent tensor;exact channel dim not specified | flow matching 中间状态 | appendix C.1 |
| Reference set | \(\mathcal{R}^{\setminus\{m\}}\) | batch/reference latents | leave-one-out,避免样本 attend 自己 | method + appendix |
| Anchor | \(\bar{x}\) | cross-attention output | reference-induced mean anchor | SPG architecture |
| Refiner | \(f^\theta(\bar{x},x_t,t)\) | DiT-style transformer residual | 学会修正 anchor,不复制 nuisance | method |
| Loss | \(\mathcal{L}_\mu+\mathcal{L}_{ref}\) | scalar | endpoint prediction + residual learning | appendix C.1 |
| Output | generated image | decoded latent image | 可通过替换 reference set 控制 cats/dogs 组合 | results |
SPG 的流程更适合用训练/推理分开看:
| 阶段 | 发生了什么 | 为什么这样设计 |
|---|---|---|
| Training input | AFHQv2 图像编码成 VAE latents;对每个样本构造 \(x_t\) | 把普通图像分布转成 flow matching 的 endpoint prediction 问题 |
| Leave-one-out reference | 当前样本不能 attend 自己,只能看其它 reference latents | 防止模型退化成检索或泄漏答案 |
| Cross-attention anchor | 用 \(x_t\) 查询 reference set,得到 \(\bar{x}\) | 学一个类似 reference posterior mean 的 anchor |
| Residual refiner | DiT-style transformer 学 \(x^{(m)}-\bar{x}^{(m)}\) 的修正 | 保留有用参考属性,同时避免直接复制背景等 nuisance |
| Inference swap | 测试时换 cat-only / dog-only / mixed reference set | 不改模型参数,只改 reference distribution 控制输出 |
和 RMG 相比,SPG 多了一层学习能力。RMG 看到 reference bank 有白背景,可能把白背景也转移过去;SPG 的 refiner 有机会学会“动物属性该保留,背景偶然相关该压掉”。这是它存在的主要理由。
Training:监督信号、loss 和优化目标
RMG 没有训练阶段。它在 FLUX.2-klein 上做的是测试时修改 velocity。论文明确强调:prompt、noise seed、model weights 固定;没有 classifier、reward model、LLM、gradient computation 或 candidate selection。
SPG 才有训练。它的训练目标围绕 endpoint mean prediction。
第一部分是 endpoint prediction loss:
\[\mathcal{L}_{\mu}(\theta)= \mathbb{E}\left[ \sum_{m=1}^{M} \frac{1}{(1-t)^2} \left\| x^{(m)}-\mu_t^\theta(x_t^{(m)},\mathcal{R}^{\setminus\{m\}}) \right\|^2 \right].\]这里的 \(\frac{1}{(1-t)^2}\) 来自 endpoint-mean 参数化,对接近终点的误差更敏感。论文在训练里用 \(t\sim U[0,1-\epsilon]\),用 cutoff 避免 endpoint-weighted objective 发散。
第二部分是 refiner residual loss:
\[\mathcal{L}_{ref}(\theta)= \mathbb{E}\left[ \sum_m \left\| \mathrm{sg}[x^{(m)}-\bar{x}^{(m)}] - f^\theta(\mathrm{sg}[\bar{x}^{(m)}],x_t^{(m)},t) \right\|^2 \right].\]这个 loss 的存在很关键。anchor 本身已经很强,如果只靠 endpoint loss,refiner 可能没有足够梯度学会修正。作者用 stop-gradient 把 anchor 固住,让 refiner 学 ground truth 和 anchor 之间的 positive residual。
SPG 训练配置如下:
| 项目 | 论文公开配置 |
|---|---|
| Dataset | huggan/AFHQv2 full training split,dog + cat |
| Latent encoder | frozen REPA-E VAE encoder |
| Latent resolution | 256 x 256 latents,channel count not specified |
| Cross-attention | single block, patchwise retrieval, patch size 2, 8 heads, qk_dim 768, DB dropout 0.1 |
| Residual refiner | DiT-style transformer, 11 blocks, embedding dim 768, 12 heads, patch size 2, MLP ratio 4 |
| Gates | learned MLPs for \(g_t\) and \(\alpha_t\), initialized at 0.5 |
| Steps / hardware | 10,000 steps, 4 A100 GPUs |
| Batch / precision | batch size 64, bf16 mixed precision |
| Optimizer | Lion, lr 1e-4, beta1 0.9, beta2 0.999, no weight decay |
| EMA / clipping | EMA 0.9999, grad clip norm 1.0 |
| Other | refiner penalty weight 0.1, self-masking enabled |
这里我比较认可的设计是 leave-one-out。reference set 如果包含当前样本自己的 endpoint,模型很容易学成检索或泄漏;排除 \(x^{(m)}\) 以后,模型必须从其它样本里估计同一分布的 mean。
Inference:测试时到底怎么生成结果
RMG 的推理路径很短:
- 选一个 prompt 和 seed。
- 选一个 reference bank,比如 20 张 pink elephants。
- 用 FLUX.2 的 frozen VAE 把 reference images 编到和 sampler state 相同的 latent space。
- 每个采样时刻从 base velocity 得到 \(\mu_t^\theta=x+(1-t)u_t^\theta(x)\)。
- 对 reference latents 计算 posterior softmax,得到 \(\hat{\mu}_t^\rho\)。
- 用 \(\beta_t(\hat{\mu}_t^\rho-\mu_t^\theta)/(1-t)\) 修正 velocity。
- 解码得到输出图像。
FLUX.2 实验使用 resolution 768 x 768。默认 schedule 是 \(\beta_t=\beta_0(1-t)^2\),并在 \(t\geq0.85\) 后关闭 guidance。这个 cutoff 不是小细节,因为 correction 里有 \(1/(1-t)\),后期不关容易放大不稳定。
SPG 的推理路径不同。它不需要 closed-form posterior softmax 直接修正 velocity,而是把 reference set 送进训练好的 cross-attention anchor,然后由 refiner 输出 endpoint mean。推理时替换 reference set,就能让生成分布在 dog/cat 或更细的 reference composition 之间移动。
官方 GitHub repo 把实验分成四个目录:
| 目录 | 作用 |
|---|---|
moons/ | two-dimensional mechanism visualization |
mnist/ | sparse-reference guidance on MNIST zeros and ones |
rgm/ | RMG on frozen FLUX.2-klein |
spfm/ | SPG training and evaluation |
RMG 配置示例是:
cd rgm
./run.sh experiments/pink_elephant.yaml
SPG 训练则通过 Slurm 脚本或 dry-run 命令启动。论文和 README 都没有把这件事包装成“一键复现全部结果”,它更像一个按实验模块拆开的研究代码库。
Evaluation:验证集、指标和 baseline 是否公平
这篇论文的实验有三类证据,强度不同。
第一类是 mechanistic validation。Two moons 和 MNIST 的好处是后验均值和 flow field 可以画出来。two moons 里,数据集有 500 个样本,标签不暴露给模型,只在 inference 时用少量 labeled reference set 计算 soft posterior weights。改变 reference composition,flow field 和 trajectory 的 attractor 跟着变。这个证据很干净,因为它把复杂模型误差先拿掉了。
第二类是 frozen FLUX.2-klein 上的 qualitative 和 quantitative control。reference swaps、structural control、prompt-reference interaction 都在说明同一个点:reference set 是独立于 prompt 的控制轴。尤其 prompt-reference interaction 里,neutral elephant reference set 会压低 pink prompt 的粉色属性,pink elephant reference set 又能在 neutral prompt 下引入粉色属性。这说明它不是简单 prompt engineering。
第三类是 GenEval 和 SPG 的定量结果。GenEval 表比较的是不同控制接口,而不是“谁的视觉质量最高”。所有方法使用同一个 FLUX.2-klein backbone、resolution、sampler、steps、prompts 和 seeds;RMG 使用每个类别固定的 20-image visual reference bank;其它方法用自己的 text/search/gradient/classifier 接口。
| Method | Time | NFE | Aux evals | Mean | Two objects | Position | Attribution |
|---|---|---|---|---|---|---|---|
| FLUX.2-klein baseline | 1.00x | 1x | - | 80.10 | 91.41 | 65.25 | 58.75 |
| + Prompt Opt. | 7.87x | 8x | 8C+2L | 84.18 | 95.45 | 69.75 | 64.00 |
| + Best-of-4 | 4.07x | 4x | 4C | 83.35 | 95.96 | 67.75 | 65.25 |
| + SMC | 6.17x | 4x | 81C | 80.28 | 95.71 | 61.75 | 57.25 |
| + ReNO | 19.44x | 4x | 4C | 83.46 | 93.18 | 65.50 | 64.75 |
| RMG | 1.02x | 1x | - | 91.17 | 99.49 | 94.00 | 75.25 |
最扎眼的是 Position 从 65.25 到 94.00,Two objects 从 91.41 到 99.49。我的看法是,这张表最应该被理解为“visual reference bank 是一种高效控制接口”,而不是“RMG 在所有生成任务上都更强”。RMG 在这里拿到了额外的 visual bank,这和其它方法的控制信号不同;公平性在于 backbone、steps、seed 和 prompt 一致,不在于控制信号完全同质。
SPG 在 AFHQv2 上的表更像 sanity check:reference-conditioned 结构不能把无条件生成质量搞坏。
| Model | FID down | KID down | IS up |
|---|---|---|---|
| DiT-B/4 | 23.111 | 0.012 | 6.554 |
| SPG | 23.256 | 0.013 | 6.227 |
SPG 没有明显超过 DiT-B/4,但这不是它的主张。它要证明的是:加 reference anchor 和 refiner 以后,生成质量基本不掉,同时 reference set 还能在 inference time 控制输出分布。
实验与证据:哪些 claim 被支持,哪些还不够
我会把论文 claim 分成三档。
证据最强的是机制 claim:在 flow matching 里,endpoint mean 控制 velocity;reference set 改变 posterior mean 后,flow field 会变。这个由公式推导和 two moons/MNIST 实验同时支撑。
证据比较强的是低成本控制 claim:在 frozen FLUX.2-klein 上,RMG 可以不训练、不调用外部评估模型、不增加 NFE,在 GenEval 上提升 compositional categories。GenEval 表和 runtime/NFE 数字支撑得不错。
证据还不够充分的是结构控制泛化 claim:keyhole、hand、gymnastics 很有启发,但仍是少量 qualitative examples。论文也没有把结构控制做成大规模 benchmark。这里我不会把它读成“RMG 已经解决姿态控制”,更准确的说法是:它显示 reference-induced mean 对结构有可见影响,值得进一步量化。
还有一个很实际的 trade-off:reference quality 会直接进入生成质量。reference bank 如果脏、有偏或背景高度一致,RMG 可能把这些一起转移。论文在 appendix 用 white-background reference bank 展示了这个问题:RMG 会复制白背景,SPG 更能压住这个 nuisance artifact。
复现与工程风险
官方代码是公开的,而且 README 结构比较清楚。但复现要分层看。
轻量机制实验最容易复现:moons/ 和 mnist/ 基本是标准 Python 科学栈。它们适合先验证 posterior mean 和 reference composition 是否真的会改变 vector field。
RMG on FLUX.2-klein 需要更重的条件:
| 项目 | 风险 |
|---|---|
| Model access | 需要 black-forest-labs/FLUX.2-klein-4B 权限 |
| GPU / memory | FLUX.2 生成本身需要合适 GPU 环境 |
| Reference cache | paper reference banks 需要 make download,并会产生 latent/image caches |
| Latent shape | 论文说明 same packed latent representation,但没有在正文给出完整 tensor shape |
| Hyperparameters | 主实验 schedule、beta0、prompt 大多公开;部分工程默认值要看 repo config |
SPG 训练的复现门槛更高。论文公开了训练步数、batch、优化器、模型结构和数据集,但 4 A100、bf16、10k steps 不是随手就能跑的设置。好处是它没有依赖闭源数据,AFHQv2 和 REPA-E VAE 路径比较明确。
我会先复现 RMG 的一条小链路,而不是直接上 SPG:先跑 two moons,看 reference composition 是否改变 attractor;再跑 rgm 的 dry-run,确认 config、reference path、model access;最后选择一个最简单的 reference swap 任务,比如 pink elephant,验证 same prompt/seed/weights 下 reference bank 是否改变输出。
总结
这篇论文给我的主要启发是:有些控制问题不必急着做成“训练一个条件模块”。如果生成过程本身有一个可以被解释的统计对象,比如 flow matching 里的 endpoint mean,那么 reference set 就能成为很自然的控制接口。
RMG 的优点很清楚:轻、可换、无需训练、对小样本目标友好。它适合那些目标属性容易通过例子表达,但难以通过 reward 或 prompt 精确表达的场景,比如个性化风格、产品视觉规范、小样本身份/类别、空间关系模板、动作/姿态先验的粗控制。
它的问题也同样清楚。reference bank 不是魔法,它会把有用属性和偶然相关一起带进来。你给的是“白底猫”,模型可能学到的不只是猫,还有白底;你给的是某种手势,模型可能学到的是构图、光照或局部纹理,而不只是骨架结构。SPG 正是在补这个缺口:让模型学习从 reference mean 里筛掉 nuisance。
我觉得后续最有价值的方向有三个。
第一,把 reference bank 从手工选择变成可检索、可编辑的数据结构。RMG 的控制质量很大程度取决于 bank 质量,如果能做 automatic retrieval、bank cleaning、attribute disentanglement,这个接口会更实用。
第二,做更严肃的结构控制评测。现在 hand 和 gymnastics 结果很吸引人,但需要 pose estimator、keypoint metric、silhouette IoU 或人类偏好评估来验证边界。
第三,把它放到视频和 3D 生成里。视频里的 identity、style、motion prior、camera motion 都很适合用 reference set 表达,但时序一致性会放大 nuisance transfer 的问题。这里 RMG 可能提供一个简单起点,SPG 这类 amortized variant 可能更像长期方案。
如果只带走一句话,我会写成:Follow the Mean 把控制从“改模型”推向“改参考分布”。这不是所有控制问题的答案,但它给 flow matching 提供了一个很干净、很便宜、也很值得继续挖的控制接口。
参考来源
- arXiv:2605.10302v2:论文元信息、abstract、PDF 与 TeX source。
- Project page:官方项目介绍、交互式结果和代码链接。
- GitHub repo:实验目录、运行命令、reference bank 下载和复现说明。
- Hugging Face Demo:RMG on FLUX.2-klein 的在线 demo。
Recommended citation: Pedro M. P. Curvo, Maksim Zhdanov, Floor Eijkelboom, and Jan-Willem van de Meent. Follow the Mean: Reference-Guided Flow Matching. arXiv:2605.10302, 2026.
Download Paper