
SHARP:单张照片在一秒内变成可实时渲染的 3D Gaussian 场
SHARP:单张照片在一秒内变成可实时渲染的 3D Gaussian 场
论文:Sharp Monocular View Synthesis in Less Than a Second
作者:Lars Mescheder, Wei Dong, Shiwei Li, Xuyang Bai, Marcel Santos, Peiyun Hu, Bruno Lecouat, Mingmin Zhen, Amaël Delaunoy, Tian Fang, Yanghai Tsin, Stephan R. Richter, Vladlen Koltun
机构:Apple
时间 / 版本:2025-12-11 submitted,2026-02-27 v2;arXiv comments 标注 ICLR 2026
链接:Paper / PDF / Project / Code
检索日期:2026-05-23
开篇点评:这篇论文到底解决了什么问题
SHARP 解决的不是「从一张图生成一个可随意漫游的 3D 世界」。它把问题收得更窄:给定一张已有照片,在不到一秒内生成一个显式 3D 表示,让用户在照片附近做小幅相机运动时,仍然看到清晰、稳定、接近原图质感的 novel views。
这个边界决定了论文的技术路线。扩散式 view synthesis 可以用强先验补全看不见的区域,但每个视角都要生成,速度慢,附近视角也可能改写输入照片的细节。SHARP 选择先回归一个 3D Gaussian Splatting 表示,把主要计算花在一次性 representation synthesis 上;之后的相机移动就是 3DGS rendering。论文报告在 A100 上合成表示约 0.91 秒,后续 render 单帧通常是毫秒级。
我的判断是,这篇论文最值得看的地方不是「单图转 3D」这个宣传点,而是它把应用边界、表示形式和训练工程对齐得很清楚:目标是 AR/VR 或照片浏览里的 nearby parallax,不是远距离补全;表示要 metric,因为虚拟相机运动要能和真实设备运动对应;质量指标要偏向 perceptual fidelity,因为 1% 的几何错位不该被 PSNR/SSIM 夸大成灾难。
Paper Card
| 项目 | 信息 |
|---|---|
| Paper | Sharp Monocular View Synthesis in Less Than a Second |
| Authors | Lars Mescheder, Wei Dong, Shiwei Li, Xuyang Bai, Marcel Santos, Peiyun Hu, Bruno Lecouat, Mingmin Zhen, Amaël Delaunoy, Tian Fang, Yanghai Tsin, Stephan R. Richter, Vladlen Koltun |
| Date / Version | submitted 2025-12-11;last revised 2026-02-27, v2 |
| Venue / Status | ICLR 2026, per arXiv comments |
| Category | single-image view synthesis, 3D Gaussian Splatting, monocular depth, neural rendering |
| Project / Code | Project page / apple/ml-sharp |
| Model / Data | 官方 checkpoint 可由 CLI 自动下载;训练数据包含 in-house synthetic data 和商业授权 real images,未完整公开 |
| 复现状态 | inference path 可跑;完整训练复现受数据、算力、训练 pipeline 和模型许可限制 |
Abstract:论文摘要解读
原始摘要的核心信息可以拆成四层。
第一层是输入输出:SHARP 输入一张普通 RGB 照片,输出一组 3D Gaussians。论文明确给出输出规模:2 x 768 x 768,也就是约 120 万个 Gaussians;每个 Gaussian 有 14 个属性,包括位置、尺度、旋转、颜色和透明度。
第二层是速度:这个表示不是 per-scene optimization 的结果,而是一次 feedforward pass。表示生成完成后,新的附近视角不需要再跑 diffusion denoising,而是直接由 3DGS renderer 渲染。
第三层是 metric scale。SHARP 不只是做看起来像 3D 的图片变换,而是希望输出表示支持绝对尺度下的相机运动。这一点让它更贴近 AR/VR 头显或手持设备中的真实相机位移。
第四层是证据。论文在多个未参与训练的数据集上做 zero-shot evaluation,报告相对最强 prior model Gen3C,LPIPS 降低 25-34%,DISTS 降低 21-43%,同时把 synthesis time 降低约三个数量级。这个 claim 的适用范围是 nearby view synthesis;论文 supplement 也承认 faraway views 不是 SHARP 的设计主场。
Motivation
论文的 motivation 不是泛泛地说「单图 3D 很重要」,而是从一个具体使用场景出发:用户已经有大量照片,如果设备能把照片临时变成可交互 3D 内容,那么照片浏览就不再局限于固定 2D 平面。这个场景需要三件事同时成立。
第一,表示生成要快。照片浏览或头显交互不能等几分钟。
第二,附近视角要保真。用户做的是自然姿态变化,不是进入照片里绕场景走一圈;因此输入图中的细线、边缘、毛发、反射和局部纹理比远处幻想补全更重要。
第三,相机运动要有物理尺度。没有 metric scale,虚拟视角和真实设备位姿之间会脱节。
论文对 prior methods 的批评主要集中在这个边界内。多图 neural rendering 或 per-scene optimization 可以很强,但不适合单张照片即时转换。扩散式方法能处理更大视角变化,但 synthesis latency 高,且附近视角的锐利度和一致性不一定满足照片浏览体验。显式回归方法速度更近,但以往质量不足。SHARP 的设计就是在这三个方向之间选一个窄而硬的目标:single image in,metric 3DGS out,nearby views high fidelity。
直观效果:先看它能做什么

图:基于论文 TeX source 中 sec/abstract/figure_teaser.tex 的 includegraphics 上下文和 caption 重新排版。它对应论文 teaser 的 qualitative comparison,支持的理解点是 SHARP 在附近视角下尽量保留输入照片中的细结构,而不是用生成先验重写画面。
这张图不应该被读成「SHARP 在所有场景都视觉完美」。它更适合用来观察论文真正关心的失败模式:细绳、杯子边缘、毛发这类结构在相机轻微移动时最容易糊、断、漂。Flash3D 一类显式方法会出现明显模糊和形变;diffusion 方法可能更干净,但局部细节和原图一致性会被模型先验改写。SHARP 的优势正是在这个小范围视差里压住细节损失。
方法总览:核心思想和系统结构
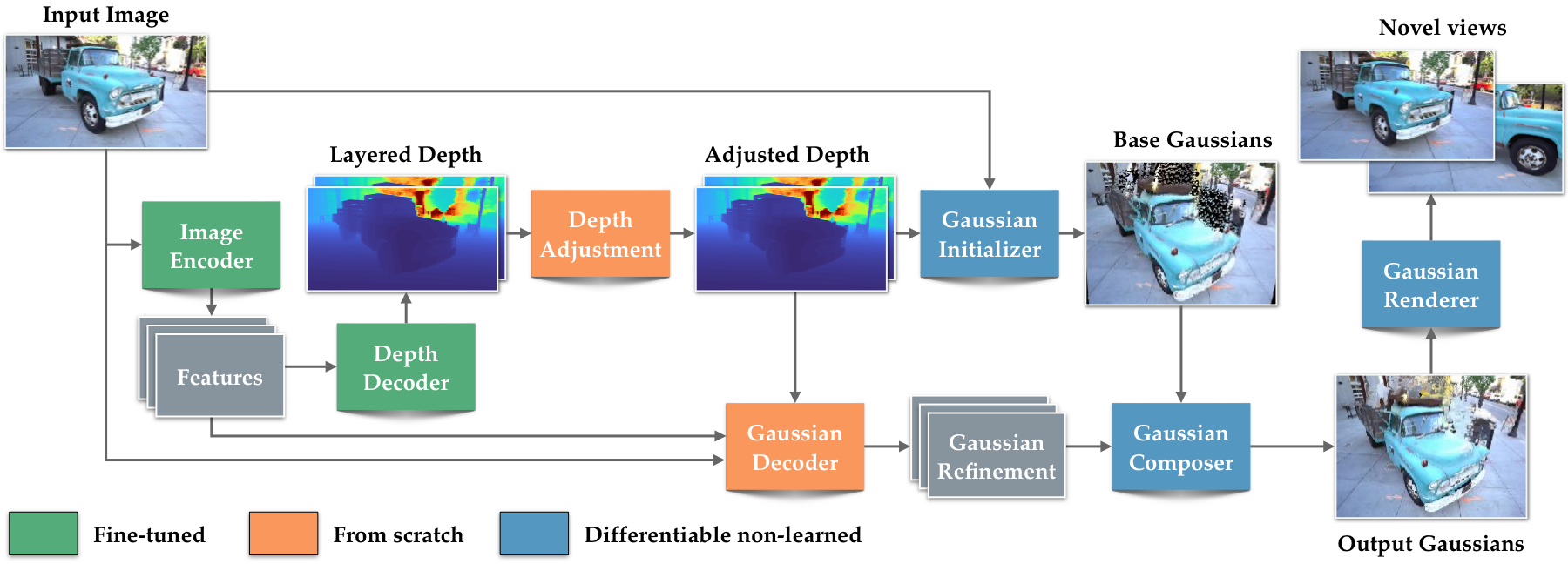
图:论文 Method Figure (figures/overview.pdf) 的官方 overview 渲染。caption 明确说明模型由四个 learnable modules 组成:pretrained image encoder、two-layer depth decoder、training-time depth adjustment module、Gaussian decoder;Gaussian initializer / composer / renderer 则负责把 depth 和 residual 组装成可渲染的 3DGS。这个图支撑的理解点是:SHARP 不是先估深度再离线转点云,而是让 depth、Gaussian attributes 和 differentiable rendering 在一个 view-synthesis 目标下共同训练。
SHARP 的结构看起来像「Depth Pro + Gaussian decoder」,但真正的设计点在模块连接方式上。Depth decoder 不是离线前处理;它的输出直接影响 Gaussian initializer,Gaussian decoder 又利用 encoder feature 和 depth 相关特征预测属性 residual。训练时,rendered input view 和 rendered novel view 都参与 loss,梯度会穿过 renderer 回到 depth 和 Gaussian 分支。
作者没有把 3DGS 当成稀疏点云,而是把每个输入像素附近都变成两层 Gaussian 候选。2 x 768 x 768 这个密度是论文重要贡献之一。ablation 显示从 2 x 192 x 192 提到 2 x 768 x 768,DISTS/LPIPS 持续改善;这说明 high-resolution explicit representation 不是装饰,而是保留照片细节的必要条件。
数据全流程:输入、表示、shape 和语义
| 阶段 | 对象 | Shape / Dim | 产生者 | 消费者 | 语义 |
|---|---|---|---|---|---|
| 输入 | inputImage | 3 x H x W,内部 1536 x 1536 | image loader / preprocessing | Depth Pro encoder, Gaussian decoder | 单张照片,全部 3D 信息的唯一观测 |
| 特征 | featureMaps | 4 maps,具体 spatial/channel shape not specified | Depth Pro encoder | depth decoder, Gaussian decoder | 多尺度视觉特征 |
| 深度 | predDepth | 2 x H x W | modified DPT depth decoder | depth adjustment, Gaussian initializer | 第一层主可见表面;第二层处理 occlusion / view-dependent effects |
| 调整 | scaleMap | H x W | training-only U-Net | adjusted depth | 用 GT depth 解决训练时单目深度歧义;推理时不用 |
| 初始 Gaussian | baseGauss | K x 2 x H' x W', K=14, H'=W'=768 | Gaussian initializer | composer | 从 depth 和 RGB 初始化 position / scale / color / rotation / opacity |
| 残差 | deltaGauss | K x 2 x H' x W' | Gaussian decoder | composer | 对所有 Gaussian 属性做 refinement |
| 输出 | finalGauss | 约 1.2M Gaussians | composer | renderer / .ply export | metric 3DGS 表示,可渲染附近视角 |
K=14 的拆分是 3D position、3D scale、4D orientation quaternion、RGB color、opacity。论文没有使用 spherical harmonics,因为 SH 系数会显著增加输出体积。这个取舍换来更小的输出和更快的渲染,但也意味着 view-dependent appearance 的显式表达能力受限,复杂反射和透明介质仍然容易成为长尾失败点。
Training:监督信号、loss 和优化目标
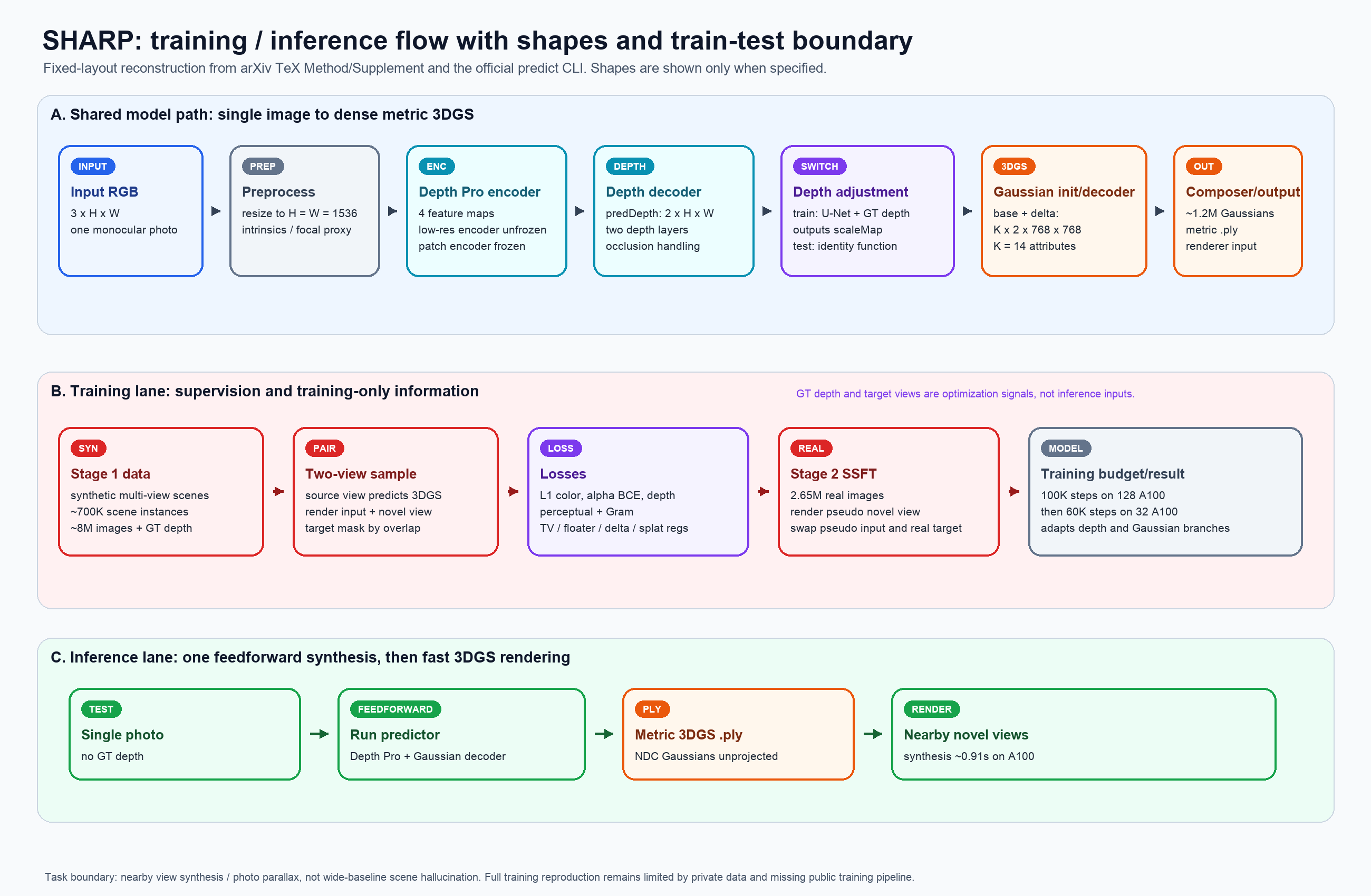
图:基于论文 Method、Supplement 和官方 predict.py 重绘的固定布局训练/推理流程图。它把 shared model path、training-only supervision 和 inference lane 分开,避免把 GT depth、target view、SSFT 这些训练信号误读成测试时输入。图里的 shape 只保留论文明确给出的部分;未公开的训练数据过滤、batch size、optimizer 等仍按 not specified 处理。
Stage 1 用 synthetic data 学基础 3D 重建。这个数据来自 Apple 内部 procedural generation system:2K+ outdoor、5K+ indoor artist-made scenes,加入数字人、衣物、头发、薄结构、透明/反射材料、HDR lighting,最后用 V-Ray 渲染。每个场景围绕目标物体放置 10 个虚拟相机,生成约 8M 高分辨率图像。
Stage 2 用真实照片做 self-supervised finetuning。论文的做法不是从单图集合里硬凑 stereo pair,而是先用 Stage 1 模型生成一个 3DGS,再渲染 pseudo novel view;随后把 pseudo novel view 当输入,真实原图当 target。这种 view swapping 逼模型适配真实图片分布,同时避免没有真实 stereo pair 的问题。
loss 设计比结构图更重要。L1 color 和 alpha BCE 保证基本重建;depth loss 只约束 input view 的第一层 depth;perceptual loss 和 Gram matrix loss用于 novel view 的可感知质量和 sharpness;TV、floater、delta offset、splat variance regularizers 用来压住漂浮物、极端 offset 和过大 Gaussian。补充材料还给了一个很工程化的细节:全图 perceptual loss 会让 ResNet-50 的计算图挂在 renderer 后面,A100 40GB、batch size 1 都可能 OOM;作者用 graph surgery 预计算 feature gradient、释放 ResNet 局部图,再把梯度注回主图。这个细节解释了为什么论文能在高分辨率、多视图监督下训练这种 dense 3DGS regression。
Inference:测试时到底怎么生成结果
官方 repo 的 CLI 和论文推理逻辑一致:输入一张图片,加载 checkpoint,构造 predictor,输出 .ply。
sharp predict -i /path/to/input/images -o /path/to/output/gaussians
src/sharp/cli/predict.py 里默认 checkpoint URL 是:
https://ml-site.cdn-apple.com/models/sharp/sharp_2572gikvuh.pt
推理路径里有几个容易忽略的工程细节。第一,图像会 resize 到内部 1536 x 1536。第二,代码用 focal length proxy 构造 disparity_factor,predictor 先输出 NDC space 中的 Gaussians。第三,后处理再根据 resized intrinsics 把 Gaussians unproject 到 metric space。第四,预测可以在 CPU、CUDA、MPS 上跑,但 --render 视频轨迹当前只支持 CUDA,因为它使用 gsplat renderer。
这个公开代码足够做 inference reproduction:单图进,.ply 出,再接常见 3DGS viewer 或官方 CUDA render path 做可视化。但它不等于完整训练复现,后面单独说。
Evaluation:验证集、指标和 baseline 是否公平
论文评测的是 zero-shot cross-dataset generalization。测试集包括 Middlebury、Booster、ScanNet++、WildRGBD、ETH3D、Tanks and Temples。作者明确不使用 RealEstate10K,因为它不是 metric dataset,而 SHARP 的目标包含绝对尺度下的相机运动。
多视图数据的 pair 选择也有边界:每个 sequence / scene 切成 10-view sets,计算 pairwise depth overlap,只保留 overlap 大于 60% 的 pair;每个 dataset 最多取 512 pairs。这个上限不是随意偷懒,supplement 给出的原因是 diffusion baselines 太慢。Gen3C 合成一个新视角大约 15 分钟,512 pairs 在 A100 上已经约 5 天。
指标方面,论文主用 LPIPS 和 DISTS。补充材料专门做了一个 1% translation 实验:图像只平移 1%,人眼看起来几乎一致,但 PSNR/SSIM 会掉到接近 mean image comparison 的水平。这对 view synthesis 很关键,因为小的几何错位不等于感知质量崩溃。作者仍然在 supplement 报 PSNR/SSIM,但不把它们作为主判断依据。
实验与证据:哪些 claim 被支持,哪些还不够
主表的结论很直接:SHARP 在六个数据集的 DISTS 和 LPIPS 上都排第一。
| Dataset | Gen3C DISTS / LPIPS | SHARP DISTS / LPIPS |
|---|---|---|
| Middlebury | 0.164 / 0.545 | 0.097 / 0.358 |
| Booster | 0.207 / 0.384 | 0.119 / 0.270 |
| ScanNet++ | 0.090 / 0.227 | 0.071 / 0.154 |
| WildRGBD | 0.106 / 0.285 | 0.069 / 0.190 |
| Tanks and Temples | 0.177 / 0.566 | 0.122 / 0.421 |
| ETH3D | 0.408 / 0.734 | 0.258 / 0.554 |
速度证据同样强。表中 SHARP inference 约 0.91s,render 单帧约 0.004s-0.022s,取决于原始分辨率。Gen3C 约 830s+,ViewCrafter 约 120s,SVC 约 57s-79s。因此「速度降低三个数量级」这个 claim 在论文的 evaluation protocol 下是有表格支撑的。
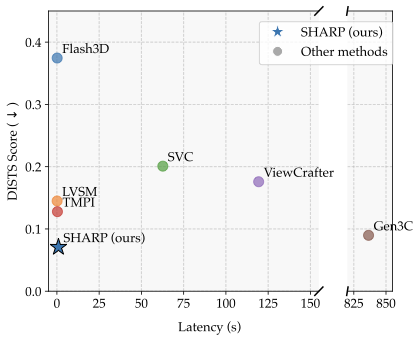
图:论文官方 figures/latency_comparison.pdf 转换结果,对应 Introduction 的 Figure 1。图中横轴是 synthesis latency,纵轴是 ScanNet++ 上的 DISTS,支持的理解点是 SHARP 的贡献是质量和交互延迟的组合,不只是某个单独指标。
ablation 更能说明哪些设计不是摆设。
| 组件 | 证据 | 判断 |
|---|---|---|
| perceptual + Gram loss | ScanNet++ DISTS 从 0.162 降到约 0.063/0.064;Tanks and Temples 从 0.239 降到约 0.126 | L1 / depth 不足以产生锐利 novel view;feature-space 监督是高保真的主要来源 |
| learned depth adjustment | ScanNet++ DISTS 0.077 -> 0.064;Tanks 0.148 -> 0.126 | 单目 depth ambiguity 会污染 3DGS 初始化;训练时的 posterior-like correction 有实证收益 |
| unfreeze monodepth backbone | ScanNet++ DISTS 0.084 -> 0.064;Tanks 0.139 -> 0.126 | depth backbone 需要适配 rendering objective,冻结 depth 不是最优 |
| Gaussian 数量 | 2 x 192 x 192 到 2 x 768 x 768 持续改善 DISTS/LPIPS | dense 3DGS output 是保留照片细节的实质条件 |
| SSFT | 指标不总是稳定提升,但 qualitative 更锐利 | 真实照片里的反射、透明和复杂材质仍需要 synthetic 之外的分布适配 |
证据不够强的地方也要保留。第一,训练数据的核心部分是 in-house,无法独立验证数据分布是否覆盖了评测集的关键难例。第二,evaluation 为了 diffusion baseline 成本限制到每个 dataset 最多 512 pairs,不是全量 exhaustive benchmark。第三,论文在 motion range 分析里承认,设计目标是 <0.5m 左右的 nearby views;大位移、低重叠时,diffusion 方法的生成先验可能更合适。
深度歧义:为什么 Depth Pro 还不够

图:基于 supplement Depth Estimation Uncertainty 小节中的四张图重组。caption 说明作者用原图、Depth Pro prediction、水平翻转后预测再翻回、relative absolute error 来展示单目深度不确定性;这张图支持的理解点是 depth 错误会在物体边界和复杂结构处放大成 view synthesis artifact。
单目深度估计不是简单的回归问题。多种 3D 结构可以投影成同一张 2D 图,depth model 往往会给一个平均合理的答案。对 depth benchmark 这可能还行;对 view synthesis,平均深度会把边界、遮挡和细结构变成漂浮物或撕裂。
SHARP 的 depth adjustment 模块只在训练时使用。它用 predicted inverse depth 和 GT inverse depth 产生 scaleMap,把预测 depth 局部缩放到更适合 view synthesis 的位置。作者把这个设计类比为 C-VAE posterior 的简化版本:不学 latent vector,而是学一个受 regularizer 限制的尺度图。推理时没有 GT depth,所以该模块必须退化为 identity。这一点很重要:它不是测试时外挂,而是训练时帮助网络跨过单目歧义的辅助通道。
复现与工程风险
官方 repo 的公开程度足够支撑 inference reproduction。README 给出 conda create -n sharp python=3.13、pip install -r requirements.txt 和 sharp predict。公开 tree 里有 src/sharp/cli、src/sharp/models、src/sharp/utils,predict.py 会自动下载 checkpoint 并保存 3DGS .ply。这部分可以直接做 smoke test。
完整训练复现是另一回事。
- Stage 1 synthetic data 是 Apple 内部 procedural generation system,包含 artist-made environments、V-Ray rendering、数字人和多种材质,未公开。
- Stage 2 real data 包含 OpenScene,以及 Shutterstock、Getty Images、Flickr 的商业授权照片,总计 2.65M images;具体清单、过滤策略和可复现下载方式没有完整公开。
- 训练算力是 128 A100 训练 100K steps,再用 32 A100 训练 60K steps。
- 公开 repo 主要是 inference / network / model code,没有完整训练 pipeline。
LICENSE_MODEL限制模型用于 research purposes。把官方 checkpoint 用进产品或服务前,需要单独处理许可边界。
工程上还有一个坐标系细节:README 说明输出 .ply 遵循 OpenCV coordinate convention,场景中心大致在 (0, 0, +z)。接第三方 3DGS renderer 时,可能需要 scale / rotate / recenter。这类问题不是论文指标能覆盖的,但会直接影响实际 demo 体验。
总结
SHARP 的价值在于证明:当任务边界是 nearby view synthesis,而不是大范围场景补全时,feedforward explicit 3D representation 仍然很有竞争力。它没有把所有希望押在更大的生成模型上,而是认真处理了几个常被低估的工程点:dense Gaussian output、depth backbone adaptation、training-only depth adjustment、perceptual loss 的计算图内存、regularizers 对 floater 和 render speed 的影响。
它的边界也很清楚。大位移、低重叠、强反射、透明材质、浅景深 macro photo、星空这类 depth failure 场景仍然容易失败。论文自己也把 future work 指向了 diffusion prior 和 view-dependent / volumetric effects。我的看法是,SHARP 不是 diffusion view synthesis 的替代品,而是另一个更适合交互式照片 3D 化的路线:快速、metric、锐利,但不承诺无限想象。
如果要继续用这篇论文做工程实验,最实际的下一步不是复现训练,而是跑官方 checkpoint:用自己的照片生成 .ply,检查坐标、尺度、nearby camera path、细结构保持、反射/透明失败模式,再决定是否值得把它接进 AR/VR photo browsing、3D 相册、轻量空间照片预览或 3DGS viewer 工作流。完整训练复现当前资料不够,适合做 partial reproduction,不适合直接立成可复现训练项目。
Recommended citation: Mescheder et al., Sharp Monocular View Synthesis in Less Than a Second, ICLR 2026
Download Paper