
AsymFlow:把 latent flow 拉回 pixel space 的低秩速度参数化
AsymFlow:把 latent flow 拉回 pixel space 的低秩速度参数化
论文:Asymmetric Flow Models
作者:Hansheng Chen, Jan Ackermann, Minseo Kim, Gordon Wetzstein, Leonidas Guibas
时间 / 版本:arXiv v1, submitted on 2026-05-13
类别:Computer Vision and Pattern Recognition
链接:Paper / Project / Code / Model / Demo
开篇点评:这篇论文到底解决了什么问题
AsymFlow 讨论的是一个很直接但长期不好处理的问题:如果不经过 VAE latent,而是让生成模型直接在 pixel space 里建模,plain transformer 怎么承受高维噪声预测?
latent diffusion 的优势很清楚:维度低、训练便宜、Transformer 容易扩展。但它也把低层细节交给固定 decoder,模型本身不能直接控制最后的 pixel texture、edge、颜色微结构。回到 pixel space 可以绕过固定 decoder,但会碰到另一个瓶颈:flow matching 常用的 velocity target 是 $u=\epsilon-x_0$,它要求模型同时预测结构化数据项和 full-rank Gaussian noise。对 latent token 来说这还可以;对 $16 \times 16 \times 3 = 768$ 维的 pixel patch 来说,噪声维度会明显污染网络内部表示。
这篇论文的关键判断是:pixel data 虽然高维,但重要变化并不是 full-rank 的。模型不必在所有维度都做 velocity-style noise prediction。AsymFlow 让 data term 保持 full-rank,只把 noise term 限制到一个 patch-wise low-rank subspace,然后用解析公式恢复 full velocity。我的判断是,这个工作有意思的地方不只是 ImageNet FID 或 T2I 分数,而是它把“pixel generation 太难”拆成了“哪些子空间需要 velocity,哪些子空间更适合 clean-data prediction”的问题。
Paper Card
| 项目 | 信息 |
|---|---|
| Paper | Asymmetric Flow Models |
| Authors | Hansheng Chen, Jan Ackermann, Minseo Kim, Gordon Wetzstein, Leonidas Guibas |
| Date / Version | arXiv v1, submitted on 2026-05-13 |
| Category | cs.CV |
| Project / Code | Project, LakonLab |
| Model / Demo | AsymFLUX.2-klein-9B, HF Space |
| 核心 claim | low-rank noise + full-rank data 的 asymmetric velocity target 能提升 pixel-space flow modeling,并支持 latent-to-pixel finetuning |
| 复现状态 | 官方代码、adapter、demo 已发布;ImageNet 和 T2I 配置可见;T2I 数据准备 README 仍未完全闭环 |
| 检索日期 | 2026-05-24 |
Abstract:论文摘要解读
论文的 abstract 可以拆成两个问题。
第一,直接在高维空间做 flow-based generation 很难,因为 velocity prediction 需要模型预测高维 noise。即使真实数据有强 low-rank structure,标准 $u=\epsilon-x_0$ target 还是把 full-rank noise 放进预测目标里。AsymFlow 用 rank-asymmetric velocity parameterization 解决这个问题:noise 只保留低秩投影 $P\epsilon$,data term 仍然是 full-dimensional $x_0$。网络输出的是 asymmetric velocity $u_A=P\epsilon-x_0$,再解析恢复 full-dimensional velocity,所以不需要改网络架构,也不需要改 flow matching 的训练/采样流程。
第二,AsymFlow 给出了一条把 pretrained latent flow model finetune 成 pixel-space model 的路径。作者用 Procrustes alignment 把 latent space 对齐到 pixel patch 的低秩子空间,使初始化后的 pixel model 继承 latent model 的语义和布局;finetuning 主要修正 low-level pixel projection gap,而不是从头学习图像生成。论文在 ImageNet 256x256 上报告 1.57 FID,并将 FLUX.2 klein 9B finetune 成 AsymFLUX.2 klein,声称在 HPSv3、DPG-Bench 和 GenEval 上超过其 latent base。
Motivation
论文的 motivation 不是简单说 pixel space 更细节,而是指出现代 scalable transformer 在 pixel space 里缺少 U-Net 那种 natural bypass。传统 DDPM/ADM U-Net 可以通过 skip connection 把 noisy input 的局部信息送到输出端;许多 pixel transformer 方法则加 U-ViT-like hierarchy 或 decoder/refiner head。它们有效,但会破坏 plain transformer recipe 的简洁性。
另一条路线是 $x_0$-prediction:不直接预测 Gaussian noise,而是预测 clean image,再通过 $(x_t-\hat{x}_0)/\sigma_t$ 转回 velocity。问题在低噪声端,$\sigma_t$ 很小,除法会让误差放大。因此 $u$-prediction 和 $x_0$-prediction 在 high-dimensional generation 中各有缺陷:前者目标太吵,后者低噪声数值条件差。
AsymFlow 的中间路线是:
low-rank subspace: velocity-like prediction
orthogonal complement: x0-like prediction
这样既保留 velocity target 在关键低秩方向上的优势,又避免在所有 pixel dimensions 上预测 full-rank noise。
直观效果:先看它能做什么

图:论文中的 T2I qualitative comparison。它支持的不是“所有 prompt 都更好”这种泛化结论,而是作者关于 pixel-space AsymFLUX.2 klein 在纹理、真实感和局部细节上更强的视觉 claim。
这组图的意义在于,它把 AsymFlow 的工程目标说得很直观:不是训练一个小型 pixel diffusion demo,而是拿已经很强的 FLUX.2 klein latent model,当作初始化基础,转成一个仍然有大模型语义能力的 pixel generator。作者希望 pixel model 的收益体现在低层视觉真实感,而不是重新学习 composition。
方法总览:核心思想和系统结构
标准 flow matching 设
\[x_t = \alpha_t x_0 + \sigma_t \epsilon,\qquad u = \frac{x_t-x_0}{\sigma_t} = \epsilon - x_0\]令 $A \in \mathbb{R}^{D \times r}$ 是 rank-$r$ orthonormal basis,$P = AA^T$ 是对应 projection。AsymFlow 不让网络预测 $u$,而是预测
\[u_A = P\epsilon - x_0\]注意这里很关键:只投影 noise,不投影 data。于是:
\[P u_A = P\epsilon - P x_0 = Pu,\qquad (I-P)u_A = -(I-P)x_0\]也就是说,低秩子空间里它还是 velocity prediction;正交补空间里它退化成 clean-data prediction。网络输出 $\hat{u}_A$ 后,full velocity 由下式恢复:
\[\hat{u} = P\hat{u}_A + \frac{(I-P)(x_t+\hat{u}_A)}{\sigma_t}\]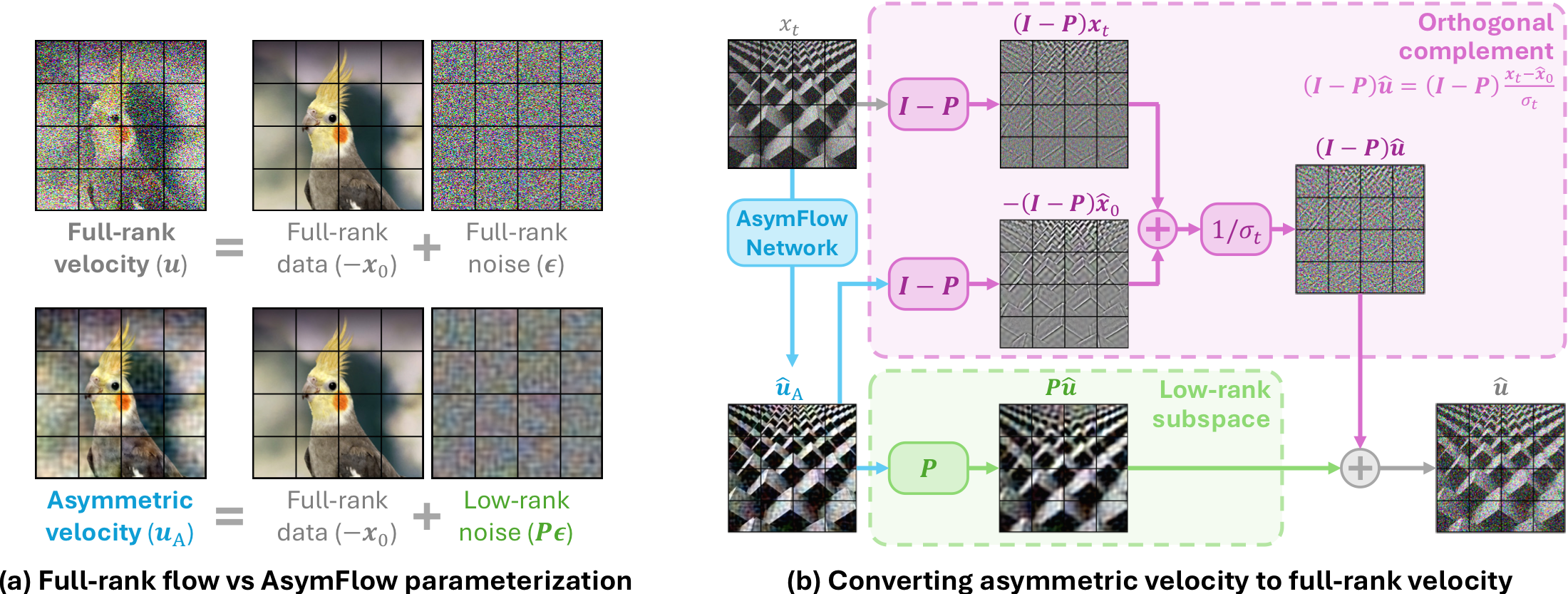
图:论文中的 AsymFlow parameterization and recovery figure。左侧说明 standard velocity 和 asymmetric velocity 的 target 差异;右侧说明网络输出 $u_A$ 后如何分解并恢复 full-rank velocity。这个图是理解论文的主图。
AsymFlow 因此可以被看成一族参数化:$r=0$ 时等价于 $x_0$-prediction;$r=D$ 时恢复成 full $u$-prediction;中间 rank 则在两者之间折中。
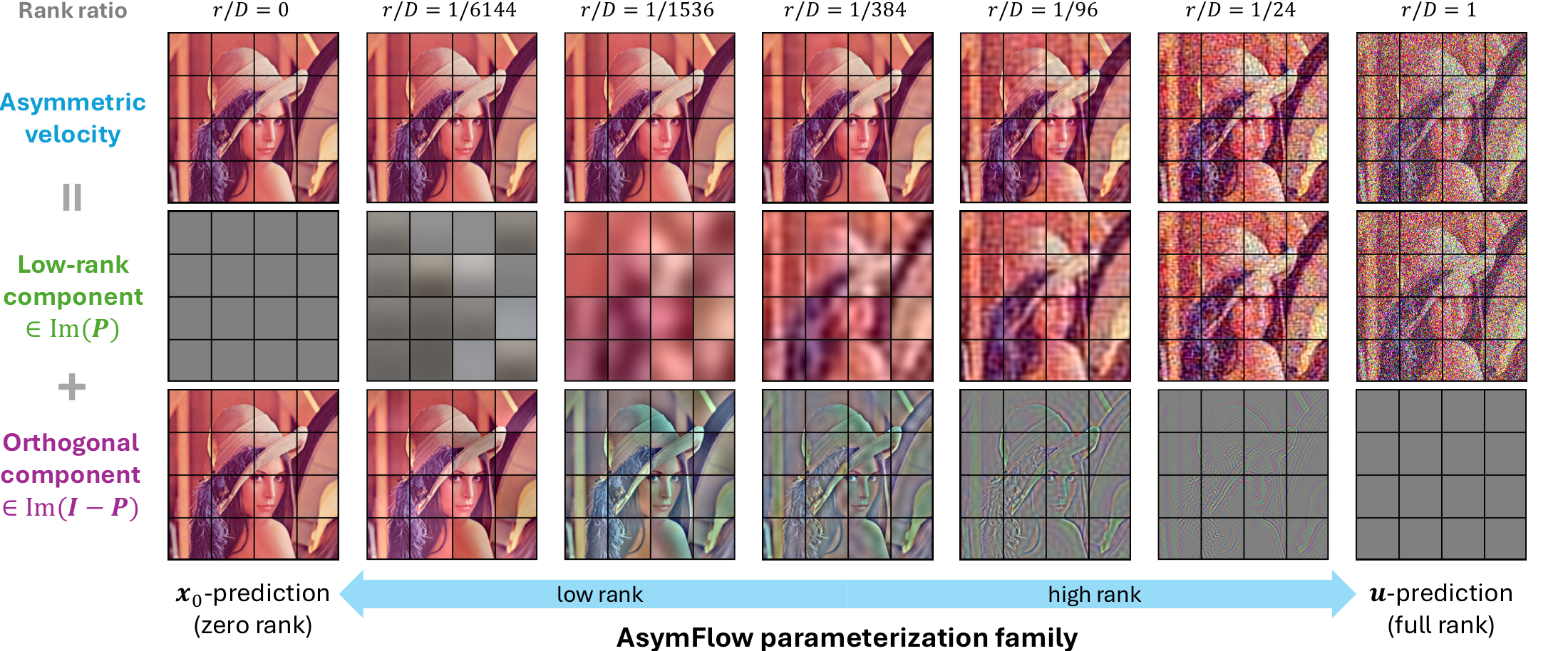
图:论文中的 parameterization family figure。它把 rank 从 0 到 full rank 的变化可视化:rank 越高,low-rank branch 越像 full velocity;rank 越低,orthogonal branch 越接近 $x_0$-prediction。
数据全流程:输入、表示、shape 和语义
| 阶段 | 对象 | Shape / Dim | 语义 | 产生者 | 消费者 |
|---|---|---|---|---|---|
| 原始数据 | $x_0$ | ImageNet: 3 x 256 x 256; T2I: 1MP mixed aspect ratio | full-rank pixel target | dataset image | forward process |
| patch token | pixel patch | $D=16 \times 16 \times 3=768$ | 每个 patch 的高维像素向量 | patchify | PCA / Procrustes / transformer |
| noise | $\epsilon$ | same as $x_0$ | Gaussian noise | training sampler | velocity target |
| low-rank basis | $A$ | ImageNet: 768 x 8; FLUX.2: 768 x 128 | patch-wise low-rank subspace | PCA or Procrustes | projection $P=AA^T$ |
| noisy state | $x_t$ | same as $x_0$ | flow interpolation state | $\alpha_t x_0+\sigma_t\epsilon$ | AsymFlow network |
| asymmetric target | $u_A$ | patch dim $D$ | low-rank noise + full-rank data | $P\epsilon-x_0$ | prediction target |
| full velocity | $u$ | patch dim $D$ | standard flow velocity | analytic recovery | FM loss / sampler |
| lifted pixel | $x_0^L$ | full pixel shape, low-rank content | latent model lifted into pixel subspace | $sAz_0$ | initialization / VR loss |
从零训练时,$A$ 来自 image patch PCA;latent-to-pixel finetuning 时,$A$ 来自 latent tokens 和 pixel patches 的 orthogonal Procrustes alignment。后一种情况还需要 scale calibration,因为 Procrustes 只对齐方向,不保证 lifted pixels 的幅值和真实 pixels 一致。
Training:监督信号、loss 和优化目标
ImageNet from scratch
ImageNet 实验主要为了隔离 AsymFlow parameterization 本身。作者使用 JiT-H/16 的架构和训练设置,只改变 prediction target。主设置是 patch size 16、$D=768$、PCA subspace rank $r=8$,并用 flow matching loss 训练。600 epochs 训练约 1750 NVIDIA H100 GPU hours。
这个实验最重要的地方在于公平性:如果架构、训练 recipe、evaluation protocol 尽量不变,那么差异更可能来自 target parameterization,而不是新 decoder head 或额外架构容量。
FLUX.2 klein latent-to-pixel finetuning
T2I 部分更像工程系统。作者从 black-forest-labs/FLUX.2-klein-base-9B 出发,把 latent patch dimension $d=128$ 对齐到 pixel patch low-rank subspace,因此 pixel patch rank 也设为 128。pixels 用 normalized Oklab color space,patch size 16,训练数据是 3M LAION-Aesthetics images,resize 到 one-megapixel resolution,并用 Qwen2.5-VL caption。

图:论文中的 latent-to-pixel initialization 可视化。初始化后的 low-rank pixel sample 在语义和布局上与 decoded latent sample 对齐,但保留明显低层 projection gap,这正是后续 finetuning 要修正的部分。
训练时 base weights 冻结,只更新:
| 组件 | 设置 |
|---|---|
| projection / output | x_embedder, proj_out, norm_out |
| LoRA | rank 256, dropout 0.05 |
| LoRA targets | FFN in/out, context FFN in/out, timestep embedder, single transformer block attention output |
| optimizer | 8-bit Adam |
| batch size | 256 |
| iterations | 15K |
| cost | about 1100 NVIDIA H100 GPU hours |
| sampler | UniPC |
| guidance | APG orthogonal-projection guidance, scale 4.0 |
Variance-reduced loss
latent-to-pixel 初始化得到的是 lifted low-rank pixel target $x_0^L=sAz_0$,它和 full pixel target $x_0$ 有结构相关性。作者把 $x_0^L$ 当成 control variate:理论上可以加入
\[\lambda\left(x_0^L-\mathbb{E}[x_0^L\mid x_t]\right)\]来降低 target variance 而不改变 conditional mean。实际训练中条件期望不可得,所以用 frozen initialized low-rank model 在 paired noisy low-rank sample $x_t^L$ 上的预测 $\hat{x}_0^L$ 近似。官方代码 lakonlab/models/diffusions/asymflow.py 的 AsymFlowVR.forward_train 会计算 low-rank residual 和 full-rank residual 的 patch-wise projection coefficient,并 clamp 到 [0, 1]。
这个近似有代价:在低噪声区域,$\mathbb{E}[x_0^L\mid x_t] \approx \mathbb{E}[x_0^L\mid x_t^L]$ 不再严格成立,会把误差带进 low-rank subspace。论文因此加了 LPIPS perceptual correction,用一个 time-dependent fading schedule 从 VR term 过渡到 perceptual term。

图:论文中的 finetuning ablation。VR loss 增强细节但也引入噪声;LPIPS correction 的作用是压掉这种低噪声端的误差,同时保留更锐利的 texture。
Inference:测试时到底怎么生成结果
ImageNet 推理使用 50-step Heun ODE solver、BF16 inference 和 attention upcasting。AsymFlow 在恢复 velocity 时仍需要对 $\sigma_t$ 做 clamp;论文报告最优 sigma_min=0.04,并强调 AsymFlow 对关闭 clamp 的退化小于 JiT,因为只有 orthogonal branch 需要通过 $1/\sigma_t$ 转换。
T2I 推理不需要 VAE decode,因为输出直接在 Oklab pixel representation 中;每个采样步把 denoised pixels 转为 RGB 并 clamp 到有效范围,再转回 Oklab velocity。官方 README 给了 Diffusers-style pipeline:加载 FLUX.2 klein Base 9B,再加载 Lakonik/AsymFLUX.2-klein-9B adapter。Hugging Face 上也有公开 Gradio demo。
Evaluation:验证集、指标和 baseline 是否公平
ImageNet 使用 ADM evaluation protocol,并对 CFG scale 和 guidance interval 做 grid search。这里有一个细节:论文表中标注了 JiT evaluation protocol 可能比 ADM protocol 好约 0.08 FID,所以作者在 ImageNet comparison 中把协议差异写出来,这是比较表里比较诚实的一点。
T2I 分两类评测:
| 评测 | 数据 / 指标 | 目的 |
|---|---|---|
| system-level comparison | HPSv3, DPG-Bench, GenEval at 1024 x 1024 | 和主流 latent / pixel T2I 系统比较 |
| controlled ablation | COCO-10K captions; HPSv3, HPSv2.1, VQAScore, CLIP, FID, pFID | 排除 dataset finetune 和 loss 组件带来的混淆 |
这套评测能支撑“visual quality / preference 变好”的 claim,但不能完全替代真实人评、安全评测、文字渲染、复杂组合关系和版权/数据偏差分析。
实验与证据:哪些 claim 被支持,哪些还不够
ImageNet 结果
| Method | 设置 | FID | IS |
|---|---|---|---|
| JiT, $r=0$ | sigma_min=0.04 | 1.90 | 300.8 |
| AsymFlow, $r=8$ | sigma_min=0.04 | 1.76 | 312.0 |
| JiT, $r=0$ | no clamp | 3.27 | 286.7 |
| AsymFlow, $r=8$ | no clamp | 2.28 | 306.2 |
这个结果说明两件事。第一,rank-8 asymmetric target 在同样 plain transformer 架构下确实提升质量。第二,AsymFlow 仍然需要 clamp,但对低噪声端的数值退化更不敏感。
rank ablation 更能解释为什么它有效:PCA subspace 的 rank 从 0 增加到 8 时 FID 下降明显,继续增大反而略差;random subspace 接近 baseline。这说明收益不是“随便降维”,而是必须把 noise 约束到有意义的数据相关子空间。
![]()
图:论文中的 rank/PCA ablation。rank-8 PCA subspace 最好,random subspace 明显差,支持“低秩子空间必须有语义/数据结构”的设计判断。
Text-to-image 结果
system-level 表中,AsymFLUX.2 klein 在 HPSv3、DPG-Bench、GenEval 上都超过 FLUX.2 klein Base,也超过 PixelDiT-T2I。controlled ablation 更关键:
| Method | HPSv3 | HPSv2.1 | VQA | CLIP | FID | pFID |
|---|---|---|---|---|---|---|
| FLUX.2 klein Base + latent finetune | 10.70 | 0.290 | 0.936 | 0.276 | 15.0 | 18.8 |
| FLUX.2 klein Base + DDT finetune | 10.33 | 0.291 | 0.922 | 0.273 | 20.4 | 26.0 |
| AsymFLUX.2 klein, standard FM | 12.03 | 0.293 | 0.922 | 0.277 | 20.2 | 25.4 |
| AsymFLUX.2 klein, VR | 12.99 | 0.296 | 0.925 | 0.280 | 18.5 | 27.8 |
| AsymFLUX.2 klein, VR + LPIPS | 13.06 | 0.297 | 0.925 | 0.278 | 19.1 | 22.5 |
我的解读是:AsymFlow 的收益主要体现在 human preference 和 texture realism,而不是所有 distribution metric 都单调更好。latent finetune 的 FID/pFID 很强,但 HPSv3 低;AsymFlow 的 HPSv3 高很多,但 FID 不是最优。这与论文强调的“pixel model 改善低层真实感”一致,也提醒我们不要只用单一指标判断。
复现与工程风险
官方 repo 已经可用,不是只有 paper claim。LakonLab README 给了 AsymFlow 文档、Diffusers-style inference pipeline、ImageNet training/evaluation 命令、T2I config 和 AsymFLUX.2 klein HF adapter。代码中关键位置包括:
| 目的 | 文件 |
|---|---|
| PCA subspace | tools/asymflow_subspace_pca_dit.py |
| Procrustes latent-to-pixel subspace | tools/asymflow_subspace_procrustes.py |
| shared velocity recovery | lakonlab/models/architectures/asymflow/common.py |
| JiT wrapper | lakonlab/models/architectures/asymflow/asymjit.py |
| FLUX.2 wrapper | lakonlab/models/architectures/asymflow/asymflux2.py |
| VR + perceptual loss | lakonlab/models/diffusions/asymflow.py |
| pixel FLUX.2 pipeline | lakonlab/pipelines/pipeline_pixelflux2_klein.py |
但完整复现仍然不轻:
- ImageNet 需要 8 GPU 对齐 batch size 1024,完整训练约 1750 H100 GPU hours。
- T2I 需要 FLUX.2 klein 权重、3M LAION-Aesthetics 子集、Qwen2.5-VL caption、Procrustes projection checkpoint 和约 1100 H100 GPU hours。
- README 当前写明 AsymFLUX.2 klein training 的 data preparation instructions will be added soon;也就是说,T2I 训练数据闭环还不完整。
- HF model card 标注 license 为
flux-non-commercial-license,工程应用前必须单独检查授权。
总结
AsymFlow 的价值在于,它没有把 pixel generation 的困难归结为“加更大模型”或“加 decoder head”,而是从 flow target 本身切入:高维 pixel patch 中,并不是每个方向都值得做 full noise velocity prediction。把 low-rank subspace 里的 velocity branch 和 orthogonal complement 里的 $x_0$ branch 合在一起,既保持了 standard flow matching 的训练/采样接口,又降低了 plain transformer 的表示负担。
这条路线对 FLUX.2 klein 的 latent-to-pixel finetuning尤其重要。通过 Procrustes lift,pretrained latent model 可以先变成一个数学上耦合的 low-rank pixel model,再用 finetuning 修正低层细节。它比“从头训练 pixel model”现实,也比“给 latent model 加后处理 decoder”更接近真正的 pixel generator。
仍然要保留几个不确定性:linear lift 是否适合所有 latent representation;VR loss 的近似误差是否能更严格地处理;HPSv3 提升是否能稳定对应真实用户偏好;以及这种更高 photorealism 的模型如何和 provenance、watermarking、safety filters 一起部署。作为研究方向,它最值得借鉴的是低秩子空间建模视角:在视频、3D、音频这类高维生成里,也许问题不是要不要回到原始空间,而是如何只在真正需要随机速度的子空间里建模。