
Code as Agent Harness:把代码看成 Agent 的运行底座
Code as Agent Harness:把代码看成 Agent 的运行底座
论文:Code as Agent Harness: Toward Executable, Verifiable, and Stateful Agent Systems
作者:Xuying Ning, Katherine Tieu, Dongqi Fu, Tianxin Wei, Zihao Li, Yuanchen Bei et al.
机构:University of Illinois Urbana-Champaign / Meta / Stanford University
时间 / 版本:arXiv v1, submitted on 2026-05-18
类别:Computation and Language, Artificial Intelligence
链接:Paper / PDF / Project / GitHub
开篇点评:这不是一篇“更强 coding agent”的论文,而是在给 agent 工程重新命名
这篇 102 页 survey 的核心价值不是提出一个新模型,也不是在 SWE-bench 上刷一个更高分。它做的是一个概念重组:过去我们习惯把 code 理解成 LLM 的输出,比如“模型会写 Python”“模型能修 bug”。这篇文章反过来问:如果 agent 的推理、动作、环境状态、记忆、验证、协作都越来越依赖代码,那么 code 是否已经变成了 agent 的运行底座?
作者把这个底座叫做 code as agent harness。这里的 harness 不是单个 prompt,也不是一个工具列表,而是围绕 LLM 的软件层:工具、API、sandbox、memory、validator、permission boundary、execution loop、feedback channel,以及被 agent 创建、执行、观察、修改、持久化和共享的代码制品。换句话说,真正让一个 stateless model 变成 long-running agent 的,不只是模型能力,而是这套可执行、可检查、可保存状态的系统。
我的判断是,这篇 survey 最值得读的地方在于它把很多分散概念连起来了:Program-of-Thought、tool calling、SWE-agent、OpenHands、GUI agent、科学发现 agent、multi-agent code collaboration、harness engineering、sandbox、telemetry、permission gate,都可以放进同一个问题里讨论:agent 如何通过可执行代码和可验证反馈控制自己的行为轨迹。
Paper Card
| 项目 | 信息 |
|---|---|
| Paper | arXiv:2605.18747, PDF |
| Project / Code | Project Page, GitHub paper list |
| Authors | Xuying Ning, Katherine Tieu, Dongqi Fu, Tianxin Wei, Zihao Li, Yuanchen Bei et al. |
| Institutions | UIUC, Meta, Stanford |
| Type | Survey / taxonomy / research roadmap |
| Main claim | Code is not only an output artifact; it is an executable, inspectable, and stateful harness substrate for agentic AI |
| 核心结构 | Harness Interface, Harness Mechanisms, Scaling the Harness |
| 证据类型 | 文献分类、系统归纳、应用域分析、开放问题总结 |
| 复现状态 | 不适用:不是算法论文;GitHub repo 提供持续更新的 paper list |
Abstract:论文摘要解读
摘要的意思可以压成一句话:随着 LLM 进入 agentic system,code 的角色已经从“被生成的结果”扩展成“agent 与外部世界交互的操作介质”。它能让推理变成可执行程序,让动作变成 API / script / command,让环境状态变成 repo、trace、test、log、simulator,让 verification 从自然语言自评变成可运行的检查。
文章围绕三层展开。第一层是 harness interface:code 如何连接 reasoning、acting 和 environment modeling。第二层是 harness mechanisms:planning、memory、tool use、Plan-Execute-Verify loop、Agentic Harness Engineering 如何支撑长程执行和反馈修正。第三层是 scaling the harness:多 agent 系统如何围绕共享代码制品进行分工、协作、审查和状态同步。
注意,这里没有新的训练 loss,也没有新的 benchmark protocol。它的贡献是提出一个解释框架,让我们能用同一套语言讨论 Codex、Claude Code、OpenHands、SWE-agent、GUI automation、scientific agents、robotic code policies 和 multi-agent software engineering。
Motivation:为什么需要“harness”这个视角
很多 agent 讨论容易把问题归因到 base model:模型不够聪明、上下文不够长、推理不够稳定。但实际工程里,agent 失败往往不只是模型生成错了,而是整个运行闭环缺了某个关键部件。
比如一个 coding agent 修 bug 时,真正影响结果的不只是 patch 生成能力,还包括它能不能定位相关文件、能不能读到项目约定、能不能安全执行测试、能不能把失败日志压缩成可用证据、能不能避免重复尝试同一个坏方向、能不能区分普通本地修改和需要用户批准的高风险操作。这里的每个环节都不是单纯“LLM reasoning”,而是 harness design。
论文把 code 放到这个视角下,有三个理由:
| 性质 | 对 agent 的意义 |
|---|---|
| Executable | 模型输出可以被解释器、shell、browser、robot runtime 或测试框架真正执行 |
| Inspectable | 中间状态、变量、trace、diff、log、test result 可以被读取和诊断 |
| Stateful | repo、脚本、测试、memory、workflow、skill library 可以跨步骤保留和演化 |
这三点让 code 不只是“程序文本”,而是 agent 的操作界面。自然语言可以描述意图,但很难直接提供可重复执行、可审计、可回滚的状态转移;代码和代码邻近制品则可以。
方法总览:三层 taxonomy
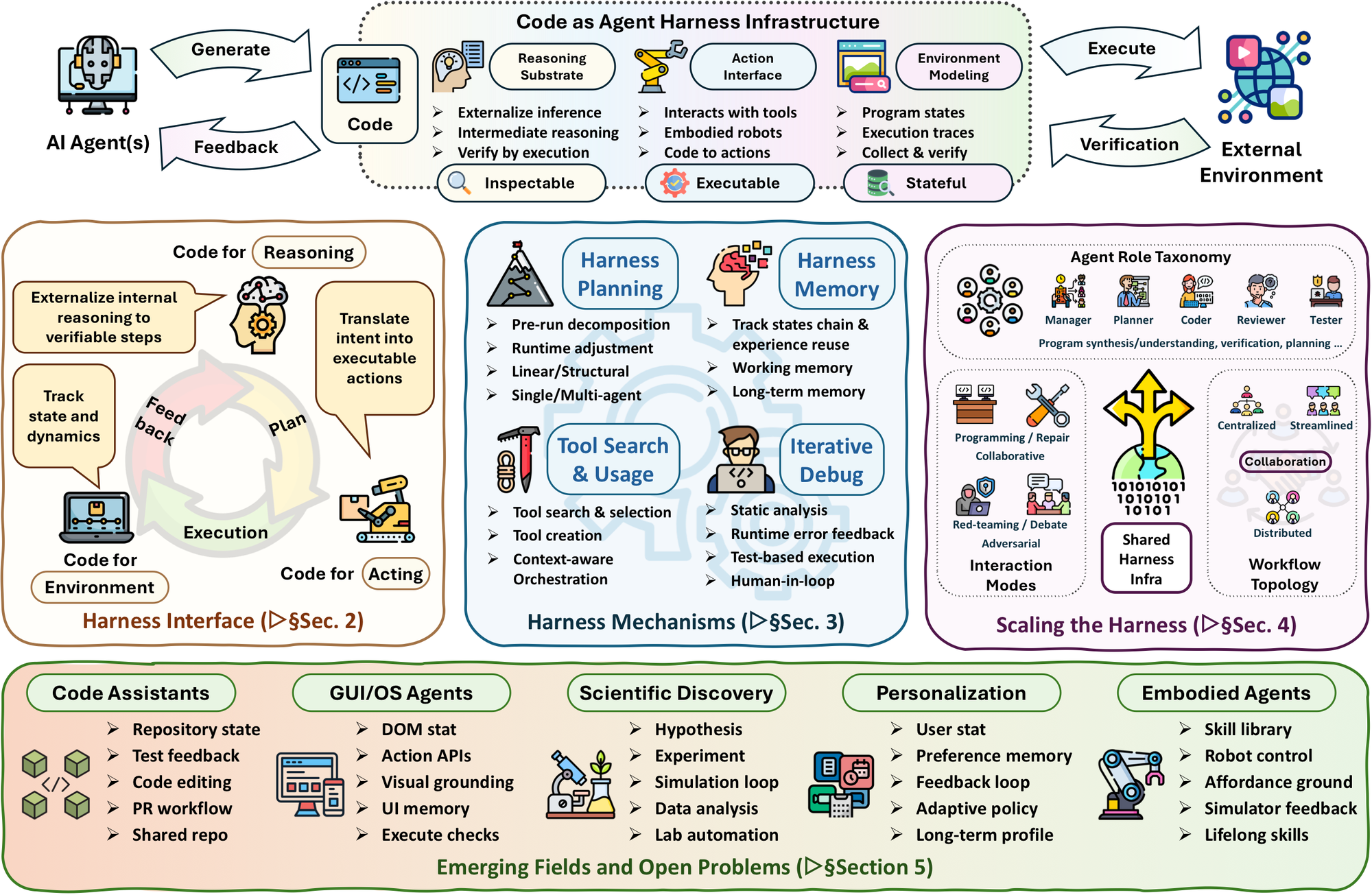
图 1:论文的核心 taxonomy。它把 code-as-harness 分成 interface、mechanisms、scaling 三层,并把应用域连接到 coding assistant、GUI/OS agent、scientific discovery、personalization 和 embodied agent。
这张图是全篇的主干。作者的组织方式不是按“模型类型”分类,而是按 code 在 agent loop 中承担的系统角色分类。
第一层 Harness Interface 回答:code 如何把模型和任务环境接起来。这里 code 有三个角色:
| Interface role | 解决的问题 | 典型形式 |
|---|---|---|
| Code for Reasoning | 把模型内部推理外部化,让计算和逻辑可执行、可验证 | Program-of-Thought, PAL, symbolic solver, proof script, execution trace |
| Code for Acting | 把高层 intent 转成环境里的可执行动作 | tool call, Python/JS script, GUI action, robot policy, behavior tree |
| Code for Environment Modeling | 把环境状态和反馈表示成可检查对象 | repository, tests, logs, simulator, DOM, accessibility tree, execution trace |
第二层 Harness Mechanisms 回答:一旦 code 进入 agent loop,系统怎样保持长程可靠性。这里包括 planning、memory、tool use、PEV loop 和 harness optimization。
第三层 Scaling the Harness 回答:当多个 agent 一起操作代码时,如何用共享代码制品协调角色、状态、验证和收敛目标。这里代码不只是工作对象,也是多 agent 的共享状态和通信介质。
Harness Interface:代码让推理、动作和环境状态进入同一个闭环
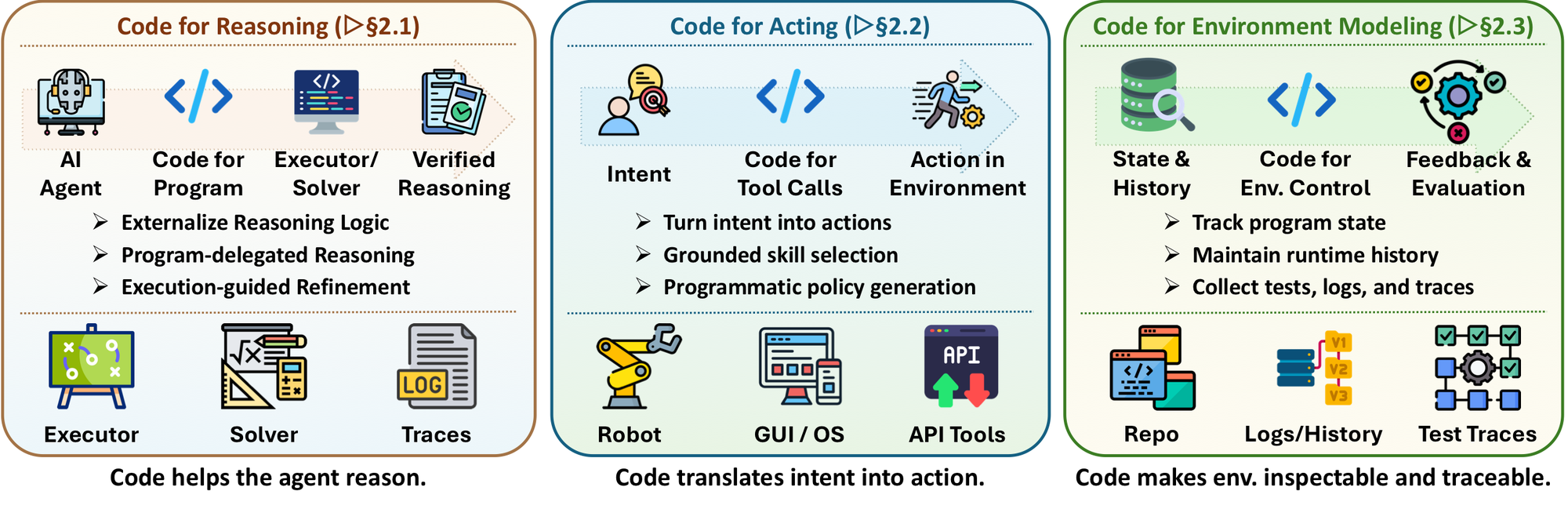
图 2:Harness interface。Code for reasoning 把内部逻辑变成可执行计算;Code for acting 把 intent 变成 tool/API/GUI/robot action;Code for environment modeling 把 repo、log、test、state history 变成可追踪环境。
Code for Reasoning 最容易理解。Program-aided Language Models、Program-of-Thought、Chain of Code 这类工作,本质上都是让模型别在自然语言里硬算,而是生成一段可执行程序,把具体计算交给 interpreter。它的关键好处不是“代码更像数学”,而是 execution trace 可以成为反馈信号:程序跑错了,可以定位变量、分支、异常和测试结果。
Code for Acting 则把 code 当成动作接口。GUI/OS agent 可以输出 Playwright、pyautogui 或 accessibility API 调用;robot agent 可以输出 policy code、behavior tree 或 primitive skill;软件 agent 可以输出 shell command、patch、test command。这样 agent 的动作不再是抽象描述,而是环境里的可执行操作。
Code for Environment Modeling 更接近 agent 工程的核心。一个 repo、DOM tree、trace log、test suite、simulator,不只是背景信息,它们就是 agent 所处世界的可查询状态。模型看不到完整世界,只能通过这些 code-defined state 观察、推断和行动。
这里有一个边界很重要:论文没有把一切都叫 code。raw perception、physical state、human intent、model latent reasoning 本身不是 code;它们可以被 code 序列化、估计、验证或操作,但不能和 code interface 混为一谈。这个边界让“code as harness”不至于变成泛泛隐喻。
Harness Mechanisms:真正的 agent 能力来自闭环控制面
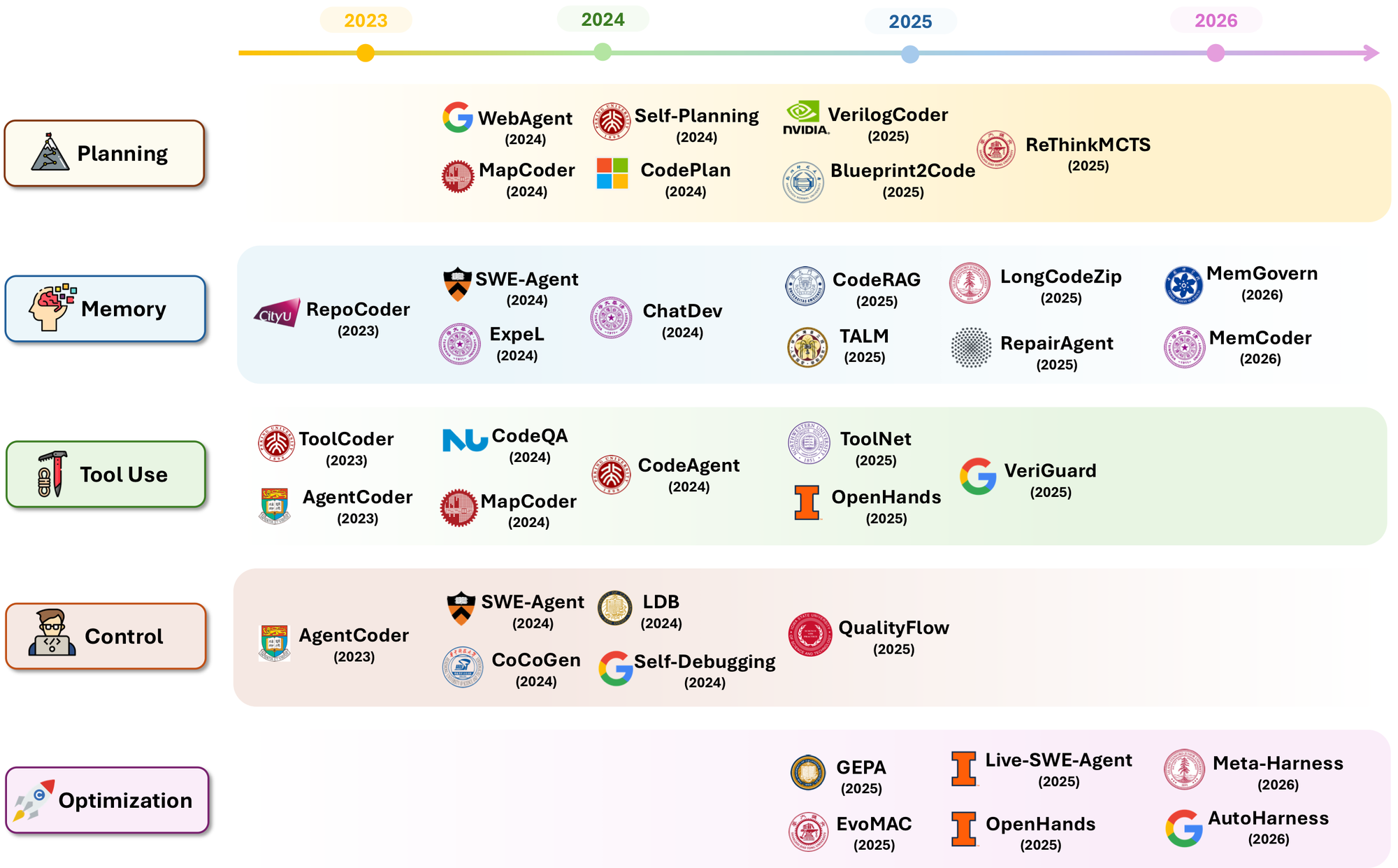
图 3:Harness mechanisms roadmap。论文把 planning、memory、tool use、control、optimization 放在同一层里,强调它们都是长程 agent 的控制面,而不是互不相关的小模块。
文章对 mechanism 的归纳很实用,因为它把很多工程组件放回同一条执行链里看。
Planning 不是简单写一个任务列表,而是决定 agent 下一步应该读什么、改什么、运行什么、何时放弃当前路径。论文把 planning 分成 linear decomposition、structure-grounded planning、search-based planning、orchestration-based planning。对代码任务来说,最有价值的是后两类:结构化计划可以利用 repo graph、dependency graph、call relation、测试关系来限制动作空间;搜索式计划则把多个候选 patch / plan / trace 保存成可比较的状态,而不是一次生成到底。
Memory and Context Engineering 解决的是模型上下文窗口和任务状态膨胀之间的矛盾。作者把 memory 分成 working memory、semantic memory、experiential memory、long-term memory、multi-agent memory。这个分类比“加个向量库”更准确:working memory 管当前任务证据,semantic memory 管 repo 结构和代码证据,experiential memory 管历史失败/成功经验,long-term memory 管跨任务可复用知识,multi-agent memory 管多个 agent 共享状态。
Tool Use 则是 action space 的治理问题。工具越多不一定越好,关键是工具 schema、权限、状态暴露、反馈质量和调用边界是否清楚。一个工具如果只返回长日志而没有结构化错误,agent 仍然很难用;一个高权限工具如果没有审批和审计,就会把模型错误直接放大成系统风险。
PEV Loop:把 debugging 提升为 harness-level control
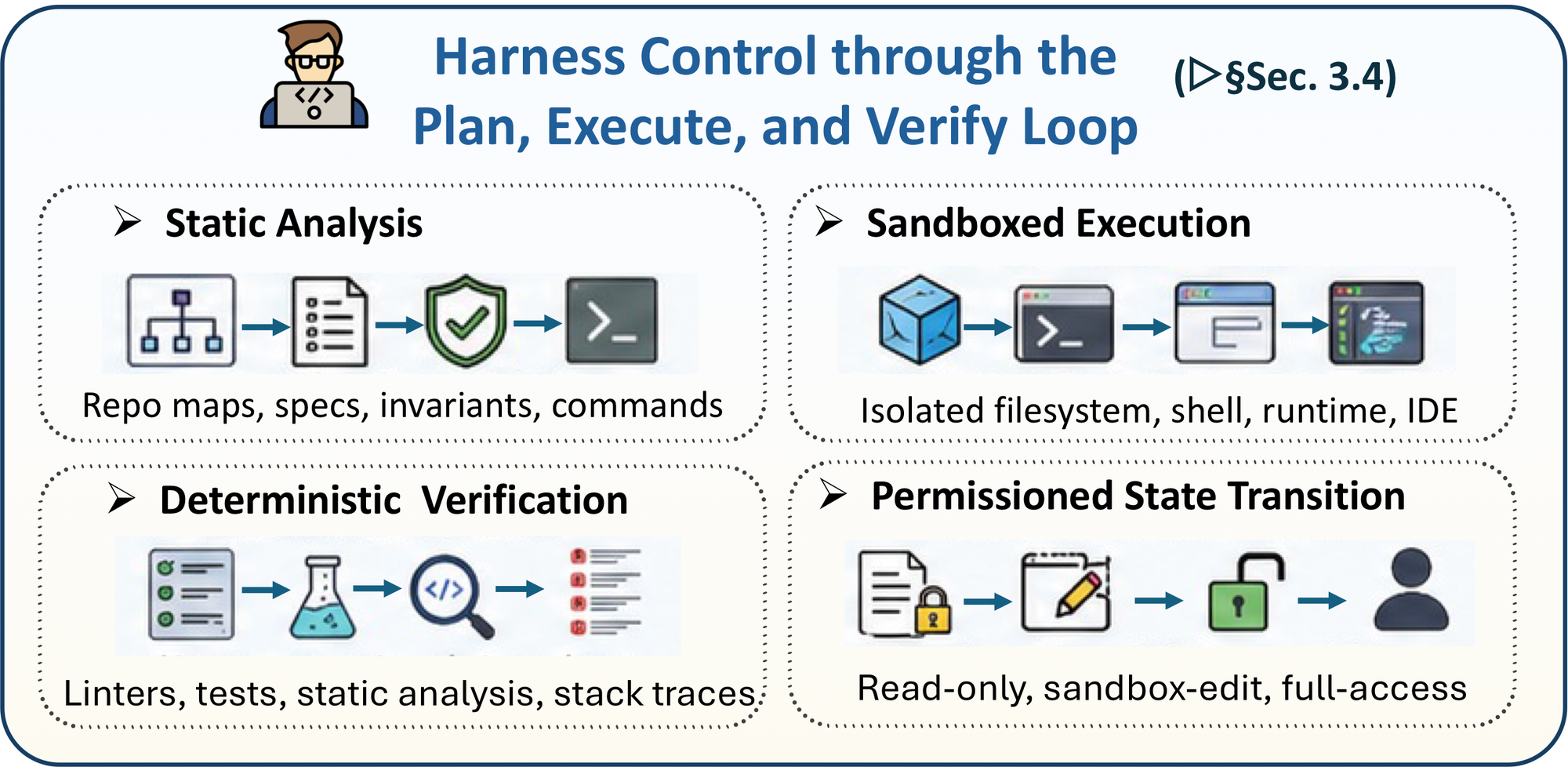
图 4:Plan-Execute-Verify loop。论文把 static analysis、sandboxed execution、deterministic verification、permissioned state transition 统一成 agent harness 的控制循环。
论文最工程化的一段是 PEV loop。这里的 PEV 不是普通“先计划、再执行、再验证”的流程图,而是在说 agent 的每一次行动都应该是一个受控的 state transition。
Plan 阶段形成 contract:要改哪些文件,预期保持什么 invariants,怎样验证,哪些操作有风险,失败时怎么回滚。计划不是模型心里的 chain-of-thought,而应该是可审计的 harness artifact。
Execute 阶段必须在 sandbox 和 permission tier 里发生。read-only、sandbox-edit、full-access 这些权限层要分清楚:读文件和跑静态分析是低风险;改本地文件和运行测试是中风险;联网、部署、发包、访问凭证、改 Git 历史、操作生产环境就是高风险,需要 human-in-the-loop gate。
Verify 阶段不应只靠模型自评。论文强调 deterministic sensors:parser、compiler、type checker、unit test、integration test、linter、security scanner、runtime monitor、CI pipeline、coverage、fuzzer。它们把“我觉得修好了”变成“哪些证据支持当前状态可接受”。
这个 framing 对 coding agent 很有用。很多失败不是因为模型不知道怎么修,而是因为 harness 没有把计划、执行和验证串成一个可回放的控制系统。没有 PEV,agent 只是不断生成 patch;有了 PEV,agent 才是在带约束地推进系统状态。
Agentic Harness Engineering:下一步不是只优化 prompt,而是优化 harness 本身
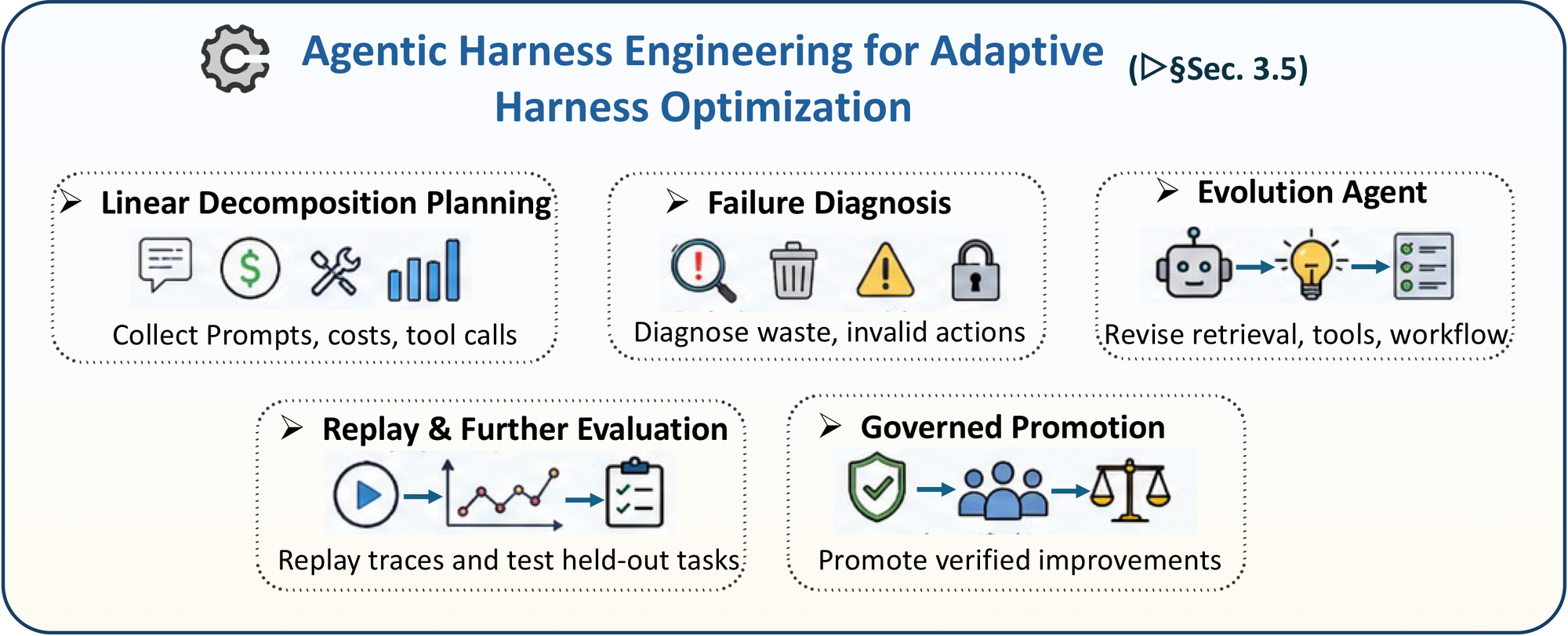
图 5:Agentic Harness Engineering。论文把 telemetry、failure diagnosis、Evolution Agent、replay evaluation、governed promotion 看成 harness 自我改进的基本流程。
这篇 survey 里比较前沿的概念是 Agentic Harness Engineering。它把优化对象从 prompt 扩展到整个 harness:tool schema、retrieval policy、memory rule、sandbox config、validator、permission tier、routing rule、multi-agent workflow、human-review gate 都可以被测量和改进。
核心材料是 deep telemetry。浅层日志只记录最终是否成功;deep telemetry 要记录 prompt、retrieved context、token cost、latency、tool arguments、permission request、edited files、sandbox snapshot、command output、test result、stack trace、branch decision、human intervention 和最终 outcome。只有这些轨迹足够结构化,系统才知道失败到底来自模型、上下文、工具、权限、测试、workflow,还是环境噪声。
论文提出的 Evolution Agent 不是直接修改业务代码的 agent,而是修改 agent 运行条件的 meta-agent。它看历史轨迹,诊断失败模式,提出 harness 改动,比如改工具说明、加 validator、调 retrieval、修改 retry limit、插入 HITL gate,然后在 held-out tasks 或 replay traces 上验证,只有不回归才推广。
这里最大的风险也很明显:self-evolving harness 不能变成不受控的自我修改。harness mutation 本质上是对安全关键 runtime 的代码改动,必须有 change contract、regression suite、rollback、approval 和审计记录。否则它可能用更弱的 verifier 换来更高的 pass rate,或者用更高权限换来表面成功。
Scaling the Harness:多 agent 的关键不是“人多”,而是共享程序状态
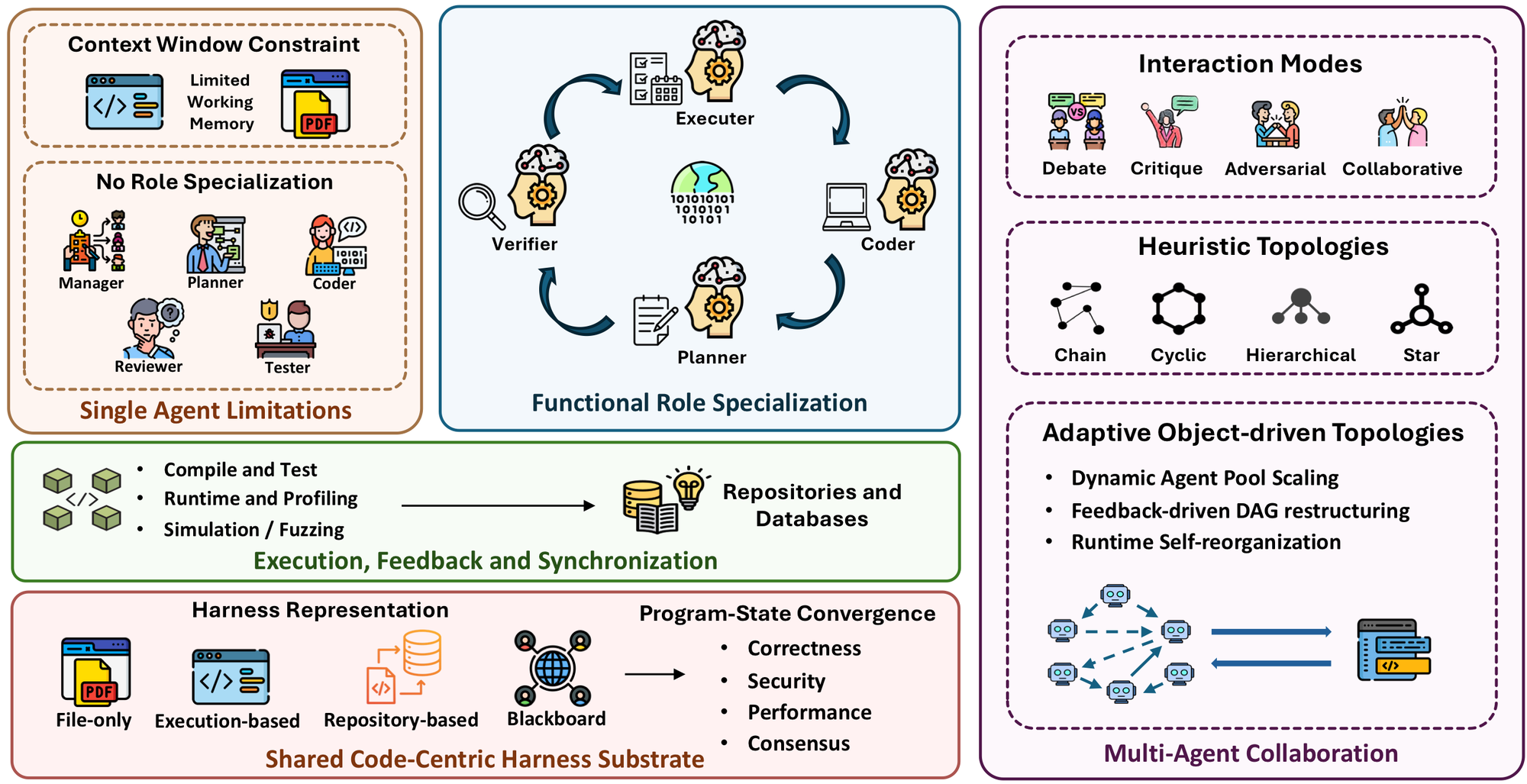
图 6:Multi-agent harness。多 agent 系统通过 planner、coder、verifier、executor 等角色分工缓解单 agent 的上下文、专业化和自检限制,但真正困难在共享代码状态的同步和收敛。
论文对 multi-agent 的看法比较克制。多 agent 的价值不是简单多叫几个模型互相聊天,而是把单 agent 的三个瓶颈拆开:一个 agent 很难同时持有完整上下文、承担所有专业角色、并独立发现自己的错误。角色分工可以让 planner、coder、tester、reviewer、executor 各自聚焦不同视角。
但多 agent 也带来新的系统问题。共享代码制品不是天然一致的:planner 可能基于旧 repo snapshot 制定计划,coder 已经改了实现,tester 运行的是另一个状态,reviewer 记住的是过时 invariant。论文把这个问题提升为 shared code-centric harness substrate:多 agent 需要的不只是共享聊天记录,而是共享 repo state、execution traces、tests、logs、blackboard、versioned artifacts 和 convergence target。
这和真实软件工程非常接近。协作不是靠“大家都说一遍”实现的,而是靠版本控制、测试、review、CI、issue、design doc、rollback、ownership 和权限规则实现的。agent 系统如果要进入真实工程,也必须学会这些机制,而不是只在 prompt 里模拟一个团队。
应用域:这套框架能解释哪些 agent
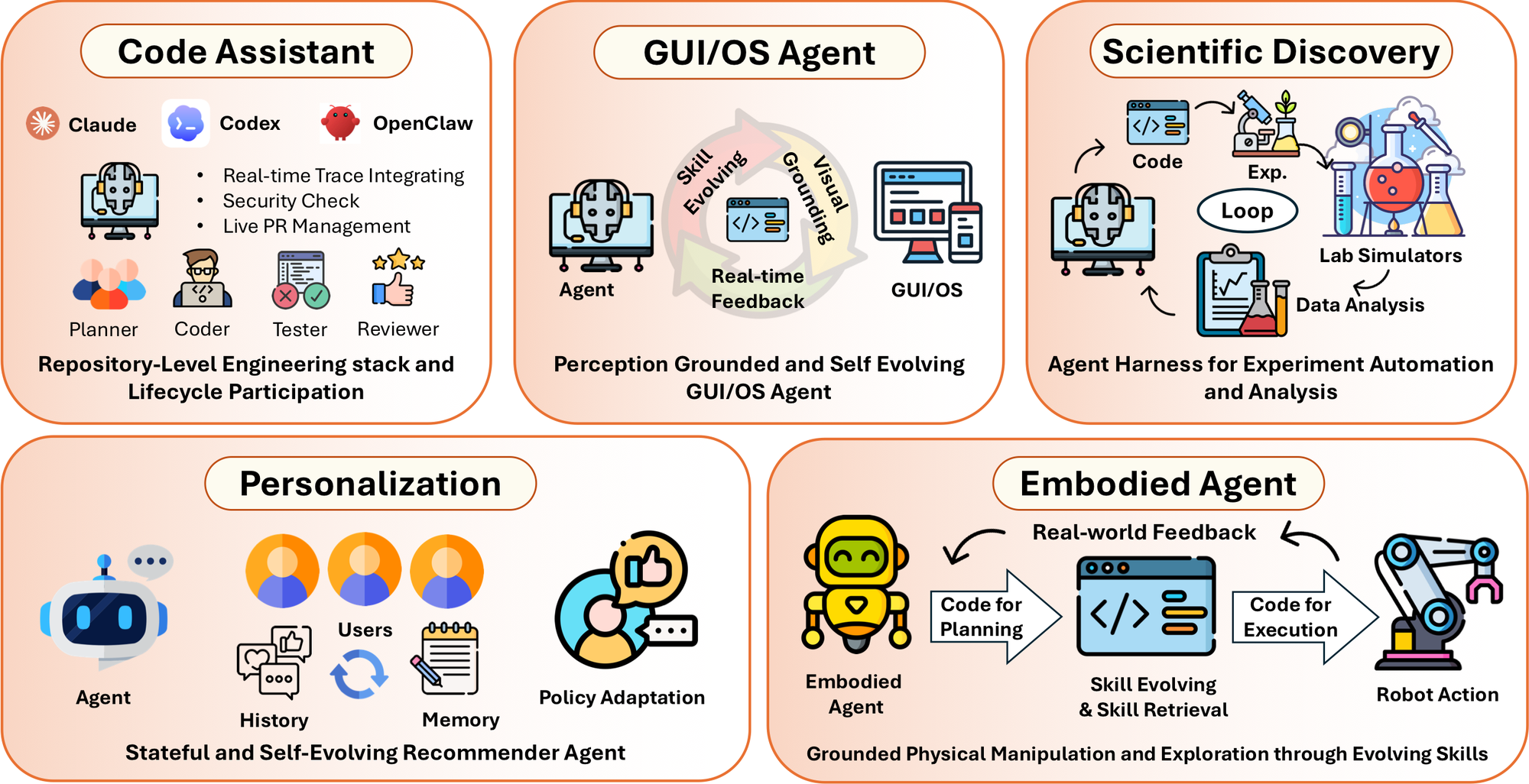
图 7:应用域。论文把 code assistant、GUI/OS agent、scientific discovery、personalization、embodied agent 都看成 code-as-harness 的不同落点。
这篇文章的应用部分很长,真正有用的是看它如何把不同 agent 统一成“程序世界”。
Code Assistant 是最直接的例子。Codex、Claude Code、OpenHands、SWE-agent、GitHub Copilot coding agents 都不是单次 code completion;它们运行在 repo、branch、diff、test、CI、PR、issue、terminal、sandbox、review gate 构成的 harness 里。模型只是其中的 decision maker,软件工程环境本身才是可执行世界。
GUI/OS Agent 更能说明 code 和 perception 的关系。GUI 看起来是视觉任务,但底层是 DOM、accessibility tree、window manager、ADB、Playwright、pyautogui、evaluator script。agent 看到的是截图或 UI tree,动作是 click/type/scroll/API call,评测是脚本检查最终状态。视觉只是入口,真正闭环仍然靠 executable environment。
Scientific Discovery Agent 则把实验假设、仿真、数据分析、lab protocol 都变成可执行 pipeline。它的关键不是“让模型会科学推理”,而是让 hypothesis、experiment、analysis、verification 都进入可追踪流程。
Embodied Agent 和 Personalization Agent 是更困难的边界。机器人和个性化系统的状态更偏物理或用户偏好,不像代码测试那样有清晰 oracle。论文把它们纳入框架,但也承认这里的 verification、memory、privacy、multimodal grounding 远没有 code assistant 成熟。
Evaluation:这篇 survey 的证据强在哪里,弱在哪里
因为这是 survey,它没有传统实验表。它的证据强度主要来自三类材料。
第一,taxonomy 覆盖面足够宽。论文从 Program-of-Thought、formal verification、robot code policy、GUI agent、SWE-agent、OpenHands、multi-agent software engineering、harness engineering、observability、sandbox、permission gateway 一直覆盖到 2026 的 AutoHarness、Meta-Harness、Agentic Harness Engineering。这说明“code as harness”不是为单一方法硬造概念,而是在归纳一个已经发生的工程趋势。
第二,分类维度比较有解释力。很多 survey 按任务或模型分类,读完容易变成 paper list。这篇按 interface、mechanism、scaling 三层组织,能解释为什么工具、记忆、测试、权限、多 agent、telemetry 属于同一个系统问题。
第三,开放问题写得很像工程 agenda,而不是泛泛说“需要更强模型”。它指出的关键问题包括 harness-level evaluation、oracle adequacy、semantic verification、regression-free harness evolution、transactional shared program state、HITL safety、multimodal code-harness systems。这些确实是当前 agent 工程绕不过去的问题。
弱点也明显。它的覆盖非常广,很多系统只能被简要归类,难以深入比较 benchmark protocol、代码实现和真实部署差异。其次,harness 概念有一定扩张风险:如果边界控制不好,几乎所有 agent infrastructure 都能被叫作 harness。作者通过“code must be executable or machine-checkable artifacts”做了边界,但实际讨论中仍然会跨到很多非代码状态,比如用户偏好、物理状态、视觉 grounding。最后,它更像路线图,不是可复现方法;读者不能指望从中直接得到一个可运行系统。
复现与工程风险
这篇论文不需要复现实验,但它对工程实现有很强的提醒作用。
第一,不要把 agent 可靠性只押在 prompt 上。真正可维护的 agent 需要可回放 telemetry、结构化 memory、明确 tool schema、sandbox、权限层、verification stack 和人类审批点。
第二,不要把 test pass 当成完整正确性。论文反复强调 oracle adequacy:测试、GUI checker、simulator、scientific script 都可能只是弱 proxy。agent harness 应该记录每个验证信号的 scope:它验证了什么、没验证什么、还有哪些风险。
第三,多 agent 系统最容易低估共享状态问题。多个 agent 不是多个 chat participant,而是多个并发操作者。它们需要 read set、write set、assumption、version dependency、conflict policy 和 re-verification。否则“协作”会变成状态污染。
第四,self-evolving harness 必须按安全关键系统管理。任何修改 retrieval、permission、validator、routing、workflow 的改动,都可能改变未来 agent 行为分布。没有 regression suite 和 rollback,就不要让 harness 自动升级。
总结:这篇论文真正有用的地方
Code as Agent Harness 的价值在于把“代码生成”提升成“agent runtime engineering”。它告诉我们,下一阶段 agent 研究不应该只问模型能不能写出正确代码,而应该问:模型输出如何进入受控执行环境?状态如何保存?反馈如何验证?权限如何治理?多个 agent 如何共享和合并程序状态?harness 自己如何在不回归的前提下演化?
如果你在做 coding agent、GUI agent、科研自动化、机器人或长期个性化 agent,这篇文章值得读。它不会给你一个新的算法模块,但会给你一个系统 checklist:interface 是否可执行,mechanism 是否可追踪,control loop 是否有强 verifier,state 是否可回放,多 agent 是否有事务语义,harness mutation 是否有回归保护。
我更愿意把它看成一篇“agent 工程语言统一”论文。它的概念不一定最终成为标准术语,但它抓住了一个真实变化:agent 的能力边界越来越由模型和 harness 共同决定。谁能把代码、工具、记忆、执行、验证、安全和协作组织成稳定闭环,谁就更接近真正可用的 long-horizon agent。
参考链接
- Paper: arXiv:2605.18747, PDF
- Official project page: Code as Agent Harness
- Official paper list / repo: YennNing/Awesome-Code-as-Agent-Harness-Papers
- Hugging Face paper page: HF Papers 2605.18747
Recommended citation: Ning et al., Code as Agent Harness: Toward Executable, Verifiable, and Stateful Agent Systems, arXiv:2605.18747, 2026.
Download Paper