
Edit2Restore:把图像复原改写成少样本图像编辑
Edit2Restore:把图像复原改写成少样本图像编辑
论文:Edit2Restore: Few-Shot Image Restoration via Parameter-Efficient Adaptation of Pre-trained Editing Models
作者:M. Akın Yılmaz, Ahmet Bilican, Burak Can Biner, A. Murat Tekalp
机构:Codeway AI, Koc University
时间 / 版本:2026-01-06 submitted,2026-01-20 v2
类别:few-shot image restoration, image editing, FLUX.1 Kontext, LoRA, PEFT
链接:Paper / PDF / Code / Model
检索日期:2026-05-24
开篇点评:这篇论文到底解决了什么问题
Edit2Restore 不是在 image restoration 里又设计了一个更深的 CNN、Transformer 或 U-Net。它换了一个问题表述:既然 FLUX.1 Kontext 这类 text-conditioned image editing model 已经会根据图像和文字指令做图像到图像转换,那么 denoising、deraining、dehazing 能不能也当成一种编辑操作?
这件事的工程含义很直接。传统 restoration 往往每种退化都要准备大量 paired data,训练一个专门网络,最后再按 PSNR/SSIM 做像素级比较。Edit2Restore 反过来利用大编辑模型已有的视觉先验,只在 FLUX.1 Kontext 上训练 LoRA adapter,并且每个任务只用 16-128 对 clean/degraded images。输入 degraded image 和一句 prompt,比如 remove the rain from the image,输出 restored image。
我的判断是,这篇论文最有价值的地方不是“指标全面超过传统复原模型”,而是它把 restoration 变成了一个 adapter learning 问题:如果一个强 image editing prior 已经存在,那么很多垂直复原任务可能不再需要从零训练 backbone,而是可以通过少量任务样本把 prompt、退化类型和局部视觉修复行为对齐。
Paper Card
| 项目 | 信息 |
|---|---|
| Paper | Edit2Restore: Few-Shot Image Restoration via Parameter-Efficient Adaptation of Pre-trained Editing Models |
| Authors | M. Akın Yılmaz, Ahmet Bilican, Burak Can Biner, A. Murat Tekalp |
| Date / Version | submitted 2026-01-06;v2 updated 2026-01-20 |
| Venue / Status | arXiv preprint |
| Category | eess.IV, cs.CV;few-shot restoration, text-conditioned editing, PEFT |
| Backbone | black-forest-labs/FLUX.1-Kontext-dev |
| Code / Weights | official code;README 提供 Google Drive 形式的 LoRA weights 和 results |
| Model / Dataset | FLUX.1 Kontext dev 权重需按其 license 获取;训练数据来自 BSD400、Rain100L、RESIDE/SOTS sampling,仓库未直接打包完整数据 |
| 复现状态 | 有官方训练/推理脚本,但完整复现还依赖 FLUX 权重、数据目录、metric dependency、Google Drive adapter/results 和高显存 GPU |
Abstract:论文摘要解读
摘要的核心可以拆成三层。
第一层是任务重表述。作者认为 image restoration 不一定只能靠专门的 restoration backbone;它也可以看作 image-to-image editing:给定一张退化图,再给一句恢复指令,模型把图像编辑成干净版本。
第二层是参数高效适配。论文没有 full fine-tune 12B 的 FLUX.1 Kontext,而是在 transformer 上训练 LoRA adapter;主实验使用 rank 64,每类退化只用 16-128 对样本。任务包括 denoising、deraining、dehazing。
第三层是评估取向。作者明确把重点放在 perceptual quality,而不是 pixel-perfect reconstruction。因此论文主表格报告 FID、CMMD、CLIP-IQA;PSNR/SSIM 更像辅助指标。这一点很重要,因为它决定了方法适合“视觉上更自然”的恢复,而不一定适合必须忠实保留每个像素的科学、医学或取证场景。
Motivation
image restoration 传统上很依赖任务特化。去噪、去雨、去雾、去模糊、低照增强往往各有模型、训练数据和评估协议。all-in-one restoration 试图统一多个任务,但很多方法仍然需要大量 paired data,并且要从头训练 restoration network。
Edit2Restore 的 motivation 更像一个迁移学习问题:FLUX.1 Kontext 已经在大规模数据上学过图像结构、自然纹理、视觉质量和文本指令对齐;如果 restoration 只是一个“把 degraded input 变成 clean output”的编辑操作,那么少量 paired data 可能只需要告诉模型“这个 prompt 对应哪种低层修复行为”。
这也是它和 InstructIR、PromptIR 等工作的关键区别。后者把 text/prompt 放进 restoration backbone,让一个从头训练的模型学会多任务复原;Edit2Restore 则把 restoration 放进已有 editing model 的接口,让 LoRA 去微调一个已经很强的生成式先验。
直观效果:先看它能做什么

图:来自论文 TeX source 中 figures/fluxir1.pdf 的官方 qualitative figure。它对比 input、zero-shot baseline、LoRA transformer、LoRA transformer + text encoder 和 ground truth,支持的理解点是:zero-shot FLUX.1 Kontext 并不能稳定复原,但 LoRA adaptation 后去雾、去雨和强噪声场景的视觉质量明显更接近 GT。
这张图也暴露了任务边界。Edit2Restore 的输出更像 generative restoration:画面会变干净、自然、结构更完整,但它不是严格的像素级逆问题求解器。尤其在 denoising 的老虎和沙漠样例里,模型输出会受大生成模型先验影响;如果应用需要严格保真,就不能只看“更好看”。
方法总览:核心思想和系统结构
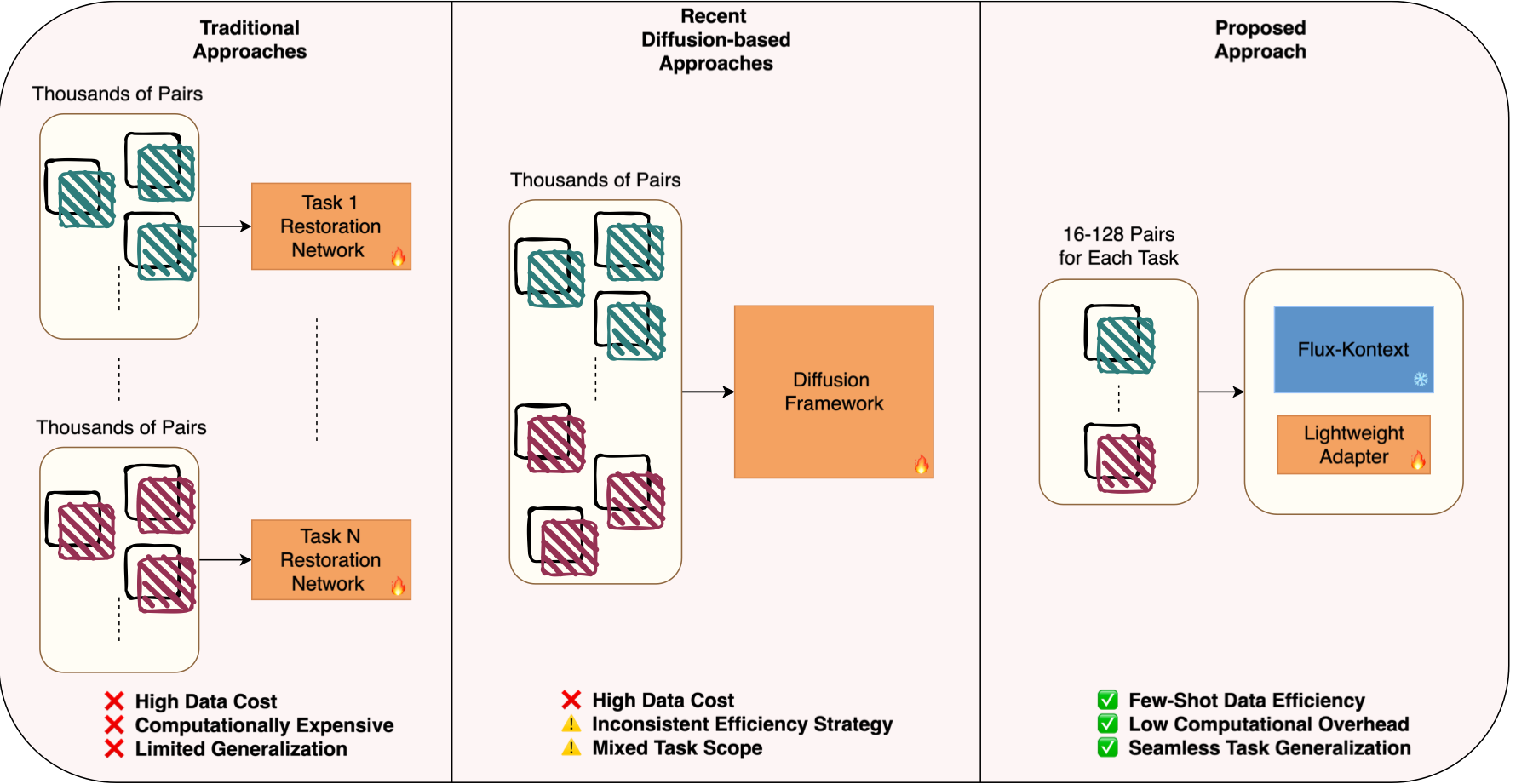
图:来自论文 figures/fluxir_overview.pdf 的官方 framework figure。它强调 Edit2Restore 和传统 task-specific restoration、recent diffusion-based restoration 的区别:不是为每个任务训练大型专用模型,而是在预训练编辑模型上用少量 pairs 训练 lightweight adapter。
方法可以概括成一句话:冻结 FLUX.1 Kontext 的主体能力,用 LoRA 学一个“把 restoration prompt 翻译成具体修复行为”的小参数增量。
论文把 FLUX.1 Kontext 看成三部分:
| 模块 | 作用 | 论文/代码中明确的信息 |
|---|---|---|
| VAE encoder/decoder | RGB image 和 latent 之间转换 | 论文写到 VAE latent 有 16 channels |
| CLIP / T5 text encoders | 把 restoration prompt 编成文本条件 | prompt 是固定模板,不依赖复杂 prompt engineering |
| Flow matching transformer | 在 latent space 做 image-to-image generation | LoRA 挂在 transformer;可选 text encoder LoRA |
rectified flow 的训练目标也很直接。clean image 被 VAE 编码成 clean latent,采样 Gaussian noise 和 timestep 后构造:
\[z_t = (1 - t) z_{\text{clean}} + t\epsilon\]对应的监督目标不是直接预测 clean latent,而是预测连接 noise 和 clean latent 的 velocity:
\[v^\star = \epsilon - z_{\text{clean}}\]模型输入包括 noisy target latent、degraded image latent 和 prompt embedding;模型输出预测 velocity,并用 MSE 拟合上面的目标速度。推理时反过来从 noise latent 开始,根据 degraded condition 和 prompt 逐步积分,最后 decode 成 restored image。
数据全流程:输入、表示、shape 和语义
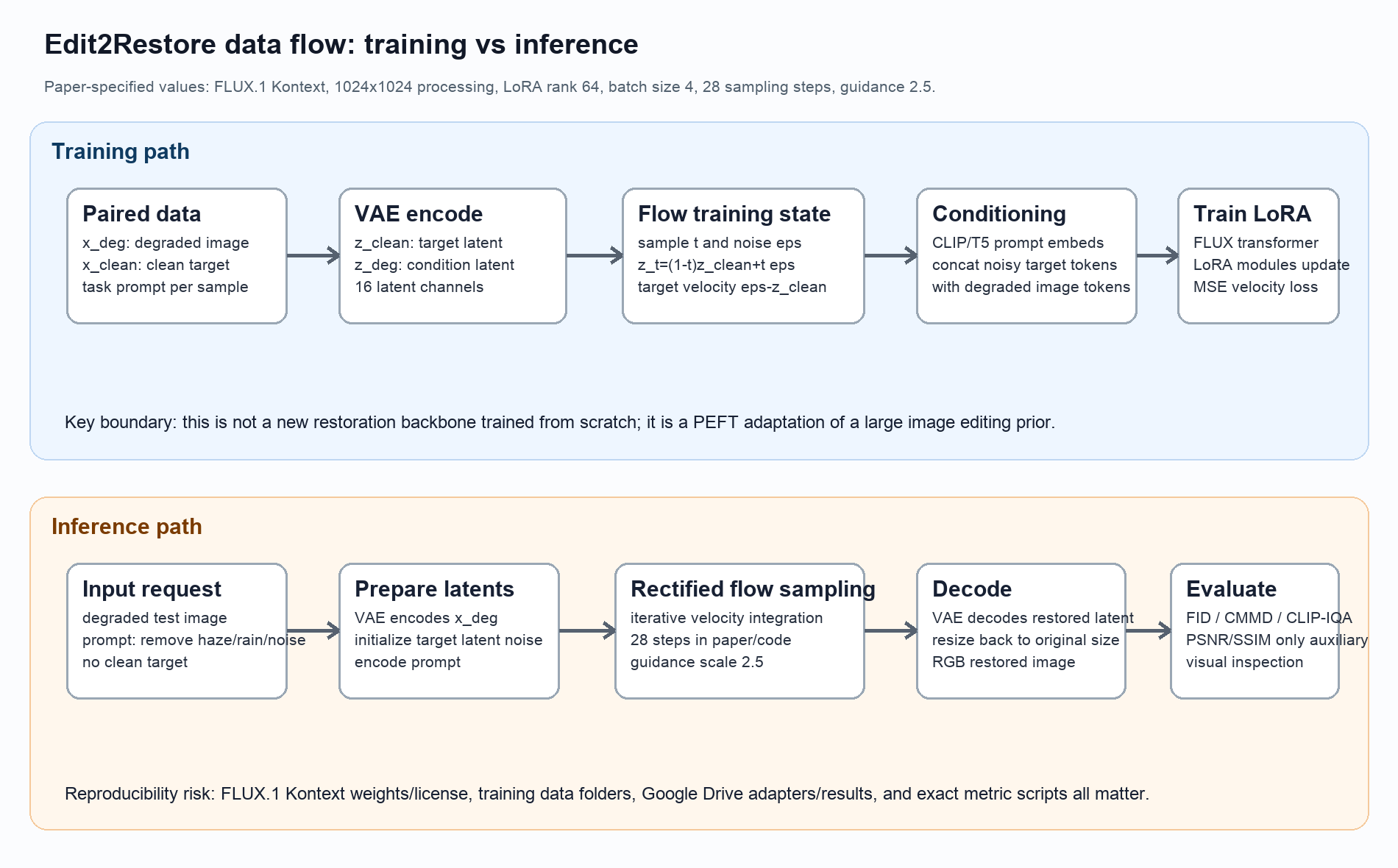
图:基于论文方法描述和官方代码重绘的数据流。它把 training path 和 inference path 分开,突出 clean target 只在训练中出现,测试时只保留 degraded image、prompt、noise latent 和 FLUX/LoRA sampling。
训练阶段的样本是 $(x_{\mathrm{deg}}, x_{\mathrm{clean}}, \mathrm{prompt})$:
- $x_{\mathrm{deg}}$:退化图,来自 denoising/deraining/dehazing 数据目录的
degraded子目录; - $x_{\mathrm{clean}}$:clean target,来自对应
clean子目录; - $\mathrm{prompt}$:任务指令,官方脚本使用
remove the noise from the image、remove the rain from the image、remove the haze from the image。
官方代码的 dataset loader 要求每个 degradation folder 下有 clean/ 和 degraded/,并按同名文件配对。所有图像在训练和推理时都会处理到 1024 x 1024,推理输出再 resize 回原图尺寸。
| 阶段 | 对象 | Shape/Dim | 语义 | 产生者 | 消费者 |
|---|---|---|---|---|---|
| input | $x_{\mathrm{deg}}$ | 1024 x 1024 x 3 after resize | degraded condition image | dataset / user input | VAE encoder |
| target | $x_{\mathrm{clean}}$ | 1024 x 1024 x 3 after resize | clean supervision target | paired dataset | VAE encoder |
| target latent | $z_{\mathrm{clean}}$ | VAE latent, 16 channels stated | 要恢复到的 clean latent | $\mathrm{VAE}(x_{\mathrm{clean}})$ | flow loss |
| condition latent | $z_{\mathrm{deg}}$ | VAE latent, 16 channels stated | degraded image condition | $\mathrm{VAE}(x_{\mathrm{deg}})$ | FLUX transformer |
| prompt embedding | CLIP/T5 embeddings | exact dim not specified | task instruction condition | text encoders | FLUX transformer |
| noisy latent | $z_t$ | same latent space | flow matching 中间状态 | $z_{\mathrm{clean}}$, noise, timestep | FLUX transformer |
| output | restored image | original size after resize-back | visual restoration result | VAE decoder | metrics / user |
这里最容易误读的一点是:degraded image 不是被当作普通文本条件,也不是只用于 loss。它被编码成 condition latent,与 noisy target latent 一起进入 FLUX Kontext 的 image-conditioned generation 路径。prompt 负责告诉模型做哪种操作,图像 condition 负责保留输入内容。
Training:监督信号、loss 和优化目标
论文的实验设置如下:
| 配置 | 取值 |
|---|---|
| Backbone | FLUX.1 Kontext dev |
| GPU | single NVIDIA H100 |
| Resolution | 1024 x 1024 |
| LoRA rank | 64 |
| Batch size | 4 |
| Training steps | 1,920 iterations |
| Optimizer | AdamW |
| Transformer LR | 1e-4 |
| Text encoder LR | 5e-6 when enabled |
| Weight decay | 1e-4 for transformer, 1e-3 for text encoder |
| Precision | bfloat16 with gradient checkpointing |
论文正文说 LoRA 用在 attention projection。官方代码实际更宽一些:train_lora_flux_kontext_multiple.py 的 target_modules 包括 attn.to_q/to_k/to_v/to_out.0,也包括 attn.add_*、ff.net.*、ff_context.net.*、proj_mlp。这说明它不是最窄的 attention-only LoRA,而是对 FLUX transformer 的多个投影/FFN 位置做低秩适配。
LoRA 的低秩更新可以写成:
\[W = W_0 + \Delta W = W_0 + BA,\qquad B \in \mathbb{R}^{d \times r},\ A \in \mathbb{R}^{r \times k}\]如果启用 --train_text_encoder,官方代码给 text_encoder_one 加 LoRA,target modules 是 q_proj/k_proj/v_proj/out_proj。这与论文里“text encoder fine-tuning”的表述方向一致,但复现时还需要确认 text_encoder_one 对应的具体 encoder,以及 T5 侧是否保持冻结。
Inference:测试时到底怎么生成结果
推理时没有 clean target。流程是:
- 读取 degraded test image;
- resize 到
1024 x 1024; - 输入对应 prompt,例如
remove the rain from the image; - 加载 FLUX.1 Kontext 和 LoRA weights;
- 从 noise latent 开始执行 rectified flow sampling;
- VAE decode;
- resize 回原始尺寸。
论文写到 inference 使用 28 integration steps,guidance scale 为 2.5。官方 save_deraining_wlora.py 也显式设置了 guidance_scale=2.5,但没有显式写 num_inference_steps,所以实际步数取决于 diffusers pipeline default 或外部调用设置。这个小细节值得记下来,因为 restoration 的速度和质量都可能受 sampling steps 影响。
Evaluation:验证集、指标和 baseline 是否公平
训练数据:
- denoising:从 BSD400 sample,并生成 $\sigma=15,25,50$ 的 noise;
- deraining:从 Rain100L sample;
- dehazing:从 RESIDE outdoor SOTS sample。
评测数据:
- BSD68 for denoising,覆盖 $\sigma=15,25,50$;
- Rain100L for deraining;
- SOTS outdoor 500 images for dehazing。
指标方面,论文主打 FID、CMMD、CLIP-IQA:
- FID 看 restored distribution 和 GT distribution 的距离;
- CMMD 用 CLIP feature space 做分布匹配;
- CLIP-IQA 是 no-reference perceptual quality 估计;
- PSNR/SSIM 被放在辅助位置,因为作者不把 pixel-level reconstruction 作为主要目标。
这个评估策略和方法目标是自洽的,但它也带来公平性边界。传统 restoration 方法常按 PSNR/SSIM 优化和报告,Edit2Restore 按 generative/perceptual quality 讲故事,两者不是完全同一条赛道。如果应用要求 faithful reconstruction,FID/CMMD/CLIP-IQA 不能替代误差分析。
实验与证据:哪些 claim 被支持,哪些还不够
1. LoRA adaptation 明显强于 zero-shot FLUX
论文先比较了不训练 LoRA 的 FLUX.1 Kontext 和 LoRA fine-tuned variants。关键结果如下,格式是 FID / CMMD / CLIP-IQA:
| Task | Baseline No LoRA | LoRA: TF | LoRA: TF + TE |
|---|---|---|---|
| Dehazing SOTS | 24.15 / 0.41 / 0.72 | 15.74 / 0.13 / 0.60 | 15.05 / 0.12 / 0.59 |
| Deraining Rain100L | 37.68 / 0.52 / 0.90 | 12.36 / 0.42 / 0.91 | 11.76 / 0.40 / 0.91 |
| Denoising BSD68 sigma=15 | 29.62 / 0.54 / 0.80 | 30.53 / 0.68 / 0.89 | 28.80 / 0.56 / 0.89 |
| Denoising BSD68 sigma=25 | 45.93 / 0.70 / 0.76 | 36.08 / 0.72 / 0.87 | 36.60 / 0.65 / 0.88 |
| Denoising BSD68 sigma=50 | 81.75 / 0.94 / 0.73 | 51.98 / 0.73 / 0.86 | 52.13 / 0.67 / 0.88 |
这个表支持两个结论。第一,zero-shot editing prior 不等于 restoration capability,尤其 deraining 和 high-noise denoising 需要任务适配。第二,LoRA 确实能以少量参数释放一部分 restoration 能力。
但也要注意,CLIP-IQA 并不总是随 FID/CMMD 同向改善。例如 dehazing 的 CLIP-IQA 从 baseline 的 0.72 到 LoRA TF+TE 的 0.59。论文更依赖 qualitative figure 来解释视觉质量提升,因此这里不能把“感知质量提升”简化成所有指标都更好。
2. 16-128 pairs 的 data efficiency 结果很强,但不是单调 scaling law
论文最有冲击力的表格是每个任务只用 16、32、64、128 pairs。以 unified adapter 为例:
| Pairs per task | Dehazing SOTS | Deraining Rain100L | Denoising sigma=15 | Denoising sigma=25 | Denoising sigma=50 |
|---|---|---|---|---|---|
| 128 | 15.05 / 0.12 / 0.59 | 11.76 / 0.40 / 0.91 | 28.80 / 0.56 / 0.89 | 36.60 / 0.65 / 0.88 | 52.13 / 0.67 / 0.88 |
| 64 | 15.60 / 0.14 / 0.58 | 11.29 / 0.41 / 0.91 | 28.89 / 0.58 / 0.90 | 35.77 / 0.63 / 0.90 | 51.97 / 0.73 / 0.88 |
| 32 | 15.20 / 0.11 / 0.63 | 11.92 / 0.41 / 0.91 | 28.64 / 0.58 / 0.90 | 37.12 / 0.69 / 0.90 | 51.99 / 0.78 / 0.89 |
| 16 | 14.66 / 0.13 / 0.60 | 12.29 / 0.44 / 0.91 | 27.73 / 0.57 / 0.90 | 36.05 / 0.57 / 0.89 | 53.88 / 0.81 / 0.88 |
这张表支持“极少样本也能启动 adapter”这个 claim。更准确地说,它说明在这些 benchmark、这些 metrics、这个 FLUX prior 下,从 16 到 128 pairs 没有出现大幅线性收益。
我的判断是,不能把它解读成“16 张总是够”。论文没有展示多 seed 方差,也没有覆盖更多真实退化分布。这里更稳妥的结论是:大编辑模型的先验足够强,少样本 LoRA 在常见退化 benchmark 上已经进入可用区间;后续数据增量可能被 metric noise、benchmark 饱和或 adapter 容量限制掩盖。
3. Unified adapter 可用,但不是所有任务都赢过 task-specific adapter

图:来自论文 figures/fluxir3.pdf 的官方 qualitative figure。它展示 unified multi-task adapter 与 single-task adapter 在去雾、去雨、去噪上的视觉差异,支持的理解点是:一个共享 adapter 在少样本条件下没有明显崩坏,prompt 可以承担任务路由。
16 pairs per task 下,unified 和 task-specific 的数量对比是混合的:
| Task | Task-specific | Unified |
|---|---|---|
| Dehazing SOTS | 14.41 / 0.14 / 0.60 | 14.66 / 0.13 / 0.60 |
| Deraining Rain100L | 11.86 / 0.41 / 0.90 | 12.29 / 0.44 / 0.91 |
| Denoising sigma=15 | 29.36 / 0.64 / 0.89 | 27.73 / 0.57 / 0.90 |
| Denoising sigma=25 | 37.05 / 0.72 / 0.88 | 36.05 / 0.57 / 0.89 |
| Denoising sigma=50 | 51.10 / 0.83 / 0.88 | 53.88 / 0.81 / 0.88 |
所以论文的 strong version 不是“unified adapter 总是更好”,而是“unified adapter 质量接近 task-specific,并且部署更简单”。这对产品化很关键:一个 adapter + prompt routing 可以覆盖多种常见恢复任务,存储和维护成本明显低于多个 task-specific adapters。
复现与工程风险
官方仓库提供了训练脚本、推理脚本和部分 metric scripts,但它更像 research release,不是开箱即用的完整 benchmark package。
复现需要注意几类问题:
| 风险 | 具体表现 | 影响 |
|---|---|---|
| Model access / license | README 明确需要 FLUX.1 Kontext weights,且 FLUX.1 dev 权重受 non-commercial license 约束 | 商业落地和公开部署要先解决授权 |
| 数据目录 | 代码期望 train_data128/denoising/clean、degraded 等目录,但仓库不含完整数据 | 需要自行整理 BSD400、Rain100L、SOTS |
| metric dependency | deraining_metric_report_withlora.py 引入 CMMD.main,浅克隆仓库中未看到 CMMD/ 目录 | 表格级复现需要补依赖和确认版本 |
| 采样细节 | 论文写 28 steps、guidance 2.5;推理脚本写了 guidance 2.5,但未显式指定 steps | diffusers 版本变化可能影响输出 |
| 生成式修复 | 输出可能更自然,但也可能改写纹理、颜色、身份或局部结构 | 高保真场景需要额外约束和误差分析 |
| 算力 | 论文实验使用 single H100,模型为 12B FLUX.1 Kontext | 本地复现成本明显高于传统小 restoration net |
我会把它看成一个适合做 prototype 和垂直任务适配的方向,而不是立即替代所有 restoration pipeline。对“老照片修复、内容创作、低质量社媒图增强、特定摄像头退化修复”这类场景,它的价值很明确;对“医学影像、遥感测量、司法取证、科学成像”,生成式 prior 的 hallucination 风险必须被严格控制。
总结
Edit2Restore 的贡献可以说得很朴素:它证明了一个强 text-conditioned editing model 经过少样本 LoRA 适配后,可以承担常见 image restoration 任务,而且一个 unified adapter 可以用 prompt 区分去噪、去雨、去雾。
这篇论文真正启发我的地方有三点。
第一,restoration 方向可以从 architecture-first 转向 prior-first。与其为每个退化重新训练网络,不如先问现有大编辑模型已经知道什么,再用 adapter 学任务边界。
第二,few-shot restoration 的核心不只是“数据少”,而是“prompt、image condition、latent flow 和 LoRA capacity 是否能形成稳定闭环”。Edit2Restore 的实验说明这个闭环在三个经典任务上能跑通。
第三,评价体系要诚实。论文没有强行把自己包装成 PSNR/SSIM SOTA,而是承认方法偏 perceptual quality。这让它的应用边界更清楚:适合视觉增强和内容质量提升,不天然适合需要严格 truth-preserving 的逆问题。
后续最值得继续追的研究问题是:如何给这种生成式 restoration 加 fidelity constraint,如何自动判断一个新 degradation 是否适合 few-shot LoRA,如何把多个 adapters 或 prompts 组合成可控、可解释、可部署的 restoration system。
Recommended citation: Yılmaz et al., Edit2Restore: Few-Shot Image Restoration via Parameter-Efficient Adaptation of Pre-trained Editing Models, arXiv 2026
Download Paper