
Flow-OPD:把多任务奖励对齐改写成 Flow Matching 的 on-policy 蒸馏
Flow-OPD:把多任务奖励对齐改写成 Flow Matching 的 on-policy 蒸馏
论文:Flow-OPD: On-Policy Distillation for Flow Matching Models
作者:Zhen Fang, Wenxuan Huang, Yu Zeng, Yiming Zhao, Shuang Chen, Kaituo Feng, Yunlong Lin, Lin Chen, Zehui Chen, Shaosheng Cao, Feng Zhao
时间 / 版本:arXiv v4, submitted 2026-05-13, revised 2026-05-19
类别:Flow Matching / Text-to-Image Alignment / GRPO / On-Policy Distillation
链接:Paper / PDF / Project / Code / Model
检索日期:2026-05-24
开篇点评:这篇论文真正要解决的是多奖励对齐里的梯度冲突
Flow-OPD 不是一篇单纯“把 GRPO 用到图像生成”的论文。它讨论的是一个更窄、也更有工程价值的问题:当 text-to-image 模型已经是 Flow Matching 模型时,如果我们想同时优化 GenEval、OCR、DeQA、PickScore 这类异质目标,为什么把多个 reward 混在一起做 GRPO 会卡住?
论文给出的答案很直接:单个 reward 的 GRPO 可以靠 online exploration 推动模型在一个目标上变强,但多 reward 混合会把不同能力压成一个稀疏 scalar advantage。这个 scalar 只在最终图像上打分,无法告诉模型某个 denoising step、某个 latent state、某个 prompt 子任务应该向哪种能力迁移。结果就是常见的跷跷板:OCR 变好时 GenEval 退化,PickScore 变高时结构和文字可能变差,DeQA 或审美奖励又可能引入 reward hacking。
Flow-OPD 的关键判断是:不要继续把多任务对齐当成“多个 scalar reward 怎么加权”的问题,而要把它改写成 Flow Matching 模型天然能吃的监督形式,也就是 trajectory-level vector field supervision。学生模型仍然 on-policy 采样自己的轨迹,但每个轨迹状态都会被路由到对应任务 teacher,teacher 给出的不是最终分数,而是当前 $x_t$ 处应该跟随的 velocity field。这样,多任务奖励被转换成更密集的、逐步的、和 flow 模型参数化一致的训练信号。
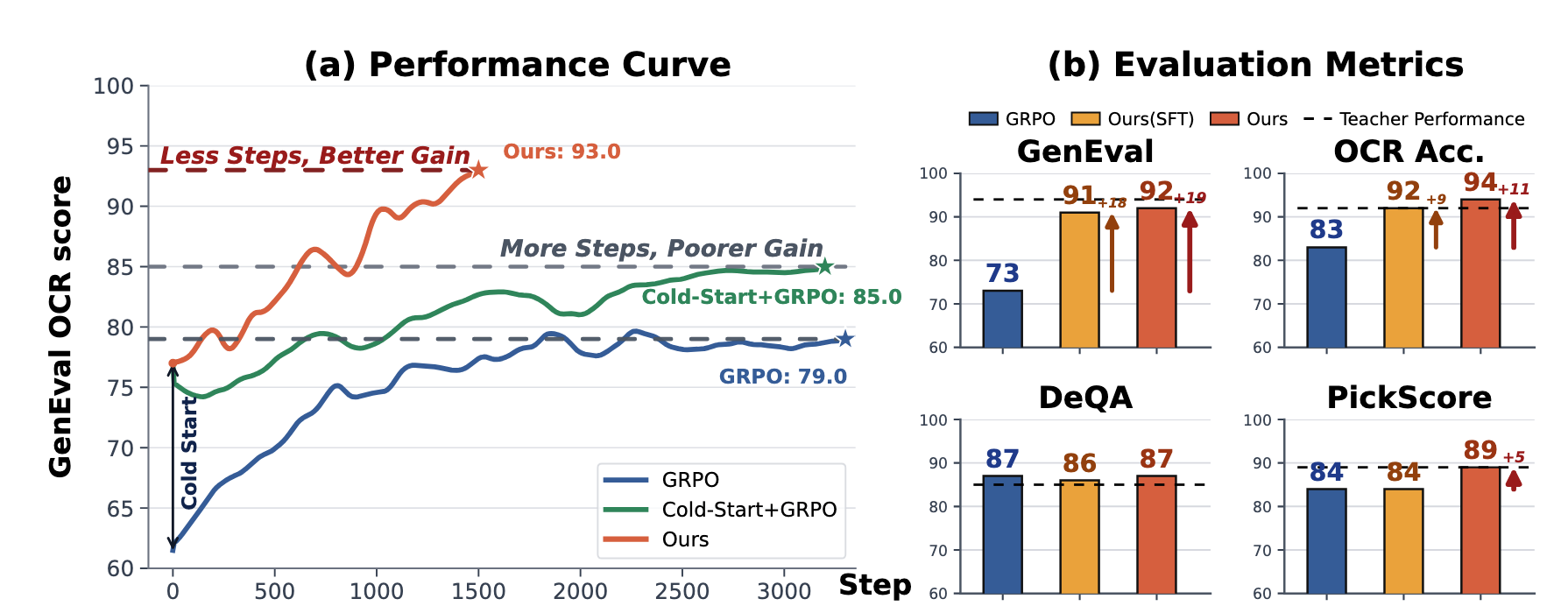
图:论文和项目页展示的 multi-task training 曲线与指标对比。它支持的核心 claim 是:在同样围绕 SD-3.5-M 的多任务后训练设置中,Flow-OPD 比 vanilla GRPO 和 Cold-Start+GRPO 更快达到更高的综合分数。注意这里的分数是论文设定下的 reward/benchmark 组合,不等价于开放场景的完整人工偏好评测。
Paper Card
| 项目 | 信息 |
|---|---|
| Paper | Flow-OPD: On-Policy Distillation for Flow Matching Models |
| Authors | Zhen Fang, Wenxuan Huang, Yu Zeng, Yiming Zhao, Shuang Chen, Kaituo Feng, Yunlong Lin, Lin Chen, Zehui Chen, Shaosheng Cao, Feng Zhao |
| Date / Version | arXiv v4, submitted 2026-05-13, revised 2026-05-19 |
| Base model | Stable Diffusion 3.5 Medium |
| Main task | multi-task alignment for text-to-image Flow Matching models |
| Main benchmarks | GenEval, OCR accuracy, DeQA, PickScore, T2I-CompBench, image quality reward metrics |
| Code / Model | GitHub, Hugging Face |
| Core claim | multi-teacher on-policy distillation gives dense vector-field supervision and reduces multi-reward interference |
| 复现状态 | 代码、脚本和模型入口已公开;完整训练仍依赖 SD-3.5 权限、多 reward model 环境、32 张 H800 级训练资源和复杂评测链路 |
Abstract:论文摘要解读
论文摘要可以拆成三层。
第一层是 failure diagnosis。作者认为 Flow Matching text-to-image 模型做 RL alignment 时,单 reward 目标相对容易,但多 reward 目标会同时遇到 reward sparsity 和 gradient interference。reward sparsity 来自最终图像级打分:模型在几十个 denoising step 里做了很多连续决策,但 reward 只在最后给一个数。gradient interference 来自能力维度不一致:文字渲染、对象计数、空间关系、审美偏好、细节真实感不一定共享同一个更新方向。
第二层是 framework。Flow-OPD 采用两阶段对齐:先用单 reward GRPO 训练多个 domain-specialized teachers,再做 Flow-based Cold Start 和 on-policy distillation。Cold Start 可以是 teacher trajectory SFT,也可以是 expert LoRA merge;后续 OPD 阶段让学生在自己的分布上采样,再由 prompt routing 选择对应 teacher,在学生访问到的每个 $x_t$ 上提供 dense vector-field label。
第三层是 regularization。论文加入 Manifold Anchor Regularization, MAR,用一个任务无关的 aesthetic teacher 给全数据分布提供锚点,避免学生只追逐功能性 reward 而离开高质量图像流形。
实验 claim 比较强:在 Stable Diffusion 3.5 Medium 上,GenEval 从 0.63 提升到 0.92,OCR 从 0.59 提升到 0.94;综合平均分从 base 的 0.7165、GRPO-Mix 的 0.8165 提升到 Ours(Merge) 的 0.9045。论文还强调了 teacher-surpassing effect,也就是学生在某些任务上超过单个 teacher 的指标。
Motivation:为什么多 reward GRPO 不够
Flow Matching 的基础目标很简单。给定 data 端 $x_0$ 和 noise 端 $x_1$,线性路径可以写成:
\[x_t=(1-t)x_0+t x_1\]对应的 conditional velocity 是 $x_1-x_0$,训练目标是:
\[\mathcal{L}_{\mathrm{FM}}(\theta)=\mathbb{E}_{t,x_0,x_1,c}\left\|v_\theta(x_t,t,c)-(x_1-x_0)\right\|_2^2\]在 Flow-GRPO 这类方法里,采样过程被看成一个 Markovian denoising process。模型从当前 policy 采样 $G$ 个候选图像,对每个候选图像计算 reward,然后用组内归一化优势:
\[A(x_1^{(i)})=\frac{r(x_1^{(i)})-\mu}{\sigma}\]这解释了为什么单 reward GRPO 经常有效:它直接优化当前模型会生成的东西,是 on-policy 的;如果一个 prompt 下某个样本比组内其他样本更好,它会被强化。
但多 reward 的问题不在 on-policy 本身,而在监督粒度和目标可分性。比如 GenEval 更关心对象、属性、计数、关系;OCR 更关心可读文字;PickScore 更接近人类偏好;DeQA 更像视觉问答式的 prompt adherence。把它们加成一个 scalar reward 后,模型只能看到“这张图综合分更高”,看不到“哪个 step 的哪个方向对 OCR 有帮助,但会损害空间关系”。论文中的 toy table 很直观:单独做 GenEval 可到 0.94,但 OCR 只有 0.65;继续加入 OCR 后,GenEval 掉到 0.89;加入 PickScore 后,GenEval 进一步掉到 0.82。这不是调权重就能彻底解决的噪声,而是共享参数下不同任务梯度方向冲突。
方法总览:从 scalar reward 到 dense vector-field reward
Flow-OPD 的方法可以用一句话概括:让学生 on-policy 采样自己的 trajectory,再让多个 expert teacher 在这些 state 上给 velocity field 标签,用 KL 形式把 teacher vector field 变成每一步的 dense reward。
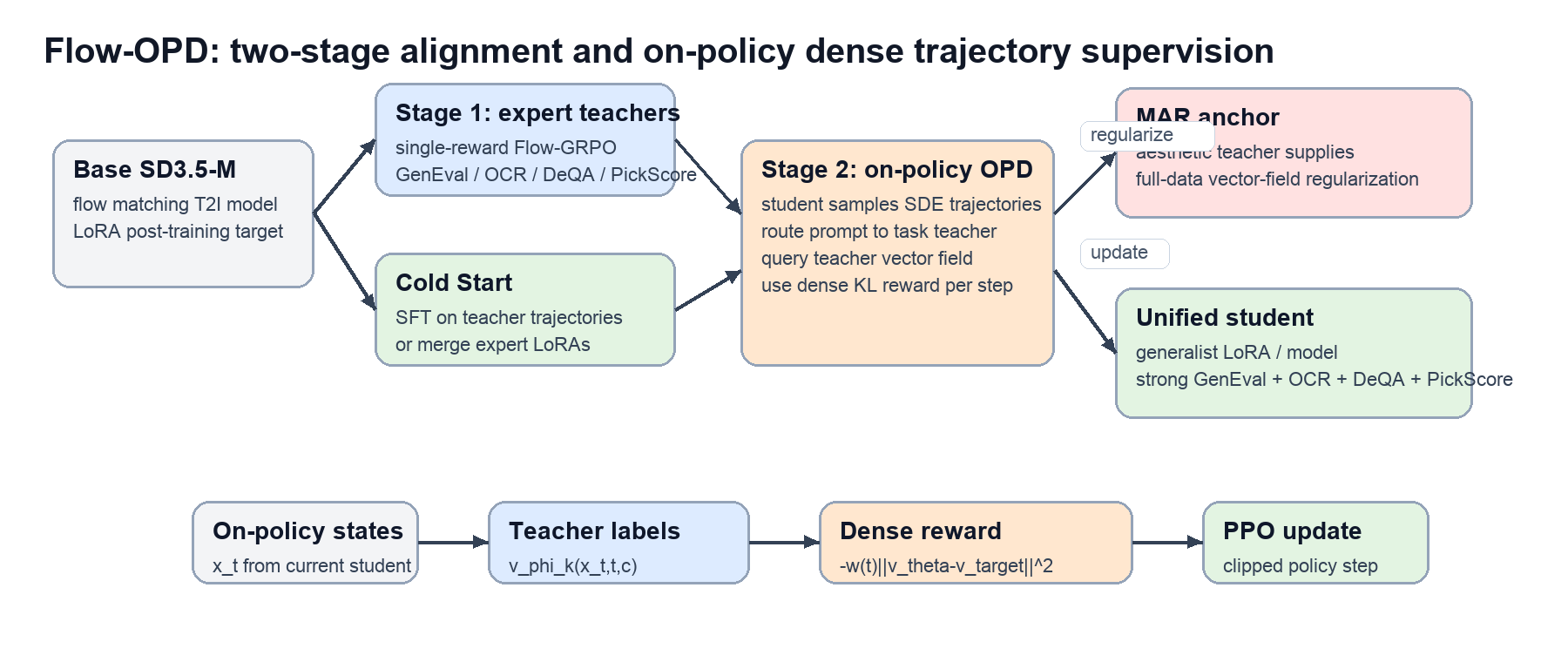
图:根据论文方法部分重画的结构图。重点不是多了几个 teacher,而是监督信号的位置发生了变化:teacher 不只评价最终图像,而是在学生真实访问到的 $x_t$ 上给出 vector-field direction。
Stage 1:先训练单任务 experts
论文先使用单 reward Flow-GRPO 训练任务专家。GenEval、OCR、PickScore 使用已有官方 checkpoint;DeQA teacher 则用 DeQA 和 PickScore 以 4:6 reward ratio 混合训练。这样做的目的不是部署多个 teacher,而是把每个 reward 的局部最优能力固化成可查询的 vector field。
这个阶段有一个隐含前提:teacher 与 student 最好架构同质。因为 OPD 后面需要在同一个 latent state $x_t$、同一个 timestep $t$、同一个 condition $c$ 上比较两个模型的 velocity field。如果 teacher 和 student 的 latent space、time schedule 或 conditioning 不兼容,逐步向量场监督就很难直接成立。
Stage 2a:Flow-based Cold Start
直接让 base student 去模仿多个 experts 会有 distribution mismatch:student 自己采样到的 states 可能离 teacher 擅长区域太远,dense supervision 也可能变成纠偏成本很高的 noisy target。因此论文在 OPD 前加了 Cold Start。
Cold Start 有两种方式。第一种是 SFT,把 teacher trajectories 当成监督数据训练学生。第二种是 model merge,把多个 expert LoRA 合并成一个更好的初始化。论文主表里 Ours(Merge) 最强,GenEval 0.92、OCR 0.94、DeQA 4.35、PickScore 23.08,平均分 0.9045;Ours(SFT) 略低但仍明显超过 GRPO-Mix。
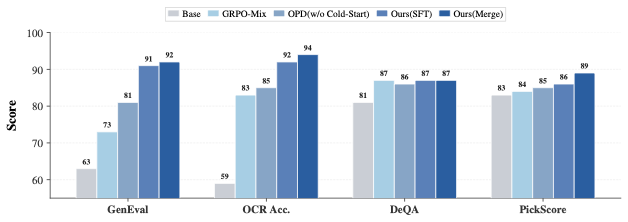
图:论文 cold-start ablation。没有 Cold Start 的 OPD 已经强于 GRPO-Mix,但 SFT 或 Merge 初始化能进一步提高 GenEval、OCR 和 PickScore。这个结果说明 OPD 不是单靠蒸馏损失本身解决所有问题,好的初始分布仍然关键。
Stage 2b:把 Flow Matching 的 transition policy 化
为了把 OPD 放进 Flow Matching,论文把 deterministic probability flow ODE 改写成带噪声的 SDE:
\[dx_t=\left[v_\theta(x_t,t,c)+\frac{\sigma_t^2}{2t}\left(x_t+(1-t)v_\theta(x_t,t,c)\right)\right]dt+\sigma_t\,dw_t\]离散化后,每一步 transition 可以看成 Gaussian policy:
\[\pi_\theta(x_{t-\Delta t}\mid x_t,c)=\mathcal{N}\left(\mu_\theta(x_t,t,c),\sigma_t^2\Delta t I\right)\]这一步很关键。自回归 LLM 里的 OPD 可以比较 token policy;Flow Matching 没有 token policy,但有连续 trajectory 和 velocity field。论文把 $v_\theta$ 对应到 transition distribution 的 mean,于是 teacher-student policy KL 可以在连续空间里定义。
Stage 2c:prompt routing 与 multi-teacher labels
对每个 prompt,Flow-OPD 用 routing function $R(c)$ 选择任务 teacher。比如文字 prompt 走 OCR teacher,组合关系 prompt 走 GenEval teacher,偏好类 prompt 走 PickScore 或 DeQA teacher。teacher 在学生自己的 $x_t$ 上输出 $v_{\phi_k}(x_t,t,c)$,这就是 target flow。
因为 student policy 和 teacher target policy 使用相同 covariance,reverse KL 可以化成 weighted L2 vector-field discrepancy:
\[D_{\mathrm{KL}}\left(\pi_\theta\|\pi_{\mathrm{target}}\right) =\frac{\Delta t}{2} \left(\frac{\sigma_t(1-t)}{2t}+\frac{1}{\sigma_t}\right)^2 \left\|v_\theta(x_t,t,c)-v_{\phi_k}(x_t,t,c)\right\|_2^2\]于是每个 timestep 都可以给一个 dense reward:
\[r_t=-w(t)\left\|v_\theta(x_t,t,c)-v_{\phi_k}(x_t,t,c)\right\|_2^2\]这比最终图像上的 scalar reward 更接近 Flow Matching 模型的训练接口。它不是说 reward model 不重要,而是把 reward model 训练出的 experts 转换成更密集、更可分的监督。
Stage 2d:MAR 作为图像质量锚点
如果只让任务 teacher 牵引学生,模型可能学会功能性捷径:文字更像字但图像变塑料,问答分更高但审美下降,局部结构迎合 reward model 但整体真实感变差。MAR 的作用是在所有数据上引入 task-agnostic aesthetic teacher:
\[\mathcal{L}_{\mathrm{MAR}}= \lambda\mathbb{E}_{t,x_t,c} \left[w(t)\left\|v_\theta(x_t,t,c)-v_{\mathrm{aesthetic}}(x_t,t,c)\right\|_2^2\right]\]最终目标可以理解为:task teachers 负责把模型拉向各自能力,aesthetic teacher 负责不让模型离开高质量图像流形。论文的 image quality table 里,Ours(Merge) 在 ImageReward、Aesthetic、UnifiedReward、HPS、QwenVL 这些指标上整体高于 w.o. MAR 和 GRPO-Mix,支持 MAR 的必要性。
训练与数据流:工程上到底怎么跑
论文实现基于 Stable Diffusion 3.5 Medium,后训练主要是 LoRA 形式。appendix 给出的关键训练配置包括:
| 项目 | 配置 |
|---|---|
| sampling timestep | $T=10$ |
| evaluation timestep | $T=40$ |
| group size | $G=24$ |
| noise level | $a=0.7$ |
| image resolution | 512 |
| MAR KL ratio | $\beta=0.02$ |
| LoRA rank / alpha | rank 32, alpha 64 |
| full training compute | 4 nodes, each 8 H800, about 50 hours |
公开 GitHub 仓库里能看到对应脚本,例如 scripts/train_sd3_opd_mix.py、scripts/train_sd3.py、scripts/train_sd3_mixed.py、scripts/merge.py、scripts/eval_t2icompbench.py,以及 single-node 示例 scripts/single_node/sd3_opd_example.sh、sd3_opd_mix_local.sh、merge.sh、run_eval.sh。README 也列出了 base model、teacher checkpoints 和 reward models,包括 SD-3.5-M、FlowGRPO GenEval/OCR/PickScore teachers、PickScore、CLIPScore、Aesthetic、PaddleOCR、DeQA、UnifiedReward、ImageReward、QwenVL scoring 等。
这说明复现不是“跑一个训练脚本”这么简单。实际链路至少有四类依赖:
- base model 权限和 SD-3.5-M 推理环境。
- 多个 reward model / evaluator 环境,尤其 OCR、DeQA、UnifiedReward、QwenVL 等可能有不同依赖和显存行为。
- teacher checkpoint 与 LoRA merge / SFT 初始化。
- 训练后的多 benchmark 评估,包括 GenEval、OCR、DeQA、PickScore、T2I-CompBench 和 image quality reward。
论文没有把所有工程细节都变成一个最小可复现命令。官方仓库已经公开主要代码和权重入口,但完整 reproduction 仍然是重工程任务,尤其是在 32 张 H800 级资源之外,想复核 paper-level 数字会很难。
实验结果:它证明了什么,没证明什么
主结果表的核心对比是 base、单 reward GRPO、GRPO-Mix、Cold-Start+GRPO-Mix 和 Flow-OPD。
| Method | GenEval | OCR Acc. | DeQA | PickScore | Avg |
|---|---|---|---|---|---|
| SD-3.5-M | 0.63 | 0.59 | 4.07 | 21.64 | 0.7165 |
| GRPO-Mix | 0.73 | 0.83 | 4.33 | 21.84 | 0.8165 |
| SFT+GRPO-Mix | 0.85 | 0.86 | 4.29 | 21.79 | 0.8515 |
| Merge+GRPO-Mix | 0.84 | 0.86 | 4.18 | 21.87 | 0.8442 |
| Ours(SFT) | 0.91 | 0.92 | 4.29 | 21.83 | 0.8820 |
| Ours(Merge) | 0.92 | 0.94 | 4.35 | 23.08 | 0.9045 |
这个表能支持三个结论。
第一,多 reward GRPO 确实有效,但上限有限。GRPO-Mix 比 base 大幅提升 OCR 和综合分,但 GenEval 仍只有 0.73,说明混合 reward 没能充分吸收 GenEval teacher 的强能力。
第二,Cold Start 本身已经很重要。SFT+GRPO-Mix 和 Merge+GRPO-Mix 都比 GRPO-Mix 高,说明多 expert 初始化可以缓解一部分任务冲突。
第三,Flow-OPD 的提升不只是 Cold Start。Ours(SFT) 和 Ours(Merge) 都进一步超过对应 GRPO baseline,特别是在 GenEval 和 OCR 上接近或超过单任务 teacher 水平。这支持论文最重要的 claim:dense trajectory-level teacher supervision 比最终 scalar reward mixing 更适合多任务能力吸收。

图:官方 qualitative comparison。它展示了不同 reward 方向的典型副作用:单 reward 模型常在文字、计数、对象形状或视觉偏好上偏科;Flow-OPD 的目标是把这些能力吸收到一个 unified student。
T2I-CompBench 的结果也值得看。Ours(Merge) 在 Color、Shape、Texture、Complex、3D-Spatial、Numeracy、Non-Spatial 上都高于 base,并且在 Shape、3D-Spatial、Numeracy 上比 Cold Start 和 Cold-Start+GRPO 更明显。这说明 Flow-OPD 不只是优化论文主表里的几个 reward 指标,也能在组合理解 benchmark 上带来外溢提升。
但它还没完全证明“真实用户偏好全面更好”。原因有三点。第一,许多指标本身来自 reward/evaluator model,可能和训练 reward 存在相关性。第二,qualitative examples 支持直观效果,但不是大规模人工偏好实验。第三,训练和评估围绕 SD-3.5-M、特定 prompt splits 和特定 reward stack,迁移到 FLUX、开源 DiT 或其他 flow 模型时仍需要实证。
和 DiffusionNFT、GRPO-Mix 的关系
论文 appendix 对 DiffusionNFT 做了讨论。DiffusionNFT 也是从 fine-tuned teacher 做行为克隆式迁移,但作者认为它在 classifier-free guidance 兼容性、reward hacking 和细节质感上有问题。Flow-OPD 的不同点是 on-policy:学生采样自己的 states,teacher 在这些 states 上给标签,减少纯 offline teacher trajectory 的分布错配。
和 GRPO-Mix 相比,Flow-OPD 也不是简单“多一个蒸馏损失”。GRPO-Mix 的强化信号仍然是最终图像级 scalar reward;Flow-OPD 的强化信号是每个 timestep 的 vector-field KL reward。两者优化接口不同,所以它更像是把 RLHF 里的 policy distillation 思路移植到 Flow Matching 的连续决策空间,而不是给 GRPO 加一个 auxiliary loss。
复现风险与未知点
从公开材料看,这篇论文的 reproducibility 处于“有官方代码和权重入口,但完整复现成本高”的状态。
比较明确的部分包括:核心公式、两阶段训练流程、主要 hyperparameters、teacher/reward model 名称、训练资源量、主表指标和 single-node 示例脚本。GitHub 仓库也能看到训练、评测、reward、dataset 的主要文件结构。
不够轻量的部分包括:完整多节点训练需要 4 x 8 H800 和约 50 小时;reward stack 复杂,环境冲突和 evaluator 版本差异可能影响结果;SD-3.5-M 与部分模型需要访问权限;多任务 prompt routing 的具体覆盖边界在工程上仍要仔细核对;论文没有把所有 seeds、失败 prompt 分布、人工评测协议和跨 base model 迁移结果都公开成可一键复核的形式。
还有一个理论边界必须保留:Flow-OPD 的细粒度监督依赖 teacher 与 student 的架构同质性。它适合“同类 Flow Matching 模型之间的能力整合”,但不自动解决跨架构、跨 latent tokenizer、跨 timestep schedule 的 distillation。如果 teacher 本身在某类 prompt 上有系统性错误,dense vector-field supervision 还会把这种错误更稳定地传给学生。
我的判断:这篇论文的价值在哪里
Flow-OPD 最有价值的地方,不是又刷新了几个 reward 分数,而是提供了一个多任务对齐的机制转译:
multi-task scalar rewards
-> single-task expert teachers
-> on-policy student trajectories
-> task-routed vector-field labels
-> dense KL rewards over flow transitions
这个转译对 Flow Matching 模型特别自然。Flow 模型本来就在学 velocity field;与其让 reward model 在最终图像上给一个稀疏分数,不如把 reward model 训练出的 expert 能力蒸馏成每一步该走的方向。它把“奖励怎么加权”变成“哪个 teacher 在哪个 state 给什么 vector-field supervision”,这比 scalar reward mixing 更细。
如果从研究角度看,Flow-OPD 后面最值得追的问题有三个。
第一,routing 能不能从 hard prompt routing 变成 adaptive routing?现在的 $R(c)$ 假设 prompt 可以被分到某个任务 teacher,但真实 prompt 往往同时包含文字、计数、空间关系和审美要求。更细的 mixture-of-teachers、state-dependent routing 或 uncertainty-aware routing 可能更自然。
第二,能不能突破 teacher-student homogeneity?如果 OPD 只能在同一架构、同一 latent 和同一 schedule 下做,价值主要在模型内部能力整合。跨架构 distillation 需要把 teacher signal 投到可比较的 latent/time representation 上,这可能是更有论文空间的问题。
第三,dense reward 是否会放大 teacher bias?稀疏 reward 的问题是信号少,但 dense teacher supervision 的问题是错误也更密。MAR 只解决图像质量锚点,不一定解决语义 teacher 的系统性偏差。未来需要更强的 disagreement detection、teacher confidence 或 self-correction 机制。
工程上,这篇论文适合被看作“多能力 LoRA / reward-tuned experts 合并”的高级方案。如果你已经有多个单任务强化微调模型,Flow-OPD 给了一条比直接 merge 或 mixed-reward GRPO 更强的整合路径。但如果你的目标只是轻量调一个模型,或没有稳定 teacher / reward evaluator / 多卡资源,这套方法的工程门槛会很高。
一句话结论
Flow-OPD 把多任务 text-to-image alignment 的核心问题从“怎么混合多个最终 reward”改写成“怎么在学生自己的 Flow Matching trajectory 上吸收多个 expert vector fields”。这个机制解释了它为什么能同时提升 GenEval、OCR、DeQA 和 PickScore,也解释了它的边界:依赖强 teacher、同质架构、复杂 reward stack 和高训练资源。对研究来说,它是一篇值得读的多任务 FM 对齐论文;对工程来说,它更像 expert consolidation pipeline,而不是低成本通用 finetuning recipe。
参考来源
- Flow-OPD arXiv abstract
- Flow-OPD PDF
- Flow-OPD project page
- Flow-OPD GitHub repository
- Flow-OPD Hugging Face model page
Recommended citation: Zhen Fang et al. Flow-OPD: On-Policy Distillation for Flow Matching Models. arXiv:2605.08063, 2026.
Download Paper