
Mean Mode Screaming:为什么 1000 层 Diffusion Transformer 会被 token 均值拖垮
Mean Mode Screaming:为什么 1000 层 Diffusion Transformer 会被 token 均值拖垮
论文:Mean Mode Screaming: Mean-Variance Split Residuals for 1000-Layer Diffusion Transformers
作者:Pengqi Lu
时间 / 版本:arXiv v1, submitted on 2026-05-07
类别:cs.LG / Diffusion Transformer / training stability
链接:Paper / PDF / Project / Code / Model
检索日期:2026-05-24
开篇点评:这篇论文不是单纯说“更深更强”,而是在拆一个很具体的崩溃模式
这篇论文的标题很抓人,Mean Mode Screaming,直译大概是“均值模式尖叫”。但它讨论的问题并不玄学:当 Diffusion Transformer 被推到数百层甚至 1000 层时,训练可能不是慢慢变差,而是在训练了几千甚至几万步后突然崩掉。更麻烦的是,这种崩溃不一定伴随 NaN、forward activation 爆炸,或者传统意义上的梯度爆炸。loss 可以在很短几步里回到接近初始化的状态,模型表面上还在正常算,但 token 表示已经高度同质化。
作者的核心判断是:这个 failure mode 发生在 token mean subspace。Transformer attention 是 row-stochastic 的,因此纯 token-mean 状态会被 attention 保留下来;而 token 间真正表达空间结构、局部差异、语义差异的 centered component,可能在超深残差链中持续被收缩。结果是 residual writer 的梯度越来越朝均值方向对齐,某一步发生 mean-coherent writer shock,随后 Q/K 梯度被 Softmax null space 压掉,深层 token 进入同质化状态。
论文提出的 MV-Split Residuals 不是把 residual branch 简单乘一个小系数,而是把 residual update 按 token mean 和 centered variation 分开处理:均值路径用较小的 $\alpha$ 做 leaky replacement,中心化路径用 $\beta$ 保留更新能力。我的判断是,这篇论文最值得读的地方不是 1000 层这个数字,而是它给超深 DiT 的训练崩溃提供了一套可观测、可诊断、可干预的子空间解释。

图:论文展示的 1000-layer MVSplit-DiT 生成样例。它说明模型不是只在 toy setting 上稳定,而是被作者推进到一个可采样的 text-to-image checkpoint;但定性图本身不构成 SOTA 证据,真正支撑训练稳定 claim 的是后面的 400L 对照和诊断曲线。
Paper Card
| 项目 | 信息 |
|---|---|
| Paper | Mean Mode Screaming: Mean-Variance Split Residuals for 1000-Layer Diffusion Transformers |
| Author | Pengqi Lu |
| Date / Version | arXiv v1, submitted on 2026-05-07 |
| Category | cs.LG, diffusion transformer scaling, residual stability |
| Project / Code | Project, GitHub |
| Model | StableKirito/mvsplit-dit-1000l, community diffusers conversion BiliSakura/MVSplit-DiT-diffusers |
| Training data | ImageNet-2012 pretraining; 1000L run additionally uses about 50k curated images for post-training |
| Core claim | ultra-deep Post-Norm DiTs can fail through mean-dominated token homogenization; MV-Split Residuals stabilize this by separately controlling token-mean and centered residual modes |
| 复现状态 | 官方 repo 提供 1000L inference 代码、Triton kernels、PyTorch fallback 和 checkpoint 使用方式;完整大规模训练闭环、训练数据筛选和评测脚本仍不完全公开 |
Abstract:论文摘要解读
论文的 abstract 可以拆成三层。
第一,作者指出把 Diffusion Transformers 扩展到几百层时,会遇到一种不同于经典 exploding/vanishing gradients 的结构性 failure mode。模型可以看起来训练稳定很久,然后在很短时间内 loss 突然恶化。诊断显示,崩溃不是所有 token 表示一起无序爆炸,而是 token 表示被均值方向吸走,token 间的 centered variation 被压掉。
第二,作者把这个现象命名为 Mean Mode Screaming。所谓 mean mode,不是 feature channel 的均值,而是 sequence/token 维度上的均值子空间。给定 token 表示 $X \in \mathbb{R}^{T \times D}$,可以把它分成 token mean component 和 centered component。MMS 的关键症状是 residual writer 的梯度在均值方向上突然变得非常相干,随后 attention 的 Q/K 学习被压制,深层 token 变得几乎一样。
第三,论文提出 MV-Split Residuals。传统 LayerScale 或 ReZero 这类方法用同一个 scalar/vector gate 缩放整个 residual branch,它们能稳定深层网络,但也会一起压低 centered feature learning。MV-Split 则把残差更新投影到 token mean 和 centered subspace,分别使用 $\alpha$ 和 $\beta$ 控制。作者报告,在 matched 400-layer 对照中,MV-Split 比 LayerScale 收敛更快,且能稳定继续训练;在 1000-layer run 中,MV-Split 支撑了一个 13.64B 参数的 text-to-image DiT。
Motivation
Diffusion Transformer 的 scaling 经验大体来自两个方向:宽度、数据和训练算力继续放大;或者把 transformer block 堆得更深。深度有一个直观吸引力:如果每层承担更小的变换,模型可以用更长的 computation path 表达复杂的去噪/flow dynamics。但极深 residual network 的训练稳定性一直是硬问题。
LayerScale、ReZero、DeepNorm、zero-init residual writer 等方法的共同直觉是让早期 residual update 不要太大。它们确实能让网络在更深处起步,但这篇论文强调:超深 DiT 里的崩溃不只是 residual norm 太大,而是 residual update 的方向偏了。尤其在 sequence model 中,token mean direction 是一个特殊方向。attention matrix 的每一行 softmax 后和为 1,因此纯均值状态通过 attention 时天然是 fixed direction;centered variation 则取决于 $PAP$ 这样的 centered mixing operator,可能被逐层收缩。
如果一个稳定器只是把 residual branch 整体乘小,它会同时压小危险的 mean-coherent update 和有用的 centered update。这样当然更稳,但代价是 feature learning 变慢。MV-Split 的动机就是拆开这两个通道:该管住的是均值方向上的相干积累,不是所有 residual learning。
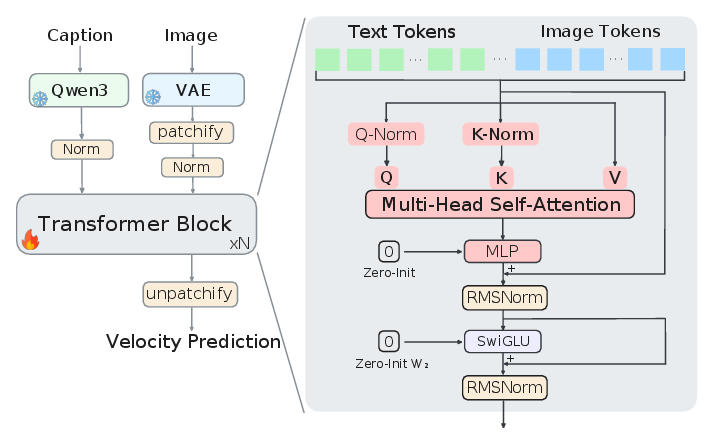
图:论文中的 backbone 示意。作者刻意使用 stripped-down single-stream DiT:image tokens 和 text tokens 拼成同一序列,靠 self-attention 交互;没有 AdaLN 或逐层 timestep modulation。这让论文更容易把崩溃归因到 residual/token-subspace 机制,而不是复杂条件调制。
先看崩溃:MMS 到底长什么样
MMS 的经验轨迹很有辨识度。一个 400-layer baseline 可以训练到某个时刻,然后出现全局梯度 spike。这个 spike 不是所有参数平均地变大,而是 residual writer 梯度里的 mean-coherent component 暴涨。随后 attention 的 Q/K 梯度下降数个数量级,深层 attention 继续保持 centered contraction,token cosine similarity 在深层迅速接近 1。
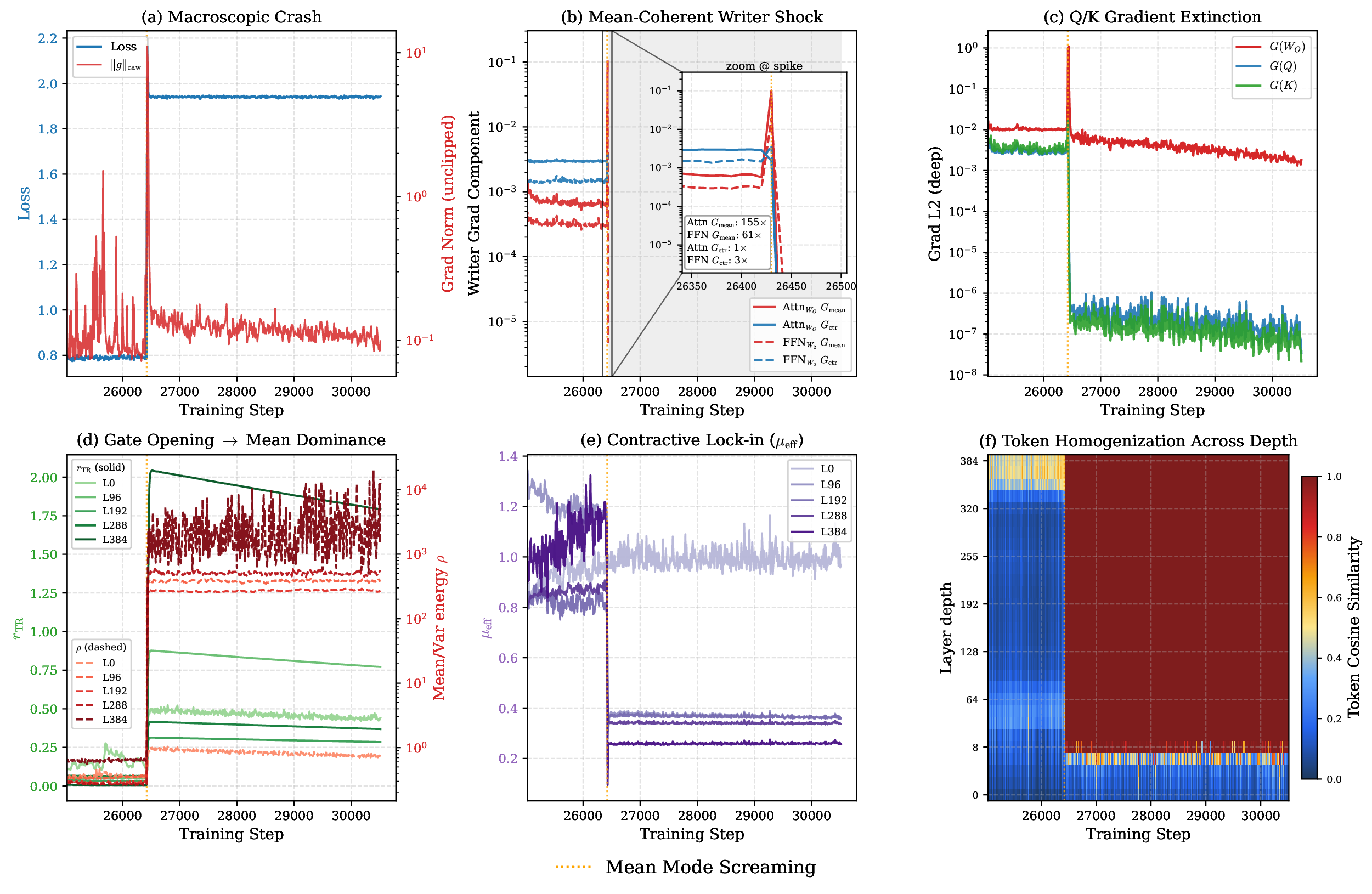
图:论文 Figure 3 的 MMS 诊断。关键读法是按时间顺序看:loss 和 raw grad norm 突然恶化;writer gradient 的 mean component 先尖峰;Q/K 梯度随后衰竭;residual branch 打开后 mean/centered energy ratio 上升;深层 token similarity 进入接近全同的状态。
这里有两个点容易误读。
第一,MMS 不是普通的 attention row collapse。论文的 standard-initialization appendix 里显示 RowDiv 仍然非零,说明 attention row 不是简单变成完全一样。真正的问题是子空间不平衡:row-stochastic attention 保留纯均值状态,centered component 的 retention 和 branch-side replenishment 又不够。
第二,MMS 也不是“均值没用,所以把均值删掉”。作者专门做了 timestep probe:这个 stripped-down backbone 没有显式 timestep embedding 或 AdaLN modulation,连续 flow time $t$ 很大程度可以从 image-token mean 中线性读出。也就是说,token mean 是危险方向,也是有用的 global-state carrier。硬性 centering 会删掉有用信息,MV-Split 选择的是 gain-limit new mean writes,而不是把 mean path 清零。
数学机制:均值子空间为什么会自我强化
令 $J=\frac{1}{T}\mathbf{1}\mathbf{1}^{\top}$ 是 token-mean projector,$P=I-J$ 是 centered projector。对 token 表示 $X$,有
\[X = JX + PX = \mu(X) + c(X)\]对 attention matrix $A$ 来说,因为每一行归一化,纯均值状态满足
\[A\mu(X)=\mu(X)\]centered component 则变成
\[c(AX)=PAPX\]因此它的能量受 $\lVert PAP\rVert_2$ 控制。如果深层 attention 在 centered subspace 上是 contractive 的,centered variation 会逐层被压掉,而 mean component 没有同样的自然衰减。
更关键的是 residual writer 的梯度。对 token-wise linear writer $W$,梯度可以写成
\[\nabla_W \mathcal{L} = \sum_t \delta_t y_t^{\top} = T\bar{\delta}\bar{y}^{\top} + \sum_t \tilde{\delta}_t\tilde{y}_t^{\top}\]第一项是 mean-coherent component,第二项是 centered component。若 token 输入和 backward adjoint 在不同 token 间开始对齐,第一项会以 $T$ 级别相干积累;centered 部分则更像抵消后的 diffusive accumulation。论文的 alignment amplification identity 进一步说明,这种放大和 token 间 activation/adjoin cosine alignment 有关。
崩溃后的 Q/K 梯度衰竭也有明确解释。若 value vectors 已经同质化,$V_j=\bar{v}$,那么 pre-softmax logits 的梯度会被 Softmax Jacobian 的 null space 消掉。直观说,attention 再怎么调 logits,所有 value 都差不多,输出也不会变太多,Q/K 就缺少有效学习信号;但 residual writer 的均值方向梯度仍然可以继续存在。
方法总览:MV-Split Residuals 做了什么
MV-Split 的核心公式是:
\[Z_l = X_l + \beta \odot P_{\mathrm{seg}}F_l + \alpha \odot J_{\mathrm{seg}}(F_l-X_l)\] \[X_{l+1}=\mathrm{RMSNorm}(Z_l)\]其中 $F_l=f_l(X_l)$ 是 residual branch output,$J_{\mathrm{seg}}$ 和 $P_{\mathrm{seg}}$ 是 segment-wise token projector。segment-wise 很重要:image tokens 和 text tokens 在同一序列里,但不应该用一个全局均值把图像和文本直接混在一起,所以作者对不同 segment 分别计算 mean 和 centered component。
这条公式可以拆成两条路径:
\[PZ_l = PX_l + \beta \odot PF_l\] \[JZ_l = (1-\alpha)\odot JX_l + \alpha \odot JF_l\]centered path 仍然是标准 residual-style update,靠 $\beta$ 控制;mean path 不是简单加上 $JF_l$,而是把 trunk mean 做 leaky replacement。这个区别正是 MV-Split 和 LayerScale/ReZero 的核心差异。
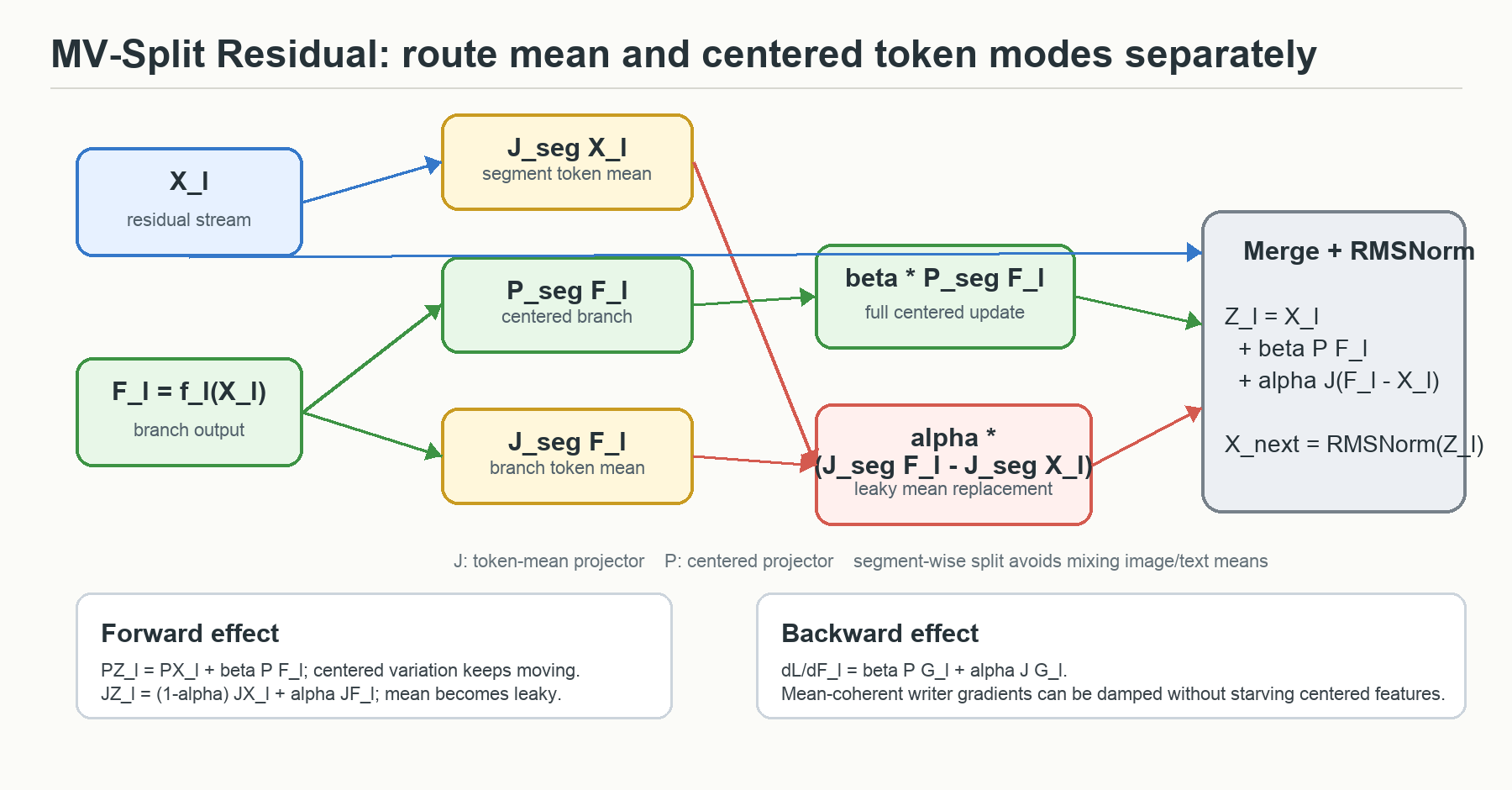
图:根据论文公式重绘的 MV-Split 机制图。绿色路径保留 centered branch update;红色路径用 $\alpha$ 控制 token mean replacement。下方 backward relation 表明,MV-Split 同时改变 forward mean dynamics 和 residual writer gradient 的 mean/centered gain。
反向传播也有对应结构。论文给出的简化形式是:
\[\frac{\partial \mathcal{L}}{\partial F_l} = \beta \odot PG_l + \alpha \odot JG_l\]也就是说,mean gradient 和 centered gradient 可以得到不同增益。若 $\alpha \ll \beta$,mean-coherent writer shock 被压住,但 centered feature learning 不必一起变得很弱。
LayerScale 的 merge 是
\[Z_l^{\mathrm{LS}}=X_l+\lambda_l\odot F_l\]投影到 mean subspace 后,LayerScale 仍然保留 $JX_l$,只缩放新注入的 $JF_l$。MV-Split 则把 $JX_l$ 自身也放进 leaky integrator:
\[JZ_l^{\mathrm{MV}}=(1-\alpha)\odot JX_l+\alpha\odot JF_l\]所以它不是 LayerScale 换个名字,也不是单纯更小学习率。它改变了 residual interface 在 token subspace 上的几何。
数据与模型全流程
论文的实验设置刻意保持简单,以便观察 residual-subspace failure。
| 阶段 | 对象 | Shape / Dim | 语义 | 产生者 | 消费者 |
|---|---|---|---|---|---|
| Raw image | ImageNet-2012 image | not fully specified in source text | pretraining target image | ImageNet-2012 | frozen VAE encoder |
| Image latent | $x_0$ | latent token grid, exact spatial shape not specified | data endpoint of rectified-flow path | frozen FLUX.2 VAE | DiT image token stream |
| Noise latent | $x_1$ | same as $x_0$ | Gaussian endpoint | sampler | path construction |
| Flow state | $z_t$ | same as latent | interpolated noisy latent | $z_t=(1-t)x_0+t x_1$ | DiT |
| Text tokens | caption / class text embedding | token length not specified | conditioning information | frozen Qwen3-0.6B text encoder | concatenated single-stream sequence |
| Transformer stream | $X_l$ | $T \times 1024$ | image/text unified token representations | DiT block stack | attention, FFN, MV-Split |
| Residual branch output | $F_l$ | $T \times 1024$ | attention or FFN writer output | transformer block branch | MV-Split merge |
| Output | velocity prediction | same latent shape as $x_0$ | rectified-flow target $x_0-x_1$ | DiT final projection | training loss / Euler sampler |
架构细节上,400L 和 1000L run 都使用 $d_{\mathrm{model}}=1024$,FFN dimension 3072,8 attention heads,head dim 128,MHA,SwiGLU,2D RoPE,non-affine RMSNorm,QK-Norm。400L 模型约 5.45B 参数,1000L 模型约 13.64B 参数。
这里最值得注意的是两个 deliberate simplification。
第一,论文使用 single-stream DiT,把 image tokens 和 text tokens 拼起来做 self-attention,而不是复杂的双流交互结构。
第二,主实验里没有 AdaLN 和 per-layer modulation。模型要从 noisy latent 本身推断连续时间 $t$。这让 timestep 信息如何在 token mean 中流动变成一个可观察问题,也让 residual merge 的作用更干净。
Training:训练目标和稳定器设置
训练目标是 rectified flow。给定数据 latent $x_0$ 和 Gaussian noise $x_1$,构造
\[z_t=(1-t)x_0+t x_1\]模型预测的 velocity target 是
\[v=x_0-x_1\]400L 对照实验共享 backbone、optimizer、batch size 和非 residual primitive。差异主要在 residual stabilization:
| Run | Depth | Params | Residual mode | Init / Gate | Hardware |
|---|---|---|---|---|---|
| DiT-400L-Baseline | 400 | 5.45B | none | zero-init $W_O,W_2$; other params standard init | 8 H100 |
| DiT-400L-LayerScale | 400 | 5.45B | LayerScale | learnable $\lambda$ with small init | 8 H100 |
| DiT-400L-MVSplit | 400 | 5.45B | MV-Split | $\alpha_{\mathrm{init}}=0,\beta_{\mathrm{init}}=1$ | 8 H100 |
| DiT-1000L-MVSplit | 1000 | 13.64B | MV-Split | $\alpha_{\mathrm{init}}=0,\beta_{\mathrm{init}}=0.03$ | 16 H100 |
optimizer 是 AdamW,global batch size 1024,warmup 1000 steps 后 constant LR,gradient clipping threshold 为 1.0,weight decay 0.1 只作用于 2D weights。论文特别指出,global gradient clipping 并不能解决 MMS,因为 clipping 是 scalar shrinkage:
\[\operatorname{clip}_{\tau}(G)=sG=sG_{\mu}+sG_c\]它不改变 mean component 和 centered component 的比例。当 $G_{\mu}$ 已经主导时,clipping 只会同时缩小本来就弱的 centered update,不能把更新方向转回 centered subspace。
Inference:采样和发布模型
官方 GitHub repo 提供了 1000-layer checkpoint 的 inference 入口。使用时需要三类 artifact:
| Artifact | 来源 | 作用 |
|---|---|---|
| DiT checkpoint | StableKirito/mvsplit-dit-1000l 的 model.pt | 1000-layer MVSplit-DiT 主体 |
| FLUX.2 AE | black-forest-labs/FLUX.2-dev 中的 VAE 权重 | latent/image 编解码 |
| Qwen3 text encoder | Qwen/Qwen3-0.6B | prompt embedding |
repo 的默认采样配置包括 image_size=256、num_inference_steps=35、cfg_scale=2.0、time_shift_alpha=4.0。README 明确说 Triton kernels 有 PyTorch fallback,因此没有 Triton 时也能跑,只是会慢。HF 上还存在一个社区 diffusers conversion,它把 transformer、scheduler、text encoder、tokenizer 和 VAE 封装成自定义 MVSplitDiTPipeline。
这说明发布模型具备基本 inference 可用性。但训练层面的复现仍不是闭环:官方 repo 面向采样,论文里的 8/16 H100 训练、ImageNet 预处理、post-training 约 50k curated images、SFT/DPO 细节和完整 evaluation scripts 没有全部变成可直接复跑的开源 recipe。
Experiments:证据是否支撑 claim
论文最有说服力的是 matched 400L 对照,而不是单独的 1000L 数字。原因是 1000L run 改了深度、参数量、硬件规模和 post-training pipeline,不能直接证明 MV-Split 比所有 baseline 更强;但 400L 对照能更干净地观察 residual stabilizer 的差异。
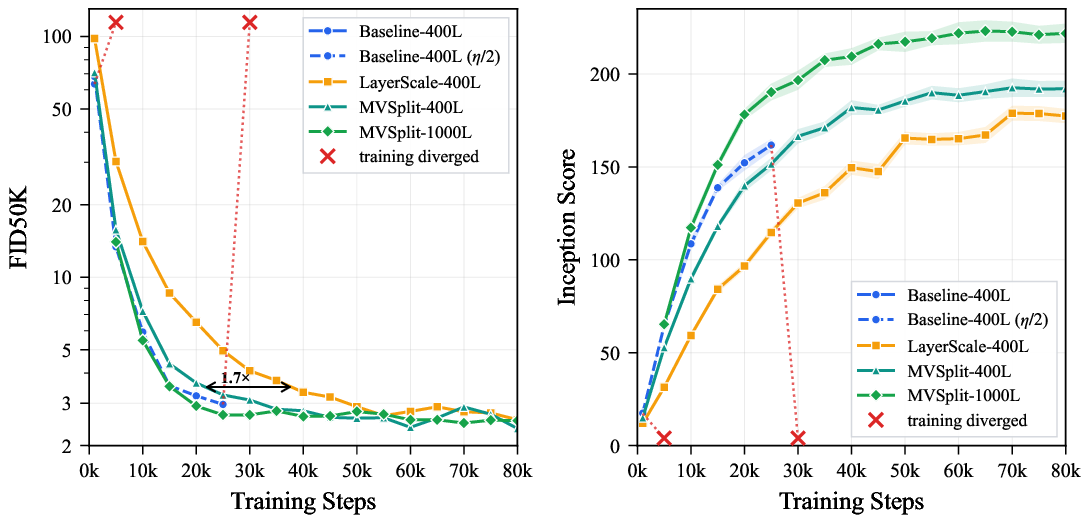
图:论文主结果曲线。400L baseline 在正常学习率下很早崩溃;半学习率 baseline 能先降到较好 FID,但随后仍崩;LayerScale 稳定但收敛慢;MV-Split 在 400L 对照中更快达到较低 FID。1000L 曲线是 scale-validation,不是 matched baseline。
主表中几个关键数字如下。采样使用 Euler,25 NFE,CFG scale $w=2.0$,报告 FID-50K / Inception Score。
| Run | 10k | 20k | 30k | 40k | 50k |
|---|---|---|---|---|---|
| 400L Base $\eta$ | diverged before first checkpoint | - | - | - | - |
| 400L Base $\eta/2$ | 5.92 / 108.6 | 3.22 / 152.2 | diverged | - | - |
| 400L LayerScale | 14.08 / 59.2 | 6.50 / 96.6 | 4.09 / 130.5 | 3.33 / 149.6 | 2.90 / 165.5 |
| 400L MV-Split | 7.23 / 89.8 | 3.64 / 139.9 | 3.09 / 166.5 | 2.79 / 182.0 | 2.60 / 185.5 |
| 1000L MV-Split | 5.47 / 117.3 | 2.92 / 178.2 | 2.68 / 196.6 | 2.64 / 209.4 | 2.77 / 217.3 |
这个表支持三个较稳的结论。
第一,只把 learning rate 降低不能解决问题。400L Base $\eta/2$ 早期效果不错,但 30k 附近仍然崩溃。
第二,LayerScale 确实能稳定训练,但代价是早期收敛慢。它缩小了 residual branch 的所有成分,mean 和 centered path 一起被压低。
第三,MV-Split 在 400L 对照里更像是“管住危险方向,而保留 feature learning”。论文的 writer-gradient mode decomposition 显示,MV-Split 能压住 mean-coherent component,同时让 centered component 保持在更高的稳定区间。
1000L run 的意义要谨慎表述。它证明这套 residual design 至少可以支撑一个 13.64B、1000 transformer blocks 的可采样 DiT,但它不是公平比较的 SOTA claim。论文自己也在 appendix 里说,GenEval 和 DPG-Bench 只是 text-conditioned calibration,不是和大型公开 T2I 系统做受控 SOTA 对比。
Ablations 和负结果:哪些直觉没有解决 MMS
论文的 appendix 对几个直觉方案做了负结果分析。
硬性 centering 看起来最直接:既然 mean path 危险,那把 $X$ 变成 $PX$ 不就行了?作者认为这会删掉有用 global information,尤其是 timestep/global context。timestep probe 显示 image-token mean 可以近乎线性预测 $t$,因此 mean path 不能简单清空。
attention reparameterization 也不够,比如 $A-I$、$I-A$ 或 row-stochastic interpolation。它们只改 attention branch,不保护 FFN branch 或 residual merge;而且 segment-wise mean mode 仍可能存在。
attention-output gating 也不等价于 MV-Split。token-local 或 feature/head-level gate 不是 token-space projector,它通常会把 mean 和 centered components 一起缩放。论文还提到 attention-only protection 可能让 spike 转移到未保护的 FFN branch。
Muon optimizer 也不是直接解法。Muon 在 parameter space 里正交化更新矩阵,可以改变 singular values,但如果 token gradients 已经求和成 mean-coherent direction,它不能自动实现 token-space split $G \mapsto \alpha JG+\beta PG$,也不能实现 forward leaky mean replacement。
这些负结果强化了论文的核心立场:MMS 不是单纯的 norm 问题、attention 问题或 optimizer 问题,而是 residual interface 在 token subspace 上缺少结构性控制。
工程实现:为什么 MV-Split 不是只写一行公式
1000 层模型会把每个 block 里的轻量操作放大成真实系统瓶颈。论文 appendix 说,为了在 8 到 16 张 H100 上训练,作者使用 activation checkpointing;这会在 backward 中重复执行 checkpointed blocks。因此 RoPE、QK-Norm、SwiGLU、MV-Split+RMSNorm 这类操作虽然单次不重,但会被反复 replay。
作者用 Triton 融合了 RoPE、QK-Norm、SwiGLU 和 MV-Split+RMSNorm。MV-Split+RMSNorm 的 fused kernel 不 materialize pre-normalized residual state,而是用 segment-wise sufficient statistics 做两遍 backward recomputation。论文报告,在 400-block profiling setup 中,这些 operators 的 aggregated self-CUDA time 从 1697.4 ms 降到 614.0 ms,in-loop optimizer-step wall-clock 从 5.87 s 降到 4.58 s,约 22.0% 下降。
这部分对复现很关键:如果只按论文公式用 eager PyTorch 写一个 MV-Split,功能上可以对,但 1000 层训练时 memory-bound overhead 会被深度和 checkpoint replay 放大。官方 repo 里确实提供了 kernels/fused_mvsplit_rmsnorm.py、rmsnorm.py、rope.py、swiglu.py 等文件,并说明有 PyTorch fallback。
Reproducibility:能复现什么,不能复现什么
我把复现状态分成三层。
第一层是 inference。官方 GitHub README 给了 sample.py,说明 checkpoint、FLUX.2 VAE、Qwen3 text encoder 的路径和采样参数。HF model card 也给了 Apache 2.0 license 和基本用法。因此“拿发布模型做 256x256 text-to-image sampling”是有明确入口的。
第二层是 method implementation。论文公式、backward derivation、Triton fusion 思路和 repo 文件结构足以让工程上理解 MV-Split 如何插入 transformer block。若已有 DiT 训练代码,把 standard residual merge 替换为 segment-wise MV-Split 是可实现的。
第三层是 full training reproduction。这里仍有明显缺口:ImageNet latent preprocessing、caption/text condition 构造、数据顺序、诊断采样、评估脚本、1000L post-training 的约 50k curated images、SFT/DPO pipeline 并没有形成完整开源训练 recipe。再加上 400L/1000L 本身需要 8 到 16 张 H100,复现实验成本很高。
所以这篇论文适合两种读法:如果目的是研究超深 transformer 的训练动力学,它给了很有价值的诊断指标和机制假设;如果目的是直接复现 1000L 训练,则目前公开材料还不够闭环。
我认为最有价值的启发
第一,深度稳定性不能只看 scalar norm。MMS 展示了一个例子:global grad norm、loss、activation norm 都可能只是后验症状;真正的早期信号在 gradient subspace composition、token similarity、centered retention、attention contraction 这些结构性指标里。
第二,sequence mean 不是无害统计量。很多视觉 transformer 讨论 token mixing 时关注 attention map、rank collapse 或 feature covariance,但这篇论文把 token mean 作为一个残差链中的 dynamical state 来看。对多模态生成尤其重要,因为 global style、timestep、caption/image interaction 都可能走 mean-like channel。
第三,LayerScale/ReZero 这类整体 gate 的上限在这里很清楚:它们能保守地压住所有 residual update,但没有区分“危险的均值相干积累”和“有用的中心化特征更新”。当网络很深时,这个区分可能比单纯 gate 大小更关键。
第四,视频、3D、长上下文生成可能更需要这类分析。论文里 writer-gradient mean component 的相干项可以随 token length 放大。视频和 3D 生成往往有更长 token sequence、更复杂的时空/视角结构,如果 token alignment 发生,mean-coherent accumulation 的压力可能更大。
仍然需要谨慎的地方
这篇论文的机制解释很完整,但仍有边界。
首先,MMS 的精确 onset time 还不能被闭式预测。论文的 alignment law 能解释 spike 发生时为什么会放大,但什么时候跨过临界状态,仍取决于 representation、backward adjoint、optimizer momentum、data order 和 mini-batch statistics 的耦合演化。
其次,Softmax attention 的论证不能直接迁移到所有生成 backbone。row-stochastic attention 保留 pure mean state、value homogenization 压制 Q/K gradient,这些都依赖 transformer attention。对 convolutional diffuser、state-space model 或 hybrid mixer,writer-gradient decomposition 可能仍有参考价值,但 attention-specific lemma 不能直接套用。
第三,1000L run 不是受控 scaling law。它说明 MV-Split 可以支撑一个极深 DiT 训练并生成图像,但还不能回答“1000 层是否比更宽或更浅的同算力模型更优”。论文主贡献是稳定机制,不是生成模型 scaling frontier 的完整答案。
总结
Mean Mode Screaming 这篇论文可以看成两件事的结合:一个训练动力学诊断故事,以及一个很具体的 residual interface 设计。
诊断故事是:超深 Post-Norm DiT 可能进入 mean-dominated token homogenization。attention 保留 token mean,centered component 被深层 mixing 收缩,writer gradient 在 token mean 方向相干积累,最终触发 mean-coherent spike 和 Q/K gradient extinction。
设计故事是:MV-Split Residuals 把 residual branch 分解成 segment-wise token mean 和 centered component,用 $\alpha$ 控制 mean leaky replacement,用 $\beta$ 保留 centered update。相比 LayerScale/ReZero,它不是把所有 residual learning 一起缩小,而是专门限制危险的 mean path。
我的最终判断是:这篇论文不应该只被当成“1000 层 DiT demo”。它更像是一篇关于超深生成 transformer 训练稳定性的机制论文。对做视频生成、3D 生成、长上下文多模态生成的人,最值得带走的是一套诊断方法:不要只看 loss 和 norm,要看 token mean/centered decomposition、writer gradient mode、attention centered contraction、Q/K gradient 是否被熄灭。MV-Split 本身是否会成为通用组件还需要更多架构和任务验证,但它指出的问题边界很清楚,工程上也足够具体。
Recommended citation: Pengqi Lu. Mean Mode Screaming: Mean--Variance Split Residuals for 1000-Layer Diffusion Transformers. arXiv:2605.06169, 2026.
Download Paper