
MeanFlow:一步生成不是蒸馏,而是学习平均速度场
MeanFlow:一步生成不是蒸馏,而是学习平均速度场
论文:Mean Flows for One-step Generative Modeling
作者:Zhengyang Geng, Mingyang Deng, Xingjian Bai, J. Zico Kolter, Kaiming He
时间 / 版本:arXiv v1 2025-05-19;NeurIPS 2025 Main Conference Track
类别:One-step generation / Flow Matching / Diffusion models
链接:Paper / PDF / NeurIPS Proceedings
检索日期:2026-05-24
开篇点评:一步生成的关键不是“少跑几步”,而是别把积分留到推理时
扩散模型和 Flow Matching 的采样慢,表面上是 NFE 多:模型要从噪声走到数据,中间反复调用网络。很多 one-step 方法的直觉是把一个强 teacher 的多步轨迹压缩到一步,或者给网络加 consistency 约束,让同一条轨迹上的不同点输出一致。
MeanFlow 这篇论文换了一个角度。它不是从“怎么蒸馏一个已有采样器”出发,而是回到 Flow Matching 的连续时间定义:如果传统 Flow Matching 学的是每个时刻的 instantaneous velocity $v(z_t,t)$,那一步生成真正需要的其实是从 $t=1$ 到 $r=0$ 这整个区间的 average velocity。前者是切线,后者是位移除以时间。
我的判断是,MeanFlow 最值得读的地方不是 FID 数字本身,而是它给 one-step generation 提供了一个比较干净的训练目标:把“推理时数值积分”转化成“训练时学习区间平均速度”。如果这个目标学得准,采样时就不需要沿着 ODE 一点点走,直接从噪声减去平均速度就能得到样本。
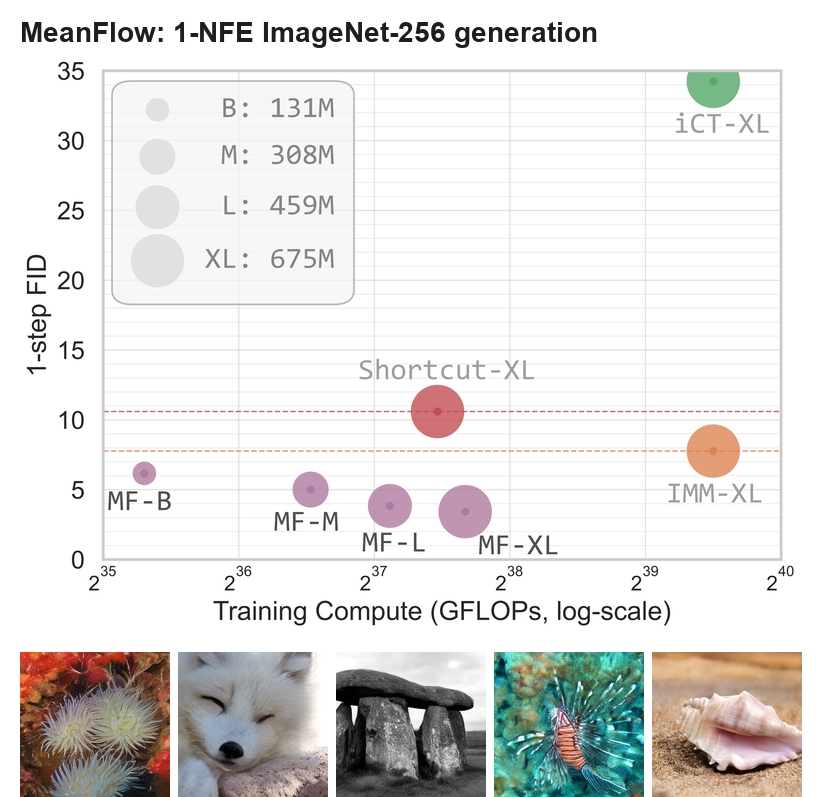
图:基于官方 arXiv source 重排的 teaser。左侧是 ImageNet-256 上 1-NFE FID 与训练计算量的关系,右侧是论文展示的 1-NFE 生成样例。它支持的核心信息是:MeanFlow 在单次函数调用下,比此前 one-step diffusion/flow baseline 更接近多步模型的质量。
Paper Card
| 项目 | 信息 |
|---|---|
| Paper | Mean Flows for One-step Generative Modeling |
| Authors | Zhengyang Geng, Mingyang Deng, Xingjian Bai, J. Zico Kolter, Kaiming He |
| Date / Version | submitted 2025-05-19, arXiv:2505.13447v1 |
| Venue | NeurIPS 2025, Advances in Neural Information Processing Systems 38, Main Conference Track |
| Category | one-step generative modeling, Flow Matching, diffusion/flow models |
| Code / Checkpoint | official code/checkpoint not specified in arXiv source or NeurIPS page as of 2026-05-24 |
| Dataset / Tokenizer | ImageNet 256 x 256, CIFAR-10; ImageNet experiments use a pretrained SD VAE tokenizer from Hugging Face |
| Core claim | learn average velocity fields so one-step diffusion/flow generation can be trained from scratch, without teacher distillation or curriculum |
| 复现状态 | method and pseudocode are clear; full reproduction still needs official implementation details, compute budget, exact data preprocessing and evaluation scripts |
Abstract:论文摘要解读
论文摘要把 MeanFlow 定义成一个 self-contained 的 one-step generative modeling 框架。这里的 self-contained 很重要:作者强调它不需要先训练一个 multi-step teacher,不需要从 teacher 蒸馏,也不需要 consistency model 里常见的 discretization curriculum。模型从头训练,目标就是直接学习平均速度场。
传统 Flow Matching 学的是某个时间点的瞬时速度 $v(z_t,t)$。这很好训练,因为给定数据 $x$、噪声 $\epsilon$ 和线性路径 $z_t=(1-t)x+t\epsilon$,条件速度通常很简单,例如:
\[v_t=\epsilon-x\]问题在推理阶段:即使每个瞬时速度都对,真实 marginal trajectory 仍可能是弯的,粗步长 Euler 积分会累积误差,所以一步采样通常很差。
MeanFlow 引入 average velocity $u(z_t,r,t)$,也就是从时间 $t$ 到更早时间 $r$ 的平均位移速度。它真正想学的是:给我当前点 $z_t$,以及区间端点 $(r,t)$,我直接告诉你跨过这个区间该走多远。一步生成就是特殊区间 $(0,1)$。
摘要里的实验 claim 是:MeanFlow-XL/2 在 ImageNet 256 x 256 上用 1-NFE 达到 FID 3.43,显著优于之前从头训练的 one-step diffusion/flow 方法;2-NFE 版本达到 FID 2.20,已经接近 DiT / SiT 这类 250-step 量级模型。这个 claim 的强度比较高,但要注意它主要建立在 ImageNet-256/FID 这个标准设置上,代码和 checkpoint 没公开时仍不能做第三方运行复核。
Motivation
Flow Matching 的优点是概念干净:构造一条从 data 到 noise 的路径,然后学习这条路径上的 velocity field。以线性路径为例:
\[z_t = (1-t)x + t\epsilon,\qquad v_t = \epsilon - x\]训练时,网络拟合 velocity;采样时,从 $z_1=\epsilon$ 出发,解 ODE 走回 $z_0=x$。瓶颈在于,网络学的是 instantaneous velocity,而采样需要的是时间积分。
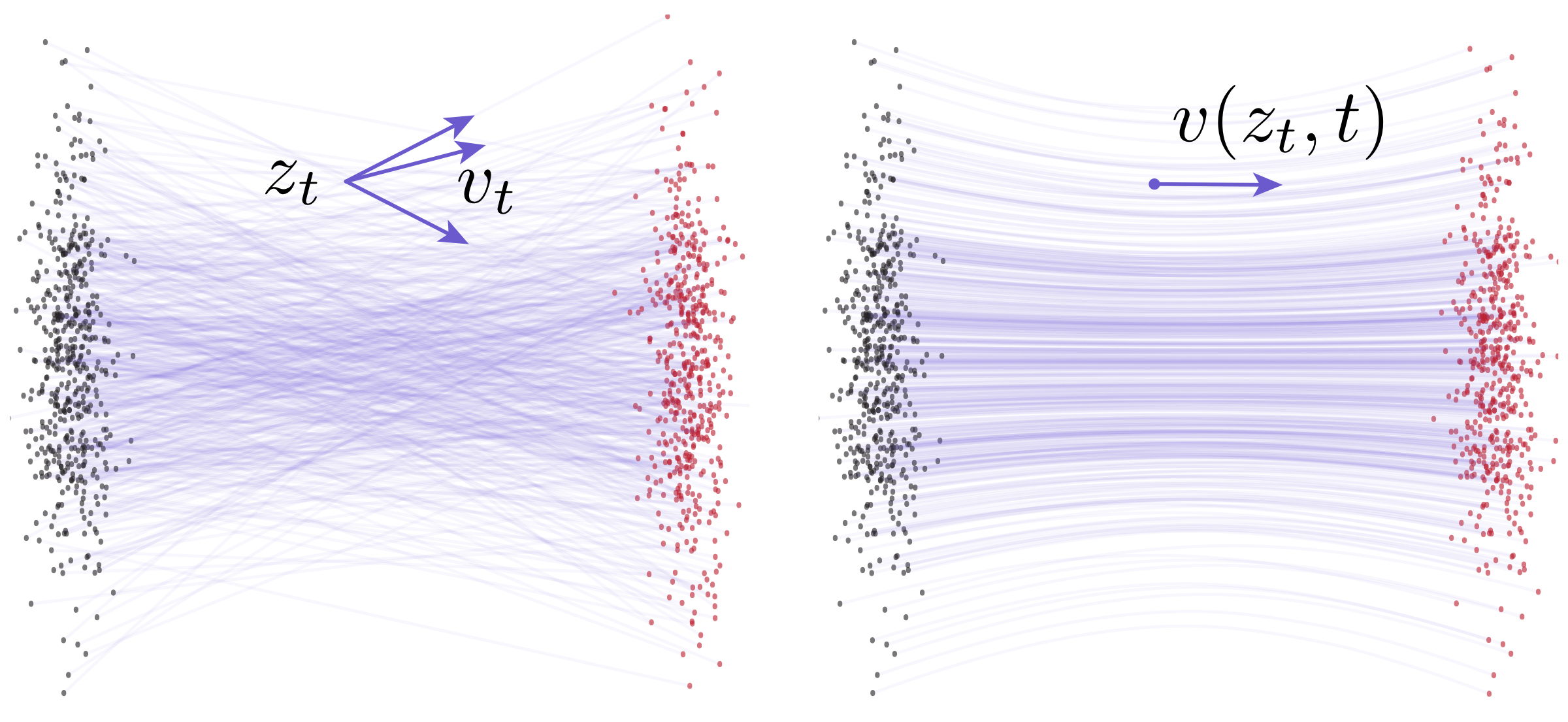
图:官方 Flow Matching 示意图。左边强调同一个路径中间点可以来自不同的数据与噪声组合,对应不同 conditional velocity;右边是 marginal velocity field。这个图说明:即使 conditional path 可以是直线,marginal velocity 诱导的整体轨迹也通常是弯的。
一步生成困难就在这里。多步采样可以用很多小步近似积分;一步采样等价于用一个巨大步长近似整段积分。如果轨迹弯,瞬时切线并不等于整段位移,粗步长自然会偏。
Consistency Models、Shortcut Models、IMM 等方法也在做 one-step 或 few-step,但它们往往从网络输出的一致性、两时间点 self-consistency、或 teacher/trajectory matching 出发。MeanFlow 的动机是:能不能直接定义一个真实存在的 ground-truth field,让 one-step 模型不是靠启发式约束,而是有明确的回归目标?
直观效果:先看它能做什么
论文最直接的效果是 ImageNet 256 x 256 class-conditional generation。MeanFlow-XL/2 用 1-NFE 得到 FID 3.43。对比同类 one-step diffusion/flow baseline,Shortcut-XL/2 是 FID 10.60,iCT-XL/2 是 34.24;如果把 IMM 的 one-step 但 1 x 2 guidance 算进来,它是 FID 7.77。

图:官方 arXiv source 中的 1-NFE 生成样例,来自 MeanFlow-XL/2,论文报告该模型 ImageNet-256 FID 为 3.43。定性图只能说明视觉样例合理,真正支撑 claim 的仍是 FID-50K 和 baseline 表。
这里要把“one-step”和“one-NFE”分清楚。很多方法说 one-step,但如果采样时还要分别跑 conditional/unconditional 两次 CFG,那么实际 NFE 是 2。MeanFlow 的 CFG 设计把 guidance 融进目标 field,采样时仍然只调用一次网络。这是它和不少 one-step baseline 的关键区别。
方法总览:核心思想和系统结构
MeanFlow 的方法可以压缩成一句话:训练网络预测区间平均速度 $u(z_t,r,t)$,而不是预测瞬时速度 $v(z_t,t)$。
平均速度定义为:
\[u(z_t,r,t)=\frac{1}{t-r}\int_r^t v(z_\tau,\tau)d\tau\]它和瞬时速度的关系来自定义本身。把两边乘以区间长度,再对结束时间求导,可以得到 MeanFlow Identity:
\[u(z_t,r,t)=v(z_t,t)-(t-r)\frac{d}{dt}u(z_t,r,t)\]这条式子的意义很直接:如果知道当前瞬时速度,再知道平均速度场随时间的总导数,就可以构造平均速度本身。它把原本不可直接计算的积分目标,改写成一个可训练的局部关系。
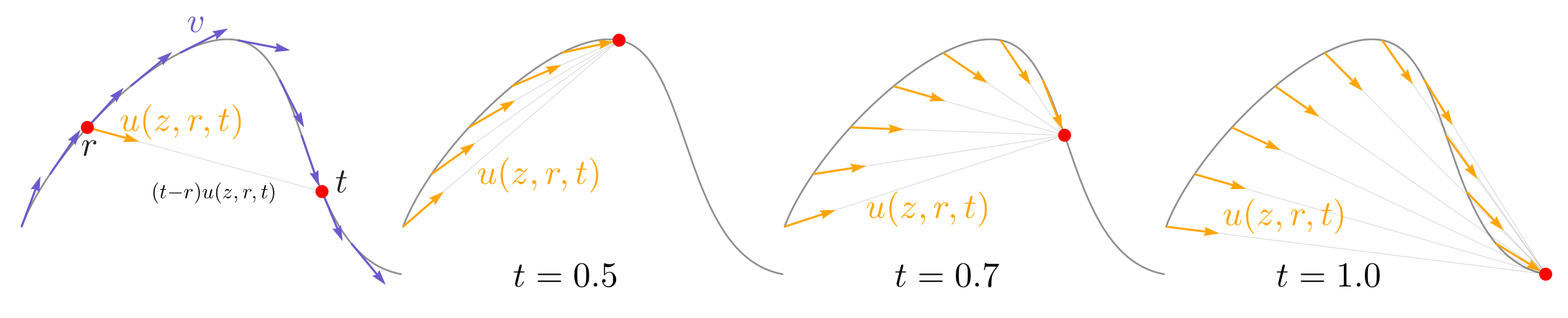
图:官方 average velocity field 示意图。紫色箭头是路径切线方向,橙色箭头指向跨区间位移方向。右侧不同结束时间展示同一个 average velocity field 依赖两个时间变量,而不是传统 Flow Matching 的单时间变量 velocity。
为了算总导数,论文展开:
\[\frac{d}{dt}u(z_t,r,t)=v(z_t,t)\partial_z u+\partial_t u\]实现上这就是对 average velocity network $u_\theta(z,r,t)$ 做 JVP,tangent 是 $(v,0,1)$。注意 $r$ 对 $t$ 独立,所以 $\frac{dr}{dt}=0$。这个细节很重要:ablation 里把 JVP tangent 改错,FID 会从 61.06 崩到 137.96、268.06 或 329.22。
数据全流程:输入、表示、shape 和语义
这篇论文不是数据集论文,数据流程相对标准,但 model/data tensor 的流向需要讲清楚。
| 阶段 | 对象 | Shape / Dim | 语义 | 产生者 | 消费者 |
|---|---|---|---|---|---|
| Raw image | ImageNet image | 256 x 256 x 3 | class-conditional generation target | ImageNet | VAE tokenizer |
| Latent image | VAE latent | 32 x 32 x 4 | 训练和生成所在 latent space | pretrained SD VAE tokenizer | DiT/ViT backbone |
| Data latent | $x$ | same as latent image | 目标样本 latent | VAE encoder | path construction |
| Noise | $\epsilon$ | same as data latent | prior sample | Gaussian prior | path construction / sampling |
| Time pair | $r,t$ | two scalars, with $r\le t$ | average velocity 的区间端点 | sampler | network conditioning / JVP |
| Noisy latent | $z_t$ | same as data latent | 路径上时间点的样本 | $z_t=(1-t)x+t\epsilon$ | MeanFlow network |
| Conditional velocity | $v_t$ | same as data latent | sample-conditional instantaneous velocity | $v_t=\epsilon-x$ | MeanFlow target |
| Average velocity prediction | $u_\theta(z_t,r,t)$ | same as data latent | 区间 $[r,t]$ 的平均速度 | network | loss / sampling |
| Output sample | $\hat{x}$ | 32 x 32 x 4 latent, decoded to 256 x 256 image | generated image | one-step sampler + VAE decoder | evaluation |
ImageNet 实验使用 latent generation:图像先通过 pretrained VAE tokenizer 变成 32 x 32 x 4 latent,模型在 latent 上训练。CIFAR-10 实验则直接在 32 x 32 x 3 pixel space 上做 unconditional generation。
这里的训练数据没有额外 teacher trajectory。每个 batch 只需要 $x$、$\epsilon$、$r,t$,再构造 $z_t$ 和 $v_t$。这也是论文强调 from scratch 的原因:监督信号来自 Flow Matching 的条件速度,而不是一个预训练扩散模型的多步输出。
Training:监督信号、loss 和优化目标
训练时的关键目标是:
\[u_{\mathrm{tgt}} = v_t - (t-r)\left(v_t\partial_z u_\theta+\partial_t u_\theta\right)\] \[\mathcal{L}(\theta)=\mathbb{E}\left\|u_\theta(z_t,r,t)-\mathrm{sg}(u_{\mathrm{tgt}})\right\|_2^2\]其中 $\mathrm{sg}$ 是 stop-gradient。这个 stop-gradient 不是小技巧,而是让训练可行的关键:目标里含有 $u_\theta$ 的导数,如果不截断,优化会涉及更高阶梯度。论文的说法是,JVP 只引入额外一次类似 backward 的开销,不需要 double backprop。
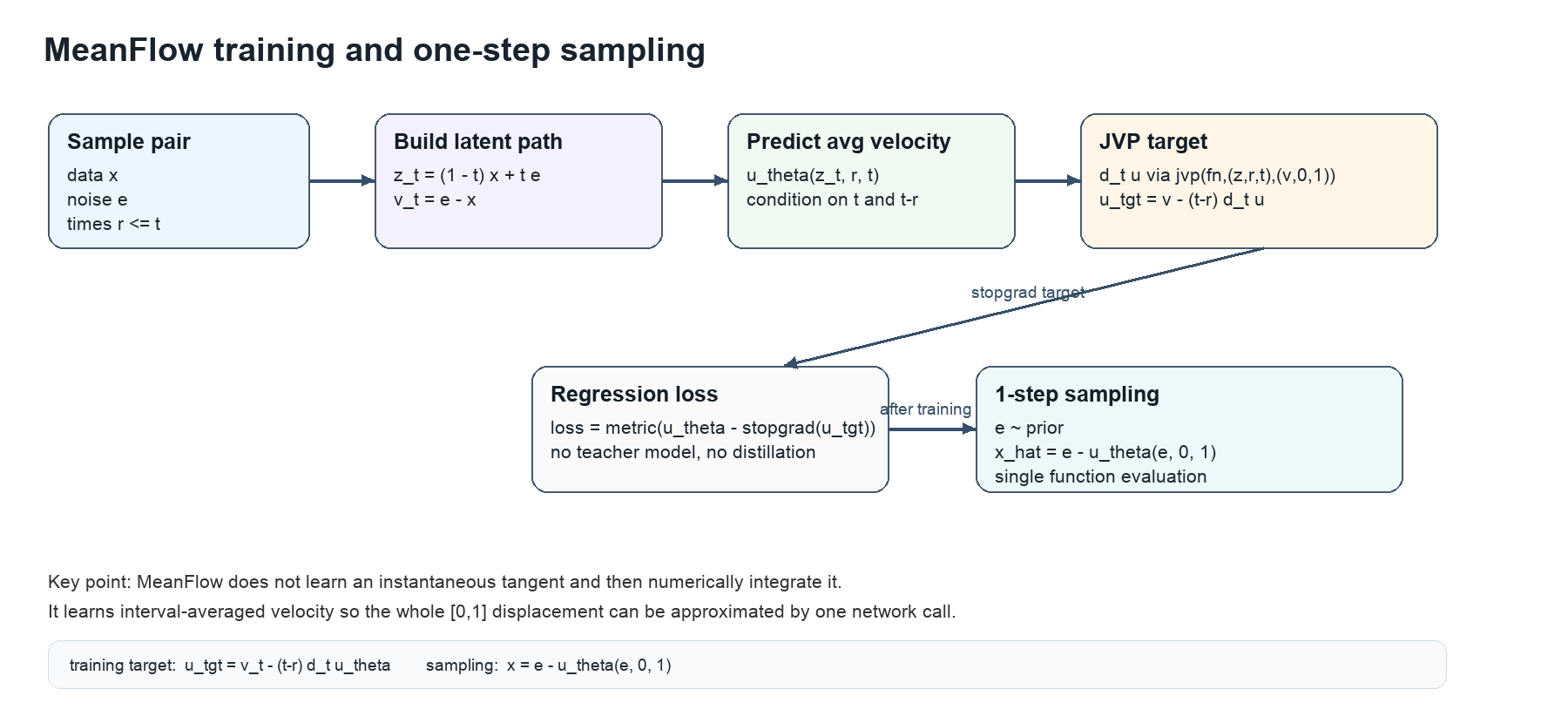
图:根据论文伪代码重绘的训练和采样流程。训练时从数据、噪声和时间区间构造路径点与条件速度,通过 JVP 得到平均速度的时间总导数,形成 stop-gradient target;采样时只需一次平均速度预测。
论文给出的 ImageNet 主要配置如下:
| 配置项 | ImageNet 256 x 256 |
|---|---|
| Backbone | DiT-style ViT with adaLN-Zero |
| Latent | SD VAE latent, 32 x 32 x 4 |
| B/4 ablation | 12 depth, hidden 768, 12 heads, patch 4 x 4, 131M params |
| XL/2 main | 28 depth, hidden 1152, 16 heads, patch 2 x 2, 676M params |
| Optimizer | Adam |
| LR | 0.0001 constant |
| Batch size | 256 |
| EMA | 0.9999 |
| Main training | 240 epochs; XL/2+ uses 1000 epochs |
| $r\ne t$ ratio | 25% for main ImageNet models |
| Time sampler | lognorm(-0.4, 1.0) |
| Conditioning | positional embedding on $t$ and $t-r$ |
| Adaptive weight | $p=1.0$ |
一个容易误读的点是,MeanFlow 不是完全抛弃 instantaneous velocity。训练 target 仍然需要 $v_t=\epsilon-x$,只是最终网络输出的是 average velocity。换句话说,它把 Flow Matching 的监督信号作为局部锚点,再通过 MeanFlow Identity 把监督传播到 $(r,t)$ 区间上。
Inference:测试时到底怎么生成结果
MeanFlow 的采样公式非常短:
\[z_r=z_t-(t-r)u_\theta(z_t,r,t)\]一步生成就是:
\[z_0=z_1-u_\theta(z_1,0,1),\qquad z_1=\epsilon\]所以 1-NFE 的含义很严格:从 prior 采样一次噪声,把 $(r,t)=(0,1)$ 传给网络,调用一次 $u_\theta$,再用 VAE decoder 解码回图像。
few-step 也自然成立。比如可以把 $[0,1]$ 拆成两个区间,分别调用 $u_\theta(z_t,r,t)$。论文报告 MeanFlow-XL/2+ 在 2-NFE 下达到 FID 2.20,已经接近 DiT-XL/2 的 FID 2.27 和 SiT-XL/2 的 FID 2.06,但后两者使用 250 x 2 NFE。
CFG 也不是推理时临时做两次 forward。论文把 guided instantaneous field 定义成:
\[v^{\mathrm{cfg}}(z_t,t\mid c)=\omega v(z_t,t\mid c)+(1-\omega)v(z_t,t)\]然后学习由这个 guided field 诱导的 average velocity $u_{\mathrm{cfg}}$。因此采样时直接用一个 conditional MeanFlow 输出,不需要再做 conditional/unconditional 线性组合。这就是它保持 1-NFE CFG 的机制。
Evaluation:验证集、指标和 baseline 是否公平
主实验是 ImageNet 256 x 256 class-conditional generation,使用 FID-50K。模型在 latent space 上训练,baseline 表里区分了三类对象:从头训练的 one-step diffusion/flow、其它生成范式作为参考、多步 diffusion/flow 模型作为上界参考。
| 方法 | Params | NFE | FID |
|---|---|---|---|
| iCT-XL/2 | 675M | 1 | 34.24 |
| Shortcut-XL/2 | 675M | 1 | 10.60 |
| MeanFlow-B/2 | 131M | 1 | 6.17 |
| MeanFlow-M/2 | 308M | 1 | 5.01 |
| MeanFlow-L/2 | 459M | 1 | 3.84 |
| MeanFlow-XL/2 | 676M | 1 | 3.43 |
| IMM-XL/2 | 675M | 1 x 2 | 7.77 |
| MeanFlow-XL/2+ | 676M | 2 | 2.20 |
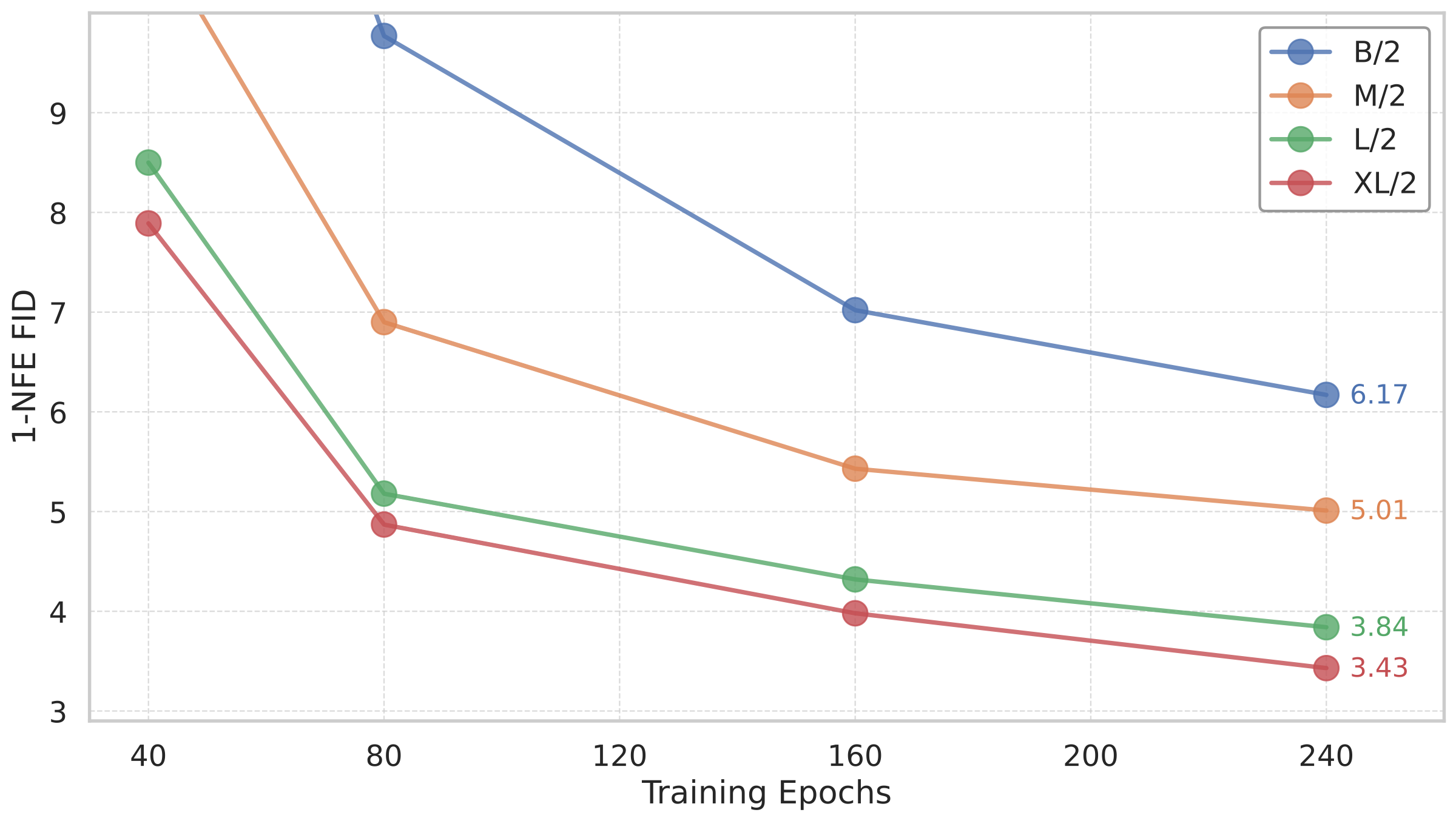
图:官方 scaling 曲线。随着模型从 B/2 到 XL/2、训练从 40 到 240 epochs 增加,1-NFE FID 持续下降。它支持的 claim 是 MeanFlow 在 DiT-style backbone 上有类似扩散 Transformer 的 scaling 行为。
baseline 公平性上,论文做了几件比较好的事:明确报告 NFE;把 CFG 额外调用用 x2 标出来;同类比较尽量用 XL/2 参数规模;并且说明 MeanFlow 从 scratch 训练,没有 teacher distillation。
但也有边界。第一,所有主结论主要来自 ImageNet-256/FID,不能直接推出 text-to-image 或 video 模型也同样成立。第二,CIFAR-10 上 MeanFlow FID 2.92,接近但不超过 iCT 的 2.83、sCT 的 2.97,说明方法不是在所有小型 benchmark 上压倒性领先。第三,训练 compute、代码细节和评估脚本没有完全公开,外部复核仍受限。
实验与证据:哪些 claim 被支持,哪些还不够
强证据:平均速度目标对 1-NFE 有效。 在 B/4 ablation 中,当 $r\ne t$ 的比例为 0% 时,模型退化成标准 Flow Matching,1-NFE FID 是 328.91,基本不可用;加入 25% 的 $r\ne t$ 后,FID 降到 61.06。这个实验直接对应论文的核心机制:如果永远只学瞬时速度,一步采样解决不了整段积分。
强证据:JVP 方向不是可有可无。 正确 tangent $(v,0,1)$ 得到 FID 61.06;错误 tangent $(v,0,0)$、$(v,1,0)$、$(v,1,1)$ 分别恶化到 268.06、329.22、137.96。这个 destructive ablation 说明 MeanFlow Identity 里的总导数结构确实在起作用,而不是“多加一个 time condition”就够了。
中等证据:时间参数化和采样分布影响质量,但不是唯一关键。 $(t,t-r)$ embedding 最好,FID 61.06;直接用 $(t,r)$ 是 61.75,只用 $t-r$ 也有 63.13。lognorm(-0.4,1.0) 比 uniform 更好。结论是这些设计会影响数值表现,但 MeanFlow 框架本身对具体 time embedding 不极端脆弱。
强证据:CFG 能保留 1-NFE 并显著提升 FID。 B/4 ablation 中不使用 CFG 是 61.06,$\omega=2.0$ 到 20.15,$\omega=3.0$ 到 15.53。附录里进一步引入 $\kappa$ 混合 conditional/unconditional average velocity,在固定 effective guidance scale 为 2.0 时从 20.15 改到 18.63。
证据不足:大规模开放复现。 论文有清晰伪代码和配置表,但没有官方代码、checkpoint、exact training logs、FID evaluation command。对于 ImageNet-256 这种大算力实验,缺少这些材料会让复现风险明显上升。
复现与工程风险
| 风险 | 具体原因 | 影响 |
|---|---|---|
| 官方代码缺失 | arXiv source 和 NeurIPS page 未给官方 GitHub | 只能按伪代码重写,容易在 JVP、stop-gradient、time sampling 上出现细节偏差 |
| 算力成本高 | ImageNet-256 XL/2 训练 240 epochs,XL/2+ 1000 epochs | 复现主结果需要较大训练预算 |
| JVP 实现容易错 | tangent 必须是 $(v,0,1)$,且 target 需要 stop-gradient | 小实现差异可能直接导致训练崩坏或 FID 大幅恶化 |
| CFG 细节复杂 | effective scale $\omega’$、$\omega$、$\kappa$、trigger interval 都有配置 | 复现 1-NFE CFG 结果需要严格跟配置 |
| 结论外推有限 | 主实验集中在 ImageNet-256 class-conditional image generation | text-to-image、video、audio、3D 任务是否同样有效需要重新验证 |
| VAE/tokenizer 依赖 | ImageNet 使用 SD VAE latent,CIFAR 使用 pixel space | 不同 latent representation 可能改变训练稳定性和 FID |
如果要工程复现,最小可行路线不是直接冲 XL/2,而是先做 CIFAR-10 或 ImageNet B/4:实现 $r,t$ sampler、JVP target、stop-gradient、adaptive weighting;确认 $r\ne t$ 和错误 JVP ablation 能复现趋势,再扩大模型。
总结
MeanFlow 的价值在于,它把 one-step generation 从“把多步模型压扁”的工程路线,拉回到 Flow Matching 的连续时间基础上。它指出一步采样真正缺的不是更强的 Euler solver,而是直接建模跨区间位移的 average velocity field。
这篇论文最干净的机制链条是:平均速度定义给出 MeanFlow Identity;Identity 通过 JVP 变成可训练 target;stop-gradient 避免高阶优化;网络输出 $u_\theta(z_t,r,t)$ 后,采样时直接:
\[z_0=z_1-u_\theta(z_1,0,1)\]这条链条比很多 consistency heuristic 更容易解释,也有 ablation 直接验证关键环节。
实验上,ImageNet-256 的 1-NFE FID 3.43 是很强的结果,2-NFE FID 2.20 也说明 few-step diffusion/flow 不一定必须依赖 teacher distillation 才能接近多步模型。但我不会把它解读成“one-step 已经完全解决”。CIFAR-10 只是 competitive;代码和 checkpoint 未公开;开放复现、跨模态扩展、训练稳定性、以及与 REPA/RAE/更强 backbone 的组合空间都还没充分展开。
对后续研究来说,MeanFlow 给了一个很好的可复用问题框架:如果任务的推理瓶颈来自连续过程积分,能不能把目标从 instantaneous quantity 改写成 interval-averaged quantity,并在训练时用微分恒等式约束它?这比单纯调采样器更接近问题本质。
参考来源
- arXiv:2505.13447 - Mean Flows for One-step Generative Modeling:论文元信息、摘要、PDF 和 TeX source。
- NeurIPS Proceedings 2025:确认该论文为 NeurIPS 2025 Main Conference Track。
- Official arXiv TeX source, retrieved 2026-05-24:
meanflow.tex、sections/method.tex、sections/experiments.tex、sections/appendix.tex、tables/*.tex、figs/*.pdf、imgs/*.png。 - SD VAE tokenizer on Hugging Face:论文附录中用于 ImageNet latent representation 的 VAE tokenizer 链接。
Recommended citation: Geng et al., Mean Flows for One-step Generative Modeling, NeurIPS 2025.
Download Paper
Recommended citation: Zhengyang Geng et al. Mean Flows for One-step Generative Modeling. NeurIPS 2025.
Download Paper