
Seedance 2.0:视频生成从单次出片走向多模态创作引擎
Seedance 2.0:视频生成从单次出片走向多模态创作引擎
论文:Seedance 2.0: Advancing Video Generation for World Complexity 作者:ByteDance Seed / Team Seedance et al. 时间 / 版本:arXiv v1, submitted on 2026-04-15 类别:Computer Vision and Pattern Recognition 链接:Paper / Official Page / Volcano Engine
开篇点评:这篇论文到底解决了什么问题
Seedance 2.0 这篇更准确地说是一份 model card,不是一篇公开训练配方的算法论文。它真正回答的问题不是“一个新 loss 如何工作”,而是 ByteDance Seed 如何把视频生成产品从 text-to-video 单点能力,推进到 text、image、video、audio 多模态参考、编辑、延展和原生音画联合生成的统一接口。
这件事对视频生成很关键。真实创作流程不会只给模型一句 prompt,然后接受一次抽卡结果。创作者更常见的需求是:让某个角色保持一致;让镜头跟随某个动作节奏;让画风来自参考图;让声音和口型、动作、背景音对齐;让已有视频继续往前或往后延展;还要能局部改角色、场景或剧情。Seedance 2.0 的定位就是把这些能力放进同一个闭源商业模型,而不是让用户在多个工具之间拼接。
我的判断是:这篇 paper 的价值在于它把 2026 年商业视频生成的竞争维度说得很清楚。单纯“视频像不像真”已经不够了,真正的壁垒变成了多模态控制面、音画同步、复杂运动、导演式镜头语言、reference/editing/continuation 的任务覆盖,以及这些能力在产品中的可用率。
Paper Card
| 项目 | 信息 |
|---|---|
| Paper | Seedance 2.0: Advancing Video Generation for World Complexity |
| Authors | ByteDance Seed / Team Seedance et al. |
| Date / Version | arXiv v1, submitted on 2026-04-15 |
| Category | cs.CV |
| Type | Seedance 2.0 Model Card |
| Official Page | Seedance 2.0 |
| Access | Doubao, Jimeng, Volcano Engine model id doubao-seedance-2-0-260128 |
| Code / Weights | not publicly released |
| 复现状态 | 可黑盒调用和评测;不可复现训练;SeedVideoBench 2.0 未完整公开 |
| 检索日期 | 2026-05-24 |
Abstract:论文摘要解读
摘要里有几个信息需要拆开看。
第一,Seedance 2.0 被定义为 native multi-modal audio-video generation model。这里的 native 很重要:作者不是把视频模型、音频模型、编辑模型简单串联,而是声称采用 unified, highly efficient, large-scale architecture 来做 multi-modal audio-video joint generation。论文没有公开这个架构细节,所以我们只能把它作为 paper claim,而不能推断具体 backbone。
第二,它支持四类输入模态:text、image、audio、video。官方开放平台当前支持最多 3 个 video clips、9 张 images、3 个 audio clips 作为 reference。这个输入面远大于传统 T2V/I2V,因此 paper 的主线自然转向 R2V、editing、continuation、extension 和组合任务。
第三,输出是 4 到 15 秒 audio-video content,native 480p 和 720p,并提供 Seedance 2.0 Fast 版本用于低延迟场景。换句话说,它瞄准的是可上线的创作系统,而不是离线研究 demo。
第四,作者强调它在专家评测和公开用户测试中达到 leading level。但这句话需要谨慎读:大部分评测来自 SeedVideoBench 2.0 内部框架,外部偏好证据主要来自 Arena.AI leaderboard。它能说明闭源商业模型层面的竞争力,不能替代开源可复现证据。
Motivation
论文的 motivation 不是单纯追求更高分辨率,而是追求 real-world complexity。这个词在文中对应几类难点:复杂人类动作、多主体交互、物理合理性、面部表情、镜头调度、连续叙事、音效和画面同步,以及在广告、影视、游戏和解说内容中的生产可用性。
这和早期视频生成任务有明显区别。早期 T2V 可以容忍片段短、动作弱、声音后配、角色不稳定,因为它更像一个“生成样片”的能力展示。到了生产场景,模型要接收复杂输入并保持约束:角色不能换脸,参考动作不能丢,风格不能漂移,音频不能和口型错位,剪辑不能改坏非编辑区域。这些约束一叠加,任务就不再是单一 prompt-to-video,而是多模态条件下的视频世界建模。
论文把 Seedance 2.0 的进步归纳为四条:生成真实世界复杂性、强多模态能力、更强可控性、高保真音画生成。这里真正值得关注的是后两条。可控性决定创作者能否稳定复用模型;音画联合决定模型能否进入短剧、广告、游戏动画、讲解视频等更完整的内容形态。
直观效果:先看它能做什么

图:论文 Figure 里的 T2V/I2V visualization。它支持的理解点不是“这些样例一定代表平均质量”,而是展示作者强调的复杂动作、镜头移动、真实质感和叙事式 prompt execution。
这组图很能说明 Seedance 2.0 的目标。上面不是单张好看的关键帧,而是连续镜头:花样滑冰的高速动作、武侠打斗中的焦点切换、画中人物从静态艺术品中“走出来”。这些例子对应论文中的几个 claim:复杂 motion、镜头语言、物理合理性、风格迁移和 reference-based generation。
不过 qualitative figure 只能作为直观证据。它不能证明失败率,也不能说明生成过程是否稳定。真正要判断产品价值,还是要看任务覆盖和可用率。
方法总览:核心思想和系统结构
论文没有给出可复现的模型结构图。它只公开了能力接口和评测框架。因此下面这张图是基于 paper 和官方页面重绘的 paper-level flow,不是内部架构复刻。
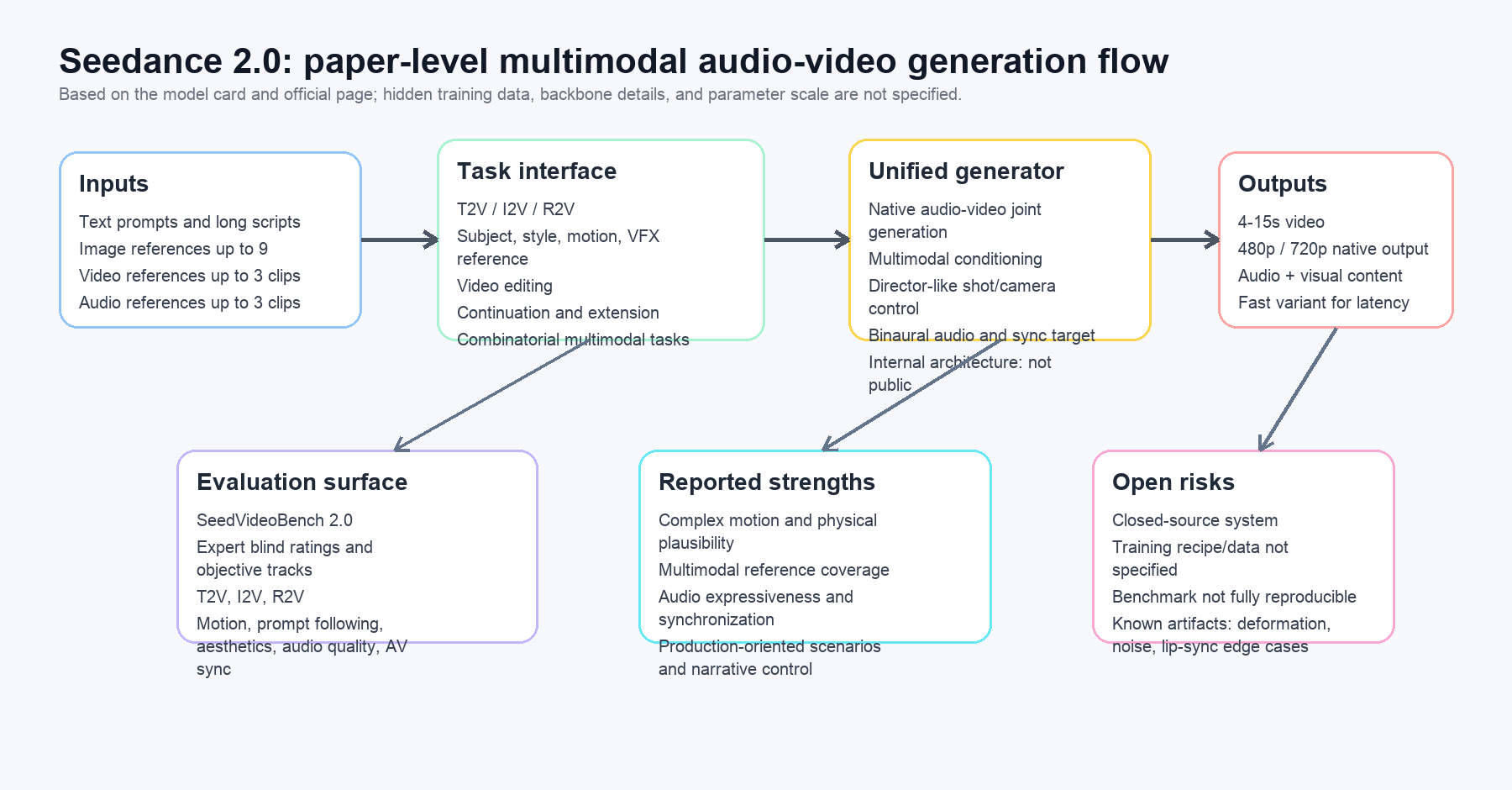
图:基于论文和官方页面重绘的系统级数据流。它强调公开可确认的输入、任务接口、输出和评测面;其中 generator 内部结构、训练数据、参数规模和具体 loss 都是 not specified。
可以把 Seedance 2.0 理解成一个多模态创作接口:
- 用户输入 text prompt 或长脚本。
- 可选加入 image、video、audio references。
- 任务被组织成 T2V、I2V、R2V、video editing、continuation、extension 或组合任务。
- 统一 audio-video generator 输出 4 到 15 秒、480p 或 720p 的音画内容。
- SeedVideoBench 2.0 和 Arena.AI 分别从内部细粒度评测与外部人类偏好角度验证质量。
这个接口背后的难点不是“多放几个输入框”。多模态 reference 之间可能互相冲突:图像要求保 identity,视频要求保 motion,音频要求保 voice 或 rhythm,prompt 又要求改变剧情和镜头。一个生产级模型需要决定哪些条件是硬约束,哪些是风格倾向,哪些可以在冲突时让步。论文没有公开冲突消解机制,但 R2V 评测正是在衡量这个能力。
数据全流程:输入、表示、shape 和语义
| 阶段 | 对象 | Shape / Dim | 语义 | 产生者 | 消费者 |
|---|---|---|---|---|---|
| Prompt | text / long script | not specified | 内容、动作、镜头、声音、叙事约束 | user | generator |
| Image reference | images | up to 9 images | subject、style、first-frame、visual reference | user | I2V / R2V / editing |
| Video reference | video clips | up to 3 clips | subject、motion、editing、continuation reference | user | R2V / editing / extension |
| Audio reference | audio clips | up to 3 clips | voice、sound、acoustic characteristic | user | audio-video generation |
| Task interface | T2V / I2V / R2V / editing / extension | not specified | 把多模态输入组织成具体生产任务 | platform / model interface | unified generator |
| Generator | closed-source Seedance 2.0 | not specified | native audio-video joint generation | ByteDance Seed | output |
| Output | audio-video content | 4-15 seconds; 480p / 720p | 同步音画生成结果 | model | user / product |
| Evaluation | SeedVideoBench 2.0 | benchmark details not fully public | 细粒度质量、可用率和满意率评测 | ByteDance Seed | paper tables |
| Arena.AI | anonymous pairwise votes | Elo leaderboard | 外部人类偏好信号 | Arena.AI users | paper comparison |
这个表最重要的是 unknown:内部 latent shape、audio representation、tokenization、conditioning fusion、训练数据规模、优化器、采样器、后处理、安全过滤都没有公开。把这些留空比编一个“可能是 DiT + VAE + audio codec”的故事更诚实。
Training:监督信号、loss 和优化目标
训练细节基本 not specified。论文没有给出:
- 模型参数规模。
- 视频/音频 tokenizer 或 VAE。
- backbone 类型。
- 训练数据来源、清洗策略和规模。
- loss 设计。
- optimizer、learning rate、batch size、训练时长。
- alignment / RL / reward tuning 配方。
- safety training 与过滤细节。
这意味着它不能作为 paper2code 的直接输入。我们能确定的是产品能力目标:多模态参考、音画同步、复杂运动、真实感、叙事和生产可用率。至于这些能力来自更大数据、更大模型、统一架构、RLHF/RLAIF、reward model、后处理还是产品侧 pipeline,论文没有拆开。
Inference:测试时到底怎么生成结果
公开信息能确认的 inference interface 包括:
- 可通过 Doubao、Jimeng 和 Volcano Engine 访问。
- Volcano Engine model id 是
doubao-seedance-2-0-260128。 - 支持 4 到 15 秒生成。
- 原生输出 480p 和 720p。
- 支持 Seedance 2.0 Fast 版本,用于低延迟场景。
- 当前开放平台支持最多 3 个视频、9 张图片、3 个音频作为 reference。
推理过程内部同样未公开。对使用者来说,关键不是能否复刻 sampling loop,而是要在黑盒接口层测试三件事:第一,同样 prompt 多次生成的稳定性;第二,多个 reference 条件冲突时模型是否遵循关键约束;第三,长脚本和多主体音画同步是否在真实素材中稳定。
Evaluation:验证集、指标和 baseline 是否公平
SeedVideoBench 2.0 是这篇 model card 的核心。论文说它比 SeedVideoBench 1.5 加入了 multimodal generation、narrative quality 和 multilingual coverage,并细化 audio expressiveness。
评测分两类:
| 评测轨道 | 例子 | 作用 |
|---|---|---|
| Objective track | motion stability 等自动化 pipeline | 尽量客观捕捉形变、稳定性和物理问题 |
| Subjective track | aesthetics、narrative quality、expert blind review | 捕捉镜头语言、情绪表达、视觉审美和叙事质量 |
评价任务分三类:
| 任务 | 关注点 |
|---|---|
| T2V | motion、video prompt following、aesthetics、audio quality、audio-visual sync、audio prompt following |
| I2V | motion quality、video prompt following、image preservation、audio quality、audio-visual sync、audio prompt following |
| R2V | multimodal task following、editing consistency、reference alignment、motion quality、prompt following |
公平性上要保留两个 caveat。第一,多数 baseline 也是闭源商业模型,版本、采样参数、默认安全过滤和产品后处理很难完全对齐。第二,SeedVideoBench 2.0 的完整 prompt set、split、rubric、evaluator agreement 和脚本没有公开,所以第三方无法完整复算。它是有价值的 model card 证据,但不是完全开放 benchmark。
实验与证据:哪些 claim 被支持,哪些还不够
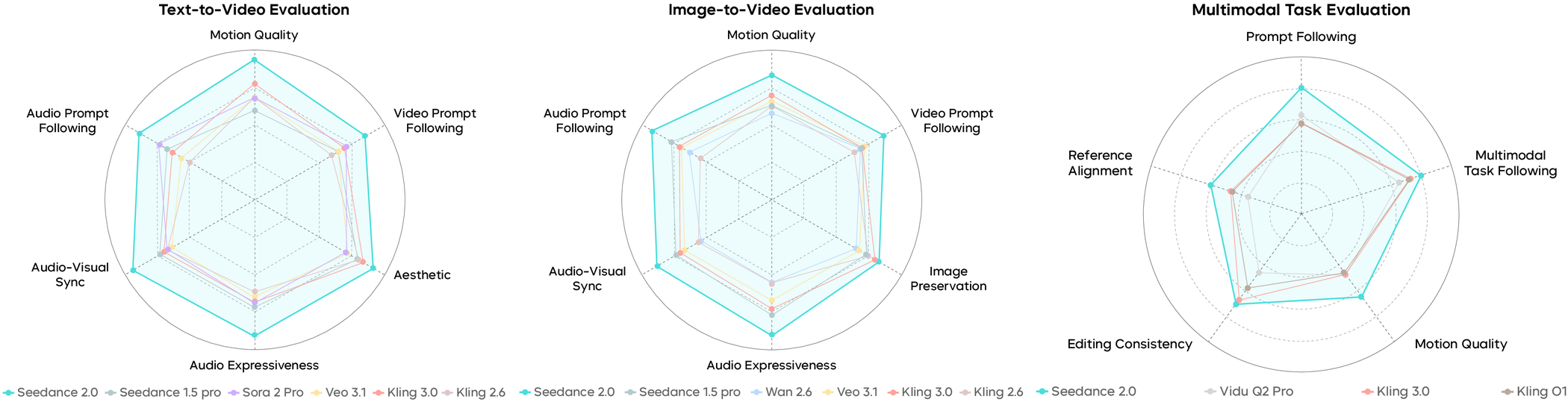
图:论文 Figure 1 的 overall radar。它把 T2V、I2V、R2V 三类任务里的主要评分维度放在一起,支持作者关于“综合维度领先”的 paper claim。
T2V:音频维度的差距最大
T2V overall table 中,Seedance 2.0 在六个维度都排第一:Motion 3.75、Video Prompt Following 3.43、Aesthetics 3.67、Audio Quality 3.63、Audio-Visual Sync 3.75、Audio Prompt Following 3.56。论文说它相对 Seedance 1.5 平均提升 0.86,其中 Motion Quality 提升最大,为 1.36。
更有信息量的是可用率和满意率。Seedance 2.0 的 T2V usability rate 在 Motion Quality 上达到 97.55%,Audio Quality 为 93.75%,Audio-Visual Sync 为 93.30%。满意率中,Audio Quality 是 62.05%,Audio-Visual Sync 是 68.30%。竞品在音频质量满意率上普遍低于 10%,这说明 Seedance 2.0 的领先主要不是只靠画面,而是靠 audio-video joint generation 把“可用视频”推成“可用音画片段”。
I2V:image preservation 接近,audio 仍拉开差距
I2V overall table 中,Seedance 2.0 同样六项第一,分数范围从 3.31 到 3.70。Image Preservation 是最接近的维度,Kling 3.0 只落后 0.13;但 audio quality、audio-visual sync 和 audio prompt following 的差距明显更大。
I2V satisfaction rate 也有相同模式:Seedance 2.0 在 Audio Prompt Following 上是 63.52%,Audio Quality 是 57.08%,Audio-Visual Sync 是 54.94%。这支持一个判断:Seedance 2.0 的产品差异化并不只是“让图动起来”,而是让图像参考、动作、声音和情绪表达一起成立。
R2V:任务覆盖是核心优势,但 extension 不是最强项
R2V 是这篇 paper 最值得看的部分。Seedance 2.0 在 Multimodal Task Following、Editing Consistency、Reference Alignment、Motion Quality、Prompt Following 五项均第一。任务覆盖表显示,它支持 20 of 22 input modalities,是覆盖最广的模型。
更具体地说,Visual Effects / Creative Reference 的 3 个子任务,以及 Continuation / Extension 的 4 个子任务,是 Seedance 2.0 独有支持项。这说明它在 product surface 上确实比只支持 subject/style/motion reference 的模型更完整。
但这不是全胜。论文自己的 R2V analysis 写得比较诚实:video editing 的 task following 上 Kling O1 略高;motion reference 里 Kling 3 Omni 的 first-frame preservation 更强;video extension 上 Veo 3.1 的 task following 和 reference alignment 都优于 Seedance 2.0。换句话说,Seedance 2.0 更像一个覆盖面和综合能力强的创作引擎,而不是每个子任务都无条件最强。

图:论文中的 R2V visualization。它展示 reference images 如何被转成多风格生成视频,用来说明 subject/style/creative reference 的任务形态。它不能替代失败率统计,但能帮助理解 R2V 任务为什么比普通 I2V 更复杂。
Arena.AI:外部偏好信号有价值,但会随时间漂移
论文报告在 2026-04-08 访问的 Arena.AI leaderboard 上,Dreamina Seedance 2.0 720p 在 T2V 和 I2V 分别取得 Elo 1450 +/- 15 与 1449 +/- 11,并排名第一。T2V 领先第二名 veo-3.1-audio-1080p 79 分,I2V 领先 grok-imagine-video-720p 29 分。
这个证据有两个优点:它来自外部用户偏好,不完全依赖 ByteDance 内部 benchmark;并且用匿名 side-by-side vote,能比单一自动指标更接近真实观看体验。限制也明显:leaderboard 会随时间变化,模型版本可能更新,投票 prompt 分布也不等于专业生产场景。因此博客里最好把它写成“外部偏好补充证据”,不要写成固定 SOTA 结论。
复现与工程风险
这篇 paper 的复现风险非常高,因为它不是开源论文。
| 项目 | 状态 |
|---|---|
| Code | not publicly released |
| Weights | not publicly released |
| Training data | not specified |
| Model architecture | not specified |
| Parameter scale | not specified |
| Optimizer / LR / batch / schedule | not specified |
| SeedVideoBench 2.0 full data and scripts | not publicly released |
| Product/API access | available through official platforms, but black-box |
能做的不是 reproduction,而是 black-box evaluation。一个比较可靠的工程验证路径是:
- 固定 T2V/I2V/R2V/editing/extension 的 prompt set。
- 对所有模型使用同样 duration、resolution、reference inputs。
- 记录 API 版本、日期、采样配置和失败重试。
- 进行 blind pairwise human preference。
- 单独标注 motion deformation、multi-subject consistency、text preservation、lip-sync、audio noise、reference drift、non-edited region damage。
工程部署还要额外关注合规风险。Seedance 2.0 的强项之一是 subject、voice、style 和 IP-like reference 控制,这对广告和短剧很有用,但也放大了肖像、声音克隆、版权风格模仿、provenance 和 watermarking 的压力。论文有 safety 段落,但没有公开具体评测和策略。
总结
Seedance 2.0 的价值不在于公开了一个新算法,而在于它给出了一个强商业视频生成模型应该具备的能力蓝图:多模态输入、原生音画联合、reference/editing/continuation 统一接口、复杂运动和导演式镜头语言,以及以 production usability 为核心的评测体系。
如果从研究角度读,它最大的启发是评测维度的迁移。视频生成已经不能只看视觉真实感,也不能只看 text prompt following。一个面向真实创作的模型必须同时看 motion quality、audio expressiveness、audio prompt following、audio-visual sync、reference alignment、editing consistency 和 task coverage。
如果从工程角度读,Seedance 2.0 是一个黑盒产品能力样本:它告诉我们应该如何设计多模态视频生成 API、如何组织 reference/editing/extension 任务、如何做盲评和失败归因。但它不能告诉我们怎么训练一个同类模型。训练数据、模型结构、优化细节、alignment 策略都没有公开。
我会把这篇列为“必须读的商业 model card”,而不是“可复现方法论文”。它适合作为视频生成产品和 benchmark 设计参考,也适合作为闭源模型评估模板;如果要做学术复现或开源实现,需要另找公开架构和数据闭环更完整的论文。