
Dual Diffusion:用扩散模型同时做图像生成和视觉理解
Dual Diffusion:用扩散模型同时做图像生成和视觉理解
论文:Dual Diffusion for Unified Image Generation and Understanding
作者:Zijie Li, Henry Li, Yichun Shi, Amir Barati Farimani, Yuval Kluger, Linjie Yang, Peng Wang
时间 / 版本:arXiv v2, submitted on 2024-12-31, last revised on 2025-04-01
链接:Paper / Project / Code
开篇点评:这篇论文真正有意思的地方
Dual Diffusion 讨论的是一个很基础但长期被绕开的边界:扩散模型已经是文本生成图像的主力,但一旦任务变成“看图回答问题”或“根据图像生成文字”,主流系统通常又回到 autoregressive VLM。于是多模态系统被拆成两个世界:图像生成靠 diffusion,视觉理解靠 LLM。
这篇文章的核心想法是把这个边界打通。它不是给 SD3 接一个分类头,也不是拿 diffusion feature 再喂给 GPT2,而是让同一个 MM-DiT backbone 同时承担两种扩散目标:
- 图像侧:连续 latent flow matching,负责 $p(x_\text{img}\mid x_\text{text})$。
- 文本侧:离散 absorbing-state masked diffusion,负责 $p(x_\text{text}\mid x_\text{img})$。
我的判断是,这篇工作最重要的价值不是某个 benchmark 数字,而是它证明了一条 diffusion-only unified multimodal model 的可行路径。它能生成图像,也能做 caption 和 VQA;它的理解能力还没有超过强 autoregressive VLM,但它把“扩散模型是否能做完整视觉语言任务”从概念讨论推进到了可训练、可评测、可开源推理的系统。
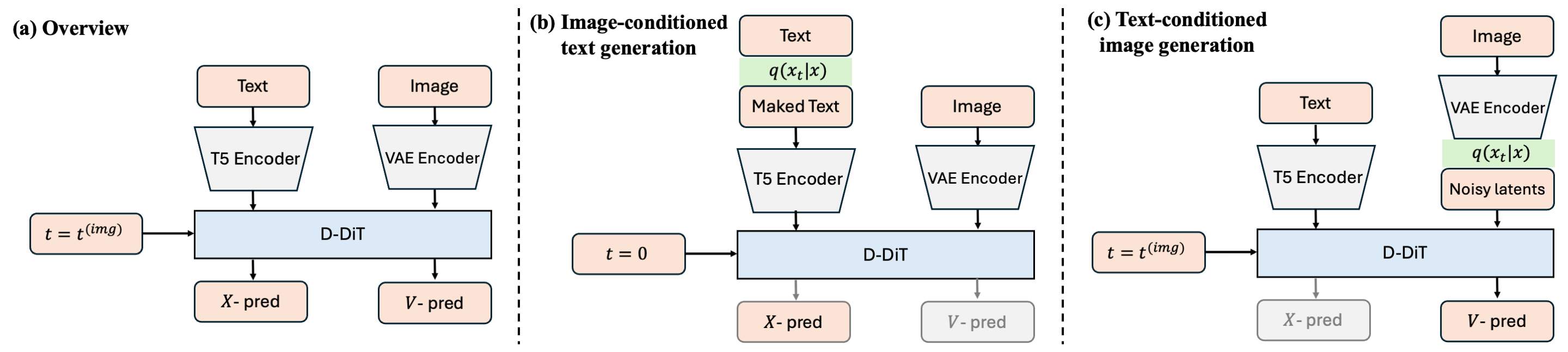
图:项目页给出的 D-DiT model overview。左侧是共享结构,中间是 image-conditioned text denoising,右侧是 text-conditioned image denoising。这个图是理解全文的主图。
Paper Card
| 项目 | 信息 |
|---|---|
| Paper | Dual Diffusion for Unified Image Generation and Understanding |
| arXiv | 2501.00289, v2 |
| Project / Code | Project, GitHub |
| Base model | SD3-medium style MM-DiT, T5 encoder/tokenizer, SD3 VAE |
| 核心任务 | Text-to-image, image captioning, visual question answering |
| 核心 claim | 用一个 diffusion-only 双分支模型统一图像生成和视觉理解 |
| 开源状态 | 代码、inference notebook、training scripts、两个 Hugging Face checkpoint 链接已公开;训练复现仍有断点 |
| 检索日期 | 2026-05-25 |
Abstract 解读
摘要可以拆成三层。
第一层是问题:扩散模型在 text-to-image generation 上很强,但视觉理解仍然主要由 autoregressive VLM 主导。已有多模态扩散模型要么只在 CLIP/text latent 里做简化文本扩散,要么仍然需要 GPT2/LLM 作为文本 decoder,因此不能算完整的 diffusion-only 视觉语言系统。
第二层是方法:作者把 MM-DiT 和 discrete diffusion language modeling 结合起来,用一个 cross-modal maximum likelihood 框架同时训练图像条件文本似然和文本条件图像似然。训练信号会回传到 diffusion transformer 的两个 branch,而不是只优化其中一个模态。
第三层是结果:模型能做 image generation、captioning、VQA,并且在 diffusion-based / unified generation-understanding 模型中有竞争力。注意这里的限定很重要:它不是说 D-DiT 已经超过了 InternVL、LLaVA-Next、Qwen-VL 这类理解专用 VLM,而是说 diffusion-only 路线第一次覆盖了比较完整的视觉语言任务集合。
Motivation:为什么不能直接拿扩散特征接语言模型
一个直觉方案是:既然 SD3 这类 T2I 模型已经在大量图文对上训练过,那它内部应该有图像语义表示,直接抽 feature 接 GPT2 decoder 做 caption/VQA 不就行了?
论文的 ablation 说明这条路不够好。把 SD3 feature 接 GPT2,VQAv2 val 0-shot 只有 42.3;把 SD3 backbone 解冻也只有 45.1;CLIP ViT-L/14 接 GPT2 是 50.6;而 D-DiT 直接用 text branch 建模条件 token 分布可以到 55.0。也就是说,问题不是 diffusion model 完全没有语义,而是这些语义不天然落在 decoder-only LM 的 token embedding space 里。
D-DiT 的路线更直接:不要把 diffusion feature 翻译给外部语言模型,而是在 MM-DiT 里让文本 branch 自己学习 masked token denoising。这样视觉理解被写成 $p(x_\text{text}\mid x_\text{img})$ 的扩散式条件建模,而不是“图像 encoder + 语言 decoder”的拼接问题。
方法总览:连续图像扩散 + 离散文本扩散
图像侧沿用 SD3/flow matching。给定 clean image latent $x$ 和 Gaussian noise $\epsilon$:
\[x_t = \alpha_t x + \sigma_t \epsilon\]常见 flow matching 目标可以写成 velocity:
\[v = \epsilon - x\]文本侧不能直接加 Gaussian noise,因为 token 是离散变量。D-DiT 使用 absorbing-state masked diffusion:每个 token 要么保持原 token,要么变成 mask state $m$。论文写成:
\[q(x_t\mid x)=\mathrm{Cat}[\alpha_t x + (1-\alpha_t)m]\]这里的 mask token 在实现中使用 T5 vocabulary 的 <extra_id0>,代码里 hard-code 成 32099。模型在文本 branch 输出 vocabulary logits,用来预测被 mask 位置的 clean token。
最终训练目标是:
\[L_\text{dual}=L_\text{image}+\lambda_\text{text}L_\text{text}\]它的关键约束是:训练某个方向时,条件模态不加噪声。预测文本时图像保持 clean;预测图像时文本保持 clean。这样学到的是两个条件分布,而不是两个都被破坏后的联合修复。
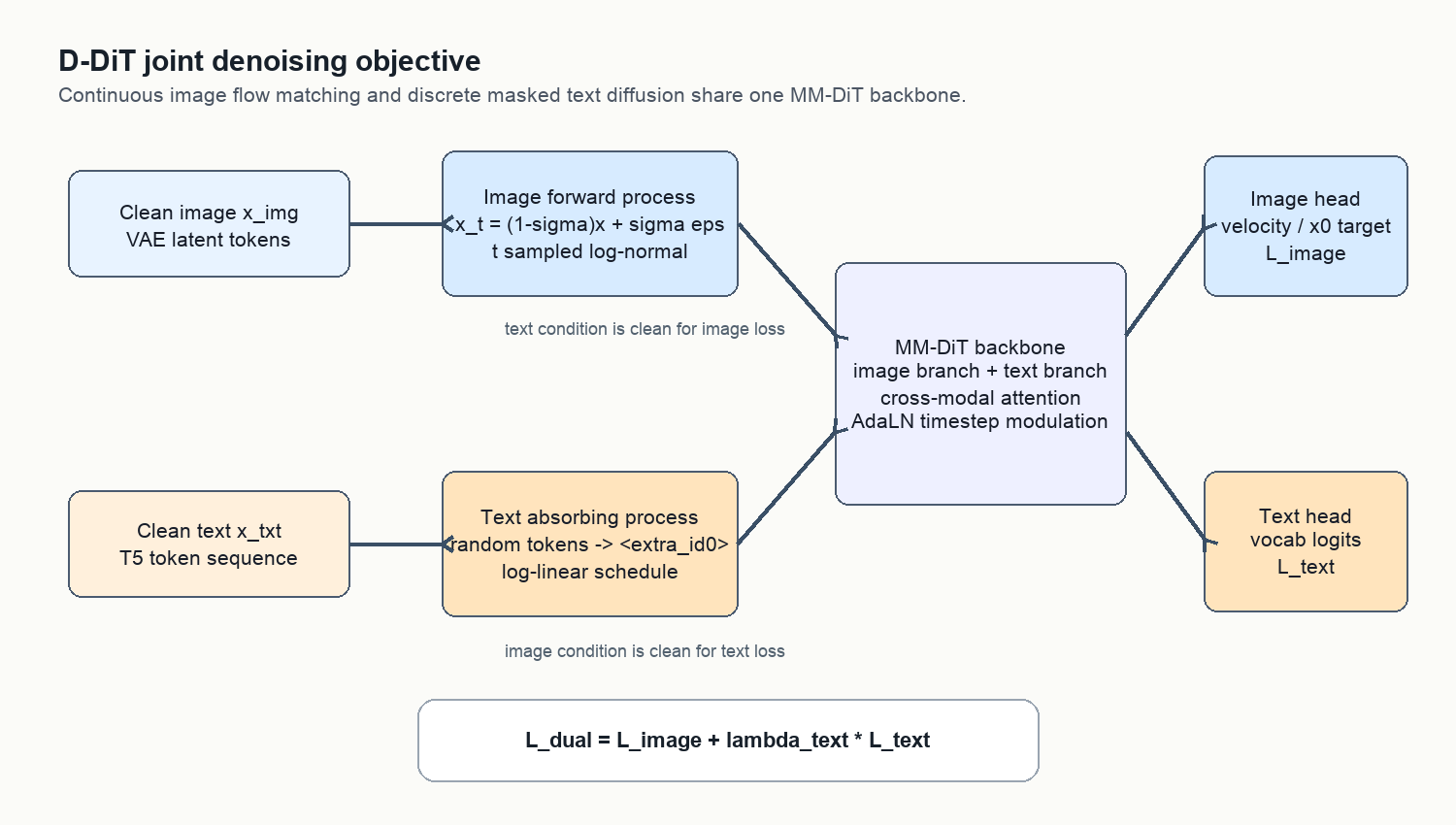
图:我根据论文和代码整理的 joint denoising 数据流。蓝色是图像 flow matching,黄色是文本 absorbing-state diffusion,中间共享 MM-DiT。
Architecture:D-DiT 对 SD3 做了哪些改造
D-DiT 建在 SD3-medium 的 MM-DiT 结构上。原本 SD3 已经有 image branch 和 text branch,并在每层做 cross-modal attention。作者保留这个骨架,但改造输出和 conditioning:
| 模块 | 处理方式 |
|---|---|
| Image VAE | 沿用 SD3 VAE,负责像素和 latent 的转换 |
| Text encoder | 使用 T5 encoder/tokenizer |
| CLIP text encoders | 移除,论文称这样可以避免 causal mask 干扰 masked diffusion,并简化结构 |
| MM-DiT backbone | 初始化自 SD3-medium checkpoint |
| Image head | 输出图像 denoising / velocity 相关目标 |
| Text head | 新增 linear head,输出 vocabulary logits |
| Timestep | 图像生成时输入 scalar timestep;文本扩散不额外输入文本 timestep,mask ratio 已隐含噪声程度 |
这里有一个容易忽略的细节:文本 branch 不能使用 causal attention mask。Masked diffusion 的语义是任意位置都可能被 mask,模型需要双向上下文来恢复 token。如果强行用 next-token causal mask,就会破坏这个建模假设。
Training:三阶段把 SD3 改造成视觉语言扩散模型
论文的训练分成三段,总共约 40M image-text pairs。
| 阶段 | 数据 / 设置 | 目的 |
|---|---|---|
| Dual diffusion pretraining | 60K iterations, batch 512, text length 64, resolution 256, recaptioned DataComp-1B,实际看约 30M images | 让 SD3 backbone 初步适配文本 masked diffusion |
| Continued pretraining | 200K iterations, batch 512, text length 256, resolution 256, ShareGPT4V pretrain 1.3M + OpenImages 1.9M subset,ShareCaptioner recaption;512 模型还可做 80K high-res finetune | 提升长描述和高质量图文建模,并对齐 T5 mask embedding |
| Visual instruction tuning | 50K iterations, LLaVA-Pretrain558K, LLaVA-v1.5-mix-665K, TextVQA, VizWiz | 支持 VQA、short answer、long answer、caption 等指令格式 |
Appendix 给出的训练超参包括 AdamW、bf16、FSDP、weight decay 1e-2。文本 loss 权重在 pretraining 阶段是 0.2,在 instruction tuning 阶段是 1.0。README 则给出一个更工程化的事实:预训练使用 32 H100,SFT 使用 16 A100。这说明它的完整训练不是普通实验室随手可以复刻的规模。
Inference:同一个模型怎么切换 T2I、caption 和 VQA
D-DiT 的推理模式本质上是决定“哪个模态固定,哪个模态被 noised/masked”。
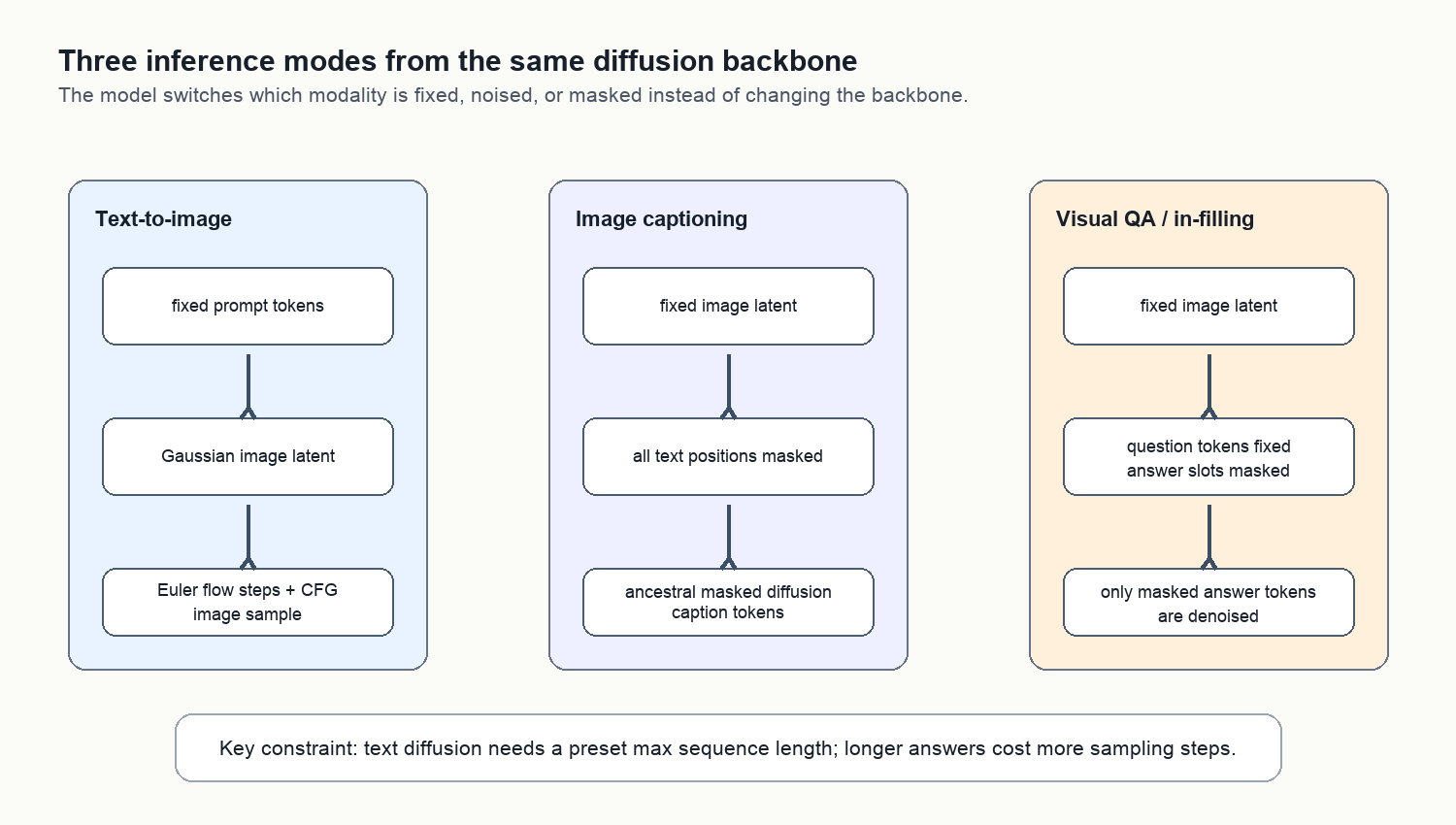
图:三种推理模式。T2I 固定文本、采样图像 latent;caption 固定图像、全 mask 文本;VQA 固定图像和问题 token,只采样答案槽位。
Text-to-image
文本 prompt 先经过 T5 encoder,图像 latent 从 Gaussian noise 初始化,然后用 FlowMatch Euler scheduler 迭代。论文主设置是 28 sampling steps、CFG scale 7.0。开源 pipeline 里的 text_to_image_sampling_loop 也沿用这一点。
Image captioning
图像先通过 VAE encoder 得到 latent condition。文本序列初始化为全 mask,然后用 masked diffusion 的 ancestral sampling 从 mask state 逐步恢复 token。最后用 tokenizer decode 得到 caption。
Visual QA / in-filling
VQA 更像文本 in-filling。问题 token 固定,answer slots 被初始化为 mask,采样时只有答案位置会被更新。这个形式很适合短答,因为短答不需要太多 diffusion steps;但对长回答,步数会明显影响质量。
直观效果

图:项目页的 VQA 示例。它展示的不是普通 caption,而是带问题条件的视觉问答,这正是 masked text in-filling 的用武之地。

图:项目页的 T2I 示例。作者想证明 joint diffusion training 后,原本的 SD3 图像生成能力没有被灾难性破坏。
Evaluation:哪些结论被实验支持
图像生成:整体保持,部分指标提升
在 GenEval 上,D-DiT 512 相比 SD3 从 0.62 提升到 0.65。它在 two objects、colors、color attribution 上提升明显,但 counting 和 position 略降。
| Model | Overall | Single obj. | Two obj. | Counting | Colors | Position | Color attribution |
|---|---|---|---|---|---|---|---|
| SD3 | 0.62 | 0.98 | 0.74 | 0.63 | 0.67 | 0.34 | 0.36 |
| D-DiT | 0.65 | 0.97 | 0.80 | 0.54 | 0.76 | 0.32 | 0.50 |
Appendix 的补充指标也大体支持“没有灾难性遗忘”。MJHQ-30K FID 从 16.45 降到 15.16;COCO FID 从 10.2 降到 9.4;CLIP score 从 30.9 到 31.2。不过 T2I CompBench 的 texture 从 0.7389 降到 0.6856,shape 也略降。作者推测这和 dual diffusion finetuning 数据的 texture 质量弱于 SD3 原训练数据有关。
这个结果的正确读法是:D-DiT 在把 SD3 改造成 VLM 的同时基本保住了 T2I 能力,并有一些 prompt-following 指标收益;但它不是对所有 T2I 维度都严格改进。
视觉理解:能打 unified model,但不是强 VLM
主要理解结果如下:
| Model | MS-COCO CIDEr | VQAv2 | VizWiz | OKVQA | MME | GQA | POPE |
|---|---|---|---|---|---|---|---|
| Show-O 512 | - | 69.4 | - | - | 1097.2 | 58.0 | 80.0 |
| D-DiT 256 | - | 59.5 | 19.4 | 28.5 | 897.5 | 55.1 | 79.2 |
| D-DiT 512 | 56.2 | 60.1 | 29.9 | 25.3 | 1124.7 | 59.2 | 84.0 |
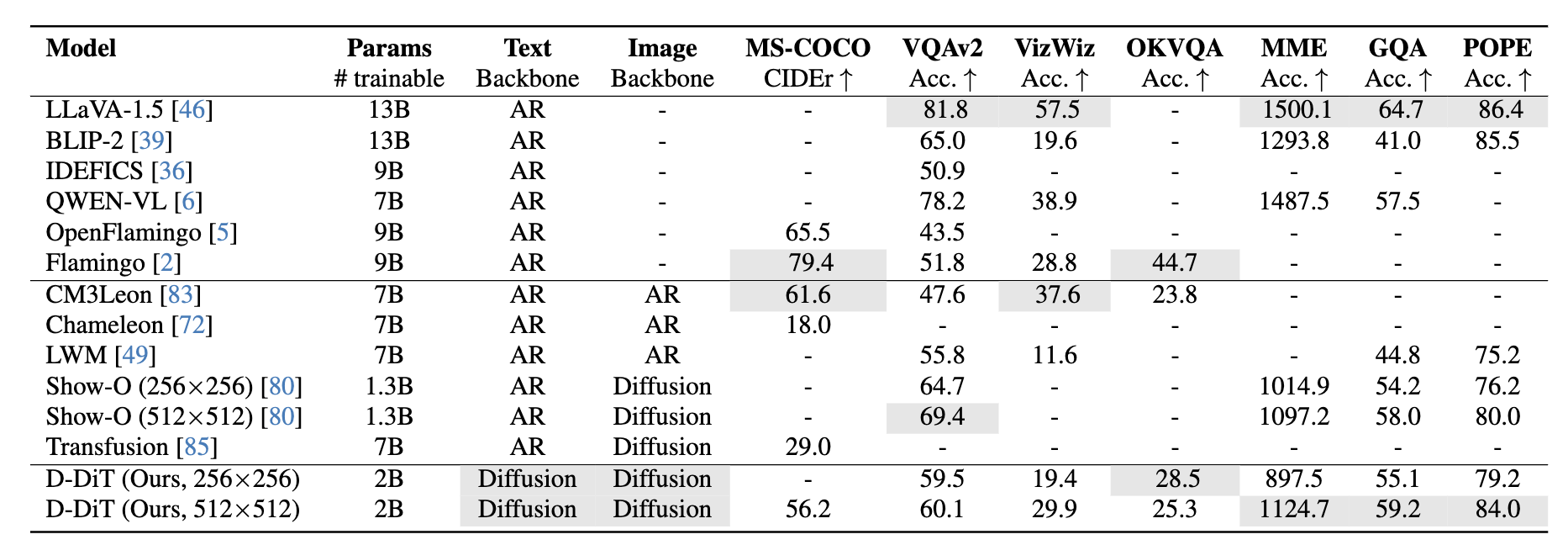
图:项目页的 multimodal benchmark 汇总。D-DiT 的定位应当是 diffusion-only / unified multimodal model,而不是理解专用 VLM。
这个表很有意思。D-DiT 512 在 MME、GQA、POPE 上超过 Show-O 512,但 VQAv2 明显低于 Show-O。和 InternVL-2.0、LLaVA-Next 等 AR VLM 比,D-DiT 的理解能力仍有差距。所以论文最稳的 claim 是“第一个比较完整的 diffusion-only VQA/caption/T2I 系统”,不是“最强视觉理解模型”。
Ablation:为什么要直接建模文本扩散
论文做了一个很关键的 ablation:拿 SD3 或 CLIP 特征接 GPT2 decoder,和 D-DiT 直接生成文本比较。
| Vision encoder | Language decoder | VQAv2 val 0-shot | VQAv2 val 32-shot |
|---|---|---|---|
| SD3 feature frozen | GPT2 | 42.3 | 46.9 |
| SD3 feature trainable | GPT2 | 45.1 | 50.2 |
| CLIP ViT-L/14 frozen | GPT2 | 50.6 | 54.8 |
| UniDiffuser | GPT2 | 46.7 | 49.4 |
| D-DiT | none | 55.0 | 60.3 |
这说明 D-DiT 的收益不是简单来自“扩散 backbone 里有图像语义”。如果把这些 feature 当作 prefix 塞给 GPT2,效果反而不如 CLIP feature。真正有效的是让 MM-DiT 的文本 branch 直接学习条件 token likelihood。
Sampling step:短答和长文本的成本不同
扩散文本生成的成本结构也被论文暴露出来了:
| Task | T=4 | 8 | 16 | 32 | 64 | 128 |
|---|---|---|---|---|---|---|
| VQAv2 acc. | 58.8 | 58.0 | 59.3 | 60.5 | 60.0 | 59.6 |
| MS-COCO CIDEr | 20.2 | 35.3 | 46.5 | 51.3 | 56.2 | 54.5 |
短答 VQA 在少量步骤下已经接近饱和;caption 需要更多 steps 才能提高 CIDEr。这和直觉一致:多 token 长文本需要更完整的迭代 refinement。扩散文本不是自回归逐 token,但也不是免费一次生成。
Code Read:开源实现支持了什么,也缺了什么
我顺手看了 GitHub 仓库当前 HEAD bbf06bf8a55ba5c6cf07c41502552eaa6d9e155c。代码结构比较直接:
| 文件 | 作用 |
|---|---|
sd3_modules/sd3_model.py | SD3JointModelFlexible,改造 SD3 transformer,新增 image/text 输出头 |
sd3_modules/sd_loss_utils.py | TextMaskedDiffusionLoss 和 ImageFlowMatchingLoss |
sd3_modules/dual_diff_pipeline.py | T2I 和 I2T inference pipeline,包含 masked diffusion sampler |
train_dual_diffusion_sd3.py | dual diffusion pretraining |
train_dual_diffusion_sd3_sft.py | instruction tuning |
configs/*.py | 示例训练配置 |
几个实现细节值得记下来。
第一,文本扩散的 SUBS parameterization 在代码里很明确:mask token logit 被加上极大负数,unmasked tokens 的 logits 被固定为原 token。这样采样时已经确定的 token 不会被反复改掉。
第二,T2I pipeline 基本沿用 SD3 inference:T5 prompt embedding、FlowMatchEulerDiscreteScheduler、CFG、VAE decode。I2T pipeline 则先把图像编码成 VAE latent,再注册到 ConditionalMaskedDiffusionSampler,最后采样 token 并 decode。
第三,开源训练配置还不是“下载后直接复现论文表格”的状态。配置文件里有大量 /mnt/bn/... 内部路径,README 只给了数据来源和训练命令框架。
第四,当前代码有一个需要注意的断点:TextMaskedDiffusionLoss._forward_pass_diffusion 在 cond_mask is None 时有 assert False,而 train_dual_diffusion_sd3.py 的 pretraining caption loss 调用没有传 label_mask。SFT 路径传了 label_mask,所以这更像是 pretraining 脚本或 loss 默认分支没有同步好的问题。复现时需要先修这个路径,至少要恢复“无 label_mask 时随机 mask 全文本”的逻辑。
局限和风险
第一,视觉理解能力仍然落后于强 AR VLM。D-DiT 的价值是证明 diffusion-only 可以做,而不是证明 diffusion-only 已经最强。
第二,文本生成需要预设最大长度。论文自己也把 dynamic sequence length 作为未来方向。对真实助手来说,这会影响长回答、对话延展和 streaming 体验。
第三,长文本采样成本高。论文 qualitative long-form response 使用 256 diffusion steps,这和现代 VLM 的交互延迟目标并不天然匹配。
第四,训练成本和数据工程门槛高。32 H100 pretraining、16 A100 SFT、约 40M 图文对、多个 recaption 数据源,使完整复现实验更接近大厂级工程。
第五,模型强依赖 SD3/T5/VAE 初始化。它证明的是“把强 T2I foundation model 改造成双向扩散多模态模型”可行,不等价于从零训练 diffusion VLM 已经成熟。
对后续研究的启发
我觉得这篇文章最值得继续挖的不是单纯追 VQA 分数,而是以下方向。
第一,FLUX/SD3 这类 MM-DiT backbone 能否系统性转成 image-to-text diffusion model。D-DiT 已经证明 SD3-medium 可以走通,下一步自然是更强的 backbone、更好的 text diffusion schedule、更稳定的 instruction tuning。
第二,masked text diffusion 是否适合做 controllable slots。比如图像编辑中的局部 caption、VQA 中的 answer span、数据标注中的 structured fields,都比开放式聊天更适合“固定上下文 + 填槽”。
第三,diffusion text branch 可以不直接当聊天模型,而是当 verifier、reranker、caption prior 或 multimodal consistency critic。这样可以利用双向 refinement 和条件似然能力,同时避开长文本生成成本。
第四,联合 loss 对 T2I 能力的影响值得更系统研究。D-DiT 在一些 GenEval 细项上提升,但 texture/shape 指标会下降。这说明理解数据、caption 数据和高质量图像数据的比例会改变生成模型的视觉偏好。
总结
Dual Diffusion 的贡献可以概括成一句话:它把 SD3-style MM-DiT 从单向 text-to-image generator 改造成了一个 diffusion-only 的双向视觉语言模型。
它的技术关键是连续图像扩散和离散文本 masked diffusion 的同构化:图像 branch 学 latent flow,文本 branch 学 mask token denoising,两个分支通过 cross-modal attention 共享 backbone,并用 $L_\text{image}+\lambda L_\text{text}$ 共同训练。推理时,T2I、caption、VQA 只是固定/扰动模态的不同组合。
但它也仍是研究原型。它证明 diffusion-only VLM 可行,却没有解决文本扩散的 sequence length、sampling cost 和理解能力差距。对工程落地而言,目前更合理的定位不是替代 AR VLM,而是为“生成模型内生理解能力”“多模态条件似然”“可控文本 infilling”提供一个很清晰的实验平台。
Recommended citation: Li et al. Dual Diffusion for Unified Image Generation and Understanding. arXiv:2501.00289, 2024.
Download Paper