
D4RT:把动态 4D 重建改写成时空点查询
D4RT:把动态 4D 重建改写成时空点查询
论文:Efficiently Reconstructing Dynamic Scenes One D4RT at a Time 作者:Chuhan Zhang, Guillaume Le Moing, Skanda Koppula, Ignacio Rocco, Liliane Momeni, Junyu Xie, Shuyang Sun, Rahul Sukthankar, Joelle K. Barral, Raia Hadsell, Zoubin Ghahramani, Andrew Zisserman, Junlin Zhang, Mehdi S. M. Sajjadi 机构:Google DeepMind, University College London, University of Oxford 时间 / 版本:2025-12-09 arXiv v1;2025-12-10 arXiv v2 类别:Dynamic 4D Reconstruction, 3D Point Tracking, Video Geometry, Feedforward Reconstruction 链接:Paper / PDF / Project / Official PDF / DeepMind Blog 检索日期:2026-06-21
开篇点评:这篇论文到底解决了什么问题
D4RT 解决的是一个很具体的 4D 视觉问题:给一段视频,不只恢复每帧的深度或相机姿态,而是要理解 场景里的每个点在三维空间和时间中的位置。如果场景是静态的,这件事已经可以由很多 feedforward reconstruction 或 SfM/MVS 系统处理;难点在于真实视频经常同时有相机运动、物体运动、遮挡和非刚体变化。
这篇论文最有价值的地方,不是提出了又一个 depth head、pose head 或 tracking head,而是把任务接口改掉了。D4RT 先把视频编码成一个全局 scene representation,然后让一个轻量 decoder 回答这样的查询:
这个 source frame 里的 2D 点,在某个 target timestep 的 3D 位置是什么?这个 3D 位置应该表达在第几个 camera reference frame 里?
一旦把问题写成 query,很多原本分散的任务就变成同一个 decoder 的不同查询方式:point track、point cloud、depth map、camera extrinsics、camera intrinsics 都可以由同一套输出 $P\in R^3$ 派生出来。
我的判断是,D4RT 的关键贡献是 用 query parameterization 统一动态 4D 重建。这比“把多个 decoder heads 拼在一个大模型后面”更干净,也解释了为什么它在速度上有明显优势:训练时只需要采样少量点 query,推理时按任务需要决定 sparse 或 dense 查询,而不是每次都 dense decode 整帧所有输出。
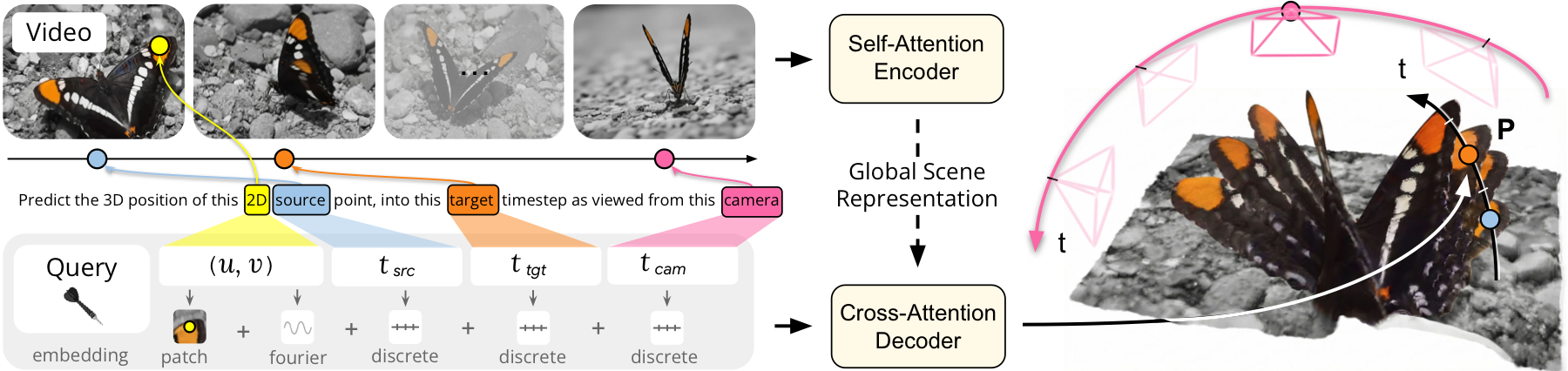
图:论文 Figure 2 的方法图。视频先进入 self-attention encoder 得到 Global Scene Representation;decoder 独立接收由 $(u,v,t_{src},t_{tgt},t_{cam})$ 和 local patch 组成的 query,并输出目标时空点的 3D 位置。
Paper Card
| 项目 | 信息 |
|---|---|
| Paper | Efficiently Reconstructing Dynamic Scenes One D4RT at a Time |
| Authors | Chuhan Zhang, Guillaume Le Moing, Skanda Koppula, Ignacio Rocco, Liliane Momeni, Junyu Xie, Shuyang Sun, Rahul Sukthankar, Joelle K. Barral, Raia Hadsell, Zoubin Ghahramani, Andrew Zisserman, Junlin Zhang, Mehdi S. M. Sajjadi |
| Date / Version | arXiv:2512.08924v2,updated 2025-12-10 |
| Task | Dynamic 4D Reconstruction and Tracking from a single video |
| Input | video $V\in R^{T\times H\times W\times3}$ |
| Core output | queried 3D point $P\in R^3$ |
| Derived outputs | point tracks, point clouds, depth maps, camera extrinsics, camera intrinsics |
| Project | d4rt-paper.github.io;项目页提供 paper、arXiv、动画/3D visualization 和官方 blog 入口 |
| Code / Checkpoint | 论文 source 和项目页未发现 D4RT 官方代码、checkpoint 或 public model card |
| 复现状态 | 方法、loss、训练配置和若干采样细节已给出;但训练混合数据含 internal datasets,代码与权重未发布,完整复现风险高 |
Abstract:论文摘要解读
摘要的逻辑很直接。动态场景重建需要同时理解几何、运动、对应关系和相机参数,但过去的方法常把这些问题拆成多个子模块:单独估深度、单独做 tracking、单独估 pose,再通过优化或后处理把结果拼起来。这样不仅慢,也容易在动态区域失效。
D4RT 的回答是一个 unified transformer architecture。它不为每种输出建一个专门 decoder,而是把任意时空点的位置当成可查询对象。模型先用 encoder 把整段视频变成 Global Scene Representation,再用 decoder 独立查询某个 2D source point 在 target time、target camera reference 下的 3D 位置。这个接口绕开了 dense per-frame decoding 的计算负担,也避免了维护多个 task-specific decoders 的复杂度。
摘要里最强的 claim 是:D4RT 在多个 4D reconstruction tasks 上达到新的 state of the art,并且训练与推理都更高效。正文中的支撑主要来自三类证据:TAPVid-3D 上的 3D tracking,Sintel/ScanNet/KITTI/Bonn 上的 depth / point cloud / camera pose,以及 A100 上的 tracking throughput。
Motivation
论文的 motivation 可以从一个失败模式开始理解:纯 3D reconstruction 方法面对动态物体时,会把同一个移动物体在不同时刻“堆”到场景里,或者干脆重建失败。论文 Figure 3 里,MegaSaM 会把天鹅重复到点云里,$\pi^3$ 在花朵示例上重建失败;SpatialTrackerV2 能跟踪动态点,但它主要从某一帧出发追踪,遮挡区域和未覆盖区域会留下空洞。
作者对 prior work 的批评不是泛泛说它们不好,而是指出了几种结构性限制:
| 路线 | 论文指出的问题 |
|---|---|
| MegaSaM 类 pipeline | 依赖多个 off-the-shelf 模型分别处理 mono-depth、metric depth、motion segmentation,并需要 test-time optimization |
| VGGT / DUSt3R-inspired feedforward reconstruction | 通常使用多个 task-specific heads;多数不能直接给动态区域建立 correspondence |
| SpatialTrackerV2 等 tracking methods | 能处理 dynamics,但依赖 costly iterative refinement,且不天然输出完整 dense 4D scene |
| Pairwise DUSt3R-style 4D methods | pairwise formulation 不适合 holistic video processing |
D4RT 的核心动机是:不要先决定输出是 depth map、track map 还是 camera pose;先学习一个全局视频表示,再用一个足够低层的 query interface 去问 3D 点。这样任务差异被推迟到 query schedule 和后处理,而不是固化在多个 decoder heads 里。
直观效果:先看它能做什么
论文的 qualitative comparison 很能说明任务边界。D4RT 不是只追踪少量点,也不是只把静态点云拼起来,而是尝试恢复一个包含动态对象轨迹的完整 4D 表示。
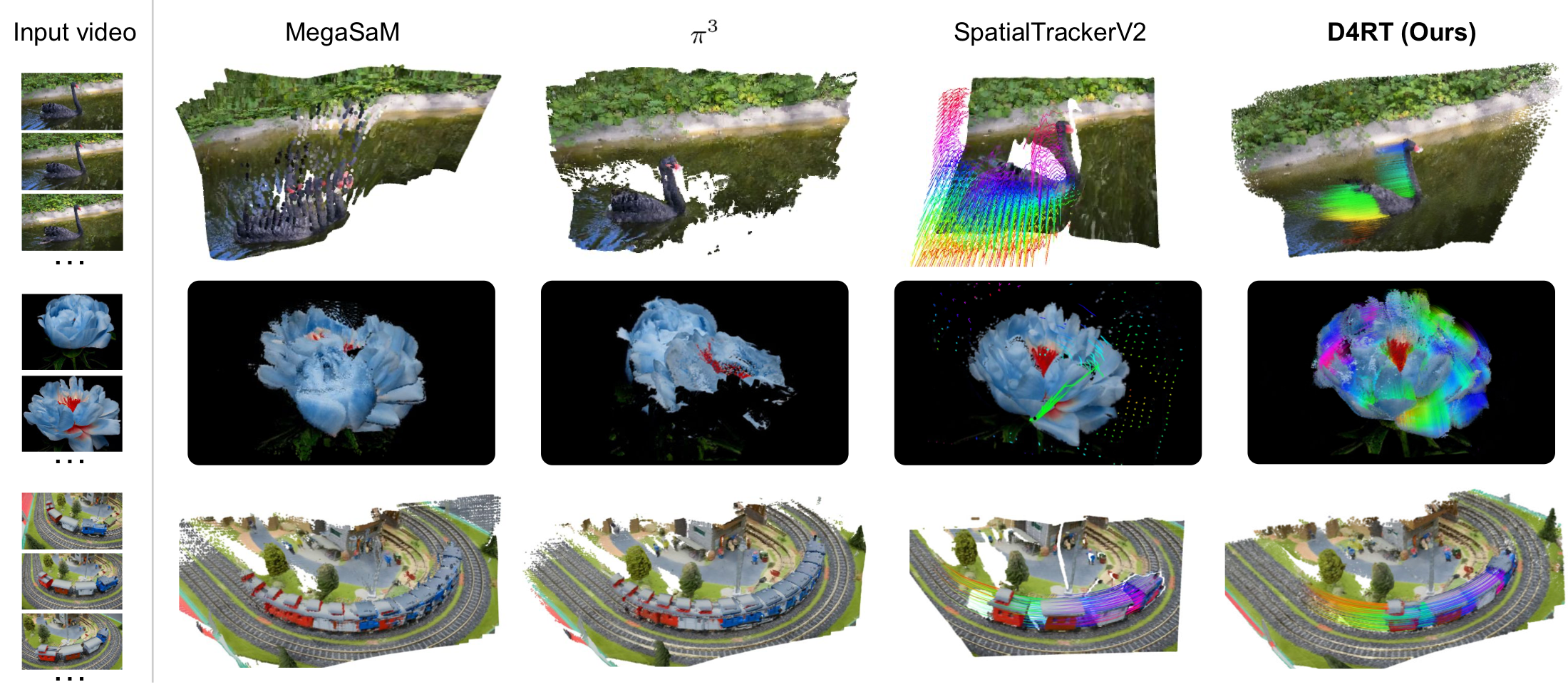
图:论文 Figure 3 的 qualitative comparison。MegaSaM 和 $\pi^3$ 这类纯 reconstruction 方法在动态物体上会出现重复、缺失或失败;SpatialTrackerV2 能捕获动态轨迹,但只覆盖部分区域;D4RT 的目标是把所有像素都放入统一的动态 4D 表示。
这张图里的重点不是视觉上哪张点云最漂亮,而是输出类型不同。MegaSaM 和 $\pi^3$ 的输出更像多个时刻的静态积累;SpatialTrackerV2 输出轨迹,但覆盖不完整;D4RT 把动态物体的轨迹作为场景表示的一部分,因此能把“移动中的物体”和“静态背景”放到同一个 4D 坐标故事里。
当然,定性图不能证明方法在所有动态场景都稳定。透明物体、强反光、rolling shutter、极端相机畸变、长时间遮挡和长视频 chunk stitching 都可能是风险点。论文真正有说服力的部分在于:定性图之外,它还把 tracking、depth、pose 和速度分开做了量化。
方法总览:核心思想和系统结构
D4RT 的基本形式非常紧凑:
\[G = \operatorname{Enc}(V) \in R^{N\times C}\] \[q=(u,v,t_{src},t_{tgt},t_{cam})\] \[P = \operatorname{Dec}(q,G) \in R^3\]这里 $V$ 是输入视频,$G$ 是 encoder 输出的 Global Scene Representation。论文没有在正文中指定 $N$ 和 $C$ 的具体数值。$q$ 是 query,$(u,v)$ 是 source frame 中 normalized 2D 坐标,$t_{src}$ 是 source timestep,$t_{tgt}$ 是想要预测的 temporal state,$t_{cam}$ 是输出 3D 坐标所在的 camera reference frame。
这个五元组的价值在于把三个概念拆开:
| 字段 | 控制的问题 | 为什么重要 |
|---|---|---|
| $(u,v,t_{src})$ | 这个点来自视频哪一帧、哪个像素 | 定义 point identity / source evidence |
| $t_{tgt}$ | 要看这个点在哪个时间状态 | 支持动态点轨迹 |
| $t_{cam}$ | 输出坐标用哪一帧的相机坐标系 | 支持 reference frame switching 和 camera recovery |
如果这三个时间索引必须一致,模型就只能做普通 depth 或 frame-local point map。D4RT 允许它们分开,于是一个 source point 可以被问到任意 target timestep,也可以被表达在任意 camera coordinate reference 里。
Encoder 是 ViT-style video transformer,使用 local frame-wise 和 global self-attention layers。主模型使用 ViT-g,40 layers,spatio-temporal patch size 为 $2\times16\times16$。为了支持任意 aspect ratio,输入视频先 resize 到固定方形分辨率,再把原始 aspect ratio 作为 separate token 输入 transformer。
Decoder 是 8-layer cross-attention transformer,参数量 144M。每个 query 独立 cross-attend 到 $G$,queries 之间不做 self-attention。论文明确说,早期实验里让 queries 互相 self-attend 会导致明显性能下降,所以独立 query 不是只为省计算,也是为了避免 query 之间形成训练/推理分布不匹配。
数据全流程:输入、表示、shape 和语义

图:基于论文方法、训练和 appendix 描述重绘的数据流。它强调 D4RT 的 cost model:视频全局编码一次,之后按任务发起 query;训练时只采样 2048 个 supervised queries,推理时可以 sparse,也可以 dense。
| 阶段 | 对象 | Shape / Dim | 语义 | 产生者 | 消费者 |
|---|---|---|---|---|---|
| input | video $V$ | $T\times H\times W\times3$ | 原始视频 | dataset / user video | encoder |
| preprocessing | resized video | training uses $256\times256$ | 固定 encoder input resolution;aspect ratio 另放 token | preprocessing | encoder |
| global latent | $G$ | $N\times C$,not specified | 全局几何、时间、对应关系和相机信息 | encoder | decoder |
| query coordinate | $(u,v)$ | normalized $[0,1]^2$ | source frame 中的点位置 | query sampler | query token |
| query times | $t_{src},t_{tgt},t_{cam}$ | discrete timesteps $1…T$ | source、target state、camera reference | query sampler | query token |
| local patch | RGB patch | $9\times9$ | source point 周围局部外观 | source frame crop | query token |
| point prediction | $P$ | $R^3$ | target time、camera reference 下的 3D 点 | decoder | tasks / losses |
| auxiliary outputs | 2D coords, normals, visibility, motion, confidence | partially specified | 辅助监督和不确定性权重 | decoder projections | losses |
训练和推理的差异很关键。训练时,模型没有 dense decode 全视频所有像素,而是在每个 clip 中采样 2048 个 queries。推理时,query 可以按下游任务自由组织:只要 sparse tracks,就发少量点;要 dense depth,就对所有像素发 query;要 camera pose,就对粗 grid 发 query 后再做几何求解。
这也是 D4RT 的机制优势:global context 的高成本由 encoder 一次性承担,decoder 的成本与 query 数量近似线性相关。对于一个需要不同输出密度的 4D 系统,这比固定输出整帧 dense maps 更可控。
Query 如何导出不同任务
论文 Table 1 可以理解成 D4RT 的 API 文档。模型输出永远是 3D 点 $P$,不同任务只改变 query 的 Cartesian product。
| Task | Query 方式 | 后处理 |
|---|---|---|
| Point Track | 固定 $(u,v,t_{src})$,让 $t_{tgt}=t_{cam}$ 遍历 $1…T$ | 得到该 source point 的 3D trajectory |
| Point Cloud | 对视频所有像素和时间查询,在固定 $t_{cam}$ 下表达 | 得到统一 camera reference 下的全视频点云 |
| Depth Map | 设置 $t_{src}=t_{tgt}=t_{cam}$,对当前帧所有像素查询 | 保留输出 $P$ 的 z 维 |
| Extrinsics | 同一批点分别表达在不同 camera reference 下 | 用 Umeyama algorithm 求 rigid transform |
| Intrinsics | 在一帧上查询 coarse grid 的 3D 点 | pinhole camera 假设下估计 focal length,取 median |
extrinsics 的推导很巧。对 frame $i,j$,作者构造两批查询:
\[q_{i,k}=(u_k,v_k,i,i,i),\qquad q_{j,k}=(u_k,v_k,i,i,j)\]这两批输出描述的是同一批 3D 点,只是坐标系不同。因此只需要找到两批点之间的 rigid transformation,就能得到相对 camera pose。
intrinsics 则假设 principal point 在 $(0.5,0.5)$,对于解码出的 3D 点 $P=(p_x,p_y,p_z)$,估计:
\[f_x = p_z(u-0.5)/p_x,\qquad f_y = p_z(v-0.5)/p_y\]然后对多个 grid points 取 median。论文提到可通过 nonlinear refinement 支持 fisheye 等畸变模型,但这不是主实验的核心验证对象。
Training:监督信号、loss 和优化目标
主训练设置来自正文和 appendix:
| 项目 | 配置 |
|---|---|
| Encoder | ViT-g, 40 layers, patch size $2\times16\times16$ |
| Decoder | 8-layer cross-attention decoder |
| Params | encoder 1B, decoder 144M |
| Clip | 48 frames |
| Resolution | $256\times256$ |
| Queries | 2048 random queries per clip |
| Datasets | BlendedMVS, Co3Dv2, Dynamic Replica, Kubric, MVS-Synth, PointOdyssey, ScanNet++, ScanNet, Tartanair, VirtualKitti, Waymo Open, plus internal datasets |
| Optimizer | AdamW |
| Training | 500k steps, local batch size 1 across 64 TPU chips, just over 2 days |
| Weight decay | 0.03 |
| LR | warmup 2500 steps to $10^{-4}$, cosine decay to $10^{-6}$ |
| Grad clip | max $L^2$ norm 10 |
| supervision 的主项是 normalized 3D point position 上的 $L_1$ loss。论文把 target 和 estimated point sets 都按 mean depth normalize,再使用 $\operatorname{sign}(x)\cdot\log(1+ | x | )$ 变换,降低远处点对 loss 的影响。 |
辅助监督包括:
| Loss / prediction | 作用 |
|---|---|
| 2D coordinates $L_1$ | 约束点投影到 image space 的位置 |
| Surface normals cosine similarity | 提升局部几何 |
| Visibility binary cross-entropy | 判断 target point 是否可见 |
| Point motion $L_1$ | 监督运动向量 |
| Confidence penalty | 用 $-\log(c)$ 和 confidence-weighted 3D error 处理不确定性 |
Appendix 还给出 query sampling 细节:30% 的 $(u,v)$ 采样在 depth discontinuities 或 motion boundaries 附近,这些边界由 depth maps 上的 Sobel filter 预计算;同时以 0.4 的概率强制 $t_{tgt}=t_{cam}$,以提升下游任务表现。
训练配置里有一个复现风险:训练 mixture 包含 public and internal datasets。论文列出了多个公开数据集,但没有给出 internal data 的内容、比例或过滤细节。因此从 paper alone 复现完整指标并不现实。
Inference:测试时到底怎么生成结果
推理时先运行一次 encoder 得到 $G$,之后按任务组织 queries。因为 decoder 是 pointwise 且 independent,query batch 可以高度并行;输出也可以按需要稀疏或稠密。
对于 dense all-pixel tracking,朴素做法会非常贵:每个 source pixel 都要在每个 target time、每个 camera reference 下查询,复杂度可到 $O(T^2HW)$。D4RT 的 dense tracking algorithm 用 occupancy grid 来减少重复:
- 初始化 occupancy grid,大小为 $T\times H\times W$。
- 从未访问的 source pixels 采样 batch。
- 对每个 source point 发起 full-video track queries。
- 把 track 可见经过的 spatio-temporal pixels 标记为 visited。
- 只从仍未 visited 的 pixels 发起新 track。
论文报告这个策略带来 5-15x adaptive speedup,取决于视频 motion complexity。这个算法能成立的前提是 decoder 的 per-query cost 足够低,而且 source-to-target 查询足够灵活;否则 dense tracking 会被 query 数量压垮。
Evaluation:验证集、指标和 baseline 是否公平
论文评估覆盖三组任务。
第一组是 dynamic 3D tracking,数据集是 TAPVid-3D,包括 DriveTrack、ADT 和 PStudio。指标包括 3D Average Jaccard、Average percent of points within delta error $\text{APD}_{3D}$、Occlusion Accuracy,以及 world-coordinate tracking 下的 L1。
第二组是 3D reconstruction / depth / point cloud。Point cloud 在 Sintel 和 ScanNet 上评估,先按 MegaSaM protocol mean-shifting 对齐,再报告 mean L1。Depth 在 Sintel、ScanNet、KITTI、Bonn 上评估,按 prior works 做 scale-only 和 scale-and-shift alignment,然后报告 AbsRel。
第三组是 camera pose。Sintel 使用带 motion blur 和 atmospheric effects 的 14-sequence subset;指标包括 ATE、RPE trans、RPE rot,以及 Re10K 上的 Pose AUC@30。论文还在 speed plot 中比较 camera pose accuracy 和 throughput,并说明为了公平,会移除 baseline 中与 camera estimation 无关的 decoding heads 来加速它们。
baseline 选择是合理的:tracking 部分比较 CoTracker3 + depth / VGGT、DELTA、SpatialTrackerV2、St4RTrack;reconstruction/depth/pose 部分比较 MegaSaM、VGGT、MapAnything、SpatialTrackerV2、$\pi^3$。需要注意的是,D4RT 训练数据含 internal datasets,baseline 是否也享有同等数据规模无法从论文完全确认;这会影响 SOTA claim 的归因。
实验与证据:哪些 claim 被支持,哪些还不够
4D tracking:动态 correspondence 是主战场
TAPVid-3D 上,D4RT 在大部分 tracking 指标上领先。以有 GT intrinsics 的设置为例:
| Dataset / Metric | D4RT | 主要对比 |
|---|---|---|
| DriveTrack AJ | 0.304 | CoTracker3+VGGT 0.245, SpatialTrackerV2 0.195 |
| DriveTrack $\text{APD}_{3D}$ | 0.410 | CoTracker3+VGGT 0.342, SpatialTrackerV2 0.275 |
| ADT AJ | 0.307 | SpatialTrackerV2 0.303 |
| ADT $\text{APD}_{3D}$ | 0.408 | SpatialTrackerV2 0.404 |
| PStudio AJ | 0.372 | CoTracker3+VGGT 0.215 |
| PStudio $\text{APD}_{3D}$ | 0.498 | CoTracker3+VGGT 0.318 |
world-coordinate tracking 也更贴近 D4RT 的 claim,因为它不仅测试点跟踪,还测试 reference frame switching。DriveTrack 上,D4RT 报告 $\text{APD}_{3D}=0.470$、L1 0.017;SpatialTrackerV2 是 0.201、0.117;CoTracker3+VGGT 是 0.292、0.160。
这些数字支持 D4RT 的核心主张:统一 query interface 不只是能做多个任务,而且在动态 3D correspondence 上确实强。
Depth / point cloud:动态场景收益更明显
Point cloud L1 上,D4RT 在 Sintel 为 0.768,优于 $\pi^3$ 的 1.139、SpatialTrackerV2 的 1.375、MegaSaM 的 1.531;ScanNet 上 D4RT 为 0.028,略优于 $\pi^3$ 的 0.030。
Depth AbsRel 上,D4RT 在 Sintel 为 0.171 scale-only / 0.148 scale-and-shift,是表中最好。ScanNet 为 0.020 / 0.018,KITTI 为 0.055 / 0.051;Bonn 上 $\pi^3$ 更好一些,D4RT 排第二。
我的理解是,Sintel 的优势最能说明方法价值,因为它包含更强动态;ScanNet/KITTI/Bonn 上的提升则说明 unified query 并没有牺牲静态几何能力。
Camera pose:既快又准,但不是每个子指标都独占第一
Camera pose 表中,D4RT 在 Sintel 得到 ATE 0.065、RPE-T 0.024、RPE-R 0.126;ScanNet 得到 ATE 0.014、RPE-T 0.010、RPE-R 0.302;Re10K Pose AUC 为 83.5。
这里要精确一点:MegaSaM 在 Sintel RPE-R 也达到 0.126,$\pi^3$ 在 ScanNet RPE-R 是 0.291,比 D4RT 的 0.302 略好。但 D4RT 的整体组合更强,尤其是 Pose AUC 和 throughput。
速度方面,论文报告 D4RT 在 camera pose 上达到 200+ FPS,比 VGGT 快约 9x,比 MegaSaM 快约 100x。tracking throughput 也很明显:
| Method | 60 FPS | 24 FPS | 10 FPS | 1 FPS |
|---|---|---|---|---|
| DELTA | 0 | 5 | 408 | 5,770 |
| SpatialTrackerV2 | 29 | 84 | 219 | 2,290 |
| D4RT | 550 | 1,570 | 3,890 | 40,180 |
这张表是全文最支持工程价值的证据之一。D4RT 的快不是靠牺牲任务能力,而是来自 decoder interface:每条 track 是 $T$ 个独立 query,适合 batch parallel。
Ablation:local patch 和 pretraining 很关键
local RGB patch 的消融非常强。Sintel 上,加入 local appearance patch 后:
| Setting | AbsRel(S) | AbsRel(SS) | ATE | RPE-T | RPE-R |
|---|---|---|---|---|---|
| w/o local patch | 0.366 | 0.306 | 0.173 | 0.031 | 0.262 |
| w/ local patch | 0.302 | 0.257 | 0.091 | 0.028 | 0.245 |
这说明 query 不应该只是一个抽象坐标和时间索引。局部 RGB patch 给 decoder 提供了低层外观线索,帮助建立 correspondence,也帮助保留边界细节。
Backbone size 也呈现清楚趋势:从 ViT-B 到 ViT-g,depth 和 pose 总体改善。appendix 还显示 VideoMAE initialization 对结果至关重要:random init 的 AbsRel(S) 为 0.738、ATE 为 0.334;VideoMAE init 为 0.302、0.091。
辅助 loss 的消融更细:去掉 2D position 或 normal 主要伤 depth;去掉 confidence 主要伤 camera pose;visibility 在一个 depth setting 上略有反向,但整体对 pose 有帮助。这里的结论不是某个 loss 万能,而是 D4RT 的 3D point objective 需要多种 projection / geometry / uncertainty 约束共同稳定。
复现与工程风险
D4RT 的论文给了不少训练细节,但离可复现还有距离。
已指定的部分包括:模型 scale、clip length、resolution、query count、optimizer、LR schedule、loss weights、augmentation、query sampling、boundary oversampling、硬件和训练时长。按论文写法,主模型是 1B encoder + 144M decoder,在 64 TPU chips 上训 500k steps,耗时 just over 2 days。
缺口也很明确:
| 项目 | 状态 |
|---|---|
| D4RT official code | 论文 source 和项目页未找到 |
| Checkpoints / model card | 未找到 |
| Internal training data | 使用了 internal datasets,细节和比例未公开 |
| Full preprocessing | 数据 supervision 构造只部分说明 |
| Evaluation scripts | 未随论文 source 公开 |
| Global Scene Representation dim | $N$ 和 $C$ 未在正文明确给出 |
| Baseline exact runtime setup | 部分公平性说明有写,但完整脚本未公开 |
工程上还有几个风险。第一,模型很大;虽然 decoder query 很快,但 encoder 仍是 1B 级别视频 transformer。第二,intrinsics recovery 默认 principal point 在中心,复杂镜头模型只作为可加 refinement 提到。第三,输入 resize 到固定方形分辨率,高分辨率 query 可以恢复局部细节,但全局 latent 的信息瓶颈仍来自 encoder resolution。第四,独立 query decoding 在 dense 输出时是否会产生邻域不一致,论文没有专门把它作为 failure mode 展开。
所以这篇论文目前更像一个高质量研究系统,而不是马上可以拉下来复现的开源 baseline。真正可迁移的部分,是 query interface 和 cost model。
总结
D4RT 的价值在于把动态 4D 重建的多个输出统一到一个低层问题:给定视频全局表示,查询某个 source point 在某个时间和 camera reference 下的 3D 位置。这个问题定义足够小,decoder 可以轻;又足够表达,能派生 tracking、depth、point cloud 和 camera pose。
它最强的证据来自三处:TAPVid-3D 上的 dynamic tracking 指标,Sintel 上的 point cloud/depth 优势,以及 A100 tracking throughput 的数量级提升。local RGB patch、backbone scaling、pretraining 和辅助 loss 的消融也说明,性能不是单纯靠“大模型”堆出来,query 设计和监督设计都有明确贡献。
但它的边界也要说清楚:官方代码和权重未发布,训练数据含 internal datasets,完整 reproduction 目前不可直接做。SOTA 结论在论文实验里成立,但如果要做工程采用,需要先验证小模型、公开数据和真实部署硬件下能否保留核心 trade-off。
我会把这篇论文放在“值得机制级学习,但暂不适合作为直接复现目标”的位置。最可借鉴的是它的接口设计:当一个任务族看起来需要多个 dense heads 时,先问有没有可能把它们收敛成一个可组合 query space。D4RT 说明,在动态 3D/4D 场景里,这个方向不仅优雅,而且可能真的更快。
Recommended citation: Zhang et al., Efficiently Reconstructing Dynamic Scenes One D4RT at a Time, arXiv:2512.08924, 2025.
Download Paper