
FLUX.2 表征比较:VAE latent 不是预处理,而是生成模型的接口
FLUX.2 表征比较:VAE latent 不是预处理,而是生成模型的接口
技术博客:FLUX.2: Analyzing and Enhancing the Latent Space of FLUX – Representation Comparison 作者:Black Forest Labs 时间:2025-11-25 类别:Latent Diffusion / Flow Matching / Autoencoder Representation / Image Generation 链接:BFL article / actual iframe article / FLUX.2 announcement / GitHub flux2 / HF FLUX.2-dev 检索日期:2026-06-22
开篇点评:这篇文章到底解决了什么问题
BFL 这篇文章看起来像 FLUX.2 的技术发布稿,但真正值得读的是它把一个经常被工程上“默认处理”的模块推到了前台:图像 autoencoder 的 latent space 决定了后面的 diffusion / flow transformer 到底要学习什么分布。
过去很多 latent diffusion 系统会把 VAE 当成压缩器。图像进来,VAE encoder 得到 latent,生成模型在 latent 上训练,最后 decoder 还原图像。这个流程容易让人产生错觉:只要重建质量够好,VAE 就够好。BFL 的观点更具体:一个 autoencoder 需要同时满足三个目标,分别是 reconstruction fidelity、compression rate 和 latent learnability。前两者很直观,第三个经常被低估:生成模型是否容易在这个 latent space 里学习、采样、泛化。
我的判断是,这篇文章的价值不在于“FLUX.2 又赢了几个榜”,而在于给了一个评估 latent representation 的实验框架。它把 SD-VAE、FLUX.1 VAE、FLUX.2 VAE 和 RAE 放在同一个 latent flow matching proxy 里比较,并且强调 timestep distribution 必须为每个 representation 单独调;否则 representation 排名会被 sampler/training schedule 污染。

图:基于 BFL Figure 1 重绘。横轴是生成模型在 latent space 上的 gFID,纵轴是 reconstruction LPIPS;越靠左下越好。FLUX.2 不是 gFID 最低的点,但它在 learnability 和 reconstruction fidelity 之间更均衡。
Paper Card
| 项目 | 信息 |
|---|---|
| Source | BFL representation comparison article,外层页面实际通过 iframe 加载正文 |
| Actual body | https://bfl.ai/techblog/representation-comparison/index.html |
| Authors | Black Forest Labs |
| Date | 2025-11-25 |
| Task | 比较不同 image autoencoder latent spaces 对 reconstruction 和 latent generative modeling 的影响 |
| Compared AEs | SD-VAE, FLUX.1 VAE, FLUX.2 VAE, RAE |
| Proxy generator | ImageNet-256 上的 DiT-XL latent flow matching |
| Model context | FLUX.2 announcement 说明 FLUX.2 model family、open-core 策略和模型入口 |
| Code / Model | black-forest-labs/flux2 和 HF FLUX.2-dev 是 FLUX.2 model family 的官方入口;representation 实验的完整 parquet 数据和训练脚本未在正文中直接公开 |
| 复现状态 | 正文 HTML 嵌入了 Figure 1、Table 1、Table 2 的关键数值;完整实验数据文件 ../data 的公开 URL 核验为 404,FLUX.2 VAE 的完整训练细节也不是这篇博客的主要公开对象 |
Abstract:论文摘要解读
这不是传统 arXiv paper,没有标准 abstract。把 BFL 正文的 introduction 展开后,它的摘要可以读成这样:
Diffusion 和 Flow Matching 提供了稳定的连续分布建模框架,但它们的效率强依赖数据表示。Latent Diffusion Models 用 VAE 把图像压到 latent space,减少生成模型的计算量;传统 VAE 通过 pixel regression、perceptual loss 和 adversarial objective 学到偏“感知压缩”的表示,能去掉原始信号中的不可感知噪声。
问题是,感知压缩不等于生成模型最容易学习。近年的 RAE / REPA 方向显示,带有更强语义结构的 representation 可以让 diffusion transformer 更容易训练,但语义 representation 往往牺牲了 reference-based reconstruction fidelity。BFL 试图在这两个极端之间找平衡:FLUX.2 VAE 保持 image editing 所需的高保真 reconstruction,同时通过语义正则改善 latent learnability。
正文最核心的实验是:固定一个 DiT-XL latent flow matching 设置,在 SD、FLUX.1、FLUX.2、RAE 四种 latent space 上训练,并对 training / sampling timestep schedules 做扫参。结果显示,RAE 的 learnability 最强但重建失真大;FLUX.1 重建比 SD 好但 latent 更难学;FLUX.2 在重建和生成 learnability 之间给出更均衡的点。
Motivation
文章的 motivation 可以从 FLUX.1 Kontext 的需求开始理解。图像编辑任务要求输入图像被 VAE 编码再解码后尽量不丢细节,否则编辑前的主体、纹理、文字和局部布局都会漂。BFL 在正文中说,FLUX.1 VAE 为了高保真 reconstruction 放宽了 information bottleneck:latent dimensionality 是 SD-VAE 的 4 倍,并降低了 regularization weight。这确实改善了重建,但代价是 latent space 更不容易被 generative model 学。
RAE 代表另一个方向:直接用 frozen vision foundation encoder 做 encoder,再学习 decoder。这类 representation 对生成模型很友好,因为它已经带有高层语义结构;但 RAE encoder 本身不是为像素级重建训练的,reference-based reconstruction 指标很差。BFL 特意指出,RAE 的 rFID 看起来不错,但 LPIPS、SSIM、PSNR 都不支持它用于高保真 image editing。
所以这篇文章不是在问“哪个 VAE reconstruction 最好”,而是在问一个更贴近生成系统的问题:
| 目标 | 如果只优化它会怎样 |
|---|---|
| Learnability | latent 更语义、更容易建模,但可能丢掉像素细节 |
| Quality / perceptual distortion | reconstruction 更好,但 latent 可能含有高频、不规则结构,flow 更难学 |
| Compression | 计算更省,但过度压缩会同时伤重建和分布建模 |
FLUX.2 VAE 的定位就是在这三者之间重选 trade-off,而不是简单扩大 latent 或换 decoder。
直观效果:先看它能说明什么
Figure 1 的四个点已经足够说明 BFL 想讲的故事:
| AE | gFID ↓ | LPIPS ↓ | 解读 |
|---|---|---|---|
| RAE | 3.103955 | 1.6737 | latent 最容易学,但 reference reconstruction 最差 |
| FLUX.2 | 3.701722 | 0.2668 | learnability 接近 RAE,同时 reconstruction fidelity 明显更好 |
| SD | 7.72709 | 0.9519 | 传统 VAE baseline,两个维度都不占优 |
| FLUX.1 | 10.12791 | 0.3380 | reconstruction 比 SD 好,但 latent learnability 最弱 |
这里的 gFID 是文章用 latent flow proxy 训练出的 generative FID,不是完整 FLUX.2 文生图系统的最终榜单。LPIPS 是 reference-based reconstruction metric,越低说明 decoder 从 latent 恢复原图越接近。
这张图支持的结论很明确:FLUX.2 没有在每个单项都第一。RAE 在 gFID 上更好,但 LPIPS 很差;FLUX.2 是一个折中点。对 image editing 来说,这种折中比单纯 gFID 更重要,因为编辑系统需要先“认出并保住输入图像”,再做修改。
方法总览:这篇文章真正比较的是什么
这篇技术博客的“方法”不是一个单独网络结构,而是一套 representation evaluation protocol。它有两个分支:
- reconstruction branch:给定图像 $u$,用 autoencoder 得到 $E(u)$,再解码 $D(E(u))$,用 LPIPS、SSIM、PSNR、rFID 评价重建。
- generation branch:冻结 encoder $E$,在 latent $E(u)$ 上训练一个 DiT-XL flow matching model,用 gFID 衡量这个 latent distribution 是否容易学。

图:基于 BFL 正文重绘的评测流程。关键点是 autoencoder candidate 固定后,重建指标和 latent flow generation 指标分别评估;generation branch 还需要为每个 latent space 调 training/sampling timestep schedule。
四个 autoencoder 的 token 设置如下。正文说明,为了让序列长度一致,SD、FLUX.1、FLUX.2 使用 $2\times2$ latent patching,RAE 不 patch;最终都得到 256 tokens,但每个 token 的 channel 数不同。
| AE | Channels / token | 设计倾向 |
|---|---|---|
| SD-VAE | 16 | 传统 LDM VAE baseline |
| FLUX.1 VAE | 64 | 为 Kontext 编辑需求放宽 bottleneck,提升 reconstruction |
| FLUX.2 VAE | 128 | 相比 SD-VAE 降低 compression,并引入语义正则 |
| RAE | 768 | frozen vision foundation representation,learnability 强但 reconstruction 弱 |
BFL 对 FLUX.2 VAE 的具体架构和训练 recipe 没有在这篇文章里完整公开。正文能确认的是:它相对 SD-VAE 有 8 倍 latent dimensionality,并“integrate these insights”,也就是吸收 spectral / equivariance / semantic regularization / REPA-style representation alignment 这条线的经验,用来同时满足 image editing fidelity 和 learnability。
数据全流程:输入、表示、shape 和语义
这套实验的数据流比完整 FLUX.2 系统简单,重点是隔离 representation。
| 阶段 | 对象 | Shape / Dim | 语义 | 来源 / 消费者 |
|---|---|---|---|---|
| input | image $u$ | ImageNet, $256\times256$ | 训练和评测图像 | ImageNet training / validation |
| encoder | $E$ | frozen;具体 architecture 依 AE 而定 | 把图像映射到 latent representation | SD / FLUX.1 / FLUX.2 / RAE |
| latent | $E(u)$ | 256 tokens;channels 为 16/64/128/768 | 被 flow model 学习的 data representation | DiT-XL latent flow |
| noise | $\epsilon$ | standard normal,shape 与 latent 对齐 | flow interpolation 的噪声端点 | CFM loss |
| timestep | $t$ | scalar | 控制 signal-noise ratio | 从 $p(t)$ 采样 |
| noisy latent | $v_t=(1-t)E(u)+t\epsilon$ | latent-shaped | flow model 输入 | DiT-XL |
| target velocity | $\epsilon-E(u)$ | latent-shaped | CFM regression target | loss |
| reconstruction | $D(E(u))$ | RGB image | 检查 decoder fidelity | LPIPS / SSIM / PSNR / rFID |
| generated samples | decoded flow samples | 50k images | 检查 latent learnability | FID vs ADM reference batch |
正文没有公开每个 AE 的 encoder / decoder layer 数、训练数据过滤、semantic regularization loss 权重、FLUX.2 VAE 的完整 optimizer 配置。这些都应标记为 not specified,不能从 Figure 1 的结果反推。
Training:latent flow 怎么训练
generation branch 使用 conditional flow matching。对每个 autoencoder,冻结 image encoder $E$,训练 DiT-XL backbone $v_\theta$ 预测从 latent 到 noise 的 velocity:
\[\mathcal{L}_\text{CFM}(\theta) = \mathbb{E}_{t\sim p,\ u\sim p_\text{data},\ \epsilon\sim\mathcal{N}} \left\| v_\theta((1-t)E(u)+t\epsilon;\ t) - (\epsilon-E(u)) \right\|^2\]正文给出的主要训练设置是:
| 项目 | 配置 |
|---|---|
| Dataset | ImageNet training data |
| Resolution | $256\times256$ |
| Backbone | DiT-XL |
| LR | constant $10^{-4}$ |
| Weight decay | no weight decay |
| Batch size | 256 |
| EMA | 0.9999 |
| Evaluation cadence | every 100k steps |
| Compared variants | with / without REPA alignment objective |
关键不是这些 hyperparameters 本身,而是 timestep distribution。BFL 认为 $p(t)$ 的最优选择依赖 representation 的 scale、dimensionality、spectrum 和 resolution。为了公平比较,他们没有只用一个固定 schedule,而是每个 representation 都扫:
| Distribution | 说明 |
|---|---|
shifted uniform (ts) | 先采 $u\sim U(0,1)$,再做 timeshift $s(\alpha,u)$ |
shifted logit-normal (ln) | logit-normal distribution 的均值随 $\log\alpha$ shift |
plateau logit-normal (pln) | 在 mode 后保持 plateau,更偏向 high-noise timesteps |
timeshift 函数是:
\[s(\alpha,t)=\frac{\alpha t}{1+(\alpha-1)t}\]他们考虑 $\alpha\in{1.00,1.78,2.95,4.63,6.93}$。这个细节很重要,因为 Figure 2 明确说明:如果不调 shifting,RAE 和 FLUX.2 的相对排序可能改变。
Inference:测试时到底怎么生成结果
在 representation proxy 实验里,推理不是完整 text-to-image FLUX.2,而是 ImageNet class-conditional latent flow sampling:
- 从 random ImageNet class 条件采样。
- 在对应 AE 的 latent space 中用 50 Euler steps 解 ODE。
- 用对应 decoder 解码 latent。
- 生成 50k samples。
- 与 ADM reference batch 计算 FID,也就是文章里的 gFID。
这个设置的好处是相对干净:它把 VAE latent space 对 DiT-XL flow learning 的影响放大出来。限制也很明显:ImageNet-256 proxy 不等价于完整 FLUX.2 文生图、参考图编辑、多参考一致性或文字渲染能力。
后半部分的 FLUX.2 model family 是另一层证据。正文说 FLUX.2 使用 latent flow matching architecture,把 Mistral-3 24B vision-language model 和 rectified flow transformer 结合起来,并使用 SwiGLU 和更高效的 global modulation mechanism。这个大模型运行在前面讨论的 FLUX.2 VAE latent space 上,但完整模型效果已经混入 VLM、训练数据、scale、conditioning 和 decoder 等因素,不能单独归因给 VAE。
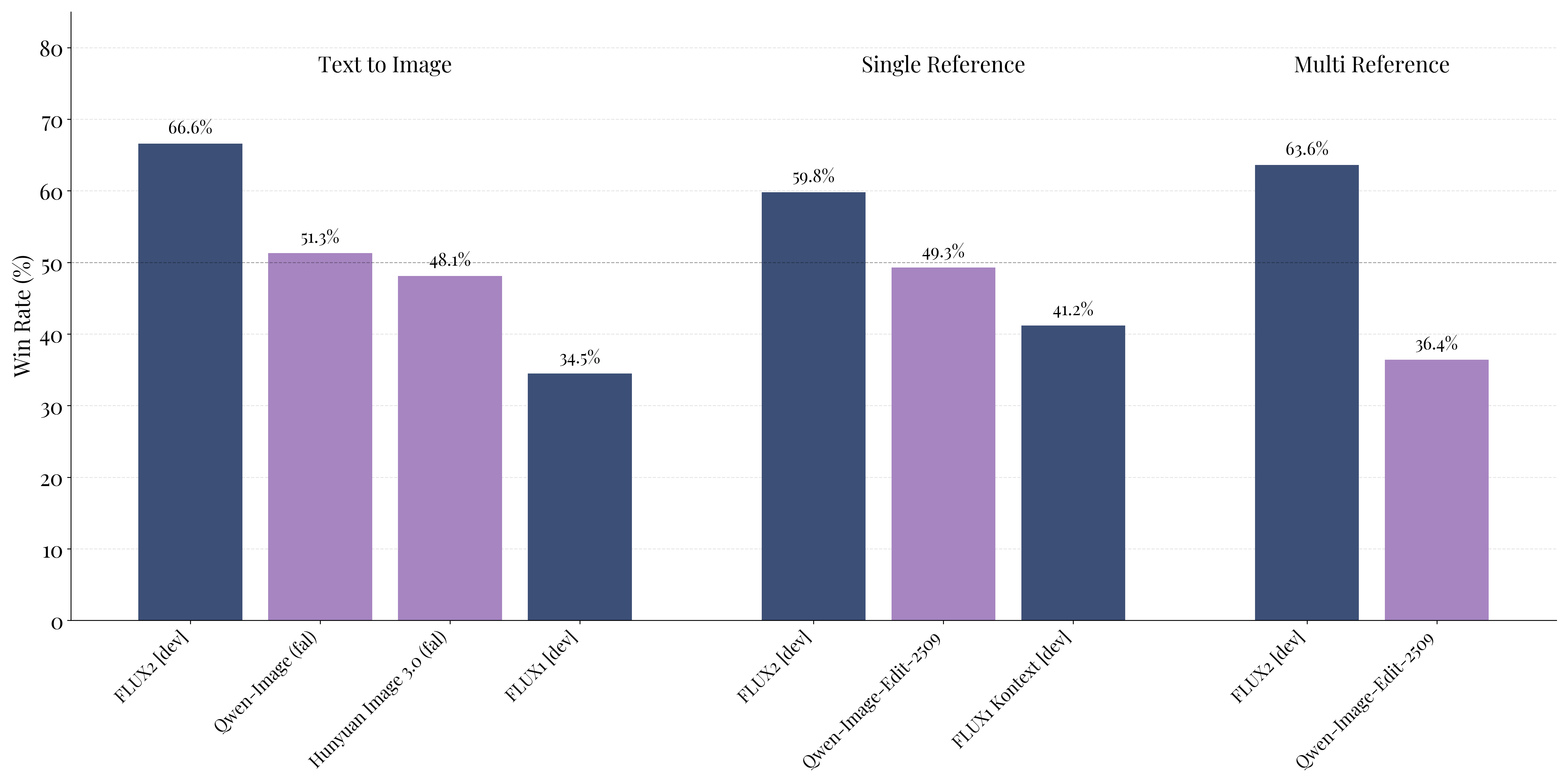
图:BFL Figure 3,官方 FLUX.2 [dev] human preference evaluation。它说明 FLUX.2 model family 的整体效果,但不能单独证明 VAE 是唯一原因。
Evaluation:验证集、指标和 baseline 是否公平
重建指标来自 ImageNet validation set:
| Model | LPIPS ↓ | SSIM ↑ | PSNR ↑ | rFID ↓ |
|---|---|---|---|---|
| RAE | 1.6737 ± 0.0057 | 0.4962 ± 0.0026 | 18.8272 ± 0.0429 | 0.6107 |
| SD | 0.9519 ± 0.0054 | 0.6976 ± 0.0121 | 25.0520 ± 0.0673 | 0.6451 |
| FLUX.1 | 0.3380 ± 0.0026 | 0.8893 ± 0.0058 | 31.1312 ± 0.0745 | 0.1761 |
| FLUX.2 | 0.2668 ± 0.0017 | 0.9038 ± 0.0049 | 31.4632 ± 0.0633 | 0.1124 |
这张表有一个容易误读的点:RAE 的 rFID 不差,但 LPIPS、SSIM、PSNR 都很差。BFL 正文也提醒,non-reference rFID 可以说明某些 general modeling suitability,但 image editing 依赖 reference-based fidelity。换句话说,RAE 可能生成分布看起来合理,但它不适合保留输入图像的精确结构。
生成指标则是 gFID。Table 2 的 HTML data_json 可以恢复 700k steps 最佳设置:
| Model | trainp | train shift | sample shift | FID ↓ |
|---|---|---|---|---|
| RAE + REPA | ln | 6.93 | 6.93 | 3.103955 |
| FLUX.2 + REPA | ln | 4.63 | 6.93 | 3.701722 |
| SD + REPA | ln | 1.00 | 2.95 | 7.72709 |
| FLUX.1 + REPA | ln | 1.00 | 2.95 | 10.127908 |
| RAE | pln | 6.93 | 6.93 | 3.476388 |
| FLUX.2 | ln | 4.63 | 6.93 | 4.528974 |
| SD | pln | 1.00 | 2.95 | 12.400983 |
| FLUX.1 | ln | 1.78 | 2.95 | 13.61545 |
baseline fairness 上,BFL 做得比较认真的一点是没有用单一 schedule 判定 latent 好坏。文章明确说,每个 representation 的 timestep distribution 和 sampling grid 都会影响表现,因此他们比较的是“约略最优 schedule 下”的 representation。缺点是完整 sweep 数据文件没有公开,读者只能从嵌入 HTML 的表格和 plot 数据复核主要点。
实验与证据:哪些 claim 被支持,哪些还不够
Claim 1:FLUX.2 VAE 的 reconstruction 最好。 这个 claim 被 Table 1 强支持。FLUX.2 在 LPIPS、SSIM、PSNR、rFID 四个指标上都优于 SD、FLUX.1 和 RAE。尤其是 LPIPS 0.2668,相比 FLUX.1 的 0.3380 继续下降;rFID 0.1124 也显著优于 FLUX.1 的 0.1761。
Claim 2:FLUX.2 VAE 的 latent 比 FLUX.1 和 SD 更容易学。 这个 claim 由 Figure 1 / Table 2 支持。在 +REPA 最佳设置下,FLUX.2 的 gFID 为 3.70,明显优于 SD 的 7.73 和 FLUX.1 的 10.13。没有 REPA 时,FLUX.2 也是 4.53,仍明显好于 SD / FLUX.1。
Claim 3:FLUX.2 比 RAE 更好。 这里需要更谨慎。FLUX.2 不是 gFID 最好,RAE + REPA 的 3.10 低于 FLUX.2 + REPA 的 3.70。BFL 真正能证明的是:FLUX.2 以小幅 learnability 代价换来大幅 reconstruction fidelity。对 image editing,这是合理 trade-off;对只追求 ImageNet gFID 的 generation proxy,RAE 仍然更强。
Claim 4:timestep schedule 是 representation comparison 的必要部分。 这个 claim 被正文敏感性分析支持。BFL 报告说,ln / pln 总能找到优于 shifted uniform 的参数;training shift 的 best-worst relative change 从 61.5% 到 86.42% 不等,远大于很多模型小改动。这个结果对复现实验很实用:换 VAE 后不重调 timestep schedule,FID 结论可能不可靠。
Claim 5:FLUX.2 model family 的最终效果来自这个 VAE。 这个 claim 只被间接支持。Figure 3 展示 FLUX.2 [dev] 在 text-to-image、single reference、multi reference 上有 66.6%、59.8%、63.6% win rate,但完整 FLUX.2 系统还包含 Mistral-3 24B VLM、rectified flow transformer、训练数据和 scale。VAE 是必要组成,但 Figure 3 不能把提升单独归因给 VAE。
复现与工程风险
第一,完整实验数据没有完全公开。正文代码读取 pd.read_parquet("../data"),但我核验了几个可能 URL:/techblog/representation-comparison/data、/techblog/data、/techblog/representation-comparison/data.parquet 都返回 404。HTML 内嵌了 Figure 1、Table 1、Table 2 和部分 Plotly 数据,可以复核主要结论,但无法直接重跑完整 sweep。
第二,FLUX.2 VAE 的训练 recipe 不完整。文章说明它使用更大 latent dimensionality 和 semantic regularization,但没有公开完整 architecture、loss weights、训练数据、optimizer、batch、训练步数等。要复刻 FLUX.2 VAE 本身,会比复刻 latent flow proxy 更难。
第三,ImageNet-256 proxy 不能覆盖真实 FLUX.2 使用场景。真实系统需要文生图、图像编辑、参考图一致性、文字/Logo 生成、4MP editing 等能力;ImageNet gFID 只能说明 latent representation 对一个 class-conditional flow proxy 的 learnability。
第四,schedule tuning 既是公平性手段,也是复现负担。BFL 比较了 3 种 training distributions、5 个 train shifts、5 个 sample shifts、with/without REPA。对一个工程团队来说,换 VAE 就意味着必须重新调 schedule,否则无法判断 latent 本身是否真的更好。
第五,RAE 的结果提示了一个产品边界:如果任务是纯生成,牺牲 reconstruction 的 semantic representation 可能更划算;如果任务是编辑、修复、参考图保持、品牌一致性,reference-based fidelity 的权重会变高。FLUX.2 的 trade-off 更偏后者。
总结
这篇 BFL 技术博客最有用的一句话是:latent representation 是生成模型的接口,不是无关紧要的压缩格式。同一个 DiT-XL flow,面对 SD、FLUX.1、FLUX.2、RAE latent,会有完全不同的训练难度、最优 timestep schedule 和 reconstruction-generation trade-off。
FLUX.2 VAE 的贡献可以概括成三个点:
- 相比 SD 和 FLUX.1,它显著改善 reference-based reconstruction。
- 相比 FLUX.1 的“放宽 bottleneck 换高保真”,它通过语义正则把 latent learnability 拉回来。
- 相比 RAE,它牺牲一点 gFID,换来对 image editing 更关键的 fidelity。
我的判断是,这篇文章对做图像生成/编辑系统的工程意义很直接:不要只用 rFID 或重建图肉眼判断 VAE;也不要只看下游 gFID。一个合理的 representation benchmark 至少要包含 reconstruction metrics、latent flow learnability、timestep schedule sensitivity 和真实任务需求权重。
未解决的问题也很清楚。FLUX.2 VAE 的完整 recipe 没公开,ImageNet proxy 和真实文生图/编辑之间仍有距离,REPA / DINOv2-style external representation learner 在大规模 text-to-image 上是否仍是最优也没有定论。BFL 在 Future Work 里暗示他们正在探索不用外部 pretrained representation learner 的替代路线;如果这个方向成立,下一步竞争可能不是“谁的 VAE 更大”,而是谁能学到既可重建、又语义规整、还不依赖外部 teacher 的 latent space。
Recommended citation: Black Forest Labs, FLUX.2: Analyzing and Enhancing the Latent Space of FLUX -- Representation Comparison, 2025.
Download Paper