
CVPR 2026 Report 深读:视觉研究正在从模型能力转向系统边界
CVPR 2026 Report 深读:视觉研究正在从模型能力转向系统边界
报告:CVPR 2026 Report (Finalized ver.) 作者:Hirokatsu Kataoka, Yue Qiu, Oishi Deb, Kazuya Nishimura 等,LIMIT.Lab / cvpaper.challenge / VGG 时间 / 版本:2026-06-11 finalized version,165 页 slide deck 类别:CVPR 2026 Trend Report / Visual General Intelligence / Robotics / VLM-as-Judge / 3D and 4D Vision 本文基于官方 PDF 阅读;检索日期:2026-06-23。 注意:这是一份会议趋势报告,不是单篇 peer-reviewed paper。文中把报告里的判断标记为趋势观察,而不是把所有结论当作论文级实验结论。
开篇点评:这份报告到底值得读什么
这份 CVPR 2026 Report 不是一个传统论文总结。它更像一份现场观察和研究地图:前面记录 CVPR 规模、投稿、审稿、Findings Track、compute reporting 等会议机制变化;中间把 VGI、robotics、bitter lesson、VLM-as-judge、remote sensing、pixel-space diffusion、3D/4D、VLA 等主题串起来;最后把讨论落到开源、poster 可见性、position paper track、compute-aware awards、industry vs academia 这些制度问题。
我的判断是,这份报告最有价值的地方不是列了多少篇 paper,而是指出了视觉研究的边界正在变化:过去我们更关心模型能不能分类、检测、分割、重建、生成;现在越来越多问题变成系统能不能被可靠评价、能不能和动作闭环、能不能在低资源下交付、能不能在真实部署里持续学习。
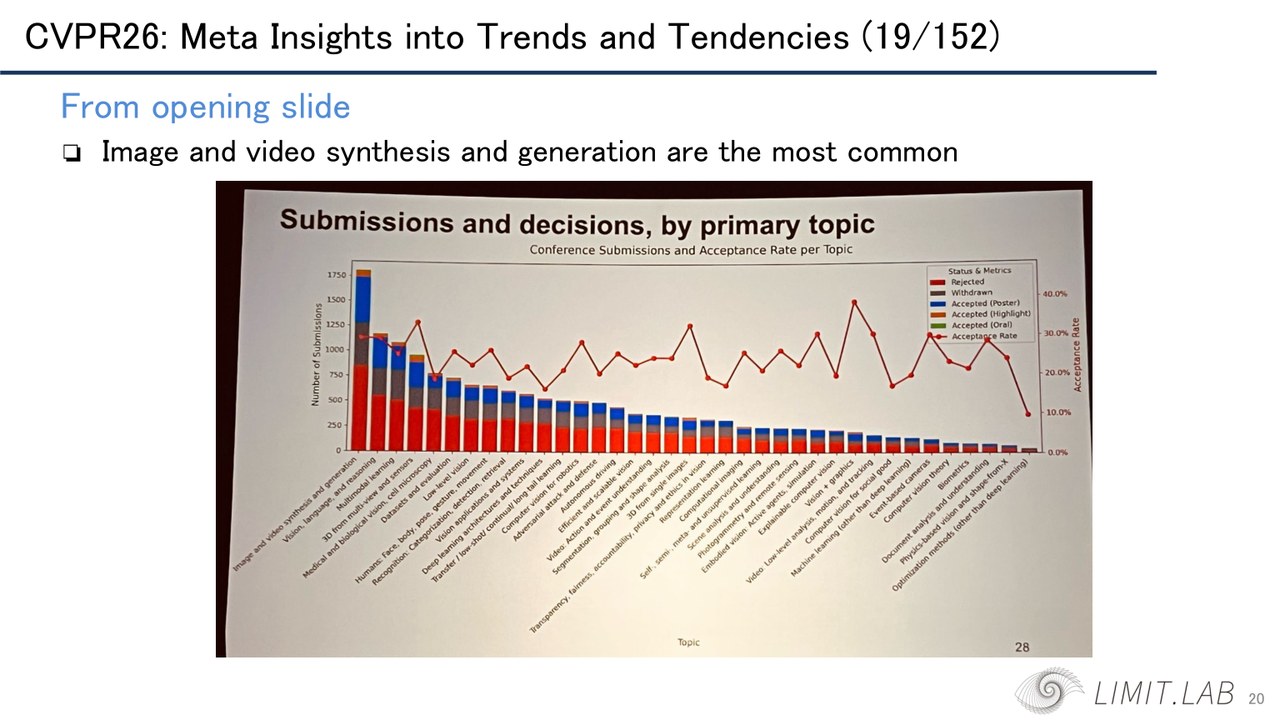
图:报告从 CVPR opening slide 截取了投稿主题分布。image/video synthesis and generation 是最拥挤的主题之一,但后面的讨论说明,生成能力本身已经不再是唯一焦点,评价、控制、交互、物理和部署正在变成新的分界线。
Report Card
| 项目 | 信息 |
|---|---|
| Source | CVPR 2026 Report PDF |
| Title | CVPR 2026 Report (Finalized ver.) |
| Authors | Hirokatsu Kataoka, Yue Qiu, Oishi Deb, Kazuya Nishimura, Rintaro Yanagi 等 |
| Organization | LIMIT.Lab / cvpaper.challenge / Visual Geometry Group |
| Format | 165 页 slide deck,包含 conference opening、workshop report、selected papers、discussion |
| Evidence type | 会议观察、slide 汇总、作者团队解读、部分 CVPR 2026 paper / workshop 引用 |
| 适合回答的问题 | CVPR 2026 哪些方向变热、视觉研究的评价和交付边界怎么变、academia 和 industry 的角色怎样变化 |
| 不适合回答的问题 | 某一方法是否 SOTA、某个数值是否可复现、某篇论文的完整技术细节 |
Abstract:报告主旨解读
如果把 165 页报告压缩成一句话,我会写成:CVPR 2026 的视觉研究正在从“单个模型能力”转向“可评价、可交互、可部署、可持续学习的视觉系统”。
报告给出的线索很一致。会议规模继续变大,投稿和审稿压力继续上升,Findings Track 和 Compute Reporting Initiative 说明社区开始意识到“贡献类型”和“算力资源”需要更细的制度化表达。研究主题上,image/video generation 仍然拥挤,但真正被反复讨论的是 generation 之后的问题:谁来判断质量,判断器是否可靠,生成模型是否理解物理,视频模型能不能进入 action loop,3D/4D 是不是必要中间表示,学术界在工业级 compute 面前还能在哪些问题上建立优势。
这也是我读完后最强的感受:CVPR 2026 的关键词不是单纯的 bigger model,而是 boundary。评价边界、表征边界、数据边界、交付边界、研究机构边界都在重新划线。
会议层面的变化:规模、审稿和算力进入显性讨论
报告开头记录了几个信号。CVPR 2026 投稿继续增长,报告中引用的数字是 16,092 submissions、4,089 accepted,接受率约 25.4%。作者也提到 44k authors、25k reviewers、909 area chairs 等规模信息。这样的体量让 CVPR 不只是学术会议,而是一个超大规模的研究分发系统。
这个规模带来两个直接后果。
第一,会议需要更细的论文分流机制。报告提到 CVPR 2026 引入 Findings Track:Area Chairs 可以推荐主会投稿中的技术扎实但 novelty 相对增量的论文,作者选择是否 opt in,最终 Findings papers 进入 workshop proceedings。这个机制背后的问题是:当投稿规模太大时,主会 accepted/rejected 这个二值出口已经不够表达研究价值。
第二,compute 不再只是训练细节,而是评价公平性的一部分。报告里有 Compute Reporting Initiative,也有“GPU 数量会影响 acceptance”的观察,以及 Limited GPU Access in Academia 的讨论。这里不能过度解读成“算力决定一切”,但它说明社区已经无法假装所有团队面对相同实验预算。对个人研究者和小团队来说,这个问题很现实:如果 frontier scale 被工业部门垄断,学术贡献就要更重视 metrology、negative results、data governance、efficient models、hard domains、old-work synthesis 和可复现工具链。
主线一:Evaluator 变成研究对象,而不是赛后打分器
报告中最清楚的一条主线是 VLM-as-judge。作者把它概括为:当 generation 规模上来后,传统 reference metrics 很难评价真实质量,所以 judge 本身从后处理评分器变成研究对象和训练信号。

图:报告的 VLM-as-judge 趋势页。它把 2026 年 highlighted papers 中 VLM / multimodal-LLM 占比提升、生成评价难度上升、reward model 进入训练循环这些现象放在一起。
这条线很重要,因为它改变了生成模型论文的证据结构。过去很多图像/视频生成工作靠 FID、CLIPScore、human preference 或少量 qualitative samples 支撑 claim。现在问题变成:这个 evaluator 是否看得见 spatial error、temporal error、physical violation、identity drift、safety failure?如果 judge 自己会 hallucinate,或者只奖励“看起来合理”的结果,那么它就会把模型推向错误方向。
报告后面列了两类趋势。Trend A 是 judge specialized:视频 reward、spatial reward、saliency reasoning、low-level vision evaluator 等评价器开始按任务分化,并进入训练 loop。Trend B 是 judge reliability:研究者开始关心 judge 的感知错误、单 judge 偏差、multimodal hallucination、safety trace 和 verifiable reward。
我的解读是,未来 AIGC 系统的关键组件会从“generator + prompt”变成“generator + verifier + editor + data flywheel”。尤其在 face restoration、digital human 和视频生成里,肉眼可见的失败不总是 FID 能抓到的失败。比如身份相似度、牙齿和眼睛局部结构、嘴型同步、时序稳定、表情可控、局部纹理恢复,这些都需要更细粒度的 evaluator。
主线二:Robotics 不是 VLA 一个模型,而是 full-stack physical AI
报告的 robotics 部分很长,但核心可以压成一句:robotics 正在变成 full-stack physical AI,数据、模型、传感器、仿真、部署和可靠性必须一起扩展。

图:报告对 robotics workshop 的 meta insight。它没有把 robotics 简化成 VLA,而是分成 data、models、embodiment、systems 四层,并把 future directions 指向 world-action model、human-video alignment、tactile/contact 和 production metrics。
这一段对视觉研究很有启发。很多 VLA 工作看起来是在把 language reasoning 接到 action 上,但报告里的多位 talk 总结强调:真正难的是 action alignment、sensor alignment、embodiment alignment、memory、hierarchy、deployment flywheel 和 real-world reliability。也就是说,语言推理只是接口之一,不是物理智能的全部。
这和视频/世界模型的关系也很直接。视频模型能生成“像动作”的片段,不等于它能为机器人提供可执行策略。报告反复强调 human videos to robotics is not automatic:人类视频缺少机器人动作、力、接触、传感器状态和失败反馈。world model 可以放大有限交互数据,但 world model 本身也需要 action-observation 数据;这形成一个鸡生蛋问题。
对做 digital human 或 face/avatar 系统的人来说,这里也有平行启发。只生成一段好看的脸部视频,不等于系统可部署。部署系统还要处理输入质量、失败检测、identity consistency、编辑可控性、延迟、缓存、用户反馈和自动回归测试。视觉模型一旦进入工作流,模型只是系统中的一个组件。
主线三:3D/4D 不是死或活,而是按交付物重新分配角色
报告的 bitter lesson 部分很值得读。它没有简单说“scale 会杀死所有手工结构”,也没有反过来维护经典 CV 的每个中间任务。更精确的表述是:传统 CV 里的 segmentation、depth、flow、pose、3D、point tracking 等中间表示,正在从默认核心表示,变成按交付物选择的 interface、supervision、probe、debugging aid 或 deployment tool。
这个判断能解释很多看似矛盾的现象。对于最终输出是 pixels 的数字媒体任务,end-to-end video/image generation 可能绕过显式 3D。对于 CAD、制造、医学、AR/VR、交互编辑、安全审核,显式 3D 或中间表示仍然非常有价值,因为交付物、检查工具和人类工作流本身就需要可解释结构。对于 robotics,动作才是交付物,但 explicit 3D 仍可能在安全、接触规划、sim-to-real、debugging 和 human-in-the-loop 控制中发挥作用。

图:报告在 bitter lesson 后给出的 future directions。核心不是“不要 3D”,而是从 representation debate 转向 role-conditioned design:当 3D 或 mid-level outputs 是交付物、接口、安全诊断或数据高效辅助任务时,就应该使用它。
我比较认同这条判断。很多争论的错误在于把“内部必须显式 3D”与“完全不需要 3D”对立起来。更实际的问题是:你要交付什么?如果交付的是可编辑 avatar、可驱动 face rig、可检查工业缺陷、可复现医疗测量,显式结构就是产品接口的一部分。如果交付的是单段短视频,显式结构可能只是一种训练辅助或约束信号。
主线四:Pixel-space diffusion 是表征重新设计,不只是回到原始像素
报告里有一组 Back to Pixels from Latent Spaces in Diffusion Models 的 slide,和我最近读 FLUX.2 表征比较时的感受很接近。pixel-space diffusion 不是简单抛弃 VAE,而是在重新思考:固定 VAE latent 是否保留了生成和条件对齐所需的信息。
![]()
图:报告对 pixel-space diffusion 的总结。重点不在“latent 一定不好”,而在结构和细节是否应该由同一个同质化 denoising process 处理。
这条线对 restoration 尤其重要。真实世界 restoration 很多失败来自局部边界、文字、眼睛、牙齿、皮肤纹理、压缩伪影和身份细节。latent diffusion 如果在 VAE 压缩阶段已经丢了局部信息,后面的 transformer 再强也只能“合理补全”,不一定能忠实恢复。pixel-space 或 hybrid representation 可能更适合 spatially aligned conditional tasks,因为这些任务要求输出和输入在边界、小结构和局部 fidelity 上保持一致。
但这里也不能走极端。pixel-space 模型代价高,训练稳定性和长程全局语义都不一定更好。报告里的更合理方向是 modular pixel-space architecture:把 global semantics、local texture、frequency components、patch-level 和 pixel-level role 分开。对 face restoration 来说,这也许比单纯追求一个更大的 U-Net 或 DiT 更有意义。
和个人方向更相关的几个局部观察
这份报告里有几处和 AIGC workflow、digital human、face restoration、3D/4D tools 很接近。
第一是 NanoSD:报告把它归为 real-time image restoration 的 efficient foundation model。它强调 U-Net 和 VAE 的联合蒸馏,以及 accuracy、latency、model size 的平衡。这里的启发是,restoration 研究不能只看 PSNR/LPIPS 或视觉样张;如果目标是 ComfyUI workflow、边缘设备、在线服务或批量生产,延迟、显存、可组合性和失败检测都应该成为论文证据的一部分。
第二是 web videos as scalable data sources。报告列了从 unlabeled web videos 到 3D scenes、video-generated point clouds、3D human motion、driving policy pretraining、continuous latent motion 的一组工作。共同逻辑是:互联网视频不只是视觉内容库,而是潜在的几何、动作、交互和时序数据源。对 digital human 来说,动态人脸、头部姿态、手脸交互、说话风格、镜头运动都可能从视频中形成更细的中间监督,但前提是要处理相机、身份、动作和场景的对齐。
第三是 3D foundation model 和 4D scene modeling。报告提到 VGGT 系列、LagerNVS、D4RT 等方向,说明 3D/4D 正在从 per-scene optimization 转向 feed-forward、foundation feature、dynamic scene representation 和 downstream reusable features。对 avatar/face 系统来说,这意味着未来不一定要从零维护完整 3D pipeline,但应该关注 3D/4D foundation features 能否作为稳定的 control interface 或 consistency constraint。
第四是 VLA 的效率、泛化和 memory。虽然这看起来离个人博客项目较远,但它和所有可部署 AI 系统共享同一个问题:模型不能只在 demo prompt 上成立,要能处理历史、失败、跨域、低延迟和资源限制。博客站点里的小工具、3D viewer、EfficientTime 这类项目看似不是论文,但它们正好体现了“研究模型如何进入可用 workflow”的工程价值。
证据强度与阅读边界
这份报告适合作为趋势地图,不适合作为单篇论文的最终证据。原因有三点。
第一,它混合了官方 opening slide、workshop talk、public notes、作者团队总结和 selected paper 摘要。不同页的证据强度不一样。会议规模和接受数量比较可核验,workshop insight 属于现场观察,具体论文摘要则需要回到原论文验证。
第二,报告里的很多判断是 meta insight,不是 controlled experiment。比如“3D 正在从核心表示变成接口/工具”这个判断很有解释力,但它不是一个可以由单个 benchmark 直接证明的结论。
第三,selected papers 的摘要覆盖很广,但每篇只给了很短说明。读者如果要引用某个方法的 novelty、SOTA 或 limitation,仍然应该回到 CVF OpenAccess、arXiv、project page 和代码仓库。
因此我会把它当成一个选题雷达:用它发现值得深读的论文和问题,而不是用它替代原论文。
我会重点跟进的方向
如果从个人研究和工程方向出发,我会优先跟进五条线。
| 方向 | 为什么重要 | 具体问题 |
|---|---|---|
| Verifiable evaluator | AIGC 系统越来越依赖 reward / judge | 如何评价 identity、temporal consistency、spatial correctness、local fidelity |
| Restoration efficiency | restoration 进入 workflow 后延迟和显存很关键 | diffusion restoration 如何做蒸馏、分辨率扩展、局部 fidelity 保持 |
| Pixel / hybrid representation | face restoration 和 dense conditional generation 需要对齐细节 | VAE latent 是否丢掉身份和小结构,pixel-space 是否值得引入 |
| 3D/4D as interface | avatar、viewer、AR/VR、动态场景需要可控结构 | 什么时候显式 3D 是产品接口,什么时候只是训练辅助 |
| Workflow systems | 模型价值需要落到可用工具链 | ComfyUI、3D viewer、dataset/eval tooling、轻量工程项目如何支撑研究复用 |

图:报告最后讨论了 3D understanding、4D dynamic scene modeling、world simulation 和 physical reasoning 是否会成为新的偏置。这个问题比“哪个方向更火”更重要,因为它直接关系到研究资源会被怎样分配。
总结
这份 CVPR 2026 Report 的中心信息不是“今年哪个模型最强”,而是视觉研究的任务定义正在变。生成模型很强之后,社区开始追问:谁来评价生成质量?评价器是否可靠?模型能不能进入动作闭环?3D/4D 是必要表示还是按交付物选择的接口?学术界在工业算力时代还能贡献什么?
对我来说,最有用的读法是把它当作 2026 年视觉研究的路线图:如果继续做 face restoration、digital human、AIGC workflow 和 3D/4D 工具,不能只盯模型结构,也要同时设计 evaluator、data pipeline、interactive control、resource budget 和 deployment feedback。真正的 frontier 不只是更大的 image model,而是可验证、可交互、可部署、能持续改进的视觉系统。
Sources
Recommended citation: Hirokatsu Kataoka et al., CVPR 2026 Report (Finalized ver.), LIMIT.Lab / cvpaper.challenge / Visual Geometry Group, 2026.
Download Paper